 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBMFM-RNA: An Open Framework for Building and Evaluating Transcriptomic Foundation Models
Jun 17, 2025



Transcriptomic foundation models (TFMs) have recently emerged as powerful tools for analyzing gene expression in cells and tissues, supporting key tasks such as cell-type annotation, batch correction, and perturbation prediction. However, the diversity of model implementations and training strategies across recent TFMs, though promising, makes it challenging to isolate the contribution of individual design choices or evaluate their potential synergies. This hinders the field's ability to converge on best practices and limits the reproducibility of insights across studies. We present BMFM-RNA, an open-source, modular software package that unifies diverse TFM pretraining and fine-tuning objectives within a single framework. Leveraging this capability, we introduce a novel training objective, whole cell expression decoder (WCED), which captures global expression patterns using an autoencoder-like CLS bottleneck representation. In this paper, we describe the framework, supported input representations, and training objectives. We evaluated four model checkpoints pretrained on CELLxGENE using combinations of masked language modeling (MLM), WCED and multitask learning. Using the benchmarking capabilities of BMFM-RNA, we show that WCED-based models achieve performance that matches or exceeds state-of-the-art approaches like scGPT across more than a dozen datasets in both zero-shot and fine-tuning tasks. BMFM-RNA, available as part of the biomed-multi-omics project ( https://github.com/BiomedSciAI/biomed-multi-omic ), offers a reproducible foundation for systematic benchmarking and community-driven exploration of optimal TFM training strategies, enabling the development of more effective tools to leverage the latest advances in AI for understanding cell biology.
MAMMAL -- Molecular Aligned Multi-Modal Architecture and Language
Oct 28, 2024Drug discovery typically consists of multiple steps, including identifying a target protein key to a disease's etiology, validating that interacting with this target could prevent symptoms or cure the disease, discovering a small molecule or biologic therapeutic to interact with it, and optimizing the candidate molecule through a complex landscape of required properties. Drug discovery related tasks often involve prediction and generation while considering multiple entities that potentially interact, which poses a challenge for typical AI models. For this purpose we present MAMMAL - Molecular Aligned Multi-Modal Architecture and Language - a method that we applied to create a versatile multi-task foundation model ibm/biomed.omics.bl.sm.ma-ted-458m that learns from large-scale biological datasets (2 billion samples) across diverse modalities, including proteins, small molecules, and genes. We introduce a prompt syntax that supports a wide range of classification, regression, and generation tasks. It allows combining different modalities and entity types as inputs and/or outputs. Our model handles combinations of tokens and scalars and enables the generation of small molecules and proteins, property prediction, and transcriptomic lab test predictions. We evaluated the model on 11 diverse downstream tasks spanning different steps within a typical drug discovery pipeline, where it reaches new SOTA in 9 tasks and is comparable to SOTA in 2 tasks. This performance is achieved while using a unified architecture serving all tasks, in contrast to the original SOTA performance achieved using tailored architectures. The model code and pretrained weights are publicly available at https://github.com/BiomedSciAI/biomed-multi-alignment and https://huggingface.co/ibm/biomed.omics.bl.sm.ma-ted-458m.
AI Age Discrepancy: A Novel Parameter for Frailty Assessment in Kidney Tumor Patients
Jul 02, 2024Kidney cancer is a global health concern, and accurate assessment of patient frailty is crucial for optimizing surgical outcomes. This paper introduces AI Age Discrepancy, a novel metric derived from machine learning analysis of preoperative abdominal CT scans, as a potential indicator of frailty and postoperative risk in kidney cancer patients. This retrospective study of 599 patients from the 2023 Kidney Tumor Segmentation (KiTS) challenge dataset found that a higher AI Age Discrepancy is significantly associated with longer hospital stays and lower overall survival rates, independent of established factors. This suggests that AI Age Discrepancy may provide valuable insights into patient frailty and could thus inform clinical decision-making in kidney cancer treatment.
