 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Smooth Pose Sequences for Diverse Human Motion Prediction
Aug 21, 2021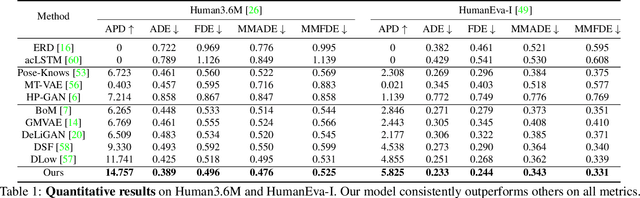
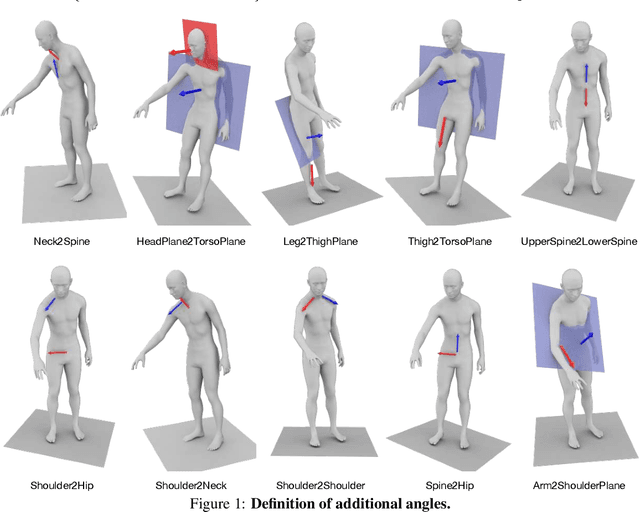
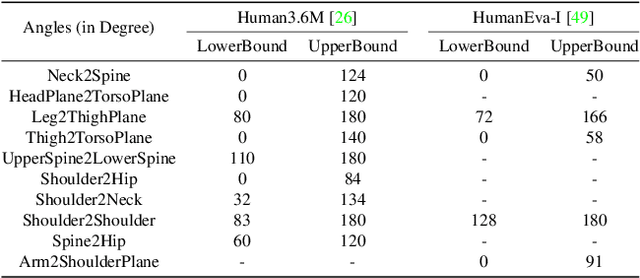
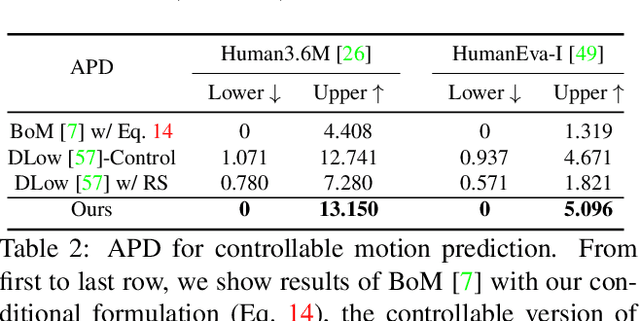
Recent progress in stochastic motion prediction, i.e., predicting multiple possible future human motions given a single past pose sequence, has led to producing truly diverse future motions and even providing control over the motion of some body parts. However, to achieve this, the state-of-the-art method requires learning several mappings for diversity and a dedicated model for controllable motion prediction. In this paper, we introduce a unified deep generative network for both diverse and controllable motion prediction. To this end, we leverage the intuition that realistic human motions consist of smooth sequences of valid poses, and that, given limited data, learning a pose prior is much more tractable than a motion one. We therefore design a generator that predicts the motion of different body parts sequentially, and introduce a normalizing flow based pose prior, together with a joint angle loss, to achieve motion realism.Our experiments on two standard benchmark datasets, Human3.6M and HumanEva-I, demonstrate that our approach outperforms the state-of-the-art baselines in terms of both sample diversity and accuracy. The code is available at https://github.com/wei-mao-2019/gsps
Multi-level Motion Attention for Human Motion Prediction
Jun 17, 2021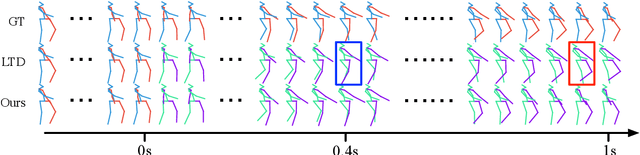
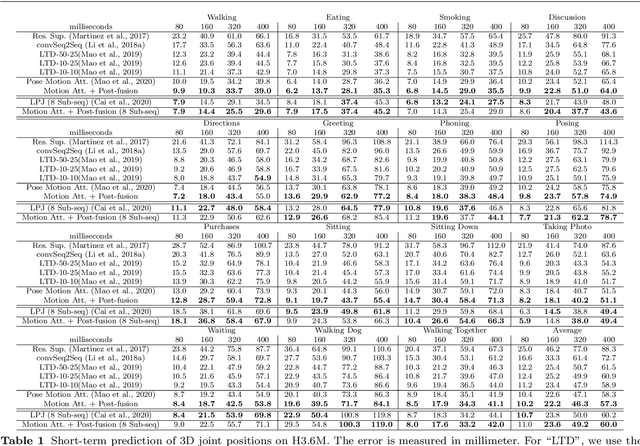
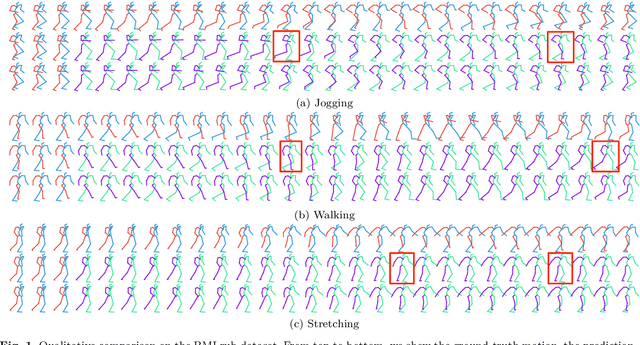

