 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Neural Models with Sequential Monte Carlo Dropout
Oct 27, 2022



The ability to adapt to changing environments and settings is essential for robots acting in dynamic and unstructured environments or working alongside humans with varied abilities or preferences. This work introduces an extremely simple and effective approach to adapting neural models in response to changing settings. We first train a standard network using dropout, which is analogous to learning an ensemble of predictive models or distribution over predictions. At run-time, we use a particle filter to maintain a distribution over dropout masks to adapt the neural model to changing settings in an online manner. Experimental results show improved performance in control problems requiring both online and look-ahead prediction, and showcase the interpretability of the inferred masks in a human behaviour modelling task for drone teleoperation.
Learning robotic cutting from demonstration: Non-holonomic DMPs using the Udwadia-Kalaba method
Sep 24, 2022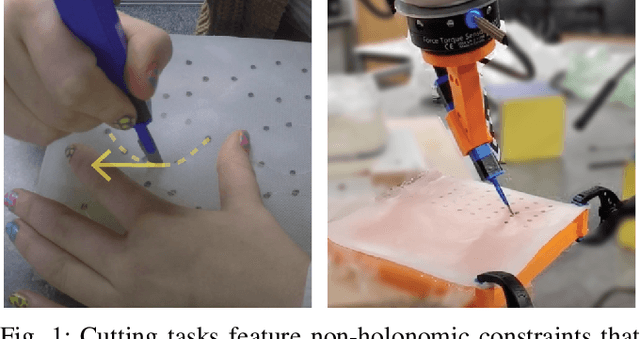

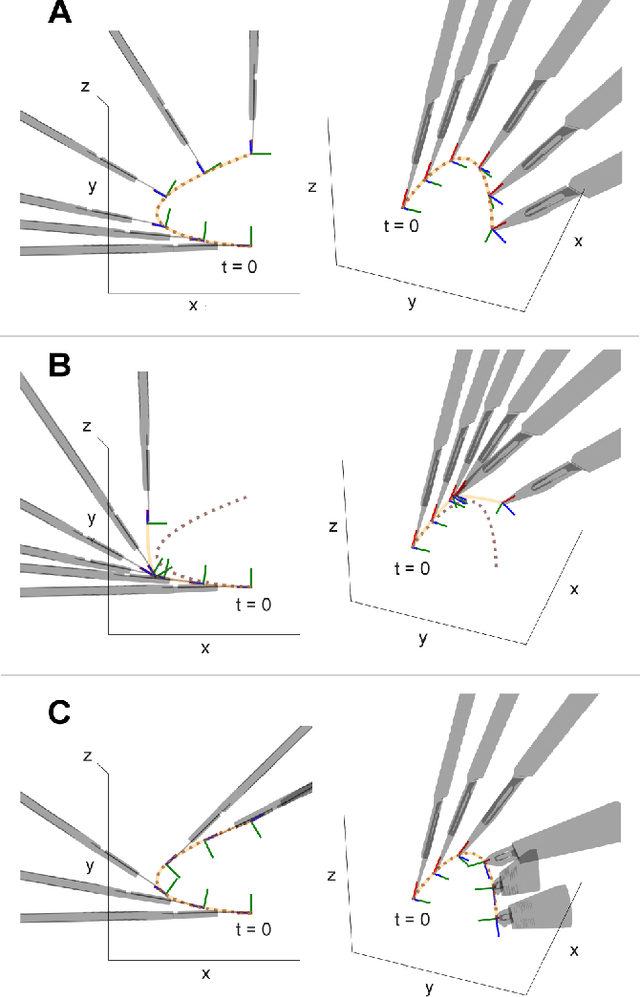

Dynamic Movement Primitives (DMPs) offer great versatility for encoding, generating and adapting complex end-effector trajectories. DMPs are also very well suited to learning manipulation skills from human demonstration. However, the reactive nature of DMPs restricts their applicability for tool use and object manipulation tasks involving non-holonomic constraints, such as scalpel cutting or catheter steering. In this work, we extend the Cartesian space DMP formulation by adding a coupling term that enforces a pre-defined set of non-holonomic constraints. We obtain the closed-form expression for the constraint forcing term using the Udwadia-Kalaba method. This approach offers a clean and practical solution for guaranteed constraint satisfaction at run-time. Further, the proposed analytical form of the constraint forcing term enables efficient trajectory optimization subject to constraints. We demonstrate the usefulness of this approach by showing how we can learn robotic cutting skills from human demonstration.
