 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrthogonalized SGD and Nested Architectures for Anytime Neural Networks
Aug 15, 2020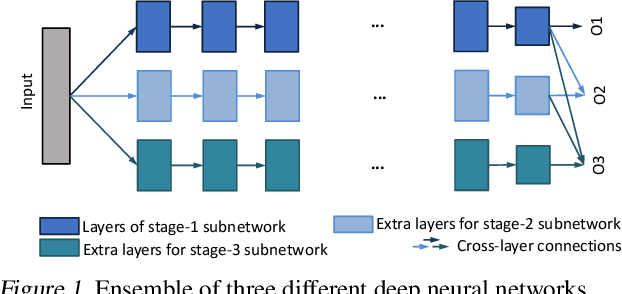
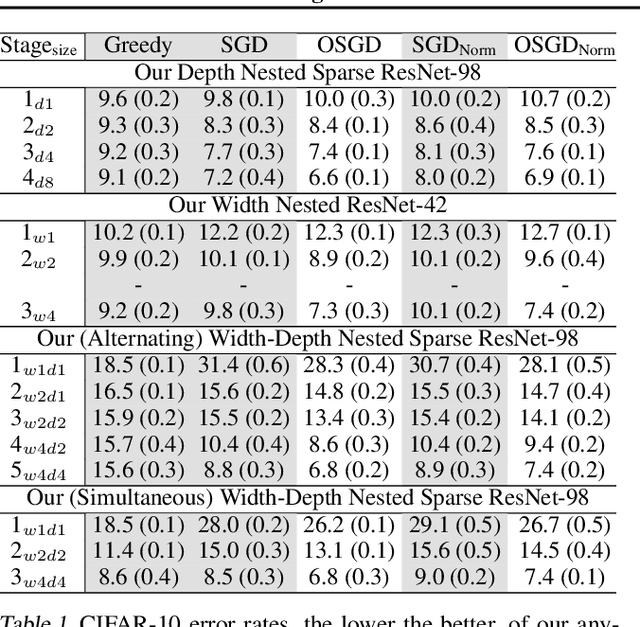
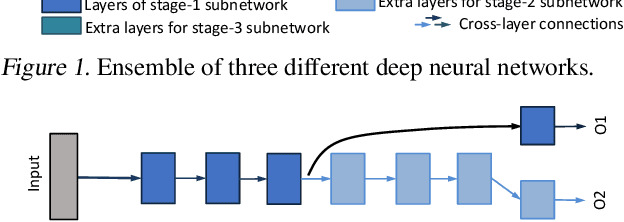
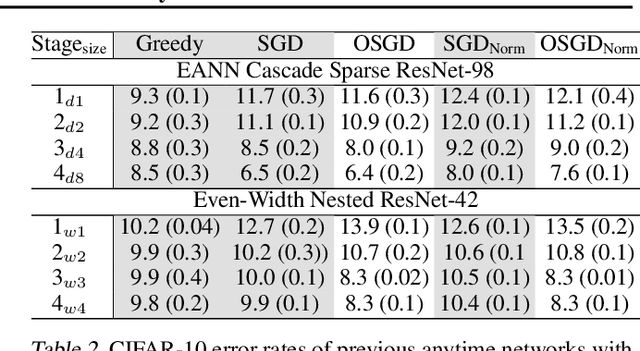
We propose a novel variant of SGD customized for training network architectures that support anytime behavior: such networks produce a series of increasingly accurate outputs over time. Efficient architectural designs for these networks focus on re-using internal state; subnetworks must produce representations relevant for both immediate prediction as well as refinement by subsequent network stages. We consider traditional branched networks as well as a new class of recursively nested networks. Our new optimizer, Orthogonalized SGD, dynamically re-balances task-specific gradients when training a multitask network. In the context of anytime architectures, this optimizer projects gradients from later outputs onto a parameter subspace that does not interfere with those from earlier outputs. Experiments demonstrate that training with Orthogonalized SGD significantly improves generalization accuracy of anytime networks.
