 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOFTER: An Online Pipeline for Time Series Forecasting
Apr 08, 2023We introduce OFTER, a time series forecasting pipeline tailored for mid-sized multivariate time series. OFTER utilizes the non-parametric models of k-nearest neighbors and Generalized Regression Neural Networks, integrated with a dimensionality reduction component. To circumvent the curse of dimensionality, we employ a weighted norm based on a modified version of the maximal correlation coefficient. The pipeline we introduce is specifically designed for online tasks, has an interpretable output, and is able to outperform several state-of-the art baselines. The computational efficacy of the algorithm, its online nature, and its ability to operate in low signal-to-noise regimes, render OFTER an ideal approach for financial multivariate time series problems, such as daily equity forecasting. Our work demonstrates that while deep learning models hold significant promise for time series forecasting, traditional methods carefully integrating mainstream tools remain very competitive alternatives with the added benefits of scalability and interpretability.
Symphony in the Latent Space: Provably Integrating High-dimensional Techniques with Non-linear Machine Learning Models
Dec 01, 2022



This paper revisits building machine learning algorithms that involve interactions between entities, such as those between financial assets in an actively managed portfolio, or interactions between users in a social network. Our goal is to forecast the future evolution of ensembles of multivariate time series in such applications (e.g., the future return of a financial asset or the future popularity of a Twitter account). Designing ML algorithms for such systems requires addressing the challenges of high-dimensional interactions and non-linearity. Existing approaches usually adopt an ad-hoc approach to integrating high-dimensional techniques into non-linear models and recent studies have shown these approaches have questionable efficacy in time-evolving interacting systems. To this end, we propose a novel framework, which we dub as the additive influence model. Under our modeling