 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSignature: Digitally Signed, Content-Encoding Watermarks for Robust and Transparent Image Authentication
Apr 24, 2026AI-powered generative models have significantly expanded the possibilities for editing, manipulating, and creating high-quality images. Particularly, images that falsely appear to originate from trusted sources pose a serious threat, undermining public trust in image authenticity. We propose DeepSignature, a novel approach that integrates the guarantees of digital signatures with the capabilities of deep neural networks. Neural networks are used both to generate content-encoding watermarks and to embed them imperceptibly into images while ensuring robust extraction. These watermarks are cryptographically verifiable, enabling source attribution and image integrity validation. DeepSignature is compatible with existing image formats and requires no special handling of signed images. It supports client-side verification, requiring only the signer's public key. Additionally, we introduce a novel latent-space verification approach to detect and localize tampering attempts. We evaluate DeepSignature in terms of imperceptibility, robustness to benign transformations, forgery detection, and its resilience against various attack scenarios. Our results highlight the inherent trade-offs between imperceptibility, robustness, and integrity verification. We demonstrate that DeepSignature reliably identifies significant forgery attempts -- achieving near 100\% in our experiments. Finally, we emphasize DeepSignature's modularity and tunable parameters, allowing adaptation to application-specific requirements. Code and model weights will be published.
Large-scale online deanonymization with LLMs
Feb 18, 2026We show that large language models can be used to perform at-scale deanonymization. With full Internet access, our agent can re-identify Hacker News users and Anthropic Interviewer participants at high precision, given pseudonymous online profiles and conversations alone, matching what would take hours for a dedicated human investigator. We then design attacks for the closed-world setting. Given two databases of pseudonymous individuals, each containing unstructured text written by or about that individual, we implement a scalable attack pipeline that uses LLMs to: (1) extract identity-relevant features, (2) search for candidate matches via semantic embeddings, and (3) reason over top candidates to verify matches and reduce false positives. Compared to prior deanonymization work (e.g., on the Netflix prize) that required structured data or manual feature engineering, our approach works directly on raw user content across arbitrary platforms. We construct three datasets with known ground-truth data to evaluate our attacks. The first links Hacker News to LinkedIn profiles, using cross-platform references that appear in the profiles. Our second dataset matches users across Reddit movie discussion communities; and the third splits a single user's Reddit history in time to create two pseudonymous profiles to be matched. In each setting, LLM-based methods substantially outperform classical baselines, achieving up to 68% recall at 90% precision compared to near 0% for the best non-LLM method. Our results show that the practical obscurity protecting pseudonymous users online no longer holds and that threat models for online privacy need to be reconsidered.
Apertus: Democratizing Open and Compliant LLMs for Global Language Environments
Sep 17, 2025



We present Apertus, a fully open suite of large language models (LLMs) designed to address two systemic shortcomings in today's open model ecosystem: data compliance and multilingual representation. Unlike many prior models that release weights without reproducible data pipelines or regard for content-owner rights, Apertus models are pretrained exclusively on openly available data, retroactively respecting robots.txt exclusions and filtering for non-permissive, toxic, and personally identifiable content. To mitigate risks of memorization, we adopt the Goldfish objective during pretraining, strongly suppressing verbatim recall of data while retaining downstream task performance. The Apertus models also expand multilingual coverage, training on 15T tokens from over 1800 languages, with ~40% of pretraining data allocated to non-English content. Released at 8B and 70B scales, Apertus approaches state-of-the-art results among fully open models on multilingual benchmarks, rivalling or surpassing open-weight counterparts. Beyond model weights, we release all scientific artifacts from our development cycle with a permissive license, including data preparation scripts, checkpoints, evaluation suites, and training code, enabling transparent audit and extension.
Membership Inference Attacks on Sequence Models
Jun 05, 2025



Sequence models, such as Large Language Models (LLMs) and autoregressive image generators, have a tendency to memorize and inadvertently leak sensitive information. While this tendency has critical legal implications, existing tools are insufficient to audit the resulting risks. We hypothesize that those tools' shortcomings are due to mismatched assumptions. Thus, we argue that effectively measuring privacy leakage in sequence models requires leveraging the correlations inherent in sequential generation. To illustrate this, we adapt a state-of-the-art membership inference attack to explicitly model within-sequence correlations, thereby demonstrating how a strong existing attack can be naturally extended to suit the structure of sequence models. Through a case study, we show that our adaptations consistently improve the effectiveness of memorization audits without introducing additional computational costs. Our work hence serves as an important stepping stone toward reliable memorization audits for large sequence models.
Measuring Non-Adversarial Reproduction of Training Data in Large Language Models
Nov 15, 2024Large language models memorize parts of their training data. Memorizing short snippets and facts is required to answer questions about the world and to be fluent in any language. But models have also been shown to reproduce long verbatim sequences of memorized text when prompted by a motivated adversary. In this work, we investigate an intermediate regime of memorization that we call non-adversarial reproduction, where we quantify the overlap between model responses and pretraining data when responding to natural and benign prompts. For a variety of innocuous prompt categories (e.g., writing a letter or a tutorial), we show that up to 15% of the text output by popular conversational language models overlaps with snippets from the Internet. In worst cases, we find generations where 100% of the content can be found exactly online. For the same tasks, we find that human-written text has far less overlap with Internet data. We further study whether prompting strategies can close this reproduction gap between models and humans. While appropriate prompting can reduce non-adversarial reproduction on average, we find that mitigating worst-case reproduction of training data requires stronger defenses -- even for benign interactions.
Evaluations of Machine Learning Privacy Defenses are Misleading
Apr 26, 2024