Challenges of Driver Drowsiness Prediction: The Remaining Steps to Implementation
Sep 17, 2021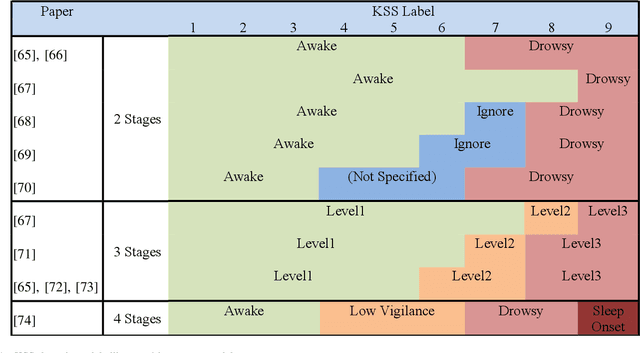


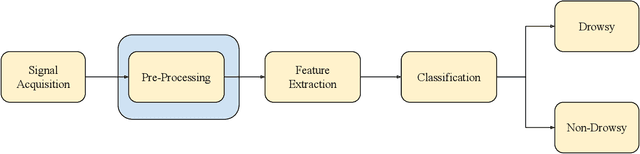
Driver drowsiness has caused a large number of serious injuries and deaths on public roads and incurred billions of taxpayer dollars in costs. Hence, monitoring of drowsiness is critical to reduce this burden on society. This paper surveys the broad range of solutions proposed to address the challenges of driver drowsiness, and identifies the key steps required for successful implementation. Although some commercial products already exist, with vehicle-based methods most commonly implemented by automotive manufacturers, these systems may not have the level of accuracy required to properly predict and monitor drowsiness. State-of-the-art models use physiological, behavioural and vehicle-based methods to detect drowsiness, with hybrid methods emerging as a superior approach. Current setbacks to implementing these methods include late detection, intrusiveness and subject diversity. In particular, physiological monitoring methods such as Electroencephalography (EEG) are intrusive to drivers; while behavioural monitoring is least robust, affected by external factors such as lighting, as well as being subject to privacy concerns. Drowsiness detection models are often developed and validated based on subjective measures, with the Karolinska Sleepiness Scale being the most popular. Subjective and incoherent labelling of drowsiness, lack of on road data and inconsistent protocols for data collection are among other challenges to be addressed to progress drowsiness detection for reliable on-road use.
