 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDEs for Minimax Optimization
Feb 19, 2024



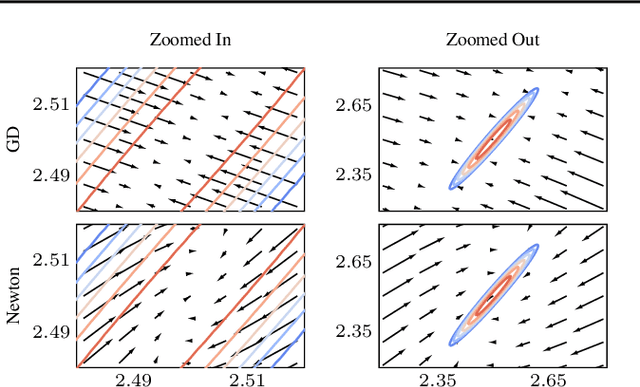
Minimax optimization problems have attracted a lot of attention over the past few years, with applications ranging from economics to machine learning. While advanced optimization methods exist for such problems, characterizing their dynamics in stochastic scenarios remains notably challenging. In this paper, we pioneer the use of stochastic differential equations (SDEs) to analyze and compare Minimax optimizers. Our SDE models for Stochastic Gradient Descent-Ascent, Stochastic Extragradient, and Stochastic Hamiltonian Gradient Descent are provable approximations of their algorithmic counterparts, clearly showcasing the interplay between hyperparameters, implicit regularization, and implicit curvature-induced noise. This perspective also allows for a unified and simplified analysis strategy based on the principles of It\^o calculus. Finally, our approach facilitates the derivation of convergence conditions and closed-form solutions for the dynamics in simplified settings, unveiling further insights into the behavior of different optimizers.
An SDE for Modeling SAM: Theory and Insights
Jan 19, 2023We study the SAM (Sharpness-Aware Minimization) optimizer which has recently attracted a lot of interest due to its increased performance over more classical variants of stochastic gradient descent. Our main contribution is the derivation of continuous-time models (in the form of SDEs) for SAM and its unnormalized variant USAM, both for the full-batch and mini-batch settings. We demonstrate that these SDEs are rigorous approximations of the real discrete-time algorithms (in a weak sense, scaling linearly with the step size). Using