assumption, we show that it is possible to decouple the learning of high-dimensional interactions from the learning of non-linear feature interactions. To learn the high-dimensional interactions, we leverage kernel-based techniques, with provable guarantees, to embed the entities in a low-dimensional latent space. To learn the non-linear feature-response interactions, we generalize prominent machine learning techniques, including designing a new statistically sound non-parametric method and an ensemble learning algorithm optimized for vector regressions. Extensive experiments on two common applications demonstrate that our new algorithms deliver significantly stronger forecasting power compared to standard and recently proposed methods.
* 24 pages
MSGNN: A Spectral Graph Neural Network Based on a Novel Magnetic Signed Laplacian
Sep 18, 2022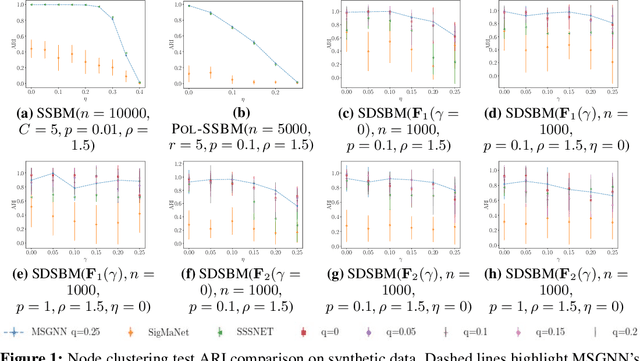
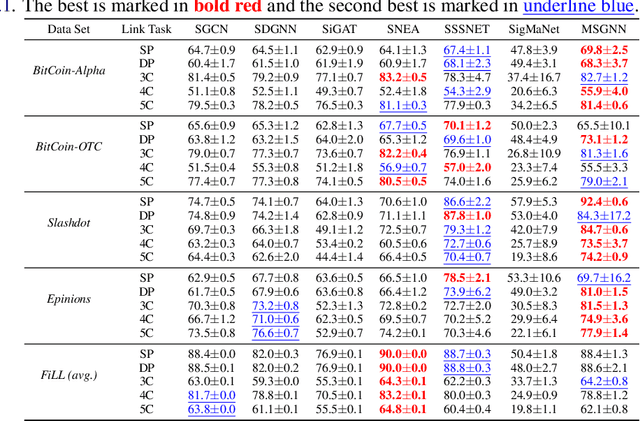
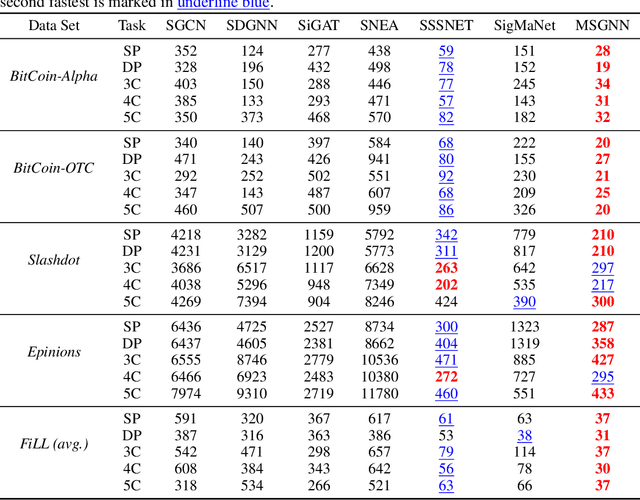
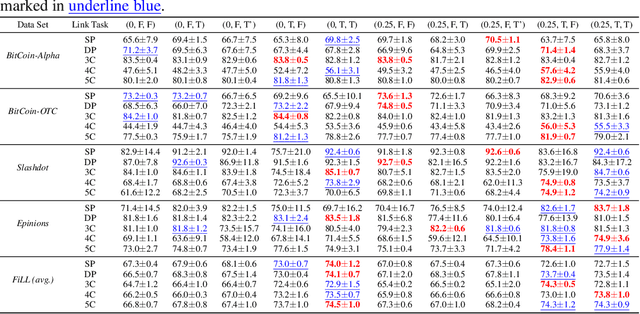
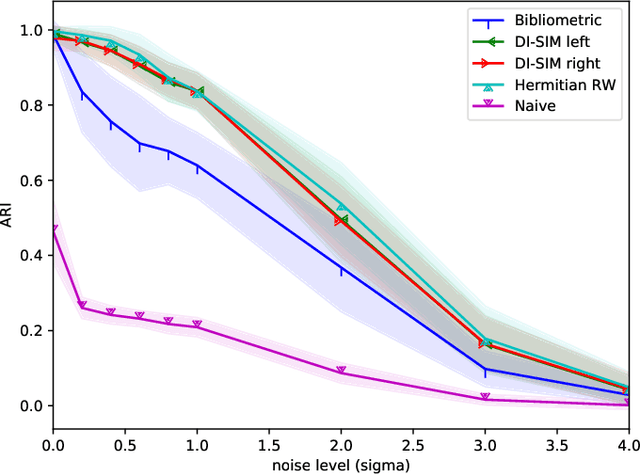
Signed and directed networks are ubiquitous in real-world applications. However, there has been relatively little work proposing spectral graph neural networks (GNNs) for such networks. Here we introduce a signed directed Laplacian matrix, which we call the magnetic signed Laplacian, as a natural generalization of both the signed Laplacian on signed graphs and the magnetic Laplacian on directed graphs. We then use this matrix to construct a novel efficient spectral GNN architecture and conduct extensive experiments on both node clustering and link prediction tasks. In these experiments, we consider tasks related to signed information, tasks related to directional information, and tasks related to both signed and directional information. We demonstrate that our proposed spectral GNN is effective for incorporating both signed and directional information, and attains leading performance on a wide range of data sets. Additionally, we provide a novel synthetic network model, which we refer to as the signed directed stochastic block model, and a number of novel real-world data sets based on lead-lag relationships in financial time series.