Vision-based system identification and 3D keypoint discovery using dynamics constraints
Sep 13, 2021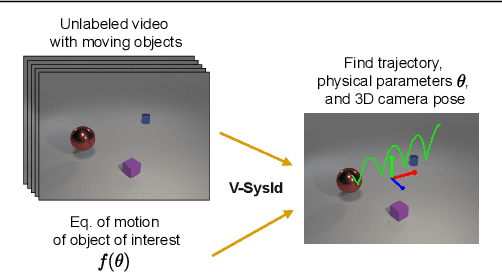
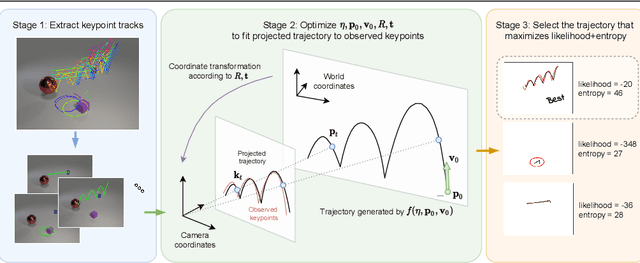
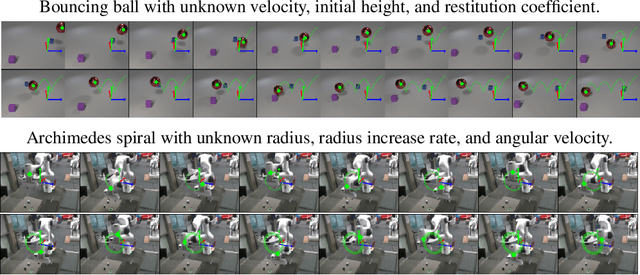

This paper introduces V-SysId, a novel method that enables simultaneous keypoint discovery, 3D system identification, and extrinsic camera calibration from an unlabeled video taken from a static camera, using only the family of equations of motion of the object of interest as weak supervision. V-SysId takes keypoint trajectory proposals and alternates between maximum likelihood parameter estimation and extrinsic camera calibration, before applying a suitable selection criterion to identify the track of interest. This is then used to train a keypoint tracking model using supervised learning. Results on a range of settings (robotics, physics, physiology) highlight the utility of this approach.
Learning data association without data association: An EM approach to neural assignment prediction
May 02, 2021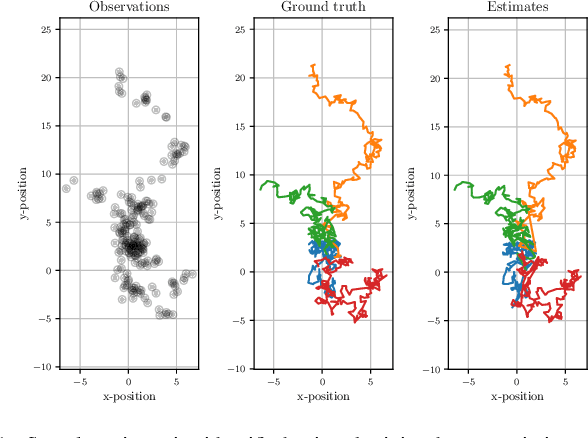
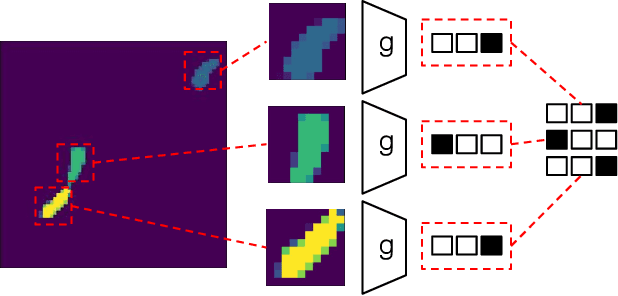
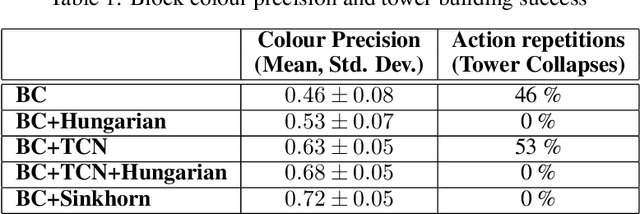
Data association is a fundamental component of effective multi-object tracking. Current approaches to data-association tend to frame this as an assignment problem relying on gating and distance-based cost matrices, or offset the challenge of data association to a problem of tracking by detection. The latter is typically formulated as a supervised learning problem, and requires labelling information about tracked object identities to train a model for object recognition. This paper introduces an expectation maximisation approach to train neural models for data association, which does not require labelling information. Here, a Sinkhorn network is trained to predict assignment matrices that maximise the marginal likelihood of trajectory observations. Importantly, networks trained using the proposed approach can be re-used in downstream tracking applications.