Growing Efficient Deep Networks by Structured Continuous Sparsification
Jul 30, 2020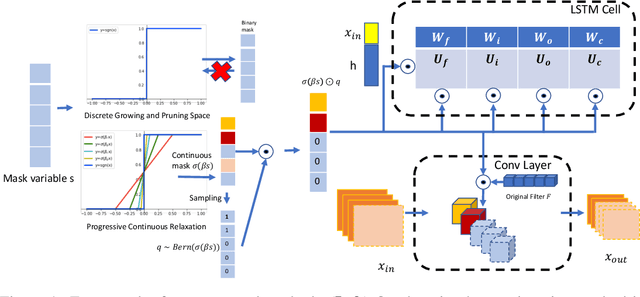
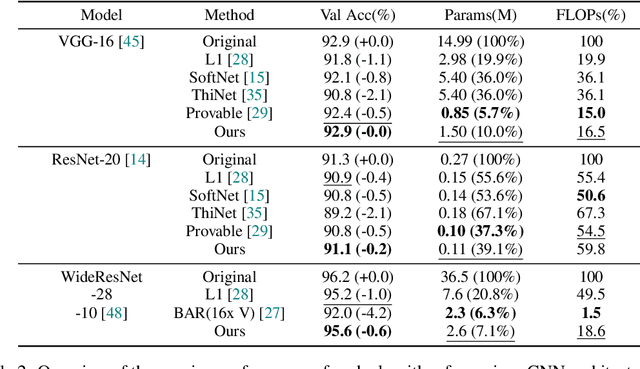
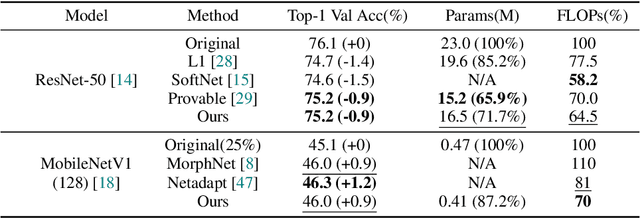
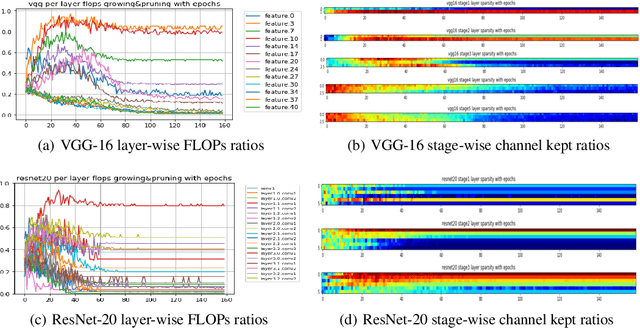
We develop an approach to training deep networks while dynamically adjusting their architecture, driven by a principled combination of accuracy and sparsity objectives. Unlike conventional pruning approaches, our method adopts a gradual continuous relaxation of discrete network structure optimization and then samples sparse subnetworks, enabling efficient deep networks to be trained in a growing and pruning manner. Extensive experiments across CIFAR-10, ImageNet, PASCAL VOC, and Penn Treebank, with convolutional models for image classification and semantic segmentation, and recurrent models for language modeling, show that our training scheme yields efficient networks that are smaller and more accurate than those produced by competing pruning methods.
Pixel Consensus Voting for Panoptic Segmentation
Apr 04, 2020The core of our approach, Pixel Consensus Voting, is a framework for instance segmentation based on the Generalized Hough transform. Pixels cast discretized, probabilistic votes for the likely regions that contain instance centroids. At the detected peaks that emerge in the voting heatmap, backprojection is applied to collect pixels and produce instance masks. Unlike a sliding window detector that densely enumerates object proposals, our method detects instances as a result of the consensus among pixel-wise votes. We implement vote aggregation and backprojection using native operators of a convolutional neural network. The discretization of centroid voting reduces the training of instance segmentation to pixel labeling, analogous and complementary to FCN-style semantic segmentation, leading to an efficient and unified architecture that jointly models things and stuff. We demonstrate the effectiveness of our pipeline on COCO and Cityscapes Panoptic Segmentation and obtain competitive results. Code will be open-sourced.