Graph similarity learning for change-point detection in dynamic networks
Mar 29, 2022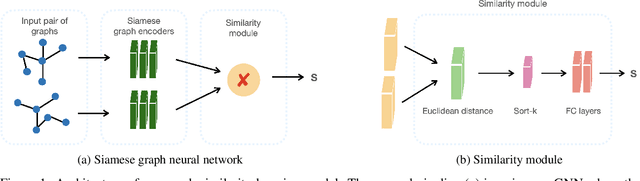
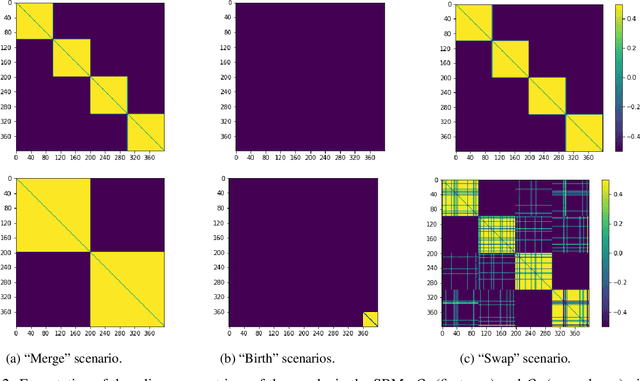
Dynamic networks are ubiquitous for modelling sequential graph-structured data, e.g., brain connectome, population flows and messages exchanges. In this work, we consider dynamic networks that are temporal sequences of graph snapshots, and aim at detecting abrupt changes in their structure. This task is often termed network change-point detection and has numerous applications, such as fraud detection or physical motion monitoring. Leveraging a graph neural network model, we design a method to perform online network change-point detection that can adapt to the specific network domain and localise changes with no delay. The main novelty of our method is to use a siamese graph neural network architecture for learning a data-driven graph similarity function, which allows to effectively compare the current graph and its recent history. Importantly, our method does not require prior knowledge on the network generative distribution and is agnostic to the type of change-points; moreover, it can be applied to a large variety of networks, that include for instance edge weights and node attributes. We show on synthetic and real data that our method enjoys a number of benefits: it is able to learn an adequate graph similarity function for performing online network change-point detection in diverse types of change-point settings, and requires a shorter data history to detect changes than most existing state-of-the-art baselines.
DAMNETS: A Deep Autoregressive Model for Generating Markovian Network Time Series
Mar 28, 2022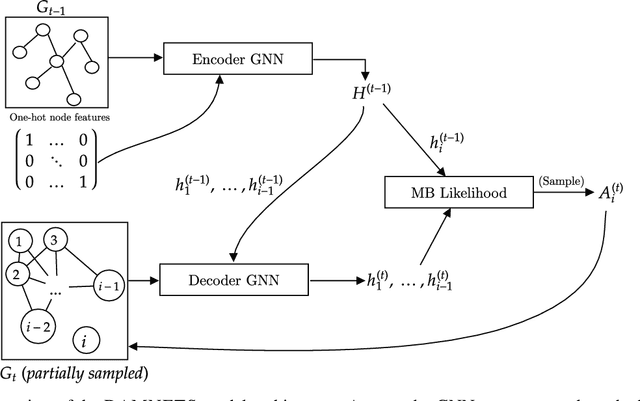
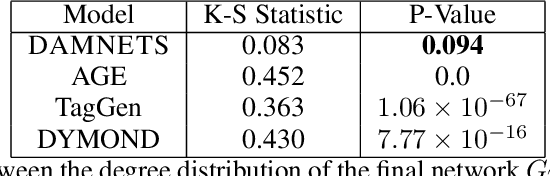
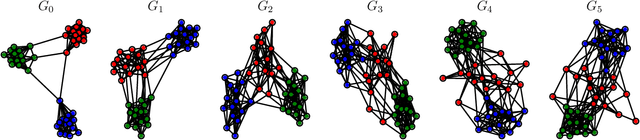

In this work, we introduce DAMNETS, a deep generative model for Markovian network time series. Time series of networks are found in many fields such as trade or payment networks in economics, contact networks in epidemiology or social media posts over time. Generative models of such data are useful for Monte-Carlo estimation and data set expansion, which is of interest for both data privacy and model fitting. Using recent ideas from the Graph Neural Network (GNN) literature, we introduce a novel GNN encoder-decoder structure in which an encoder GNN learns a latent representation of the input graph, and a decoder GNN uses this representation to simulate the network dynamics. We show using synthetic data sets that DAMNETS can replicate features of network topology across time observed in the real world, such as changing community structure and preferential attachment. DAMNETS outperforms competing methods on all of our measures of sample quality over several real and synthetic data sets.
