 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransition-Based Dependency Parsing using Perceptron Learner
Jan 28, 2020
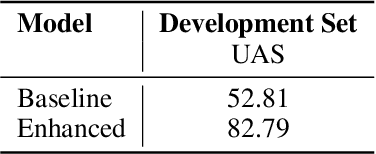
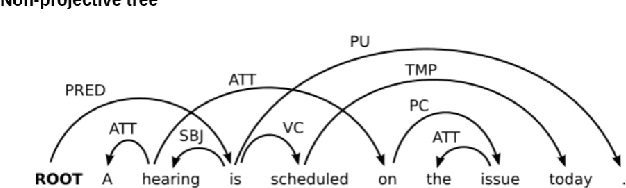
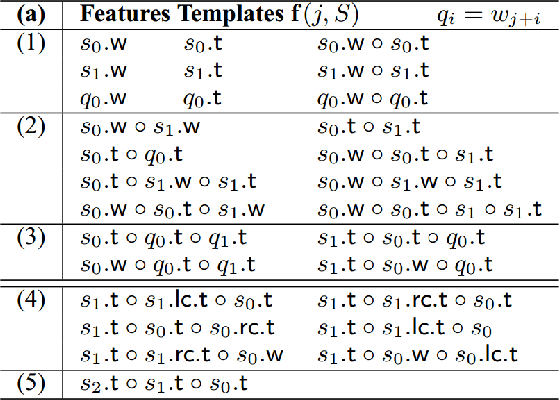
Syntactic parsing using dependency structures has become a standard technique in natural language processing with many different parsing models, in particular data-driven models that can be trained on syntactically annotated corpora. In this paper, we tackle transition-based dependency parsing using a Perceptron Learner. Our proposed model, which adds more relevant features to the Perceptron Learner, outperforms a baseline arc-standard parser. We beat the UAS of the MALT and LSTM parsers. We also give possible ways to address parsing of non-projective trees.
Rewarding Smatch: Transition-Based AMR Parsing with Reinforcement Learning
May 31, 2019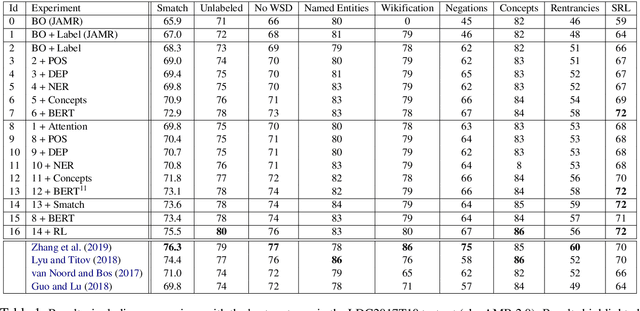
Our work involves enriching the Stack-LSTM transition-based AMR parser (Ballesteros and Al-Onaizan, 2017) by augmenting training with Policy Learning and rewarding the Smatch score of sampled graphs. In addition, we also combined several AMR-to-text alignments with an attention mechanism and we supplemented the parser with pre-processed concept identification, named entities and contextualized embeddings. We achieve a highly competitive performance that is comparable to the best published results. We show an in-depth study ablating each of the new components of the parser
Structural Supervision Improves Learning of Non-Local Grammatical Dependencies
Apr 06, 2019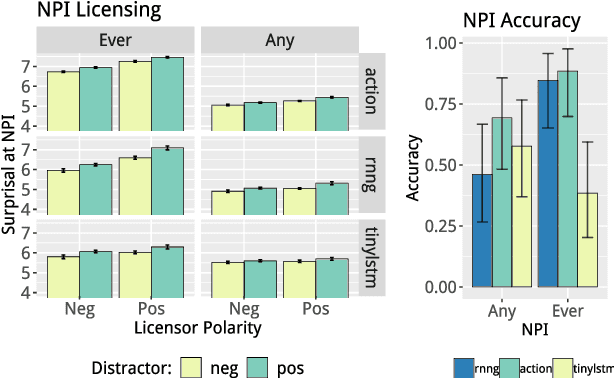
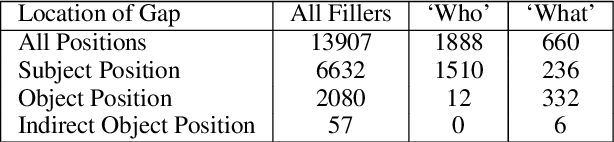
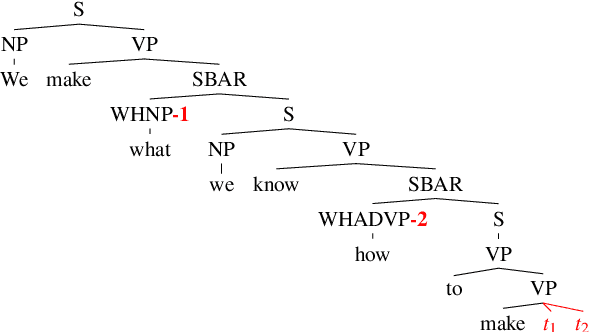
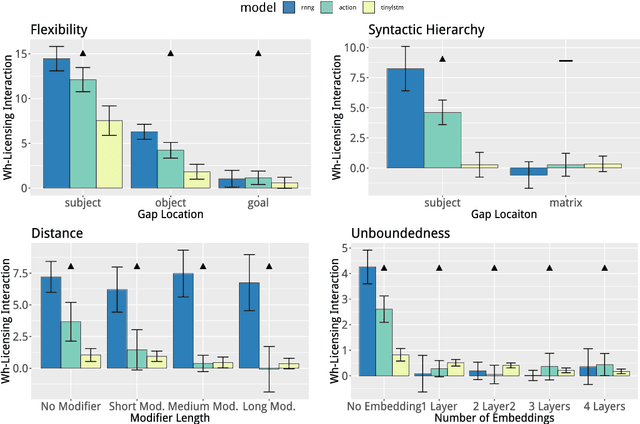
State-of-the-art LSTM language models trained on large corpora learn sequential contingencies in impressive detail and have been shown to acquire a number of non-local grammatical dependencies with some success. Here we investigate whether supervision with hierarchical structure enhances learning of a range of grammatical