Domain-independent Dominance of Adaptive Methods
Dec 10, 2019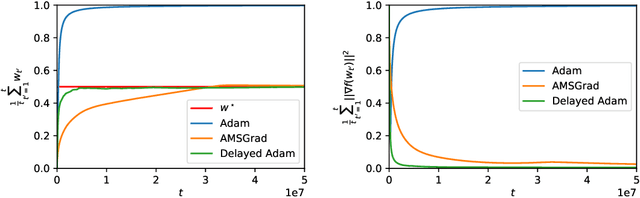
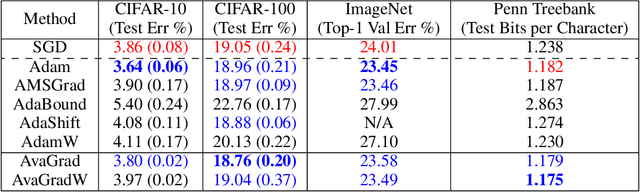
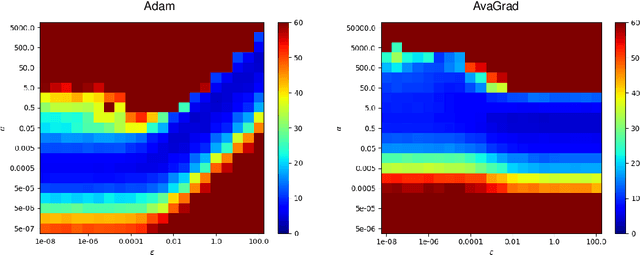
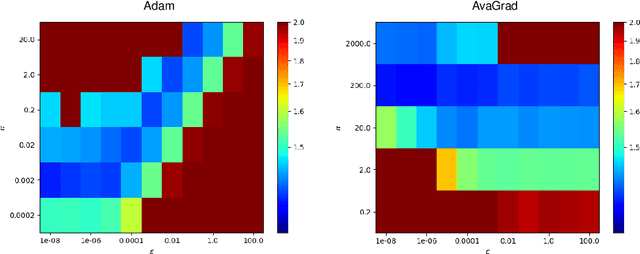
From a simplified analysis of adaptive methods, we derive AvaGrad, a new optimizer which outperforms SGD on vision tasks when its adaptability is properly tuned. We observe that the power of our method is partially explained by a decoupling of learning rate and adaptability, greatly simplifying hyperparameter search. In light of this observation, we demonstrate that, against conventional wisdom, Adam can also outperform SGD on vision tasks, as long as the coupling between its learning rate and adaptability is taken into account. In practice, AvaGrad matches the best results, as measured by generalization accuracy, delivered by any existing optimizer (SGD or adaptive) across image classification (CIFAR, ImageNet) and character-level language modelling (Penn Treebank) tasks. This later observation, alongside of AvaGrad's decoupling of hyperparameters, could make it the preferred optimizer for deep learning, replacing both SGD and Adam.
Winning the Lottery with Continuous Sparsification
Dec 10, 2019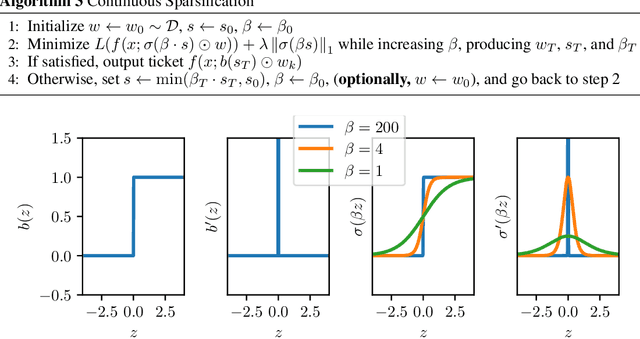
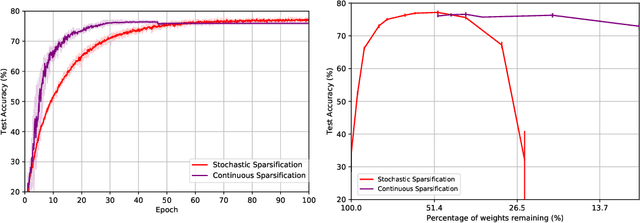
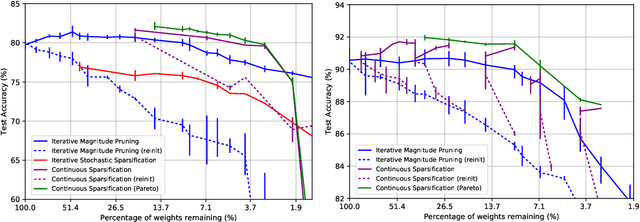
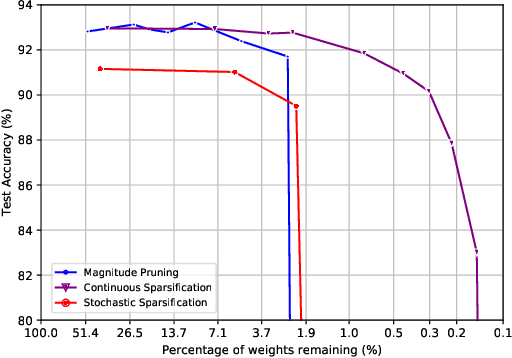
The Lottery Ticket Hypothesis from Frankle & Carbin (2019) conjectures that, for typically-sized neural networks, it is possible to find small sub-networks which train faster and yield superior performance than their original counterparts. The proposed algorithm to search for "winning tickets", Iterative Magnitude Pruning, consistently finds sub-networks with $90-95\%$ less parameters which train faster and better than the overparameterized models they were extracted from, creating