these models, we then offer an explanation of why SAM prefers flat minima over sharp ones - by showing that it minimizes an implicitly regularized loss with a Hessian-dependent noise structure. Finally, we prove that perhaps unexpectedly SAM is attracted to saddle points under some realistic conditions. Our theoretical results are supported by detailed experiments.
On the Theoretical Properties of Noise Correlation in Stochastic Optimization
Sep 19, 2022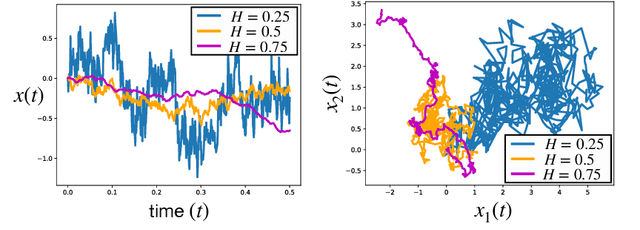
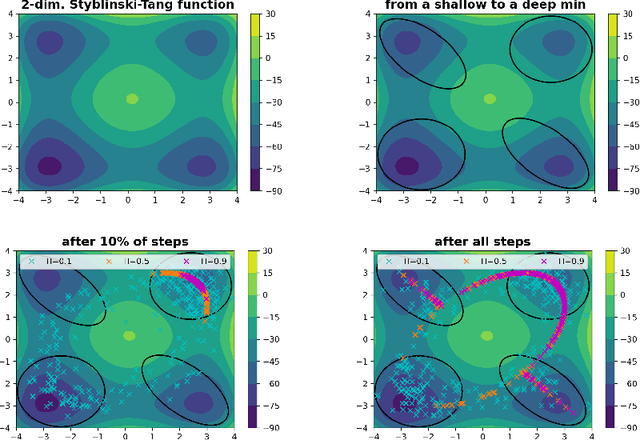
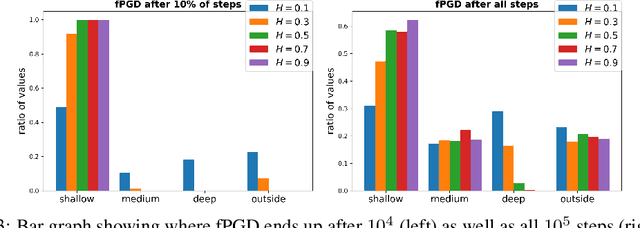
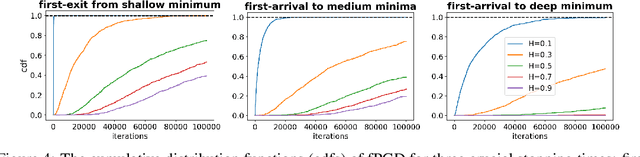
Studying the properties of stochastic noise to optimize complex non-convex functions has been an active area of research in the field of machine learning. Prior work has shown that the noise of stochastic gradient descent improves optimization by overcoming undesirable obstacles in the landscape. Moreover, injecting artificial Gaussian noise has become a popular idea to quickly escape saddle points. Indeed, in the absence of reliable gradient information, the noise is used to explore the landscape, but it is unclear what type of noise is optimal in terms of exploration ability. In order to narrow this gap in our knowledge, we study a general type of continuous-time non-Markovian process, based on fractional Brownian motion, that allows for the increments of the process to be correlated. This generalizes processes based on Brownian motion, such as the Ornstein-Uhlenbeck process. We demonstrate how to discretize such processes which gives rise to the new algorithm fPGD. This method is a generalization of the known algorithms PGD and Anti-PGD. We study the properties of fPGD both theoretically and empirically, demonstrating that it possesses exploration abilities that, in some cases, are favorable over PGD and Anti-PGD. These results open the field to novel ways to exploit noise for training machine learning models.
