 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropic Spectral Learning in Large Scale Networks
Apr 18, 2018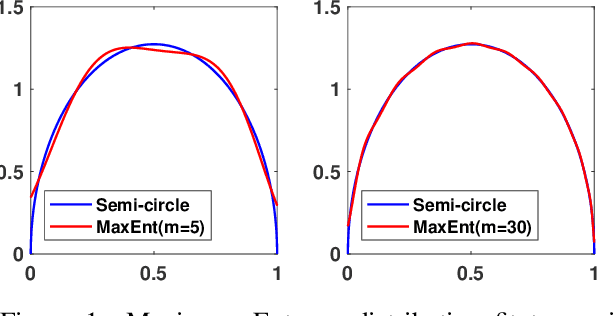

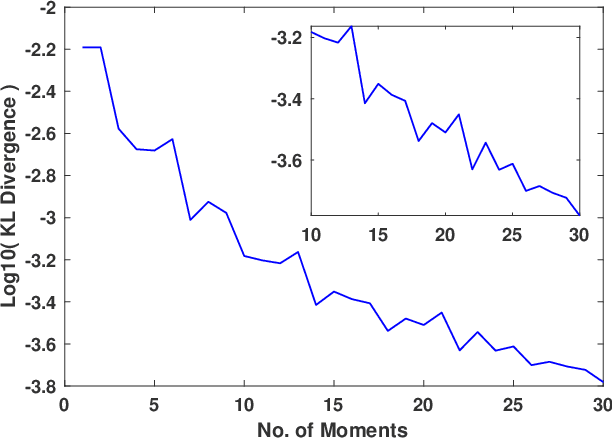
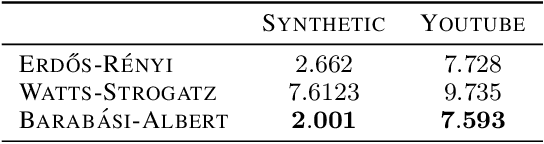
We present a novel algorithm for learning the spectral density of large scale networks using stochastic trace estimation and the method of maximum entropy. The complexity of the algorithm is linear in the number of non-zero elements of the matrix, offering a computational advantage over other algorithms. We apply our algorithm to the problem of community detection in large networks. We show state-of-the-art performance on both synthetic and real datasets.
VBALD - Variational Bayesian Approximation of Log Determinants
Feb 21, 2018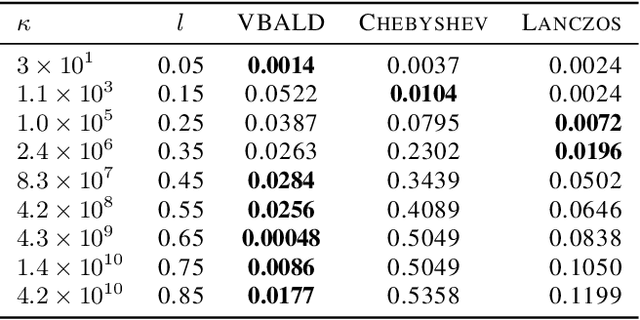
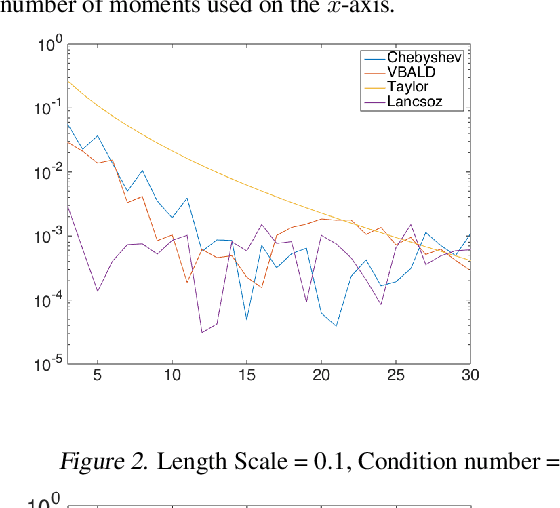
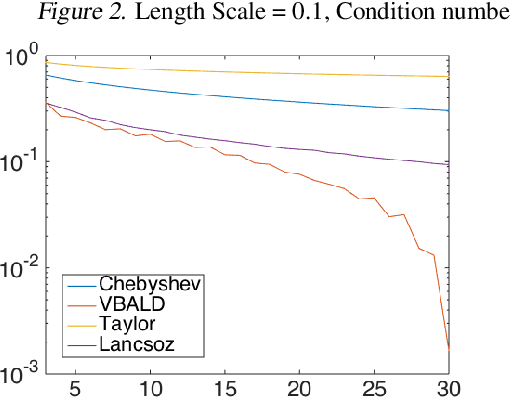

Evaluating the log determinant of a positive definite matrix is ubiquitous in machine learning. Applications thereof range from Gaussian processes, minimum-volume ellipsoids, metric learning, kernel learning, Bayesian neural networks, Determinental Point Processes, Markov random fields to partition functions of discrete graphical models. In order to avoid the canonical, yet prohibitive, Cholesky $\mathcal{O}(n^{3})$ computational cost, we propose a novel approach, with complexity $\mathcal{O}(n^{2})$, based on a constrained variational Bayes algorithm. We compare our method to Taylor, Chebyshev and Lanczos approaches and show state of the art performance on both synthetic and real-world datasets.
