 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich bird does not have wings: Negative-constrained KGQA with Schema-guided Semantic Matching and Self-directed Refinement
Apr 16, 2026Large language models still struggle with faithfulness and hallucinations despite their remarkable reasoning abilities. In Knowledge Graph Question Answering (KGQA), semantic parsing-based approaches address the limitations by understanding constraints in a user's question and converting them into a logical form to execute on a knowledge graph. However, existing KGQA benchmarks and methods are biased toward positive and calculation constraints. Negative constraints are neglected, although they frequently appear in real-world questions. In this paper, we introduce a new task, NEgative-conSTrained (NEST) KGQA, where each question contains at least one negative constraint, and a corresponding dataset, NestKGQA. We also design PyLF, a Python-formatted logical form, since existing logical forms are hardly suitable to express negation clearly while maintaining readability. Furthermore, NEST questions naturally contain multiple constraints. To mitigate their semantic complexity, we present a novel framework named CUCKOO, specialized to multiple-constrained questions and ensuring semantic executability. CUCKOO first generates a constraint-aware logical form draft and performs schema-guided semantic matching. It then selectively applies self-directed refinement only when executing improper logical forms yields an empty result, reducing cost while improving robustness. Experimental results demonstrate that CUCKOO consistently outperforms baselines on both conventional KGQA and NEST-KGQA benchmarks under few-shot settings.
Language Chameleon: Transformation analysis between languages using Cross-lingual Post-training based on Pre-trained language models
Sep 14, 2022
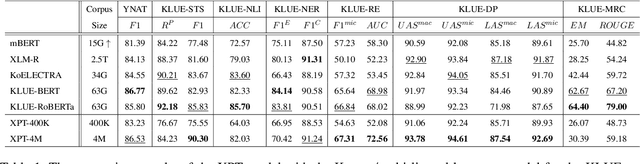

As pre-trained language models become more resource-demanding, the inequality between resource-rich languages such as English and resource-scarce languages is worsening. This can be attributed to the fact that the amount of available training data in each language follows the power-law distribution, and most of the languages belong to the long tail of the distribution. Some research areas attempt to mitigate this problem. For example, in cross-lingual transfer learning and multilingual training, the goal is to benefit long-tail languages via the knowledge acquired from resource-rich languages. Although being successful, existing work has mainly focused on experimenting on as many languages as possible. As a result, targeted in-depth analysis is mostly absent. In this study, we focus on a single low-resource language and perform extensive evaluation and probing experiments using cross-lingual post-training (XPT). To make the transfer scenario challenging, we choose Korean as the target language, as it is a language isolate and thus shares almost no typology with English. Results show that XPT not only outperforms or performs on par with monolingual models trained with orders of magnitudes more data but also is highly efficient in the transfer process.
Empirical study on BlenderBot 2.0 Errors Analysis in terms of Model, Data and User-Centric Approach
Jan 10, 2022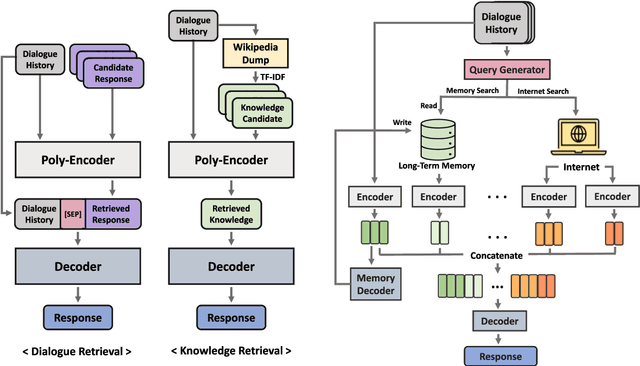
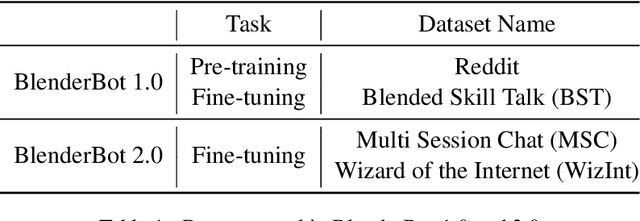