potential applications to problems such as transfer learning. In this paper, we propose Continuous Sparsification, a new algorithm to search for winning tickets which continuously removes parameters from a network during training, and learns the sub-network's structure with gradient-based methods instead of relying on pruning strategies. We show empirically that our method is capable of finding tickets that outperforms the ones learned by Iterative Magnitude Pruning, and at the same time providing faster search, when measured in number of training epochs or wall-clock time.
ALERT: Accurate Anytime Learning for Energy and Timeliness
Oct 31, 2019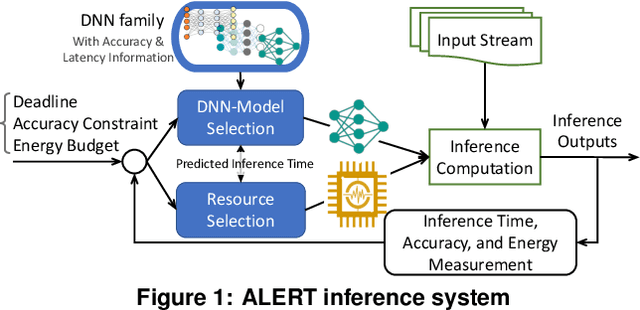
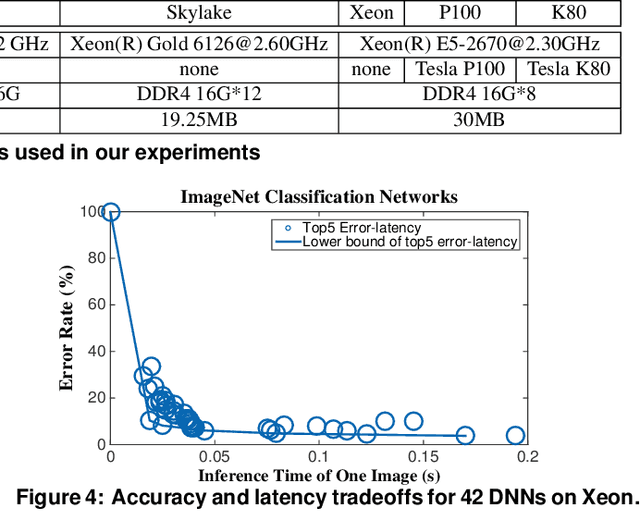
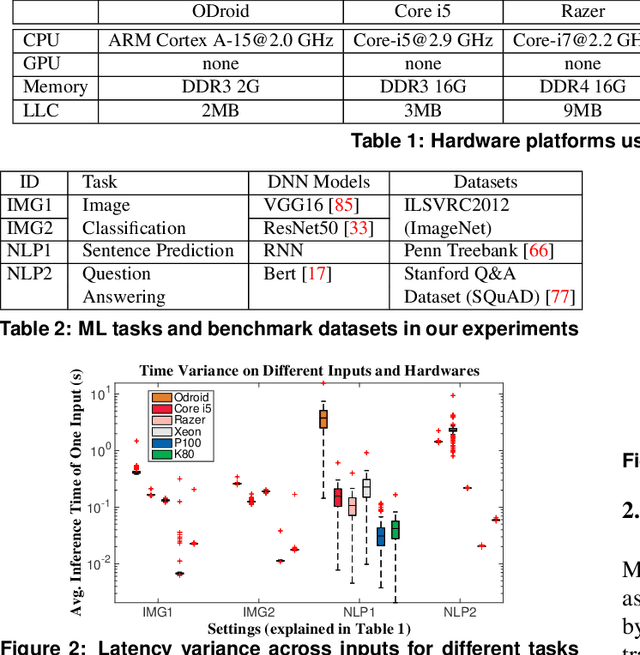
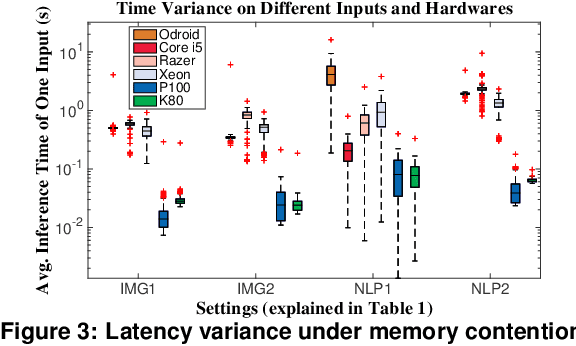
An increasing number of software applications incorporate runtime Deep Neural Network (DNN) inference for its great accuracy in many problem domains. While much prior work has separately tackled the problems of improving DNN-inference accuracy and improving DNN-inference efficiency, an important problem is under-explored: disciplined methods for dynamically managing application-specific latency, accuracy, and energy tradeoffs and constraints at run time. To address this need, we propose ALERT, a co-designed combination of runtime system and DNN nesting technique. The runtime takes latency, accuracy, and energy constraints, and uses dynamic feedback to predict the best DNN-model and system power-limit setting. The DNN nesting creates a type of flexible network that efficiently delivers a series of results with increasing accuracy as time goes on. These two parts well complement each other: the runtime is aware of the tradeoffs of different DNN settings, and the nested DNNs' flexibility allows the runtime prediction to satisfy application