 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracing the Influence of Predecessors on Trajectory Prediction
Aug 10, 2023In real-world traffic scenarios, agents such as pedestrians and car drivers often observe neighboring agents who exhibit similar behavior as examples and then mimic their actions to some extent in their own behavior. This information can serve as prior knowledge for trajectory prediction, which is unfortunately largely overlooked in current trajectory prediction models. This paper introduces a novel Predecessor-and-Successor (PnS) method that incorporates a predecessor tracing module to model the influence of predecessors (identified from concurrent neighboring agents) on the successor (target agent) within the same scene. The method utilizes the moving patterns of these predecessors to guide the predictor in trajectory prediction. PnS effectively aligns the motion encodings of the successor with multiple potential predecessors in a probabilistic manner, facilitating the decoding process. We demonstrate the effectiveness of PnS by integrating it into a graph-based predictor for pedestrian trajectory prediction on the ETH/UCY datasets, resulting in a new state-of-the-art performance. Furthermore, we replace the HD map-based scene-context module with our PnS method in a transformer-based predictor for vehicle trajectory prediction on the nuScenes dataset, showing that the predictor maintains good prediction performance even without relying on any map information.
Interactive Image Segmentation with Cross-Modality Vision Transformers
Jul 05, 2023



Interactive image segmentation aims to segment the target from the background with the manual guidance, which takes as input multimodal data such as images, clicks, scribbles, and bounding boxes. Recently, vision transformers have achieved a great success in several downstream visual tasks, and a few efforts have been made to bring this powerful architecture to interactive segmentation task. However, the previous works neglect the relations between two modalities and directly mock the way of processing purely visual information with self-attentions. In this paper, we propose a simple yet effective network for click-based interactive segmentation with cross-modality vision transformers. Cross-modality transformers exploits mutual information to better guide the learning process. The experiments on several benchmarks show that the proposed method achieves superior performance in comparison to the previous state-of-the-art models. The stability of our method in term of avoiding failure cases shows its potential to be a practical annotation tool. The code and pretrained models will be released under https://github.com/lik1996/iCMFormer.
Learning Similarity between Scene Graphs and Images with Transformers
Apr 02, 2023



Scene graph generation is conventionally evaluated by (mean) Recall@K, which measures the ratio of correctly predicted triplets that appear in the ground truth. However, such triplet-oriented metrics cannot capture the global semantic information of scene graphs, and measure the similarity between images and generated scene graphs. The usability of scene graphs is therefore limited in downstream tasks. To address this issue, a framework that can measure the similarity of scene graphs and images is urgently required. Motivated by the successful application of Contrastive Language-Image Pre-training (CLIP), we propose a novel contrastive learning framework consisting of a graph Transformer and an image Transformer to align scene graphs and their corresponding images in the shared latent space. To enable the graph Transformer to comprehend the scene graph structure and extract representative features, we introduce a graph serialization technique that transforms a scene graph into a sequence with structural encoding. Based on our framework, we introduce R-Precision measuring image retrieval accuracy as a new evaluation metric for scene graph generation and establish new benchmarks for the Visual Genome and Open Images datasets. A series of experiments are further conducted to demonstrate the effectiveness of the graph Transformer, which shows great potential as a scene graph encoder.
LAformer: Trajectory Prediction for Autonomous Driving with Lane-Aware Scene Constraints
Feb 27, 2023Trajectory prediction for autonomous driving must continuously reason the motion stochasticity of road agents and comply with scene constraints. Existing methods typically rely on one-stage trajectory prediction models, which condition future trajectories on observed trajectories combined with fused scene information. However, they often struggle with complex scene constraints, such as those encountered at intersections. To this end, we present a novel method, called LAformer. It uses a temporally dense lane-aware estimation module to select only the top highly potential lane segments in an HD map, which effectively and continuously aligns motion dynamics with scene information, reducing the representation requirements for the subsequent attention-based decoder by filtering out irrelevant lane segments. Additionally, unlike one-stage prediction models, LAformer utilizes predictions from the first stage as anchor trajectories and adds a second-stage motion refinement module to further explore temporal consistency across the complete time horizon. Extensive experiments on Argoverse 1 and nuScenes demonstrate that LAformer achieves excellent performance for multimodal trajectory prediction.
Generating Evidential BEV Maps in Continuous Driving Space
Feb 06, 2023
Safety is critical for autonomous driving, and one aspect of improving safety is to accurately capture the uncertainties of the perception system, especially knowing the unknown. Different from only providing deterministic or probabilistic results, e.g., probabilistic object detection, that only provide partial information for the perception scenario, we propose a complete probabilistic model named GevBEV. It interprets the 2D driving space as a probabilistic Bird's Eye View (BEV) map with point-based spatial Gaussian distributions, from which one can draw evidence as the parameters for the categorical Dirichlet distribution of any new sample point in the continuous driving space. The experimental results show that GevBEV not only provides more reliable uncertainty quantification but also outperforms the previous works on the benchmark OPV2V of BEV map interpretation for cooperative perception. A critical factor in cooperative perception is the data transmission size through the communication channels. GevBEV helps reduce communication overhead by selecting only the most important information to share from the learned uncertainty, reducing the average information communicated by 80% with a slight performance drop.
HRVQA: A Visual Question Answering Benchmark for High-Resolution Aerial Images
Jan 23, 2023