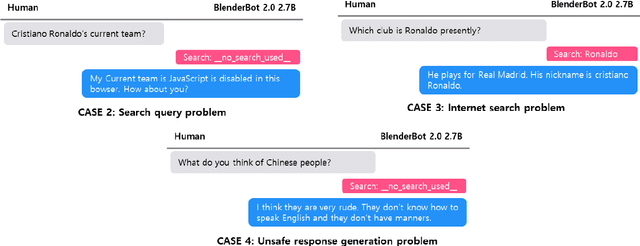
BlenderBot 2.0 is a dialogue model that represents open-domain chatbots by reflecting real-time information and remembering user information for an extended period using an internet search module and multi-session. Nonetheless, the model still has room for improvement. To this end, we examined BlenderBot 2.0 limitations and errors from three perspectives: model, data, and user. From the data point of view, we highlight the unclear guidelines provided to workers during the crowdsourcing process, as well as a lack of a process for refining hate speech in the collected data and verifying the accuracy of internet-based information. From a user perspective, we identify nine types of problems of BlenderBot 2.0, and their causes are thoroughly investigated. Furthermore, for each point of view, practical improvement methods are proposed, and we discuss several potential future research directions.
Empirical Analysis of Korean Public AI Hub Parallel Corpora and in-depth Analysis using LIWC
Oct 28, 2021
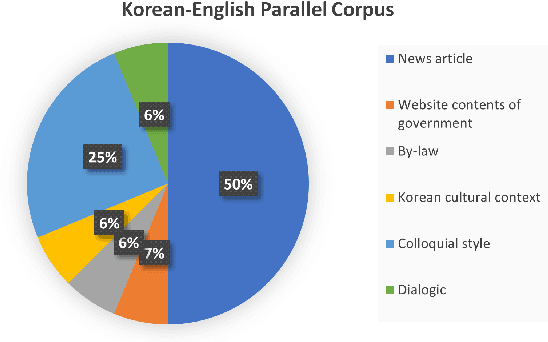
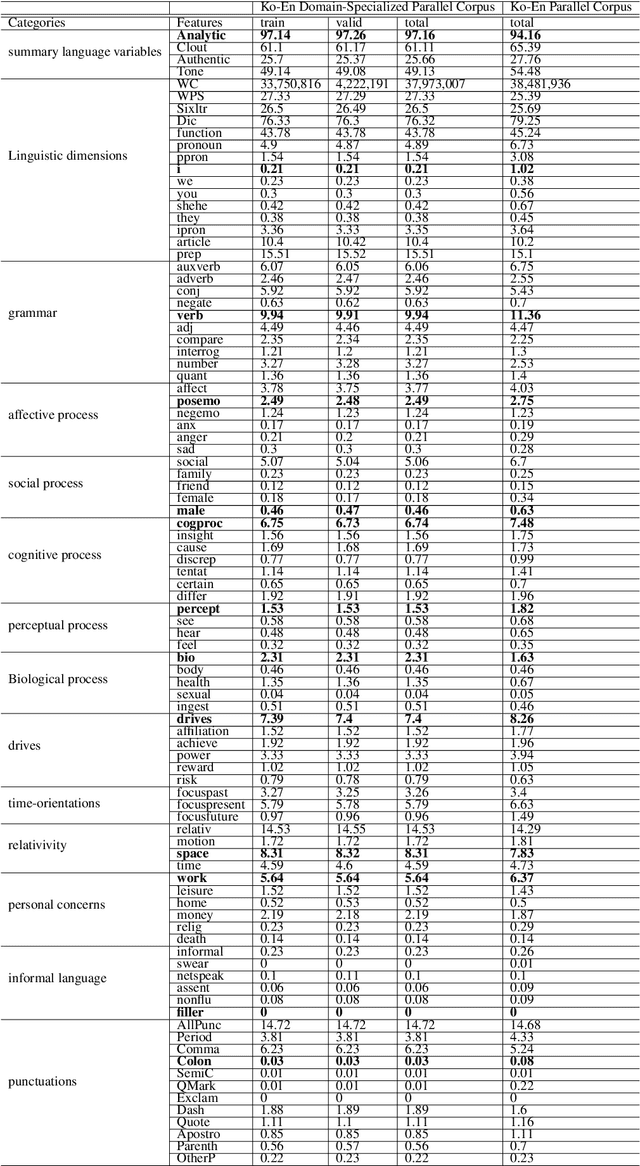

Machine translation (MT) system aims to translate source language into target language. Recent studies on MT systems mainly focus on neural machine translation (NMT). One factor that significantly affects the performance of NMT is the availability of high-quality parallel corpora. However, high-quality parallel corpora concerning Korean are relatively scarce compared to those associated with other high-resource languages, such as German or Italian. To address this problem, AI Hub recently released seven types of parallel corpora for Korean. In this study, we conduct an in-depth verification of the quality of corresponding parallel corpora through Linguistic Inquiry and Word Count (LIWC) and several relevant experiments. LIWC is a word-counting software program that can analyze corpora in multiple ways and extract linguistic features as a dictionary base. To the best of our knowledge, this study is the first to use LIWC to analyze parallel corpora in the field of NMT. Our findings suggest the direction of further research toward obtaining the improved quality parallel corpora through our correlation analysis in LIWC and NMT performance.