requirements even in unpredictable, changing environments. On real systems for both image and speech, ALERT achieves close-to-optimal results. Comparing with the optimal static DNN-model and power-limit setting, which is impractical to predict, ALERT achieves a harmonic mean 33% of energy savings while satisfying accuracy constraints, and reduces image-classification error rate by 58% and sentence-prediction perplexity by 52% while satisfying energy constraints.
Multigrid Neural Memory
Jun 13, 2019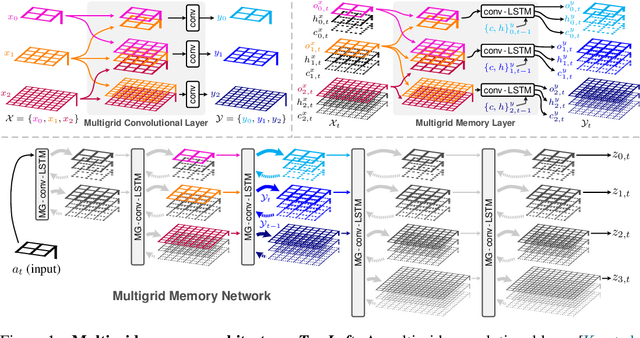
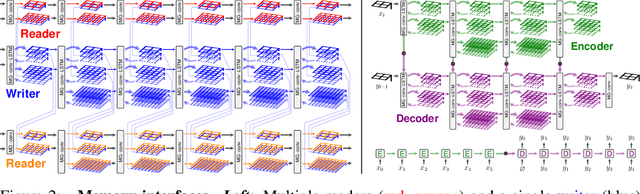

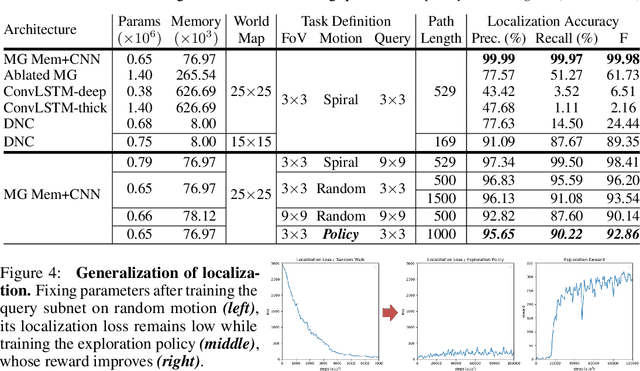
We introduce a novel architecture that integrates a large addressable memory space into the core functionality of a deep neural network. Our design distributes both memory addressing operations and storage capacity over many network layers. Distinct from strategies that connect neural networks to external memory banks, our approach co-locates memory with computation throughout the network structure. Mirroring recent architectural innovations in convolutional networks, we organize memory into a multiresolution hierarchy, whose internal connectivity enables learning of dynamic information routing strategies and data-dependent read/write operations. This multigrid spatial layout permits parameter-efficient scaling of memory size, allowing us to experiment with memories substantially larger than those in prior work. We demonstrate this capability on synthetic exploration and mapping tasks, where the network is able to self-organize and retain long-term memory for trajectories of thousands of time steps. On tasks decoupled from any notion of spatial geometry, such as sorting or associative recall, our design functions as a truly generic memory and yields results competitive with those of the recently proposed Differentiable Neural Computer.