Explicit Regularization in Overparametrized Models via Noise Injection
Jun 10, 2022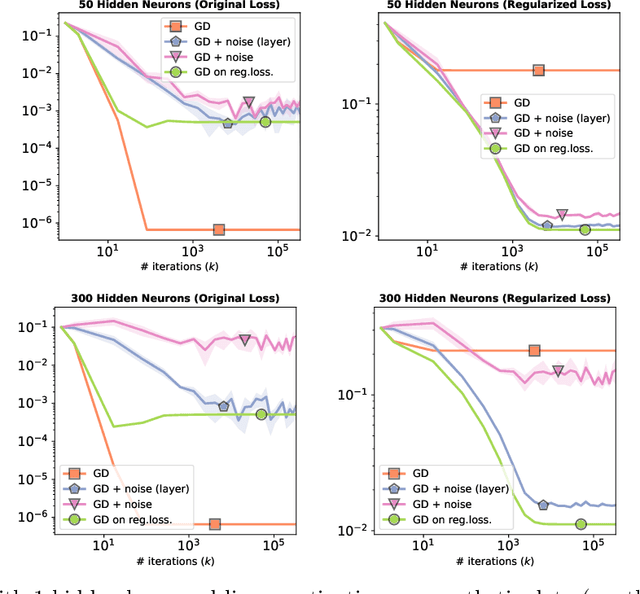
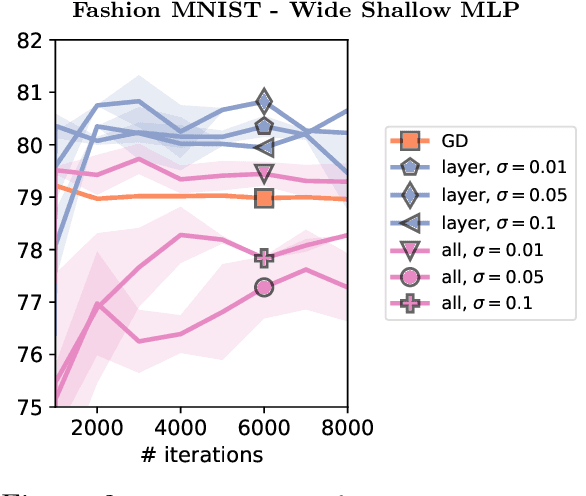
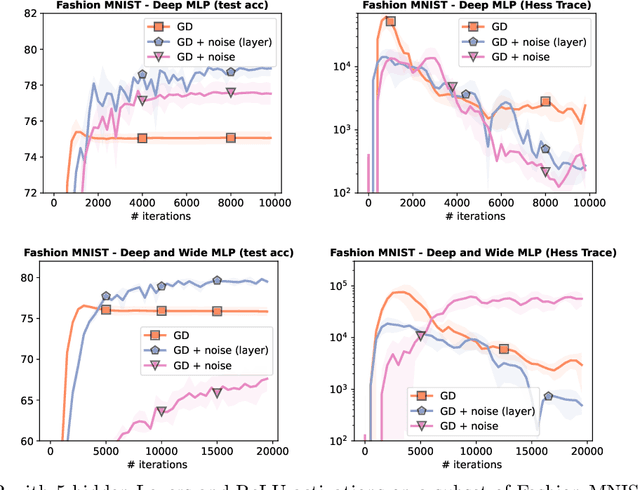
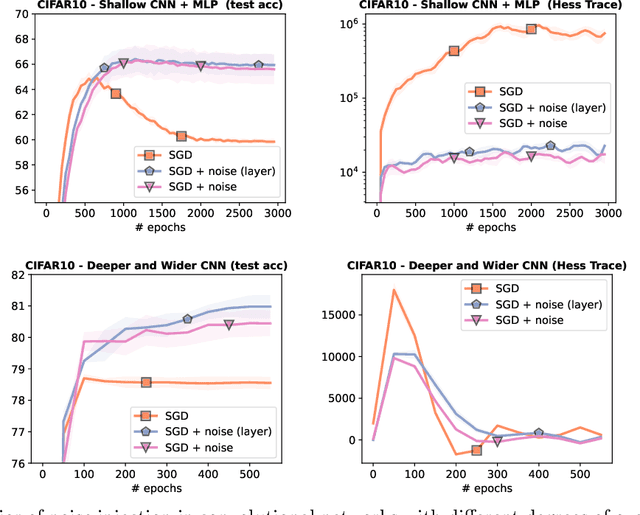
Injecting noise within gradient descent has several desirable features. In this paper, we explore noise injection before computing a gradient step, which is known to have smoothing and regularizing properties. We show that small perturbations induce explicit regularization for simple finite-dimensional models based on the l1-norm, group l1-norms, or nuclear norms. When applied to overparametrized neural networks with large widths, we show that the same perturbations do not work due to variance explosion resulting from overparametrization. However, we also show that independent layer wise perturbations allow to avoid the exploding variance term, and explicit regularizers can then be obtained. We empirically show that the small perturbations lead to better generalization performance than vanilla (stochastic) gradient descent training, with minor adjustments to the training procedure.
Anticorrelated Noise Injection for Improved Generalization
Feb 06, 2022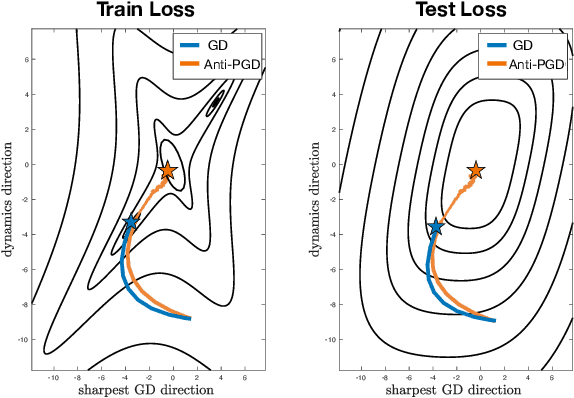
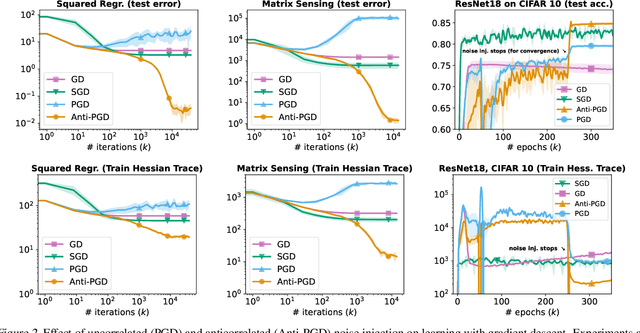
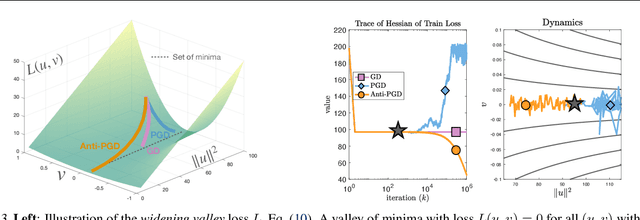
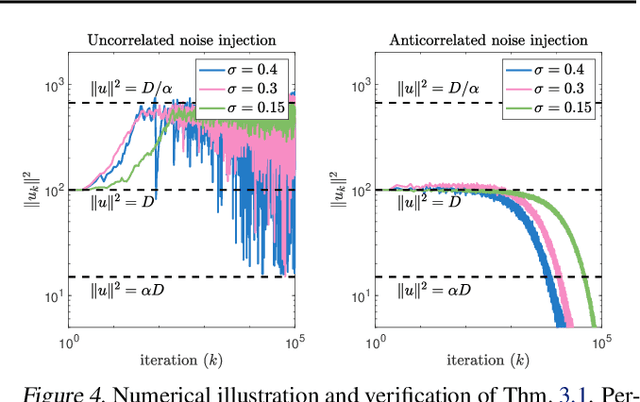