Visual question answering (VQA) is an important and challenging multimodal task in computer vision. Recently, a few efforts have been made to bring VQA task to aerial images, due to its potential real-world applications in disaster monitoring, urban planning, and digital earth product generation. However, not only the huge variation in the appearance, scale and orientation of the concepts in aerial images, but also the scarcity of the well-annotated datasets restricts the development of VQA in this domain. In this paper, we introduce a new dataset, HRVQA, which provides collected 53512 aerial images of 1024*1024 pixels and semi-automatically generated 1070240 QA pairs. To benchmark the understanding capability of VQA models for aerial images, we evaluate the relevant methods on HRVQA. Moreover, we propose a novel model, GFTransformer, with gated attention modules and a mutual fusion module. The experiments show that the proposed dataset is quite challenging, especially the specific attribute related questions. Our method achieves superior performance in comparison to the previous state-of-the-art approaches. The dataset and the source code will be released at https://hrvqa.nl/.
Attribute-Centric Compositional Text-to-Image Generation
Jan 04, 2023



Despite the recent impressive breakthroughs in text-to-image generation, generative models have difficulty in capturing the data distribution of underrepresented attribute compositions while over-memorizing overrepresented attribute compositions, which raises public concerns about their robustness and fairness. To tackle this challenge, we propose ACTIG, an attribute-centric compositional text-to-image generation framework. We present an attribute-centric feature augmentation and a novel image-free training scheme, which greatly improves model's ability to generate images with underrepresented attributes. We further propose an attribute-centric contrastive loss to avoid overfitting to overrepresented attribute compositions. We validate our framework on the CelebA-HQ and CUB datasets. Extensive experiments show that the compositional generalization of ACTIG is outstanding, and our framework outperforms previous works in terms of image quality and text-image consistency.
SSGVS: Semantic Scene Graph-to-Video Synthesis
Nov 17, 2022As a natural extension of the image synthesis task, video synthesis has attracted a lot of interest recently. Many image synthesis works utilize class labels or text as guidance. However, neither labels nor text can provide explicit temporal guidance, such as when an action starts or ends. To overcome this limitation, we introduce semantic video scene graphs as input for video synthesis, as they represent the spatial and temporal relationships between objects in the scene. Since video scene graphs are usually temporally discrete annotations, we propose a video scene graph (VSG) encoder that not only encodes the existing video scene graphs but also predicts the graph representations for unlabeled frames. The VSG encoder is pre-trained with different contrastive multi-modal losses. A semantic scene graph-to-video synthesis framework (SSGVS), based on the pre-trained VSG encoder, VQ-VAE, and auto-regressive Transformer, is proposed to synthesize a video given an initial scene image and a non-fixed number of semantic scene graphs. We evaluate SSGVS and other state-of-the-art video synthesis models on the Action Genome dataset and demonstrate the positive significance of video scene graphs in video synthesis. The source code will be released.
Flow-based GAN for 3D Point Cloud Generation from a Single Image
Oct 08, 2022