Sensor Selection and Random Field Reconstruction for Robust and Cost-effective Heterogeneous Weather Sensor Networks for the Developing World
Nov 23, 2017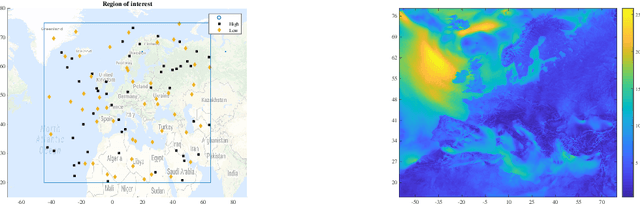
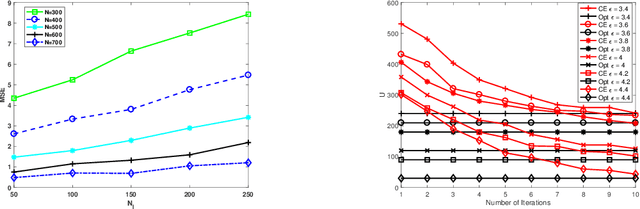
We address the two fundamental problems of spatial field reconstruction and sensor selection in heterogeneous sensor networks: (i) how to efficiently perform spatial field reconstruction based on measurements obtained simultaneously from networks with both high and low quality sensors; and (ii) how to perform query based sensor set selection with predictive MSE performance guarantee. For the first problem, we developed a low complexity algorithm based on the spatial best linear unbiased estimator (S-BLUE). Next, building on the S-BLUE, we address the second problem, and develop an efficient algorithm for query based sensor set selection with performance guarantee. Our algorithm is based on the Cross Entropy method which solves the combinatorial optimization problem in an efficient manner.
Entropic Trace Estimates for Log Determinants
Apr 24, 2017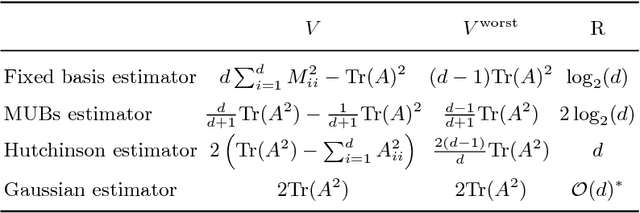
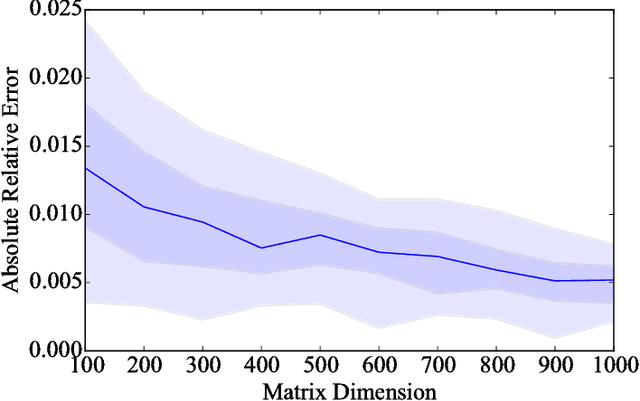
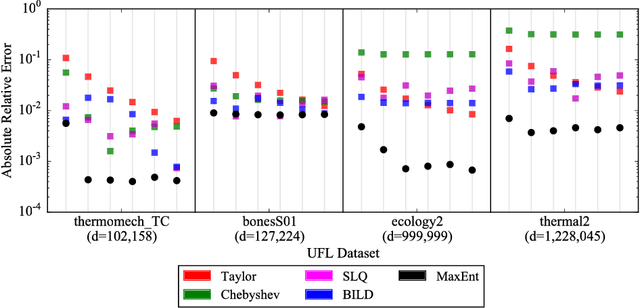
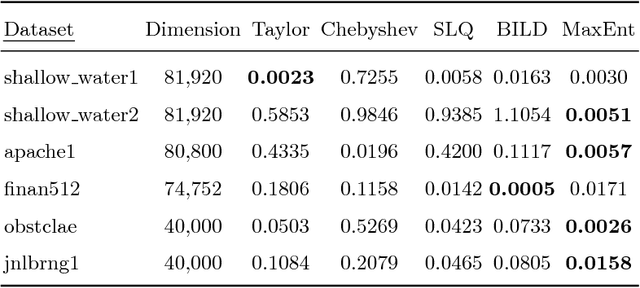
The scalable calculation of matrix determinants has been a bottleneck to the widespread application of many machine learning methods such as determinantal point processes, Gaussian processes, generalised Markov random fields, graph models and many others. In this work, we estimate log determinants under the framework of maximum entropy, given information in the form of moment constraints from stochastic trace estimation. The estimates demonstrate a significant improvement on state-of-the-art alternative methods, as shown on a wide variety of UFL sparse matrices. By taking the example of a general Markov random field, we also demonstrate how this approach can significantly accelerate inference in large-scale learning methods involving the log determinant.