WNTRAC: Artificial Intelligence Assisted Tracking of Non-pharmaceutical Interventions Implemented Worldwide for COVID-19
Sep 16, 2020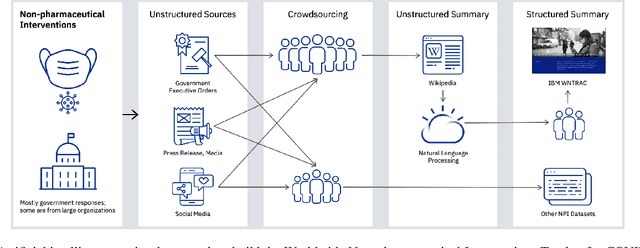
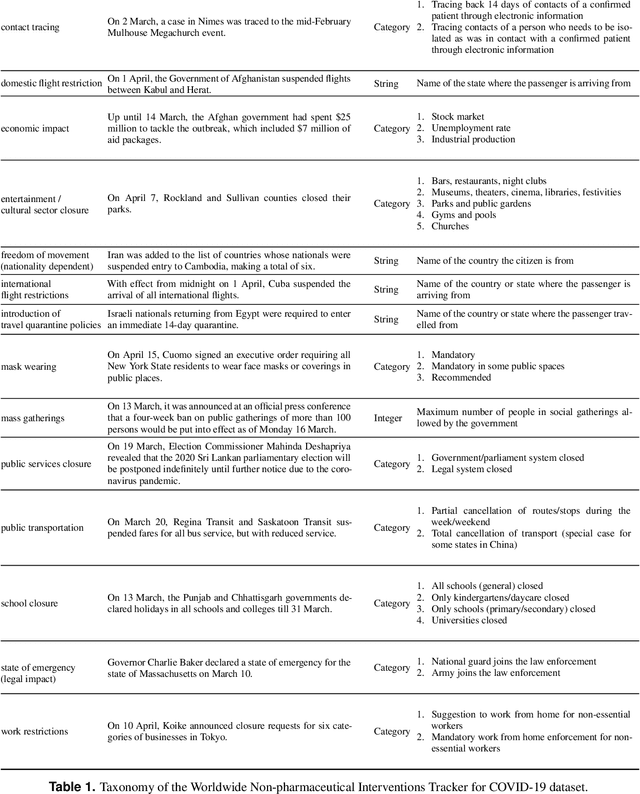


The Coronavirus disease 2019 (COVID-19) global pandemic has transformed almost every facet of human society throughout the world. Against an emerging, highly transmissible disease with no definitive treatment or vaccine, governments worldwide have implemented non-pharmaceutical intervention (NPI) to slow the spread of the virus. Examples of such interventions include community actions (e.g. school closures, restrictions on mass gatherings), individual actions (e.g. mask wearing, self-quarantine), and environmental actions (e.g. public facility cleaning). We present the Worldwide Non-pharmaceutical Interventions Tracker for COVID-19 (WNTRAC), a comprehensive dataset consisting of over 6,000 NPIs implemented worldwide since the start of the pandemic. WNTRAC covers NPIs implemented across 261 countries and territories, and classifies NPI measures into a taxonomy of sixteen NPI types. NPI measures are automatically extracted daily from Wikipedia articles using natural language processing techniques and manually validated to ensure accuracy and veracity. We hope that the dataset is valuable for policymakers, public health leaders, and researchers in modeling and analysis efforts for controlling the spread of COVID-19.
Novel Uncertainty Framework for Deep Learning Ensembles
Apr 09, 2019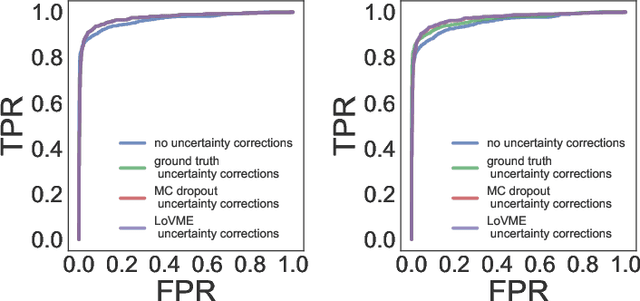
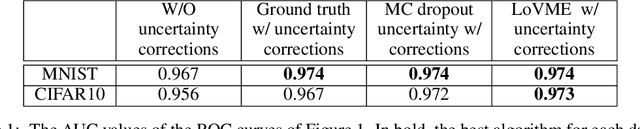
Deep neural networks have become the default choice for many of the machine learning tasks such as classification and regression. Dropout, a method commonly used to improve the convergence of deep neural networks, generates an ensemble of thinned networks with extensive weight sharing. Recent studies that dropout can be viewed as an approximate variational inference in Gaussian processes, and used as a practical tool to obtain uncertainty estimates of the network. We propose a novel statistical mechanics based framework to dropout and use this framework to propose a new generic algorithm that focuses on estimates of the variance of the loss as measured by the ensemble of thinned networks. Our approach can be applied to a wide range of deep neural network architectures and machine learning tasks. In classification, this algorithm allows the generation of a don't-know answer to be generated, which can increase the reliability of the classifier. Empirically we demonstrate state-of-the-art AUC results on publicly available benchmarks.