IV-Posterior: Inverse Value Estimation for Interpretable Policy Certificates
Nov 30, 2020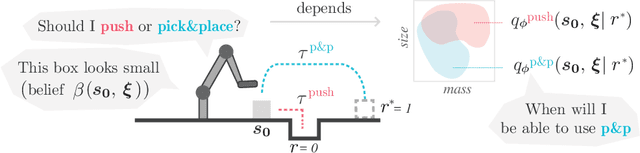
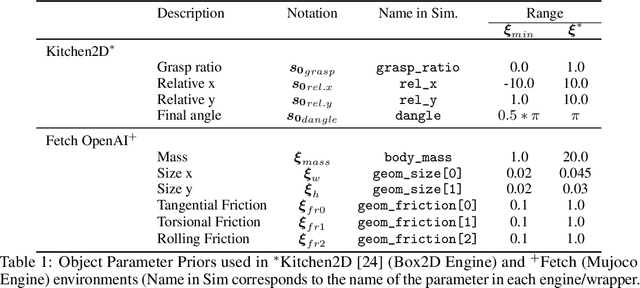
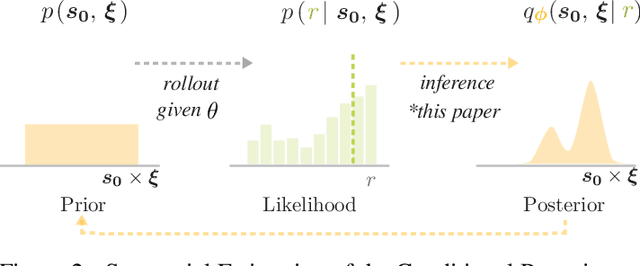
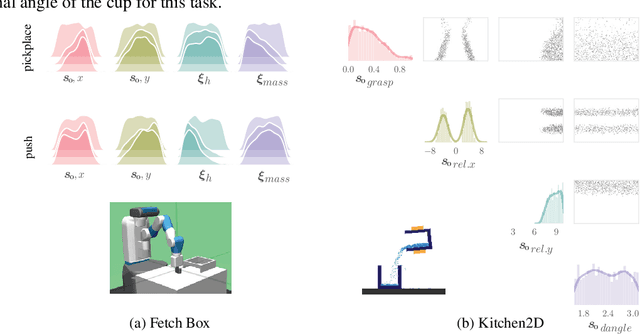
Model-free reinforcement learning (RL) is a powerful tool to learn a broad range of robot skills and policies. However, a lack of policy interpretability can inhibit their successful deployment in downstream applications, particularly when differences in environmental conditions may result in unpredictable behaviour or generalisation failures. As a result, there has been a growing emphasis in machine learning around the inclusion of stronger inductive biases in models to improve generalisation. This paper proposes an alternative strategy, inverse value estimation for interpretable policy certificates (IV-Posterior), which seeks to identify the inductive biases or idealised conditions of operation already held by pre-trained policies, and then use this information to guide their deployment. IV-Posterior uses MaskedAutoregressive Flows to fit distributions over the set of conditions or environmental parameters in which a policy is likely to be effective. This distribution can then be used as a policy certificate in downstream applications. We illustrate the use of IV-Posterior across a two environments, and show that substantial performance gains can be obtained when policy selection incorporates knowledge of the inductive biases that these policies hold.