PyTorch Geometric Signed Directed: A Survey and Software on Graph Neural Networks for Signed and Directed Graphs
Feb 22, 2022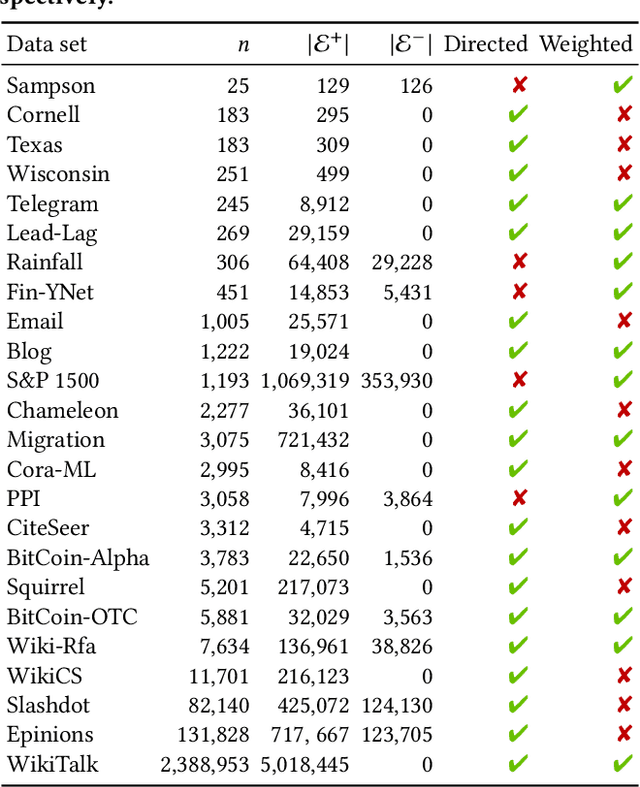
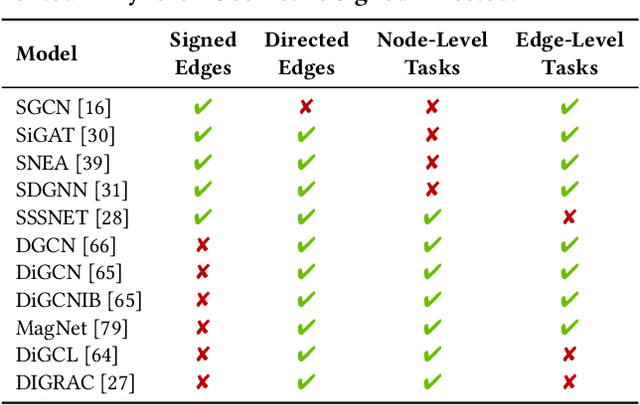
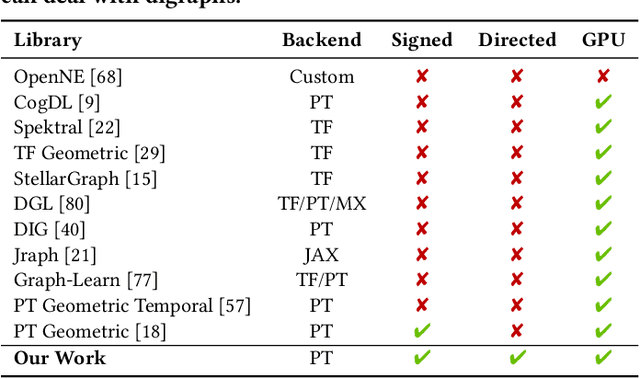
Signed networks are ubiquitous in many real-world applications (e.g., social networks encoding trust/distrust relationships, correlation networks arising from time series data). While many signed networks are directed, there is a lack of survey papers and software packages on graph neural networks (GNNs) specially designed for directed networks. In this paper, we present PyTorch Geometric Signed Directed, a survey and software on GNNs for signed and directed networks. We review typical tasks, loss functions and evaluation metrics in the analysis of signed and directed networks, discuss data used in related experiments, and provide an overview of methods proposed. The deep learning framework consists of easy-to-use GNN models, synthetic and real-world data, as well as task-specific evaluation metrics and loss functions for signed and directed networks. The software is presented in a modular fashion, so that signed and directed networks can also be treated separately. As an extension library for PyTorch Geometric, our proposed software is maintained with open-source releases, detailed documentation, continuous integration, unit tests and code coverage checks. Our code is publicly available at \url{https://github.com/SherylHYX/pytorch_geometric_signed_directed}.