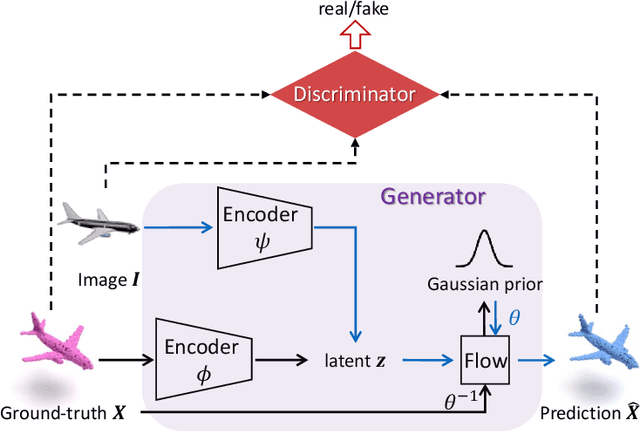
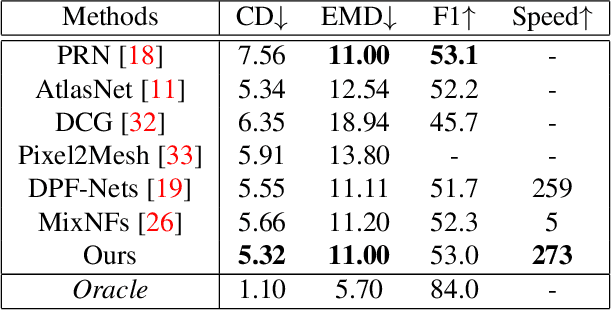
Generating a 3D point cloud from a single 2D image is of great importance for 3D scene understanding applications. To reconstruct the whole 3D shape of the object shown in the image, the existing deep learning based approaches use either explicit or implicit generative modeling of point clouds, which, however, suffer from limited quality. In this work, we aim to alleviate this issue by introducing a hybrid explicit-implicit generative modeling scheme, which inherits the flow-based explicit generative models for sampling point clouds with arbitrary resolutions while improving the detailed 3D structures of point clouds by leveraging the implicit generative adversarial networks (GANs). We evaluate on the large-scale synthetic dataset ShapeNet, with the experimental results demonstrating the superior performance of the proposed method. In addition, the generalization ability of our method is demonstrated by performing on cross-category synthetic images as well as by testing on real images from PASCAL3D+ dataset.
GATraj: A Graph- and Attention-based Multi-Agent Trajectory Prediction Model
Sep 16, 2022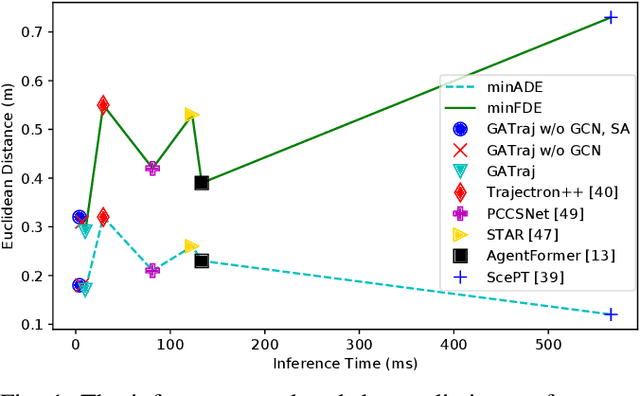

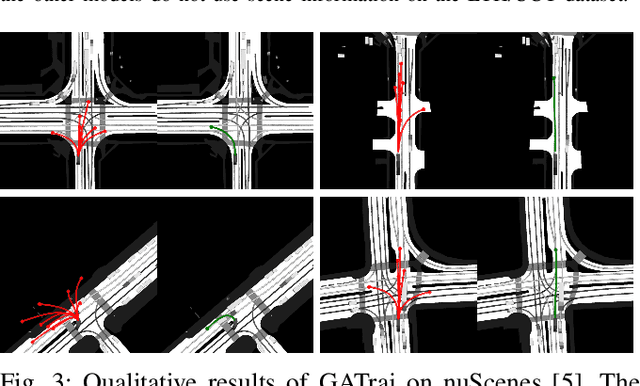
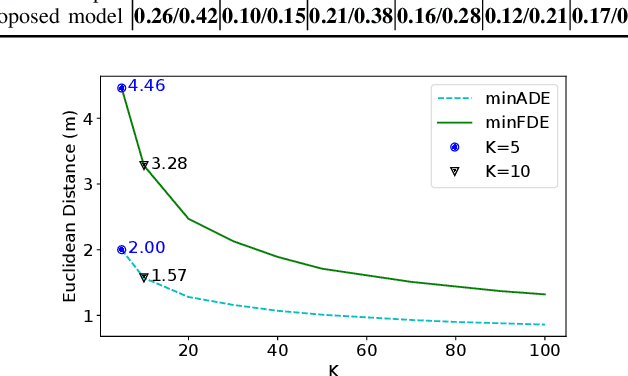
Trajectory prediction has been a long-standing problem in intelligent systems such as autonomous driving and robot navigation. Recent state-of-the-art models trained on large-scale benchmarks have been pushing the limit of performance rapidly, mainly focusing on improving prediction accuracy. However, those models put less emphasis on efficiency, which is critical for real-time applications. This paper proposes an attention-based graph model named GATraj with a much higher prediction speed. Spatial-temporal dynamics of agents, e.g., pedestrians or vehicles, are modeled by attention mechanisms. Interactions among agents are modeled by a graph convolutional network. We also implement a Laplacian mixture decoder to mitigate mode collapse and generate diverse multimodal predictions for each agent. Our model achieves performance on par with the state-of-the-art models at a much higher prediction speed tested on multiple open datasets.