Injecting artificial noise into gradient descent (GD) is commonly employed to improve the performance of machine learning models. Usually, uncorrelated noise is used in such perturbed gradient descent (PGD) methods. It is, however, not known if this is optimal or whether other types of noise could provide better generalization performance. In this paper, we zoom in on the problem of correlating the perturbations of consecutive PGD steps. We consider a variety of objective functions for which we find that GD with anticorrelated perturbations ("Anti-PGD") generalizes significantly better than GD and standard (uncorrelated) PGD. To support these experimental findings, we also derive a theoretical analysis that demonstrates that Anti-PGD moves to wider minima, while GD and PGD remain stuck in suboptimal regions or even diverge. This new connection between anticorrelated noise and generalization opens the field to novel ways to exploit noise for training machine learning models.
A Fourier State Space Model for Bayesian ODE Filters
Jul 22, 2020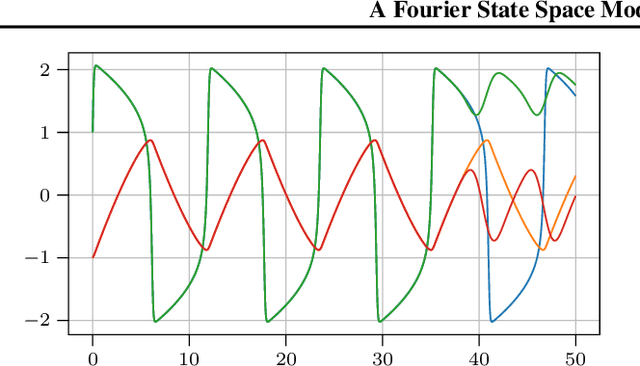
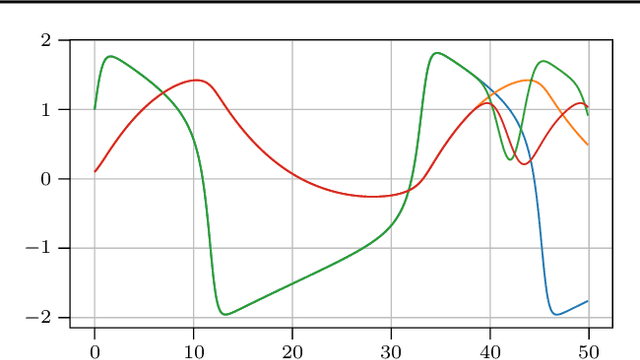
Gaussian ODE filtering is a probabilistic numerical method to solve ordinary differential equations (ODEs). It computes a Bayesian posterior over the solution from evaluations of the vector field defining the ODE. Its most popular version, which employs an integrated Brownian motion prior, uses Taylor expansions of the mean to extrapolate forward and has the same convergence rates as classical numerical methods. As the solution of many important ODEs are periodic functions (oscillators), we raise the question whether Fourier expansions can also be brought to bear within the framework of Gaussian ODE filtering. To this end, we construct a Fourier state space model for ODEs and a `hybrid' model that combines a Taylor (Brownian motion) and Fourier state space model. We show by experiments how the hybrid model might become useful in cheaply predicting until the end of the time domain.