dependencies, a question that has previously been addressed only for subject-verb agreement. Using controlled experimental methods from psycholinguistics, we compare the performance of word-based LSTM models versus two models that represent hierarchical structure and deploy it in left-to-right processing: Recurrent Neural Network Grammars (RNNGs) (Dyer et al., 2016) and a incrementalized version of the Parsing-as-Language-Modeling configuration from Chariak et al., (2016). Models are tested on a diverse range of configurations for two classes of non-local grammatical dependencies in English---Negative Polarity licensing and Filler--Gap Dependencies. Using the same training data across models, we find that structurally-supervised models outperform the LSTM, with the RNNG demonstrating best results on both types of grammatical dependencies and even learning many of the Island Constraints on the filler--gap dependency. Structural supervision thus provides data efficiency advantages over purely string-based training of neural language models in acquiring human-like generalizations about non-local grammatical dependencies.
Neural Language Models as Psycholinguistic Subjects: Representations of Syntactic State
Mar 08, 2019
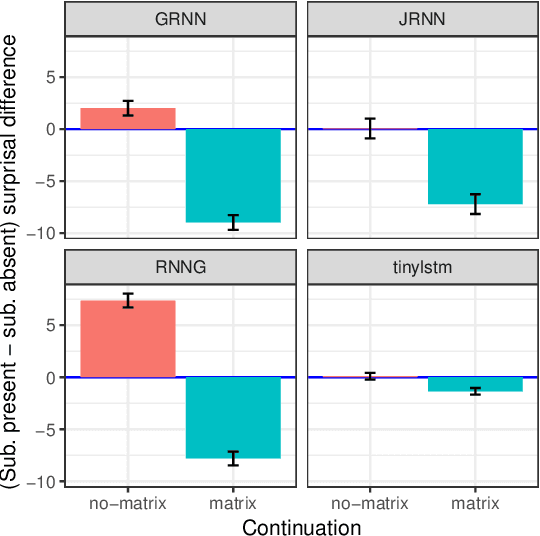


We deploy the methods of controlled psycholinguistic experimentation to shed light on the extent to which the behavior of neural network language models reflects incremental representations of syntactic state. To do so, we examine model behavior on artificial sentences containing a variety of syntactically complex structures. We test four models: two publicly available LSTM sequence models of English (Jozefowicz et al., 2016; Gulordava et al., 2018) trained on large datasets; an RNNG (Dyer et al., 2016) trained on a small, parsed dataset; and an LSTM trained on the same small corpus as the RNNG. We find evidence that the LSTMs trained on large datasets represent syntactic state over large spans of text in a way that is comparable to the RNNG, while the LSTM trained on the small dataset does not or does so only weakly.