Empirical defenses for machine learning privacy forgo the provable guarantees of differential privacy in the hope of achieving higher utility while resisting realistic adversaries. We identify severe pitfalls in existing empirical privacy evaluations (based on membership inference attacks) that result in misleading conclusions. In particular, we show that prior evaluations fail to characterize the privacy leakage of the most vulnerable samples, use weak attacks, and avoid comparisons with practical differential privacy baselines. In 5 case studies of empirical privacy defenses, we find that prior evaluations underestimate privacy leakage by an order of magnitude. Under our stronger evaluation, none of the empirical defenses we study are competitive with a properly tuned, high-utility DP-SGD baseline (with vacuous provable guarantees).
Strong inductive biases provably prevent harmless interpolation
Jan 18, 2023



Classical wisdom suggests that estimators should avoid fitting noise to achieve good generalization. In contrast, modern overparameterized models can yield small test error despite interpolating noise -- a phenomenon often called "benign overfitting" or "harmless interpolation". This paper argues that the degree to which interpolation is harmless hinges upon the strength of an estimator's inductive bias, i.e., how heavily the estimator favors solutions with a certain structure: while strong inductive biases prevent harmless interpolation, weak inductive biases can even require fitting noise to generalize well. Our main theoretical result establishes tight non-asymptotic bounds for high-dimensional kernel regression that reflect this phenomenon for convolutional kernels, where the filter size regulates the strength of the inductive bias. We further provide empirical evidence of the same behavior for deep neural networks with varying filter sizes and rotational invariance.
Interpolation can hurt robust generalization even when there is no noise
Aug 05, 2021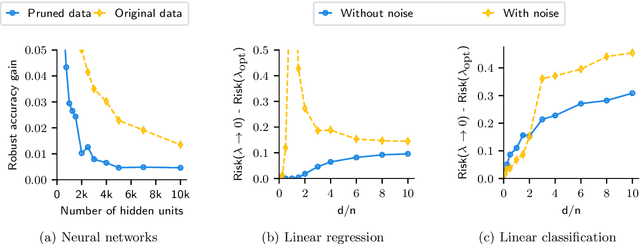
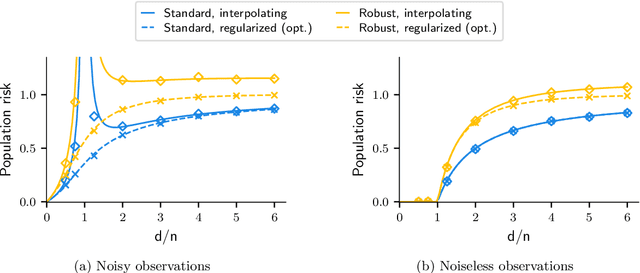
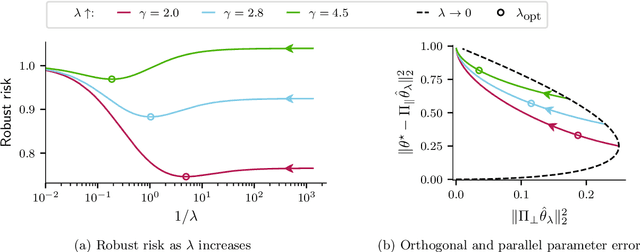
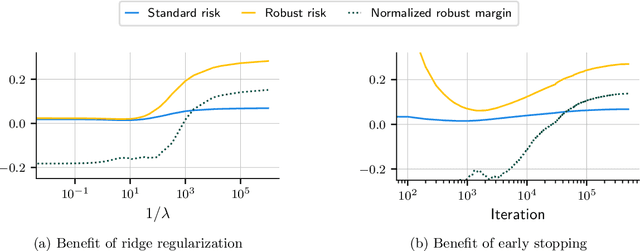
Numerous recent works show that overparameterization implicitly reduces variance for min-norm interpolators and max-margin classifiers. These findings suggest that ridge regularization has vanishing benefits in high dimensions. We challenge this narrative by showing that, even in the absence of noise, avoiding interpolation through ridge regularization can significantly improve generalization. We prove this phenomenon for the robust risk of both linear regression and classification and hence provide the first theoretical result on robust overfitting.