Differentiable Likelihoods for Fast Inversion of 'Likelihood-Free' Dynamical Systems
Feb 21, 2020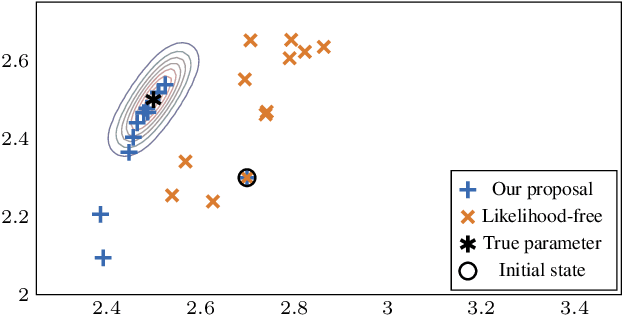
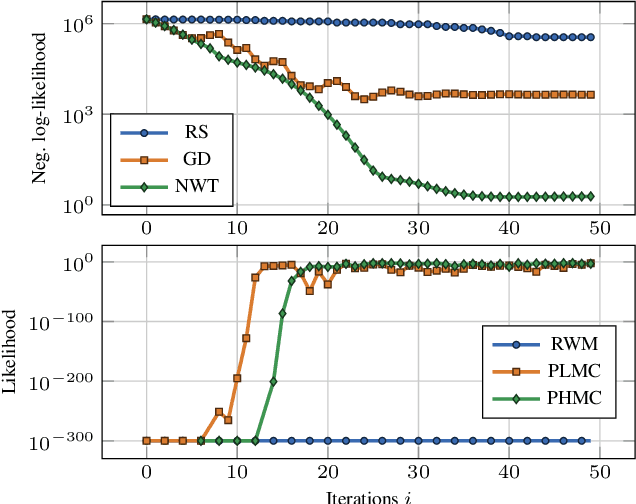
Likelihood-free (a.k.a. simulation-based) inference problems are inverse problems with expensive, or intractable, forward models. ODE inverse problems are commonly treated as likelihood-free, as their forward map has to be numerically approximated by an ODE solver. This, however, is not a fundamental constraint but just a lack of functionality in classic ODE solvers, which do not return a likelihood but a point estimate. To address this shortcoming, we employ Gaussian ODE filtering (a probabilistic numerical method for ODEs) to construct a local Gaussian approximation to the likelihood. This approximation yields tractable estimators for the gradient and Hessian of the (log-)likelihood. Insertion of these estimators into existing gradient-based optimization and sampling methods engenders new solvers for ODE inverse problems. We demonstrate that these methods outperform standard likelihood-free approaches on three benchmark-systems.
Active Uncertainty Calibration in Bayesian ODE Solvers
Nov 03, 2018
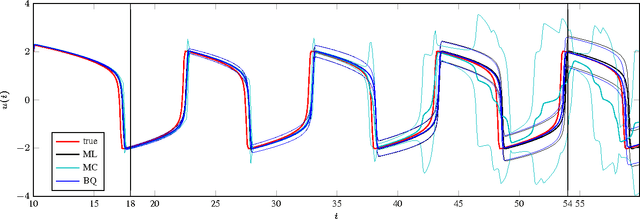


There is resurging interest, in statistics and machine learning, in solvers for ordinary differential equations (ODEs) that return probability measures instead of point estimates. Recently, Conrad et al. introduced a sampling-based class of methods that are 'well-calibrated' in a specific sense. But the computational cost of these methods is significantly above that of classic methods. On the other hand, Schober et al. pointed out a precise connection between classic Runge-Kutta ODE solvers and Gaussian filters, which gives only a rough probabilistic calibration, but at negligible cost overhead. By formulating the solution of ODEs as approximate inference in linear Gaussian SDEs, we investigate a range of probabilistic ODE solvers, that bridge the trade-off between computational cost and probabilistic calibration, and identify the inaccurate gradient measurement as the crucial source of uncertainty. We propose the novel filtering-based method Bayesian Quadrature filtering (BQF) which uses Bayesian quadrature to actively learn the imprecision in the gradient measurement by collecting multiple gradient evaluations.