Learning Implicitly Recurrent CNNs Through Parameter Sharing
Mar 13, 2019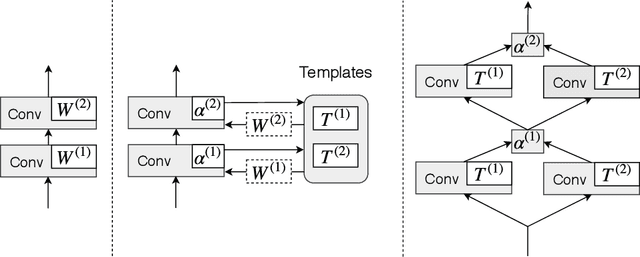
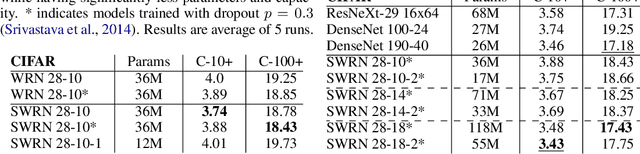
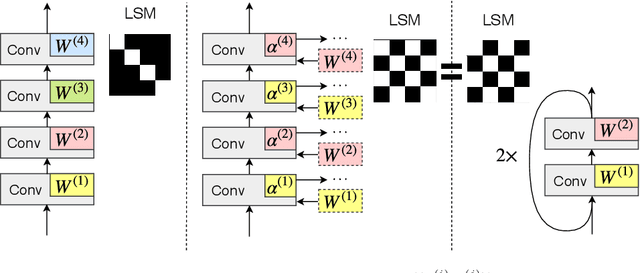
We introduce a parameter sharing scheme, in which different layers of a convolutional neural network (CNN) are defined by a learned linear combination of parameter tensors from a global bank of templates. Restricting the number of templates yields a flexible hybridization of traditional CNNs and recurrent networks. Compared to traditional CNNs, we demonstrate substantial parameter savings on standard image classification tasks, while maintaining accuracy. Our simple parameter sharing scheme, though defined via soft weights, in practice often yields trained networks with near strict recurrent structure; with negligible side effects, they convert into networks with actual loops. Training these networks thus implicitly involves discovery of suitable recurrent architectures. Though considering only the design aspect of recurrent links, our trained networks achieve accuracy competitive with those built using state-of-the-art neural architecture search (NAS) procedures. Our hybridization of recurrent and convolutional networks may also represent a beneficial architectural bias. Specifically, on synthetic tasks which are algorithmic in nature, our hybrid networks both train faster and extrapolate better to test examples outside the span of the training set.