Recursive Subtree Composition in LSTM-Based Dependency Parsing
Feb 26, 2019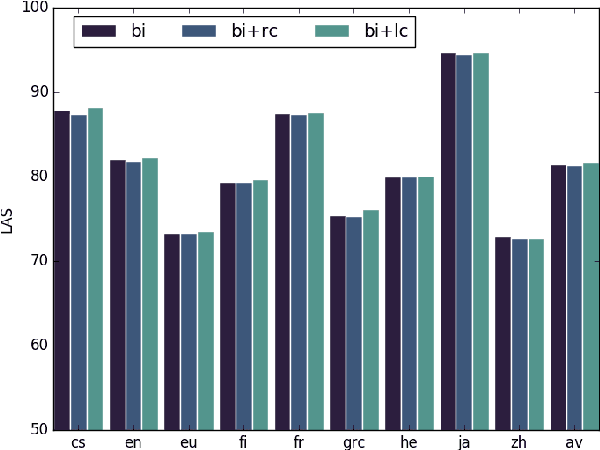
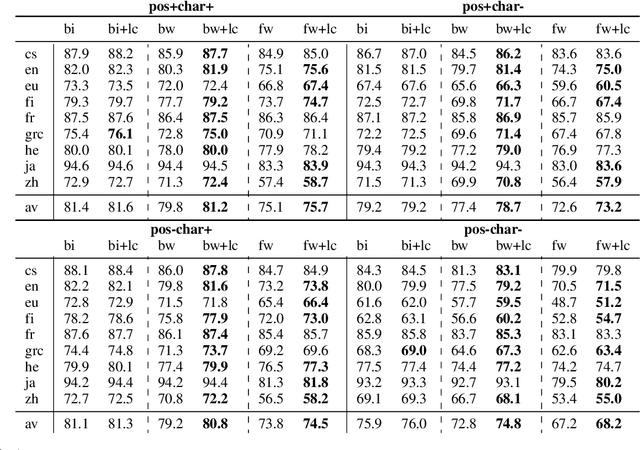
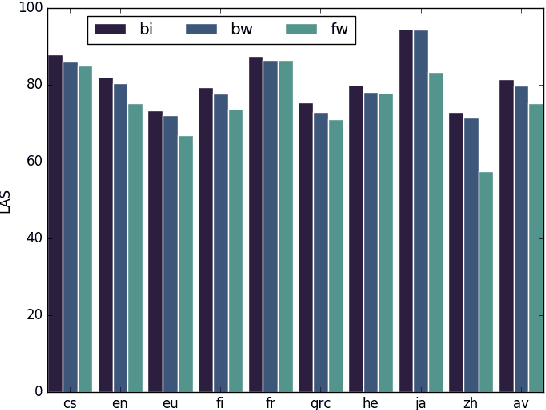
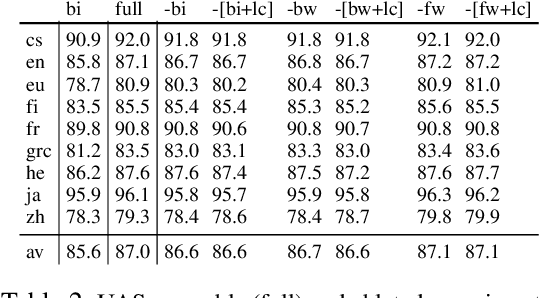
The need for tree structure modelling on top of sequence modelling is an open issue in neural dependency parsing. We investigate the impact of adding a tree layer on top of a sequential model by recursively composing subtree representations (composition) in a transition-based parser that uses features extracted by a BiLSTM. Composition seems superfluous with such a model, suggesting that BiLSTMs capture information about subtrees. We perform model ablations to tease out the conditions under which composition helps. When ablating the backward LSTM, performance drops and composition does not recover much of the gap. When ablating the forward LSTM, performance drops less dramatically and composition recovers a substantial part of the gap, indicating that a forward LSTM and composition capture similar information. We take the backward LSTM to be related to lookahead features and the forward LSTM to the rich history-based features both crucial for transition-based parsers. To capture history-based information, composition is better than a forward LSTM on its own, but it is even better to have a forward LSTM as part of a BiLSTM. We correlate results with language properties, showing that the improved lookahead of a backward LSTM is especially important for head-final languages.