* 10 pages, 3 figures, published at UAI 2016. Changes for Version 3: fixed minor index mistake in equation (14) (q-1-i instead of q+1-i on top of the product)
Probabilistic Solutions To Ordinary Differential Equations As Non-Linear Bayesian Filtering: A New Perspective
Oct 08, 2018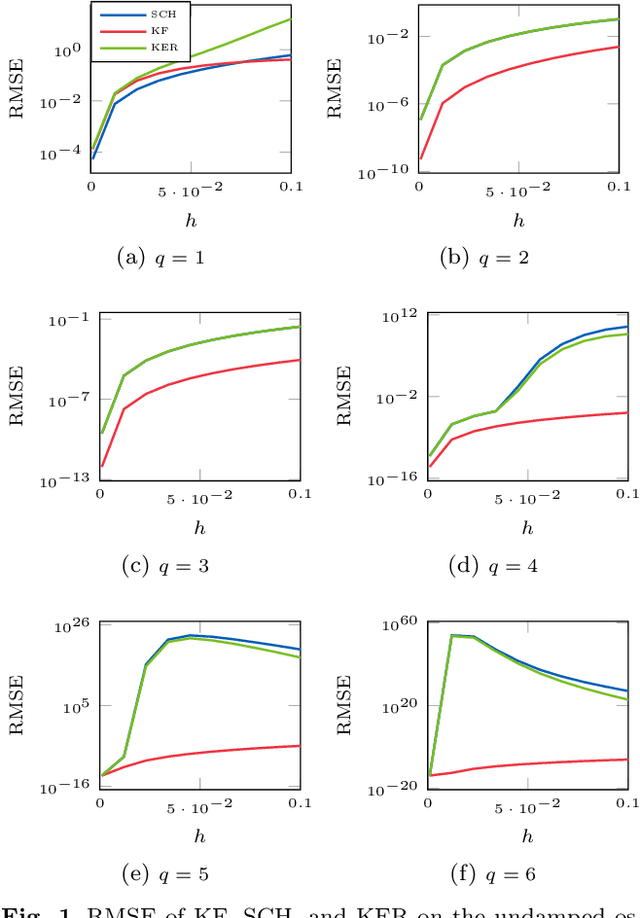
We formulate probabilistic numerical approximations to solutions of ordinary differential equations (ODEs) as problems in Gaussian process (GP) regression with non-linear measurement functions. This is achieved by defining the measurement sequence to consists of the observations of the difference between the derivative of the GP and the vector field evaluated at the GP---which are all identically zero at the solution of the ODE. When the GP has a state-space representation, the problem can be reduced to a Bayesian state estimation problem and all widely-used approximations to the Bayesian filtering and smoothing problems become applicable. Furthermore, all previous GP-based ODE solvers, which were formulated in terms of generating synthetic measurements of the vector field, come out as specific approximations. We derive novel solvers, both Gaussian and non-Gaussian, from the Bayesian state estimation problem posed in this paper and compare them with other probabilistic solvers in illustrative experiments.