Residual Learning from Demonstration
Aug 18, 2020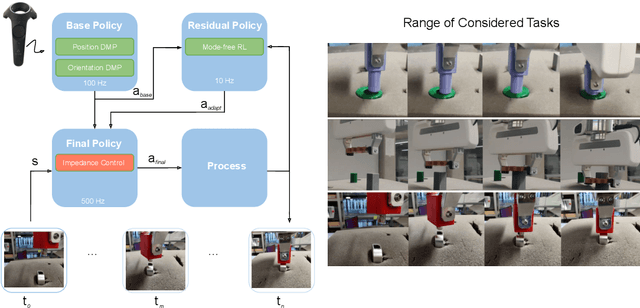
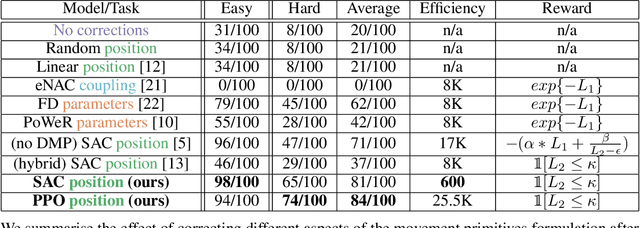
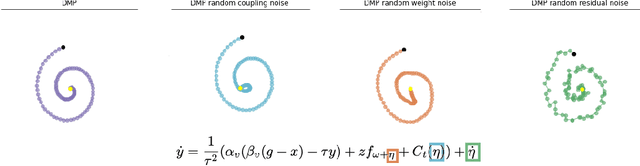
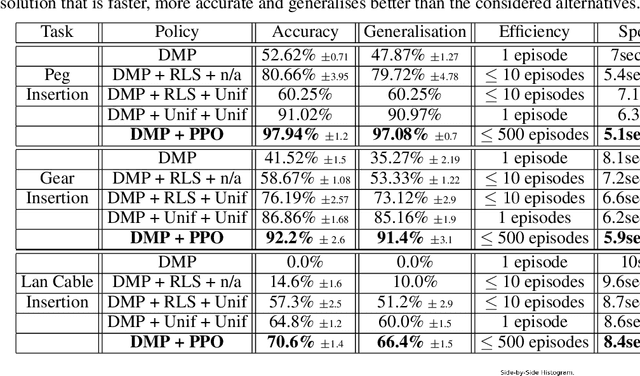
Contacts and friction are inherent to nearly all robotic manipulation tasks. Through the motor skill of insertion, we study how robots can learn to cope when these attributes play a salient role. In this work we propose residual learning from demonstration (rLfD), a framework that combines dynamic movement primitives (DMP) that rely on behavioural cloning with a reinforcement learning (RL) based residual correction policy. The proposed solution is applied directly in task space and operates on the full pose of the robot. We show that rLfD outperforms alternatives and improves the generalisation abilities of DMPs. We evaluate this approach by training an agent to successfully perform both simulated and real world insertions of pegs, gears and plugs into respective sockets.
Action sequencing using visual permutations
Aug 03, 2020
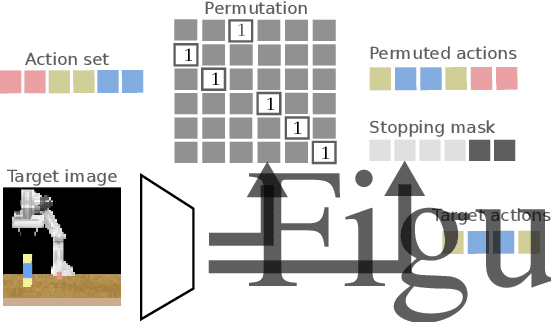
Humans can easily reason about the sequence of high level actions needed to complete tasks, but it is particularly difficult to instil this ability in robots trained from relatively few examples. This work considers the task of neural action sequencing conditioned on a single reference visual state. This task is extremely challenging as it is not only subject to the significant combinatorial complexity that arises from large action sets, but also requires a model that can perform some form of symbol grounding, mapping high dimensional input data to actions, while reasoning about action relationships. Drawing on human cognitive abilities to rearrange objects in scenes to create new configurations, we take a permutation perspective and argue that action sequencing benefits from the ability to reason about both permutations and ordering concepts. Empirical analysis shows that neural models trained with latent permutations outperform standard neural architectures in constrained action sequencing tasks. Results also show that action sequencing using visual permutations is an effective mechanism to initialise and speed up traditional planning techniques and successfully scales to far greater action set sizes than models considered previously.