Greedy, Joint Syntactic-Semantic Parsing with Stack LSTMs
Jul 05, 2018


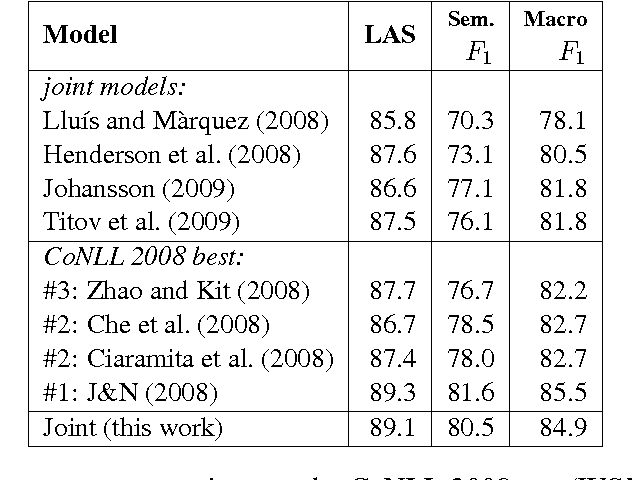
We present a transition-based parser that jointly produces syntactic and semantic dependencies. It learns a representation of the entire algorithm state, using stack long short-term memories. Our greedy inference algorithm has linear time, including feature extraction. On the CoNLL 2008--9 English shared tasks, we obtain the best published parsing performance among models that jointly learn syntax and semantics.
Multilingual Neural Machine Translation with Task-Specific Attention
Jun 08, 2018
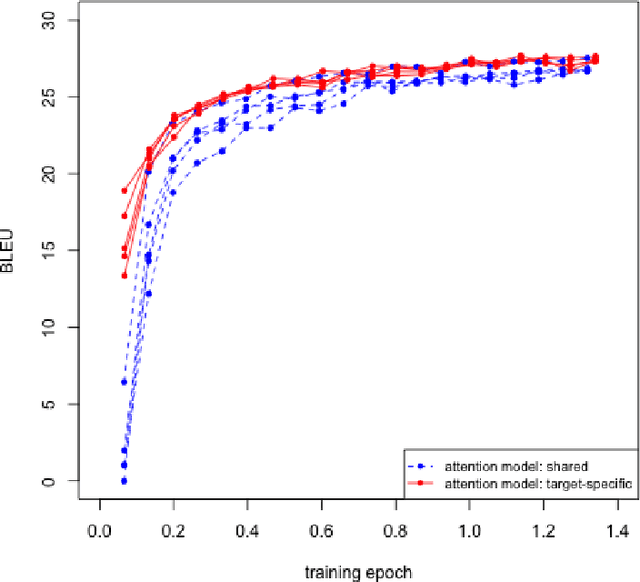
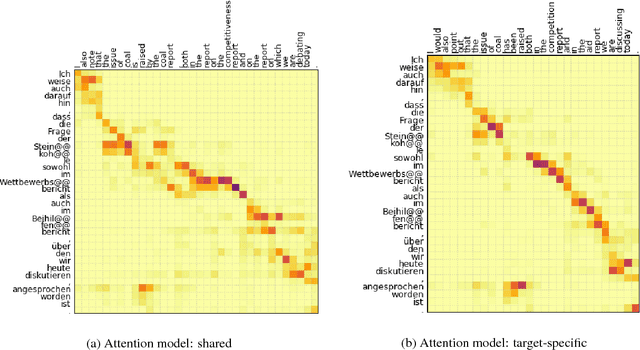
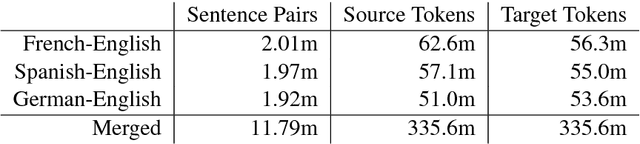
Multilingual machine translation addresses the task of translating between multiple source and target languages. We propose task-specific attention models, a simple but effective technique for improving the quality of sequence-to-sequence neural multilingual translation. Our approach seeks to retain as much of the parameter sharing generalization of NMT models as possible, while still allowing for language-specific specialization of the attention model to a particular language-pair or task. Our experiments on four languages of the Europarl corpus show that using a target-specific model of attention provides consistent gains in translation quality for all possible translation directions, compared to a model in which all parameters are shared. We observe improved translation quality even in the (extreme) low-resource zero-shot translation directions for which the model never saw explicitly paired parallel data.