The Author-Topic Model for Authors and Documents
Jul 11, 2012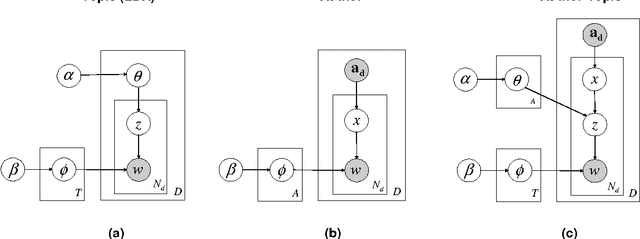
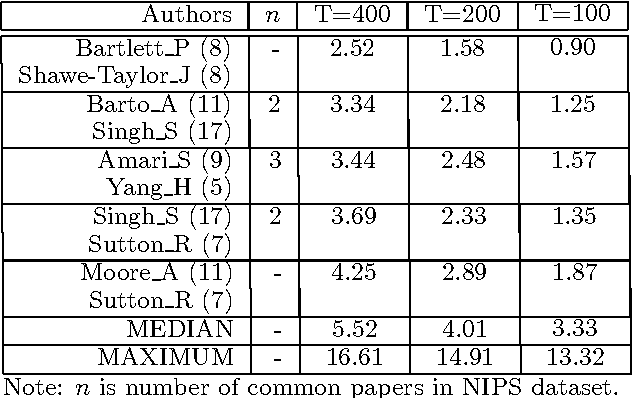
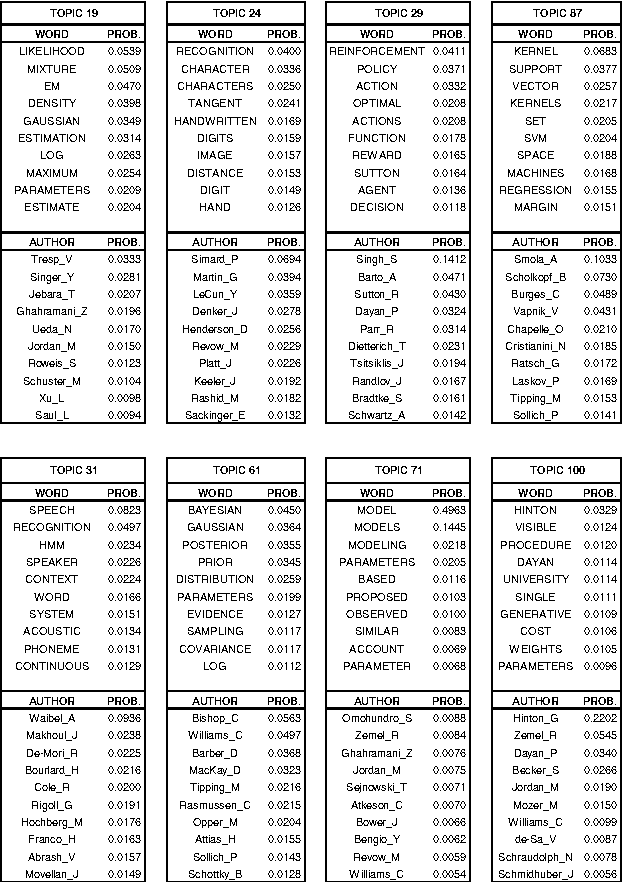
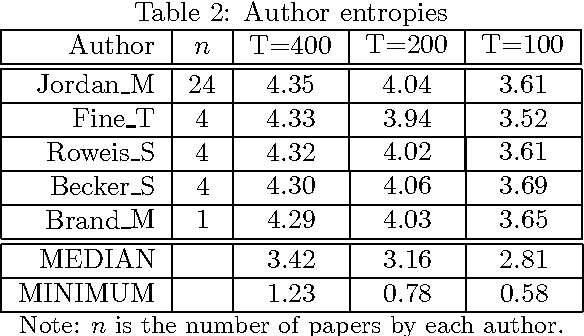
We introduce the author-topic model, a generative model for documents that extends Latent Dirichlet Allocation (LDA; Blei, Ng, & Jordan, 2003) to include authorship information. Each author is associated with a multinomial distribution over topics and each topic is associated with a multinomial distribution over words. A document with multiple authors is modeled as a distribution over topics that is a mixture of the distributions associated with the authors. We apply the model to a collection of 1,700 NIPS conference papers and 160,000 CiteSeer abstracts. Exact inference is intractable for these datasets and we use Gibbs sampling to estimate the topic and author distributions. We compare the performance with two other generative models for documents, which are special cases of the author-topic model: LDA (a topic model) and a simple author model in which each author is associated with a distribution over words rather than a distribution over topics. We show topics recovered by the author-topic model, and demonstrate applications to computing similarity between authors and entropy of author output.