GNNRank: Learning Global Rankings from Pairwise Comparisons via Directed Graph Neural Networks
Feb 01, 2022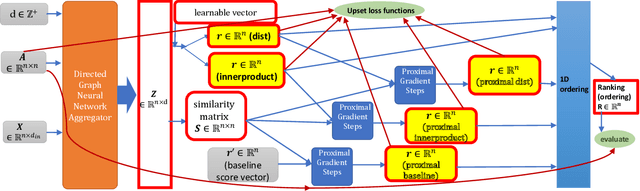
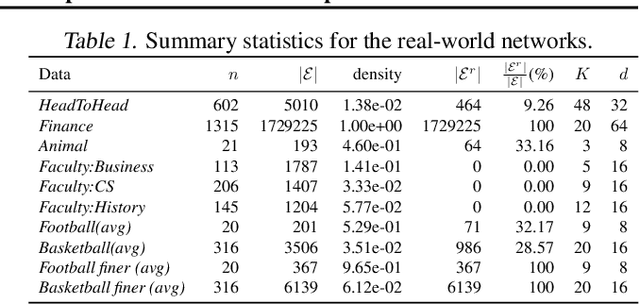
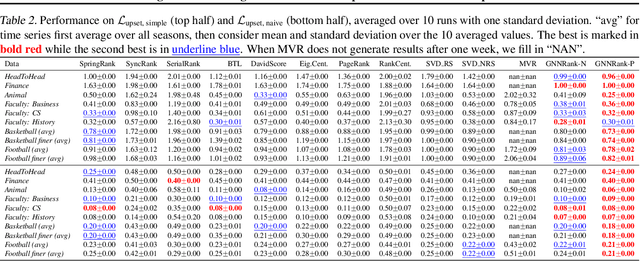

Recovering global rankings from pairwise comparisons is an important problem with many applications, ranging from time synchronization to sports team ranking. Pairwise comparisons corresponding to matches in a competition can naturally be construed as edges in a directed graph (digraph), whose nodes represent competitors with an unknown rank or skill strength. However, existing methods addressing the rank estimation problem have thus far not utilized powerful neural network architectures to optimize ranking objectives. Hence, we propose to augment an algorithm with neural network, in particular graph neural network (GNN) for its coherence to the problem at hand. In this paper, we introduce GNNRank, a modeling framework that is compatible with any GNN capable of learning digraph embeddings, and we devise trainable objectives to encode ranking upsets/violations. This framework includes a ranking score estimation approach, and adds a useful inductive bias by unfolding the Fiedler vector computation of the graph constructed from a learnable similarity matrix. Experimental results on a wide range of data sets show that our methods attain competitive and often superior performance compared with existing approaches. It also shows promising transfer ability to new data based on the trained GNN model.
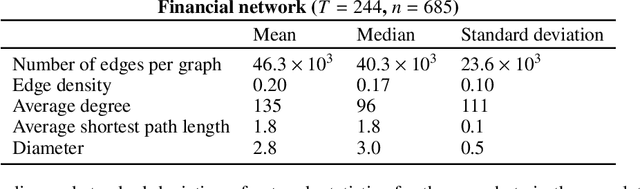
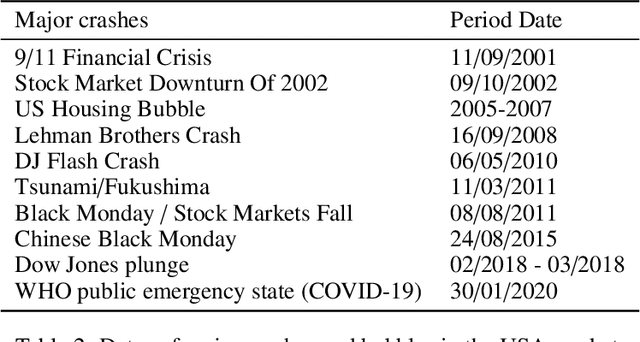
Lead-lag detection and network clustering for multivariate time series with an application to the US equity market
Jan 20, 2022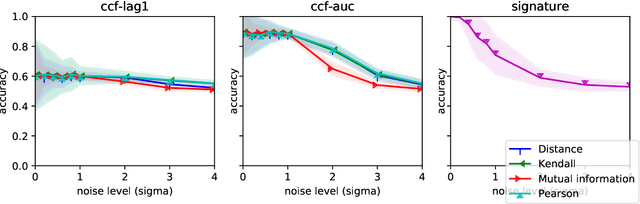
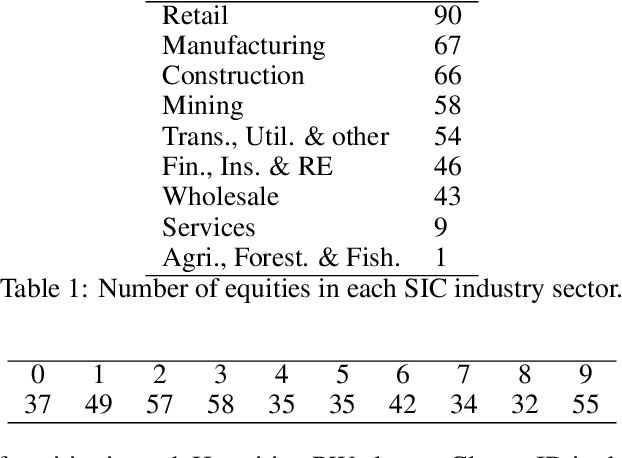
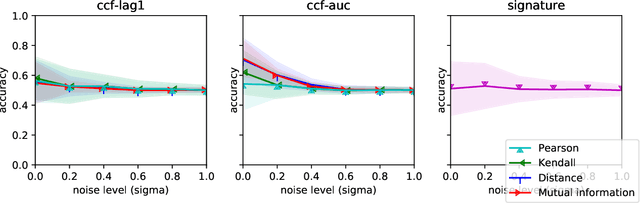
In multivariate time series systems, it has been observed that certain groups of variables partially lead the evolution of the system, while other variables follow this evolution with a time delay; the result is a lead-lag structure amongst the time series variables. In this paper, we propose a method for the detection of lead-lag clusters of time series in multivariate systems. We demonstrate that the web