Scheduled Multi-Task Learning: From Syntax to Translation
Apr 24, 2018Neural encoder-decoder models of machine translation have achieved impressive results, while learning linguistic knowledge of both the source and target languages in an implicit end-to-end manner. We propose a framework in which our model begins learning syntax and translation interleaved, gradually putting more focus on translation. Using this approach, we achieve considerable improvements in terms of BLEU score on relatively large parallel corpus (WMT14 English to German) and a low-resource (WIT German to English) setup.
Multimodal Emoji Prediction
Apr 17, 2018
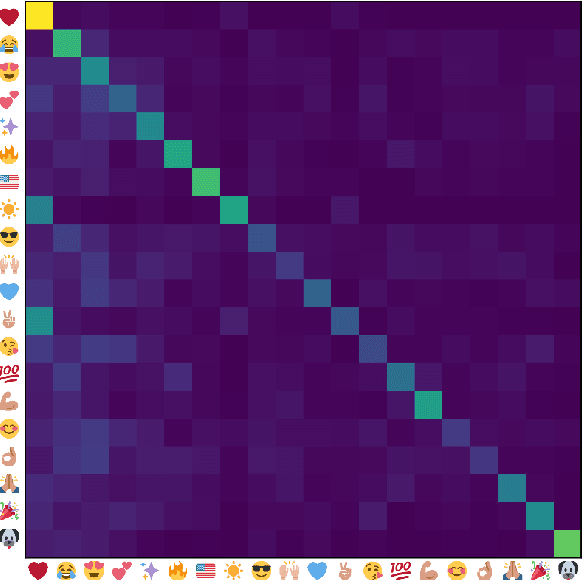
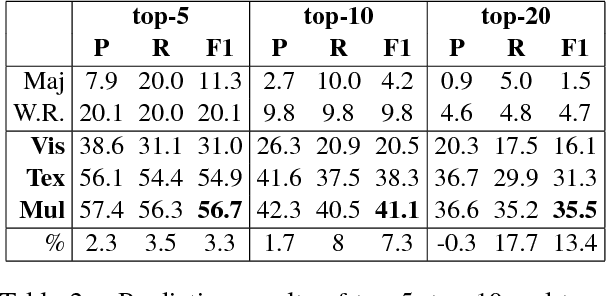

Emojis are small images that are commonly included in social media text messages. The combination of visual and textual content in the same message builds up a modern way of communication, that automatic systems are not used to deal with. In this paper we extend recent advances in emoji prediction by putting forward a multimodal approach that is able to predict emojis in Instagram posts. Instagram posts are composed of pictures together with texts which sometimes include emojis. We show that these emojis can be predicted by using the text, but also using the picture. Our main finding is that incorporating the two synergistic modalities, in a combined model, improves accuracy in an emoji prediction task. This result demonstrates that these two modalities (text and images) encode different information on the use of emojis and therefore can complement each other.
Pieces of Eight: 8-bit Neural Machine Translation
Apr 13, 2018

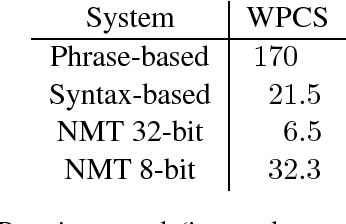
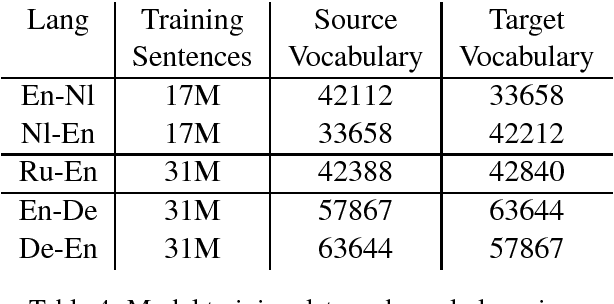
Neural machine translation has achieved levels of fluency and adequacy that would have been surprising a short time ago. Output quality is extremely relevant for industry purposes, however it is equally important to produce results in the shortest time possible, mainly for latency-sensitive applications and to control cloud hosting costs. In this paper we show the effectiveness of translating with 8-bit quantization for models that have been trained using 32-bit floating point values. Results show that 8-bit translation makes a non-negligible impact in terms of speed with no degradation in accuracy and adequacy.