Human motion prediction aims to forecast future human poses given a historical motion. Whether based on recurrent or feed-forward neural networks, existing learning based methods fail to model the observation that human motion tends to repeat itself, even for complex sports actions and cooking activities. Here, we introduce an attention based feed-forward network that explicitly leverages this observation. In particular, instead of modeling frame-wise attention via pose similarity, we propose to extract motion attention to capture the similarity between the current motion context and the historical motion sub-sequences. In this context, we study the use of different types of attention, computed at joint, body part, and full pose levels. Aggregating the relevant past motions and processing the result with a graph convolutional network allows us to effectively exploit motion patterns from the long-term history to predict the future poses. Our experiments on Human3.6M, AMASS and 3DPW validate the benefits of our approach for both periodical and non-periodical actions. Thanks to our attention model, it yields state-of-the-art results on all three datasets. Our code is available at https://github.com/wei-mao-2019/HisRepItself.
Spatially Invariant Unsupervised 3D Object Segmentation with Graph Neural Networks
Jun 11, 2021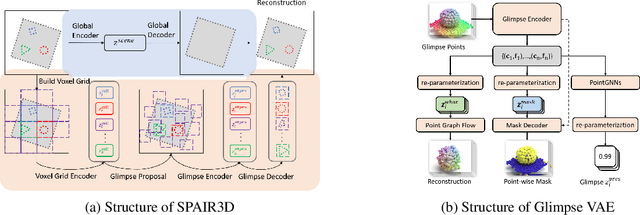
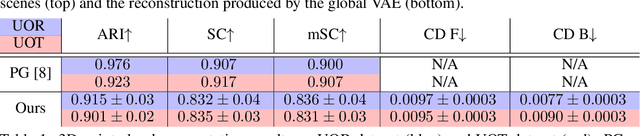
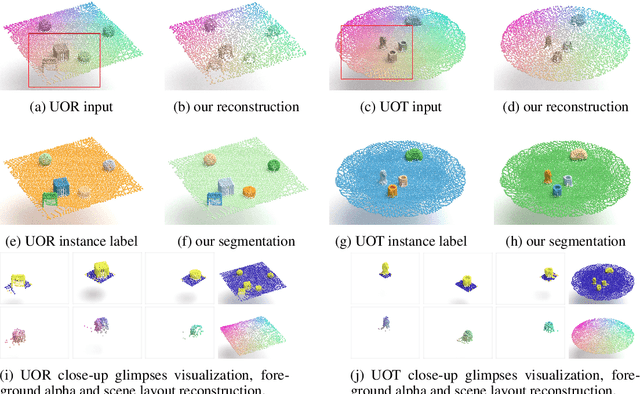
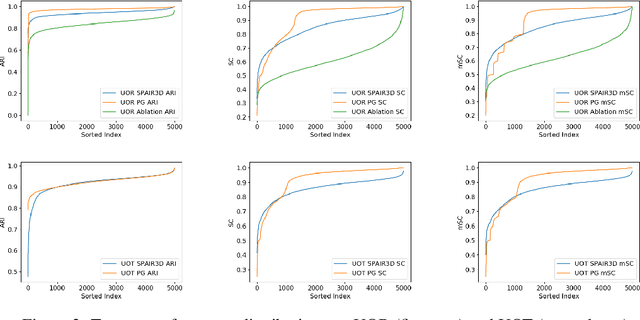
In this paper, we tackle the problem of unsupervised 3D object segmentation from a point cloud without RGB information. In particular, we propose a framework, SPAIR3D, to model a point cloud as a spatial mixture model and jointly learn the multiple-object representation and segmentation in 3D via Variational Autoencoders (VAE). Inspired by SPAIR, we adopt an object-specification scheme that describes each object's location relative to its local voxel grid cell rather than the point cloud as a whole. To model the spatial mixture model on point clouds, we derive the Chamfer Likelihood, which fits naturally into the variational