Bayesian Inference of Log Determinants
Apr 05, 2017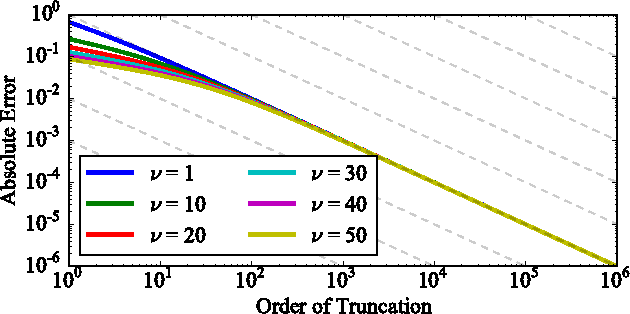
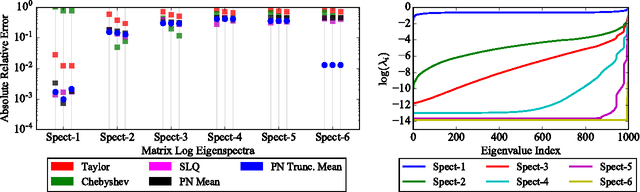
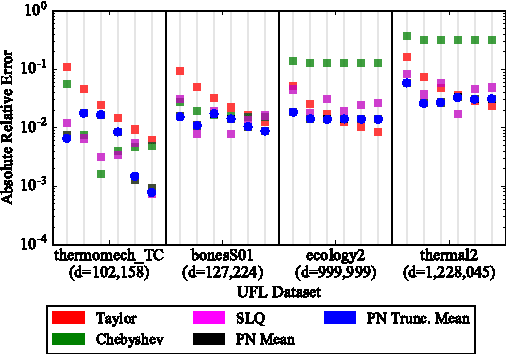
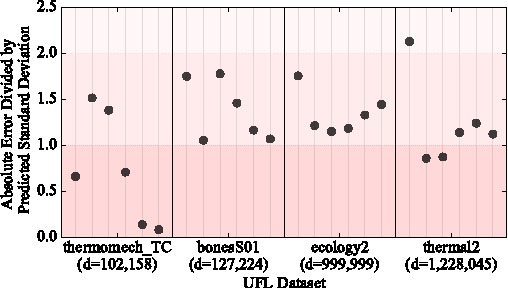
The log-determinant of a kernel matrix appears in a variety of machine learning problems, ranging from determinantal point processes and generalized Markov random fields, through to the training of Gaussian processes. Exact calculation of this term is often intractable when the size of the kernel matrix exceeds a few thousand. In the spirit of probabilistic numerics, we reinterpret the problem of computing the log-determinant as a Bayesian inference problem. In particular, we combine prior knowledge in the form of bounds from matrix theory and evidence derived from stochastic trace estimation to obtain probabilistic estimates for the log-determinant and its associated uncertainty within a given computational budget. Beyond its novelty and theoretic appeal, the performance of our proposal is competitive with state-of-the-art approaches to approximating the log-determinant, while also quantifying the uncertainty due to budget-constrained evidence.