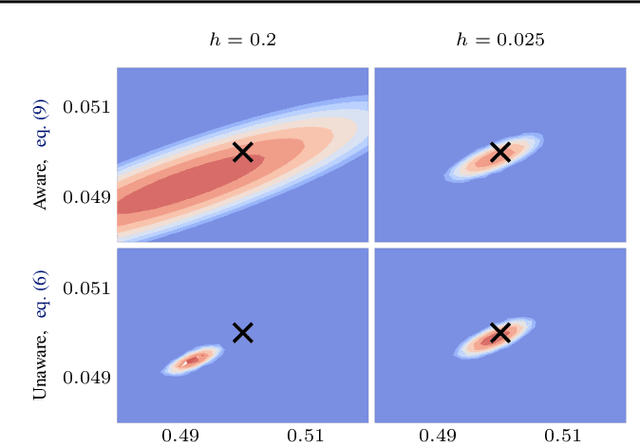
Convergence Rates of Gaussian ODE Filters
Jul 25, 2018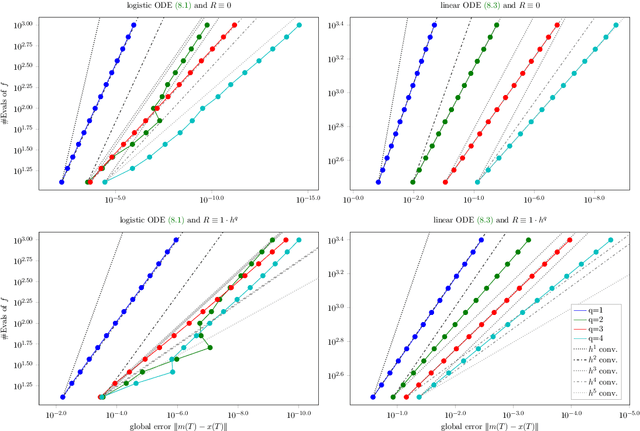
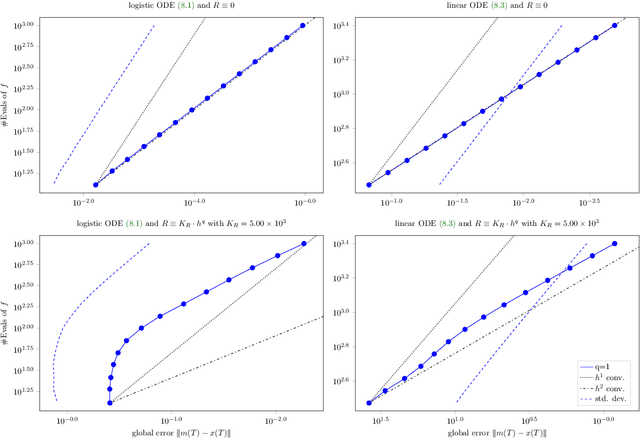
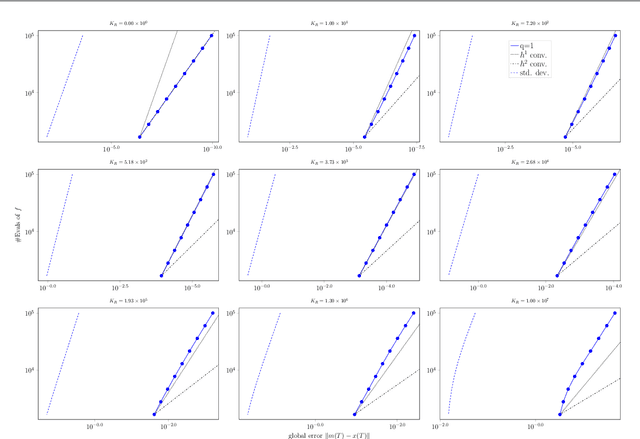
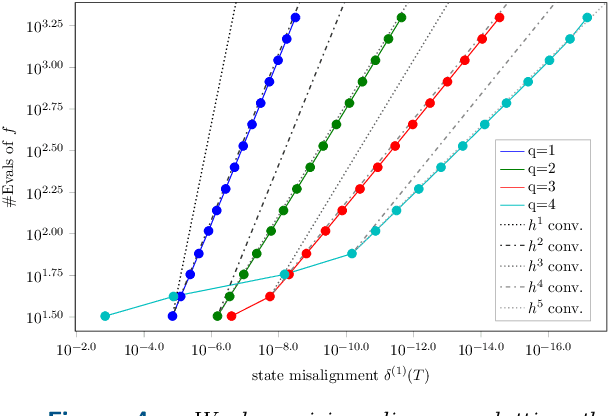
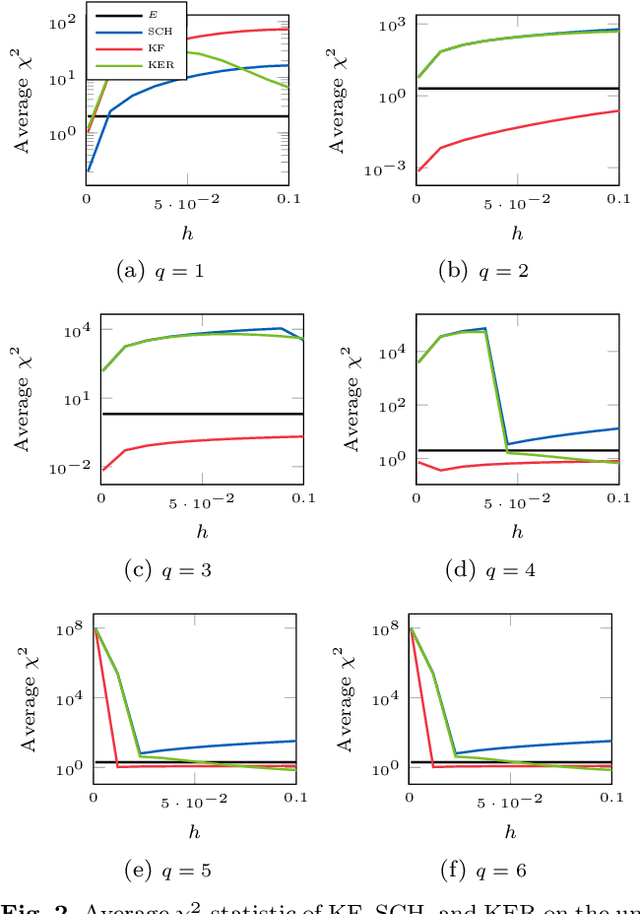
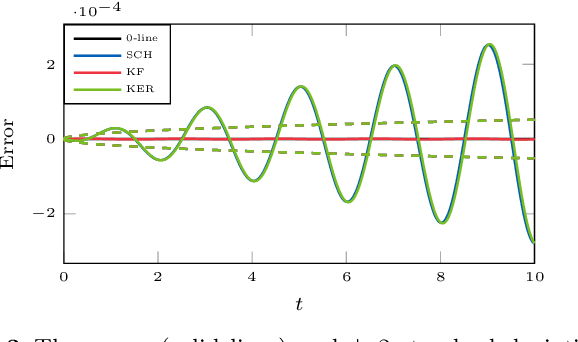
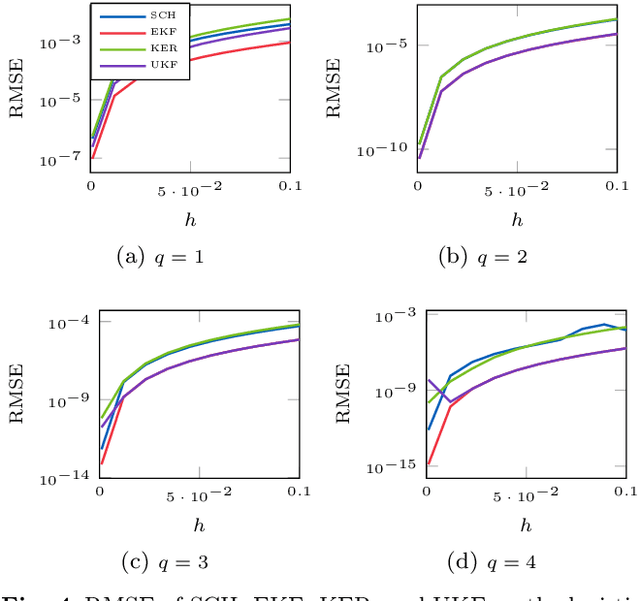
A recently-introduced class of probabilistic (uncertainty-aware) solvers for ordinary differential equations (ODEs) applies Gaussian (Kalman) filtering to initial value problems. These methods model the true solution $x$ and its first $q$ derivatives a priori as a Gauss--Markov process $\boldsymbol{X}$, which is then iteratively conditioned on information about $\dot{x}$. We prove worst-case local convergence rates of order $h^{q+1}$ for a wide range of versions of this Gaussian ODE filter, as well as global convergence rates of order $h^q$ in the case of $q=1$ and an integrated Brownian motion prior, and analyze how inaccurate information on $\dot{x}$ coming from approximate evaluations of $f$ affects these rates. Moreover, we present explicit formulas for the steady states and show that the posterior confidence intervals are well calibrated in all considered cases that exhibit global convergence---in the sense that they globally contract at the same rate as the truncation error.