training pipeline. We further design a new spatially invariant graph neural network to generate a varying number of 3D points as a decoder within our VAE. Experimental results demonstrate that SPAIR3D is capable of detecting and segmenting variable number of objects without appearance information across diverse scenes.
Dense Reconstruction of Transparent Objects by Altering Incident Light Paths Through Refraction
May 20, 2021
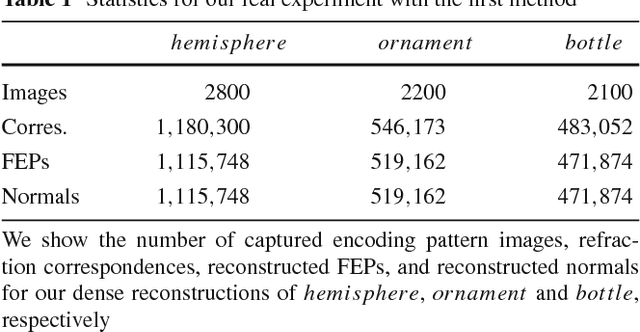
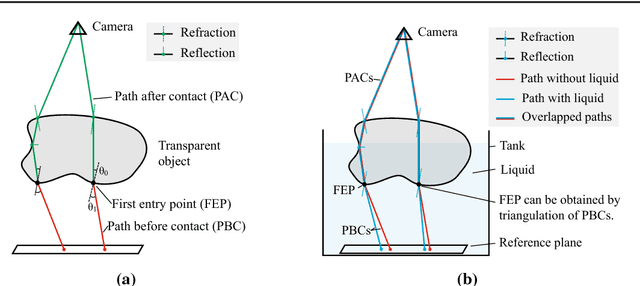

This paper addresses the problem of reconstructing the surface shape of transparent objects. The difficulty of this problem originates from the viewpoint dependent appearance of a transparent object, which quickly makes reconstruction methods tailored for diffuse surfaces fail disgracefully. In this paper, we introduce a fixed viewpoint approach to dense surface reconstruction of transparent objects based on refraction of light. We present a simple setup that allows us to alter the incident light paths before light rays enter the object by immersing the object partially in a liquid, and develop a method for recovering the object surface through reconstructing and triangulating such incident light paths. Our proposed approach does not need to model the complex interactions of light as it travels through the object, neither does it assume any parametric form for the object shape nor the exact number of refractions and reflections taken place along the light paths. It can therefore handle transparent objects with a relatively complex shape and structure, with unknown and inhomogeneous refractive index. We also show that for thin transparent objects, our proposed acquisition setup can be further simplified by adopting a single refraction approximation. Experimental results on both synthetic and real data demonstrate the feasibility and accuracy of our proposed approach.