GLASSES: Relieving The Myopia Of Bayesian Optimisation
Oct 21, 2015
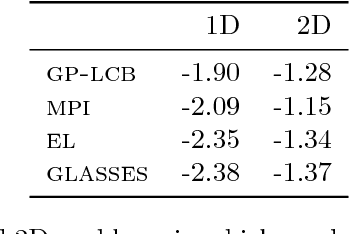
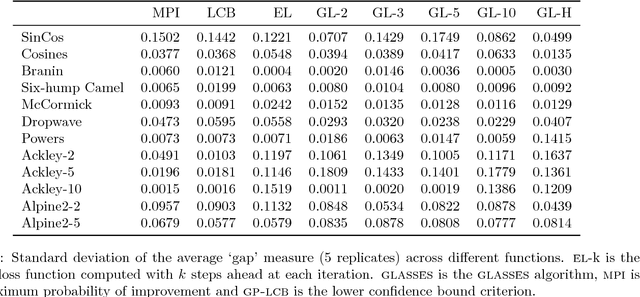
We present GLASSES: Global optimisation with Look-Ahead through Stochastic Simulation and Expected-loss Search. The majority of global optimisation approaches in use are myopic, in only considering the impact of the next function value; the non-myopic approaches that do exist are able to consider only a handful of future evaluations. Our novel algorithm, GLASSES, permits the consideration of dozens of evaluations into the future. This is done by approximating the ideal look-ahead loss function, which is expensive to evaluate, by a cheaper alternative in which the future steps of the algorithm are simulated beforehand. An Expectation Propagation algorithm is used to compute the expected value of the loss.We show that the far-horizon planning thus enabled leads to substantive performance gains in empirical tests.
Anomaly Detection and Removal Using Non-Stationary Gaussian Processes
Jul 02, 2015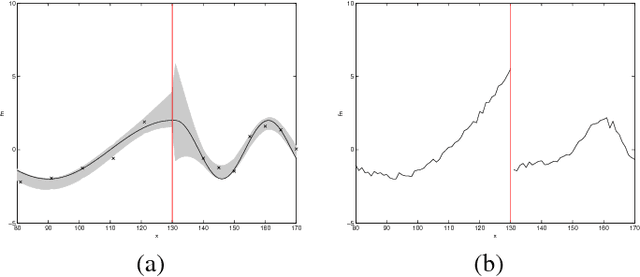
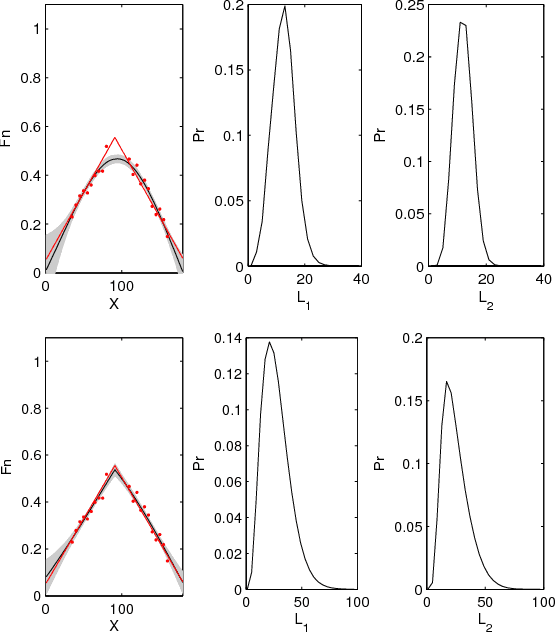
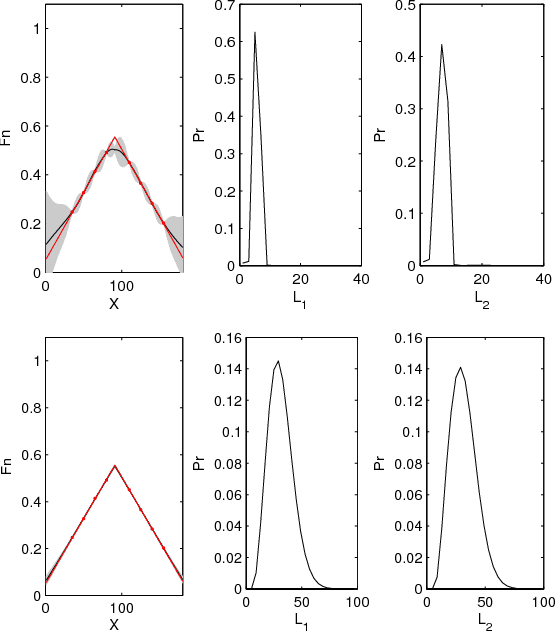
This paper proposes a novel Gaussian process approach to fault removal in time-series data. Fault removal does not delete the faulty signal data but, instead, massages the fault from the data. We assume that only one fault occurs at any one time and model the signal by two separate non-parametric Gaussian process models for both the physical phenomenon and the fault. In order to facilitate fault removal we introduce the Markov Region Link kernel for handling non-stationary Gaussian processes. This kernel is piece-wise stationary but guarantees that functions generated by it and their derivatives (when required) are everywhere continuous. We apply this kernel to the removal of drift and bias errors in faulty sensor data and also to the recovery of EOG artifact corrupted EEG signals.
