 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Ontology-Enhanced Representation Learning for Large Language Models
May 30, 2024



Taking advantage of the widespread use of ontologies to organise and harmonize knowledge across several distinct domains, this paper proposes a novel approach to improve an embedding-Large Language Model (embedding-LLM) of interest by infusing the knowledge formalized by a reference ontology: ontological knowledge infusion aims at boosting the ability of the considered LLM to effectively model the knowledge domain described by the infused ontology. The linguistic information (i.e. concept synonyms and descriptions) and structural information (i.e. is-a relations) formalized by the ontology are utilized to compile a comprehensive set of concept definitions, with the assistance of a powerful generative LLM (i.e. GPT-3.5-turbo). These concept definitions are then employed to fine-tune the target embedding-LLM using a contrastive learning framework. To demonstrate and evaluate the proposed approach, we utilize the biomedical disease ontology MONDO. The results show that embedding-LLMs enhanced by ontological disease knowledge exhibit an improved capability to effectively evaluate the similarity of in-domain sentences from biomedical documents mentioning diseases, without compromising their out-of-domain performance.
Multimodal Emoji Prediction
Apr 17, 2018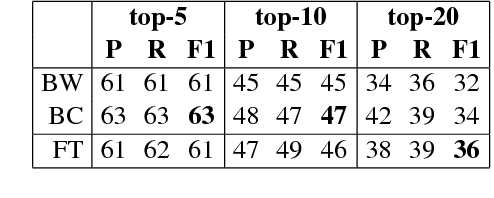
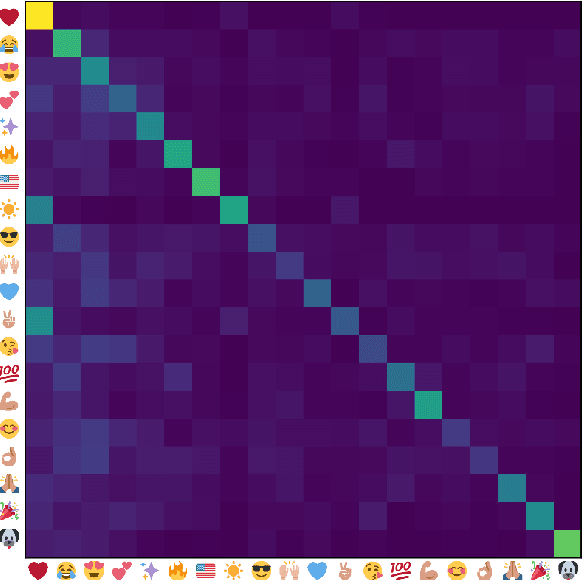
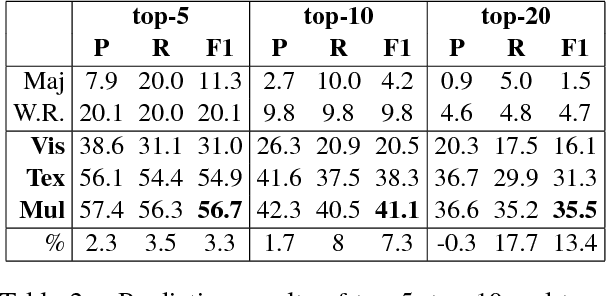

Emojis are small images that are commonly included in social media text messages. The combination of visual and textual content in the same message builds up a modern way of communication, that automatic systems are not used to deal with. In this paper we extend recent advances in emoji prediction by putting forward a multimodal approach that is able to predict emojis in Instagram posts. Instagram posts are composed of pictures together with texts which sometimes include emojis. We show that these emojis can be predicted by using the text, but also using the picture. Our main finding is that incorporating the two synergistic modalities, in a combined model, improves accuracy in an emoji prediction task. This result demonstrates that these two modalities (text and images) encode different information on the use of emojis and therefore can complement each other.
DefExt: A Semi Supervised Definition Extraction Tool
Jun 08, 2016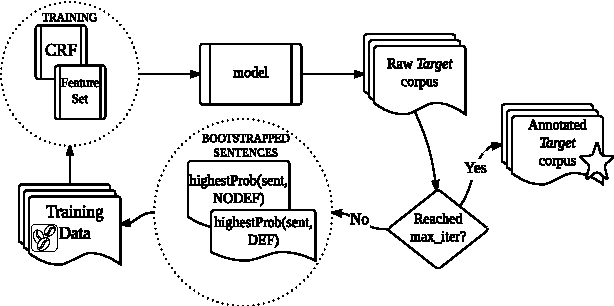
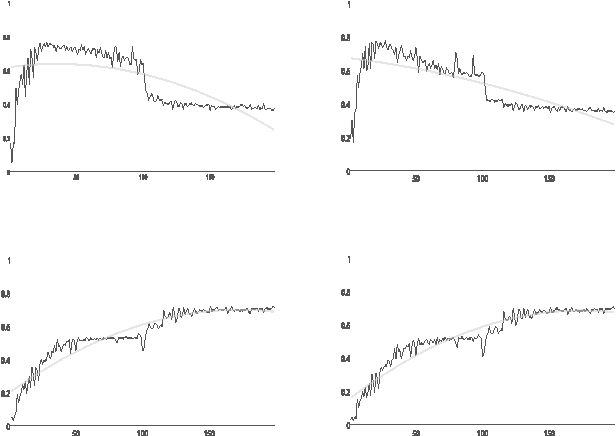

We present DefExt, an easy to use semi supervised Definition Extraction Tool. DefExt is designed to extract from a target corpus those textual fragments where a term is explicitly mentioned together with its core features, i.e. its definition. It works on the back of a Conditional Random Fields based sequential labeling algorithm and a bootstrapping approach. Bootstrapping enables the model to gradually become more aware of the idiosyncrasies of the target corpus. In this paper we describe the main components of the toolkit as well as experimental results stemming from both automatic and manual evaluation. We release DefExt as open source along with the necessary files to run it in any Unix machine. We also provide access to training and test data for immediate use.