of pairwise lead-lag relationships between time series can be helpfully construed as a directed network, for which there exist suitable algorithms for the detection of pairs of lead-lag clusters with high pairwise imbalance. Within our framework, we consider a number of choices for the pairwise lead-lag metric and directed network clustering components. Our framework is validated on both a synthetic generative model for multivariate lead-lag time series systems and daily real-world US equity prices data. We showcase that our method is able to detect statistically significant lead-lag clusters in the US equity market. We study the nature of these clusters in the context of the empirical finance literature on lead-lag relations and demonstrate how these can be used for the construction of predictive financial signals.
Local2Global: A distributed approach for scaling representation learning on graphs
Jan 12, 2022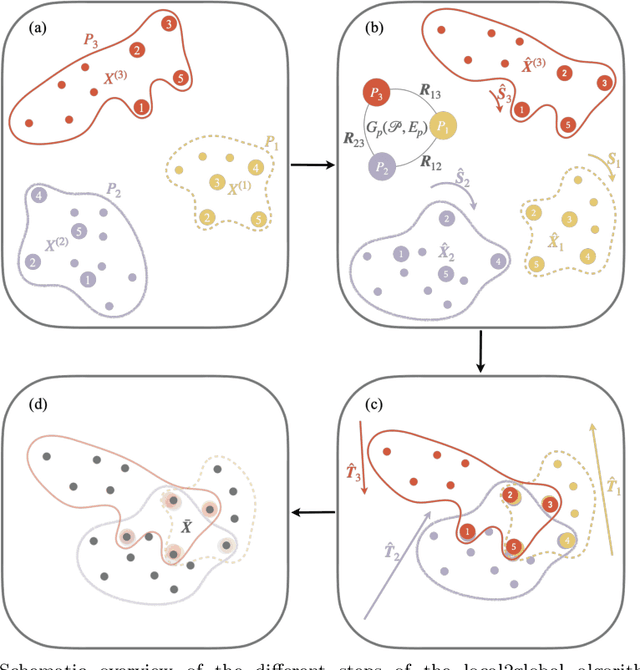

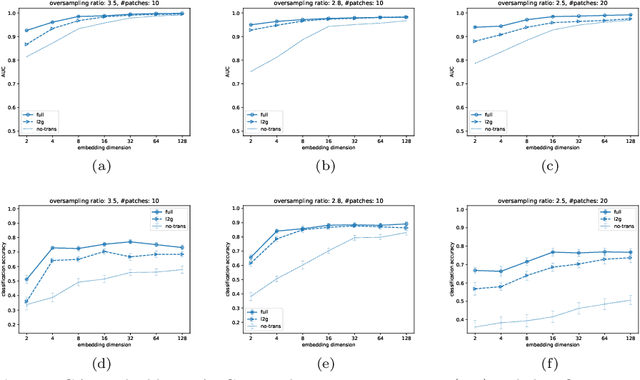
We propose a decentralised "local2global"' approach to graph representation learning, that one can a-priori use to scale any embedding technique. Our local2global approach proceeds by first dividing the input graph into overlapping subgraphs (or "patches") and training local representations for each patch independently. In a second step, we combine the local representations into a globally consistent representation by estimating the set of rigid motions that best align the local representations using information from the patch overlaps, via group synchronization. A key distinguishing feature of local2global relative to existing work is that patches are trained independently without the need for the often costly parameter synchronization during distributed training. This allows local2global to scale to large-scale industrial applications, where the input graph may not even fit into memory and may be stored in a distributed manner. We apply local2global on data sets of different sizes and show that our approach achieves a good trade-off between scale and accuracy on edge reconstruction and semi-supervised classification. We also consider the downstream task of anomaly detection and show how one can use local2global to highlight anomalies in cybersecurity networks.