Conservative collision prediction and avoidance for stochastic trajectories in continuous time and space
May 12, 2014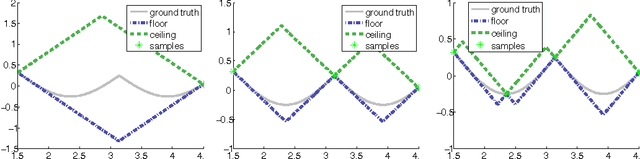

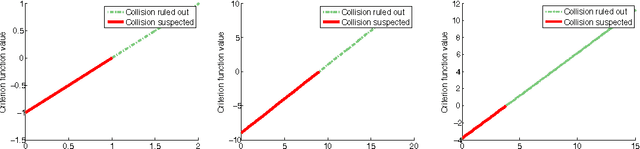
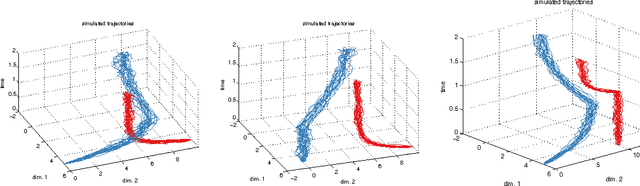
Existing work in multi-agent collision prediction and avoidance typically assumes discrete-time trajectories with Gaussian uncertainty or that are completely deterministic. We propose an approach that allows detection of collisions even between continuous, stochastic trajectories with the only restriction that means and variances can be computed. To this end, we employ probabilistic bounds to derive criterion functions whose negative sign provably is indicative of probable collisions. For criterion functions that are Lipschitz, an algorithm is provided to rapidly find negative values or prove their absence. We propose an iterative policy-search approach that avoids prior discretisations and yields collision-free trajectories with adjustably high certainty. We test our method with both fixed-priority and auction-based protocols for coordinating the iterative planning process. Results are provided in collision-avoidance simulations of feedback controlled plants.
Communication Communities in MOOCs
Apr 16, 2014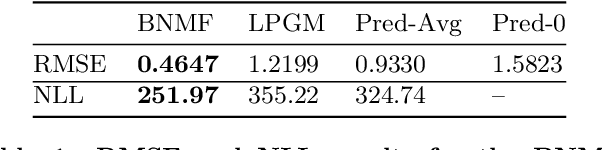
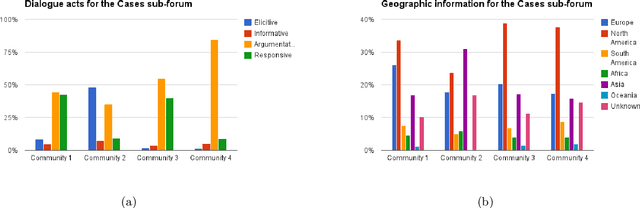
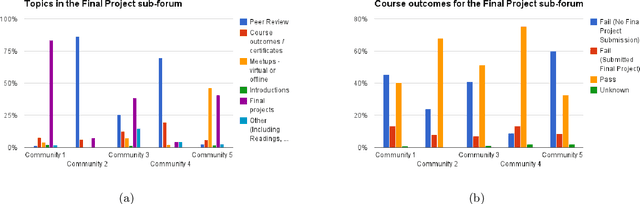
Massive Open Online Courses (MOOCs) bring together thousands of people from different geographies and demographic backgrounds -- but to date, little is known about how they learn or communicate. We introduce a new content-analysed MOOC dataset and use Bayesian Non-negative Matrix Factorization (BNMF) to extract communities of learners based on the nature of their online forum posts. We see that BNMF yields a superior probabilistic generative model for online discussions when compared to other models, and that the communities it learns are differentiated by their composite students' demographic and course performance indicators. These findings suggest that computationally efficient probabilistic generative modelling of MOOCs can reveal important insights for educational researchers and practitioners and help to develop more intelligent and responsive online learning environments.