Sparsely Aggregated Convolutional Networks
Apr 16, 2018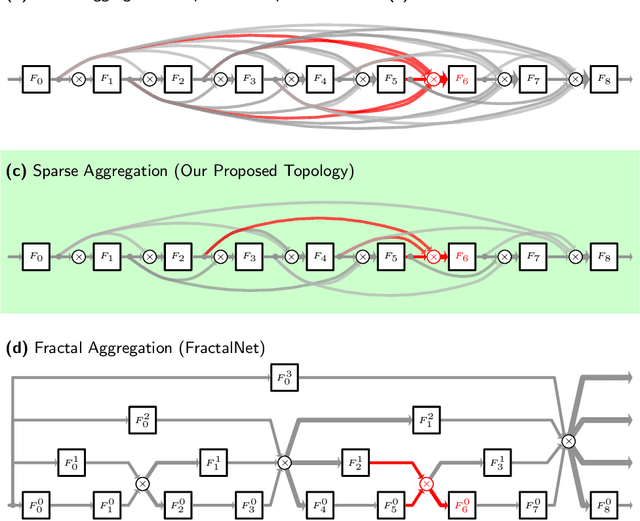
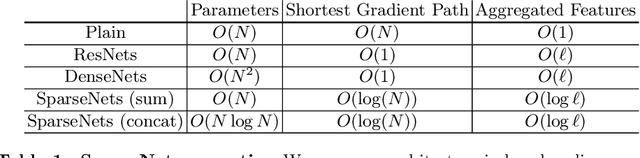
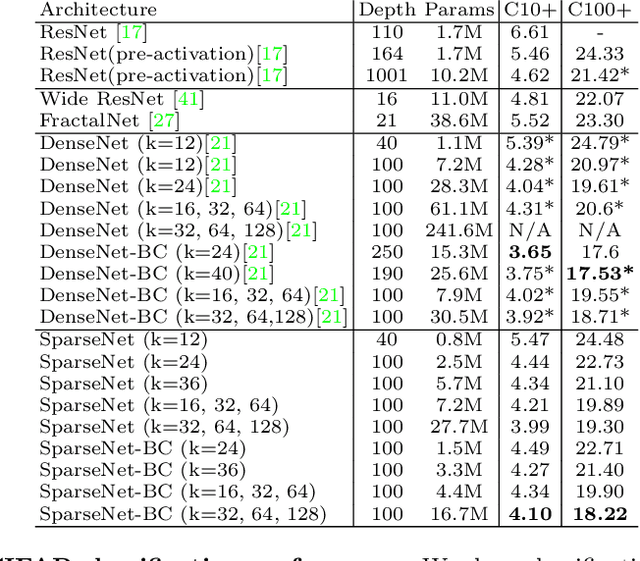
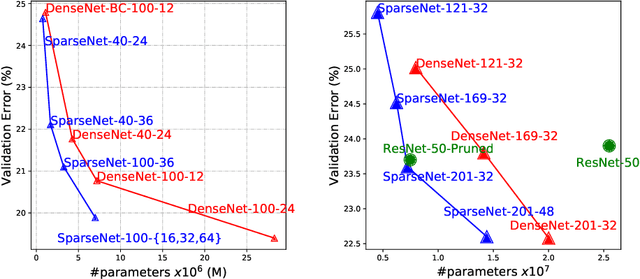
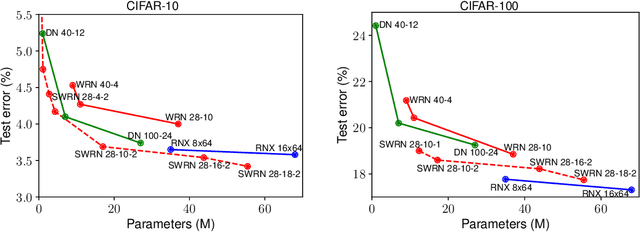
We explore a key architectural aspect of deep convolutional neural networks: the pattern of internal skip connections used to aggregate outputs of earlier layers for consumption by deeper layers. Such aggregation is critical to facilitate training of very deep networks in an end-to-end manner. This is a primary reason for the widespread adoption of residual networks, which aggregate outputs via cumulative summation. While subsequent works investigate alternative aggregation operations (e.g. concatenation), we focus on an orthogonal question: which outputs to aggregate at a particular point in the network. We propose a new internal connection structure which aggregates only a sparse set of previous outputs at any given depth. Our experiments demonstrate this simple design change offers superior performance with fewer parameters and lower computational requirements. Moreover, we show that sparse aggregation allows networks to scale more robustly to 1000+ layers, thereby opening future avenues for training long-running visual processes.