SSSNET: Semi-Supervised Signed Network Clustering
Oct 13, 2021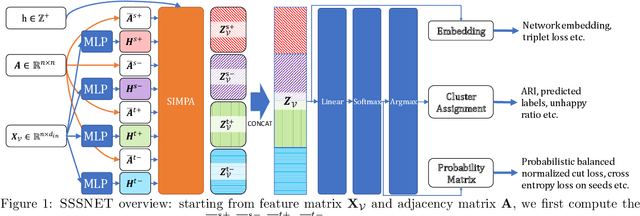
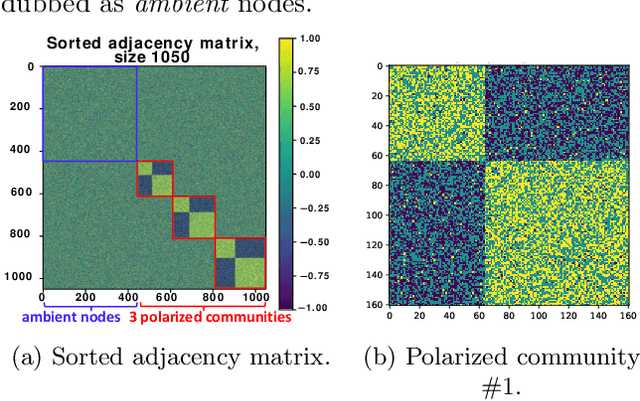
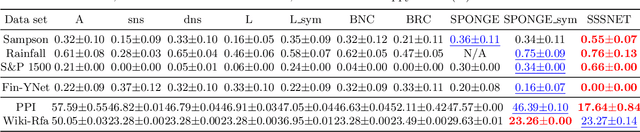
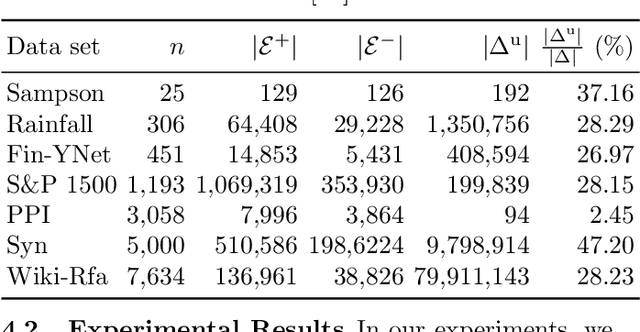
Node embeddings are a powerful tool in the analysis of networks; yet, their full potential for the important task of node clustering has not been fully exploited. In particular, most state-of-the-art methods generating node embeddings of signed networks focus on link sign prediction, and those that pertain to node clustering are usually not graph neural network (GNN) methods. Here, we introduce a novel probabilistic balanced normalized cut loss for training nodes in a GNN framework for semi-supervised signed network clustering, called SSSNET. The method is end-to-end in combining embedding generation and clustering without an intermediate step; it has node clustering as main focus, with an emphasis on polarization effects arising in networks. The main novelty of our approach is a new take on the role of social balance theory for signed network embeddings. The standard heuristic for justifying the criteria for the embeddings hinges on the assumption that "an enemy's enemy is a friend". Here, instead, a neutral stance is assumed on whether or not the enemy of an enemy is a friend. Experimental results on various data sets, including a synthetic signed stochastic block model, a polarized version of it, and real-world data at different scales, demonstrate that SSSNET can achieve comparable or better results than state-of-the-art spectral clustering methods, for a wide range of noise and sparsity levels. SSSNET complements existing methods through the possibility of including exogenous information, in the form of node-level features or labels.