The DLR Hierarchy of Approximate Inference
Jul 04, 2012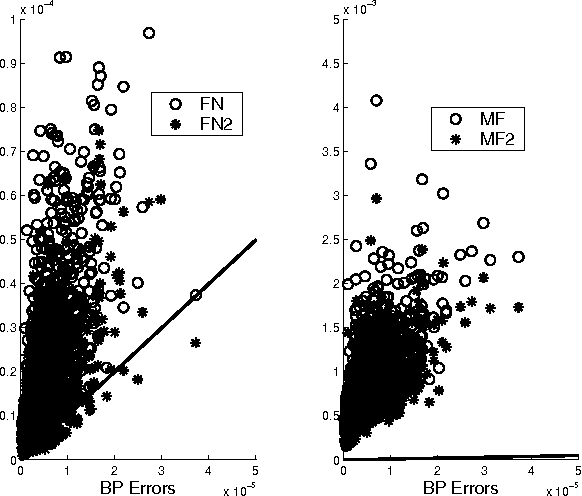
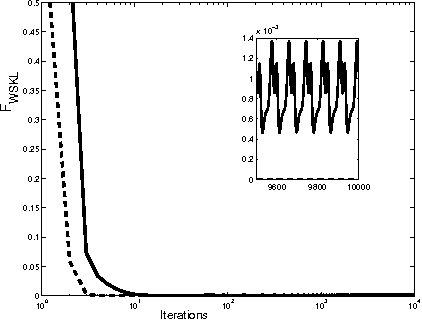
We propose a hierarchy for approximate inference based on the Dobrushin, Lanford, Ruelle (DLR) equations. This hierarchy includes existing algorithms, such as belief propagation, and also motivates novel algorithms such as factorized neighbors (FN) algorithms and variants of mean field (MF) algorithms. In particular, we show that extrema of the Bethe free energy correspond to approximate solutions of the DLR equations. In addition, we demonstrate a close connection between these approximate algorithms and Gibbs sampling. Finally, we compare and contrast various of the algorithms in the DLR hierarchy on spin-glass problems. The experiments show that algorithms higher up in the hierarchy give more accurate results when they converge but tend to be less stable.
Latent Topic Models for Hypertext
Jun 13, 2012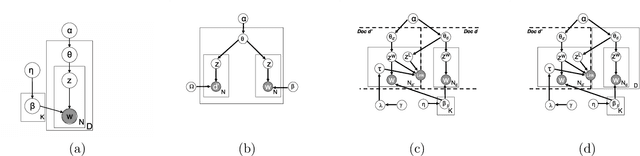


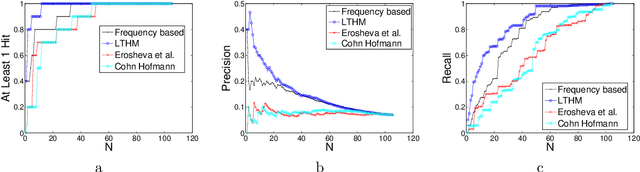
Latent topic models have been successfully applied as an unsupervised topic discovery technique in large document collections. With the proliferation of hypertext document collection such as the Internet, there has also been great interest in extending these approaches to hypertext [6, 9]. These approaches typically model links in an analogous fashion to how they model words - the document-link co-occurrence matrix is modeled in the same way that the document-word co-occurrence matrix is modeled in standard topic models. In this paper we present a probabilistic generative model for hypertext document collections that explicitly models the generation of links. Specifically, links from a word w to a document d depend directly on how frequent the topic of w is in d, in addition to the in-degree of d. We show how to perform EM learning on this model efficiently. By not modeling links as analogous to words, we end up using far fewer free parameters and obtain better link prediction results.