NewtonianVAE: Proportional Control and Goal Identification from Pixels via Physical Latent Spaces
Jun 02, 2020
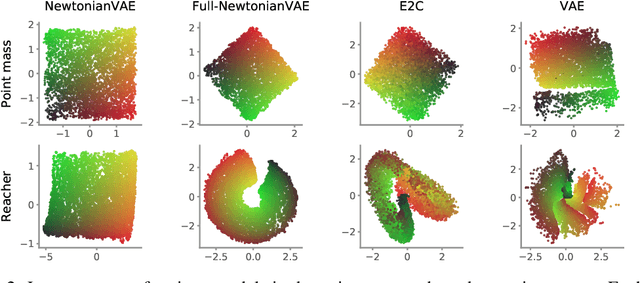
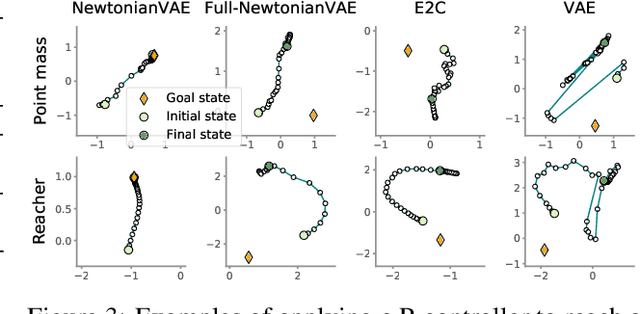
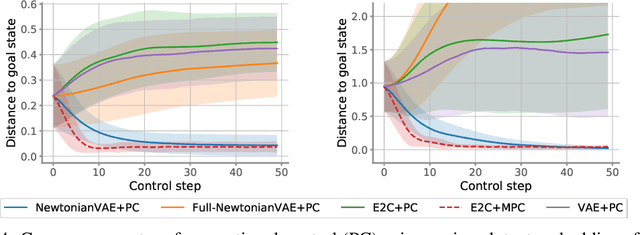
Learning low-dimensional latent state space dynamics models has been a powerful paradigm for enabling vision-based planning and learning for control. We introduce a latent dynamics learning framework that is uniquely designed to induce proportional controlability in the latent space, thus enabling the use of much simpler controllers than prior work. We show that our learned dynamics model enables proportional control from pixels, dramatically simplifies and accelerates behavioural cloning of vision-based controllers, and provides interpretable goal discovery when applied to imitation learning of switching controllers from demonstration.
Learning robotic ultrasound scanning using probabilistic temporal ranking
Feb 04, 2020This paper addresses a common class of problems where a robot learns to perform a discovery task based on example solutions, or human demonstrations. For example consider the problem of ultrasound scanning, where the demonstration requires that an expert adaptively searches for a satisfactory view of internal organs, vessels or tissue and potential anomalies while maintaining optimal contact between the probe and surface tissue. Such problems are currently solved by inferring notional rewards that, when optimised for, result in a plan that mimics demonstrations. A pivotal assumption, that plans with higher reward should be exponentially more likely, leads to the de facto approach for reward inference in robotics. While this approach of maximum entropy inverse reinforcement learning leads to a general and elegant formulation, it struggles to cope with frequently encountered sub-optimal demonstrations. In this paper, we propose an alternative approach to cope with the class of problems where sub-optimal demonstrations occur frequently. We hypothesise that, in tasks which require discovery, successive states of any demonstration are progressively more likely to be associated with a higher reward. We formalise this temporal ranking approach and show that it improves upon maximum-entropy approaches to perform reward inference for autonomous ultrasound scanning, a novel application of learning from demonstration in medical imaging.