Regularizing Deep Networks by Modeling and Predicting Label Structure
Apr 05, 2018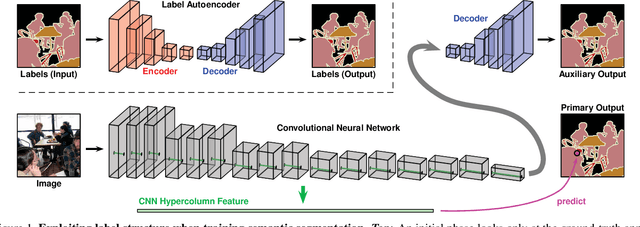
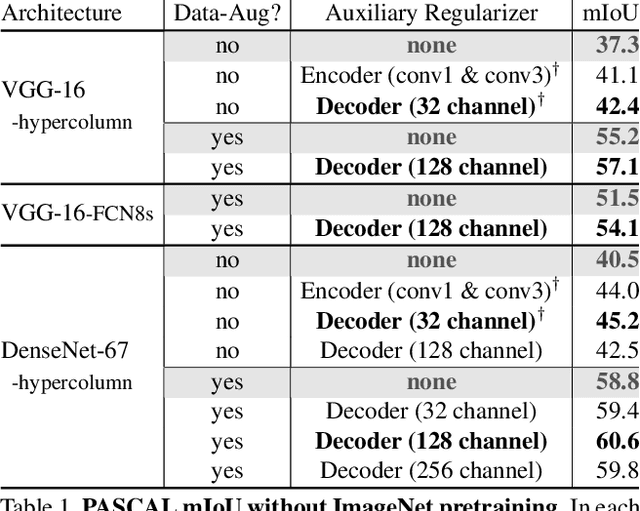
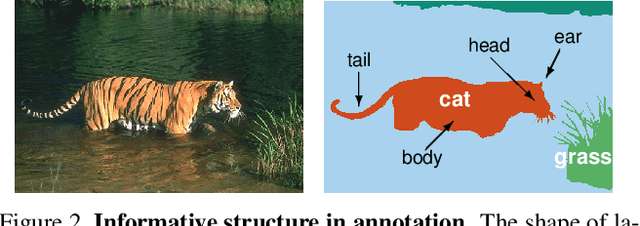
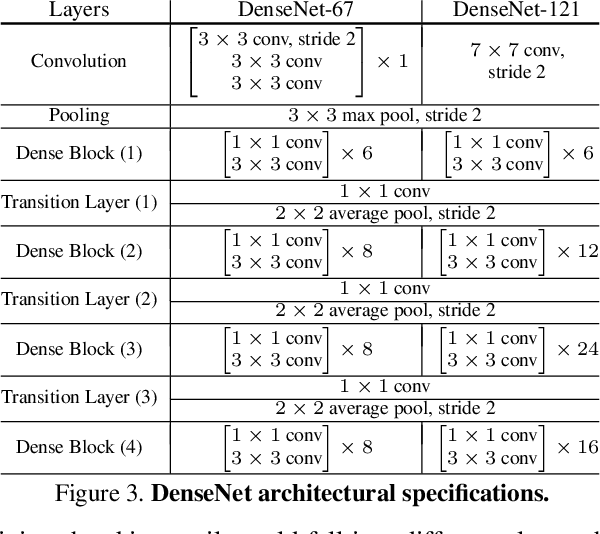
We construct custom regularization functions for use in supervised training of deep neural networks. Our technique is applicable when the ground-truth labels themselves exhibit internal structure; we derive a regularizer by learning an autoencoder over the set of annotations. Training thereby becomes a two-phase procedure. The first phase models labels with an autoencoder. The second phase trains the actual network of interest by attaching an auxiliary branch that must predict output via a hidden layer of the autoencoder. After training, we discard this auxiliary branch. We experiment in the context of semantic segmentation, demonstrating this regularization strategy leads to consistent accuracy boosts over baselines, both when training from scratch, or in combination with ImageNet pretraining. Gains are also consistent over different choices of convolutional network architecture. As our regularizer is discarded after training, our method has zero cost at test time; the performance improvements are essentially free. We are simply able to learn better network weights by building an abstract model of the label space, and then training the network to understand this abstraction alongside the original task.