Self-supervised Learning of Depth Inference for Multi-view Stereo
Apr 07, 2021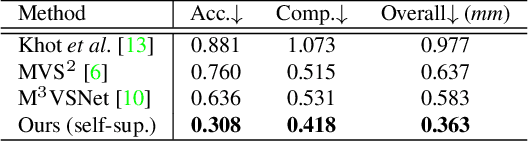
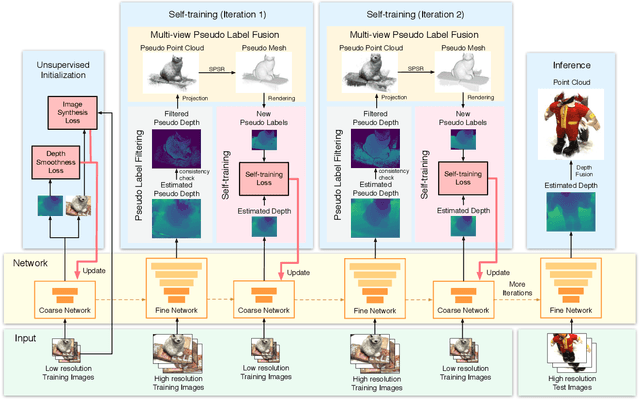
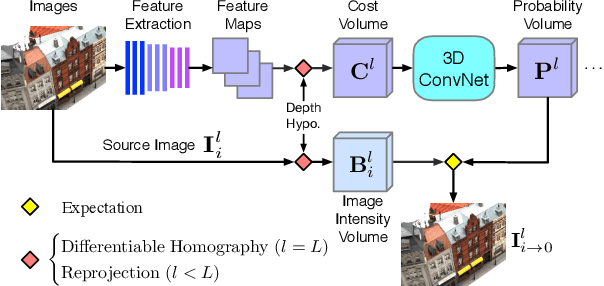
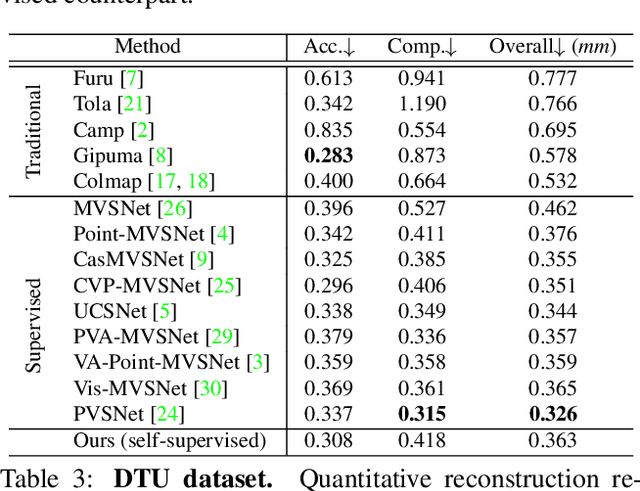
Recent supervised multi-view depth estimation networks have achieved promising results. Similar to all supervised approaches, these networks require ground-truth data during training. However, collecting a large amount of multi-view depth data is very challenging. Here, we propose a self-supervised learning framework for multi-view stereo that exploit pseudo labels from the input data. We start by learning to estimate depth maps as initial pseudo labels under an unsupervised learning framework relying on image reconstruction loss as supervision. We then refine the initial pseudo labels using a carefully designed pipeline leveraging depth information inferred from higher resolution images and neighboring views. We use these high-quality pseudo labels as the supervision signal to train the network and improve, iteratively, its performance by self-training. Extensive experiments on the DTU dataset show that our proposed self-supervised learning framework outperforms existing unsupervised multi-view stereo networks by a large margin and performs on par compared to the supervised counterpart. Code is available at https://github.com/JiayuYANG/Self-supervised-CVP-MVSNet.
Fixed Viewpoint Mirror Surface Reconstruction under an Uncalibrated Camera
Jan 23, 2021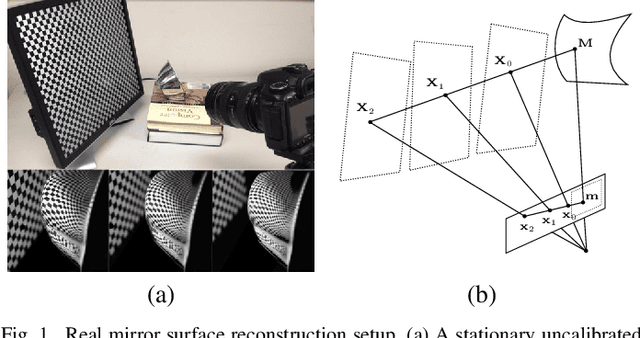
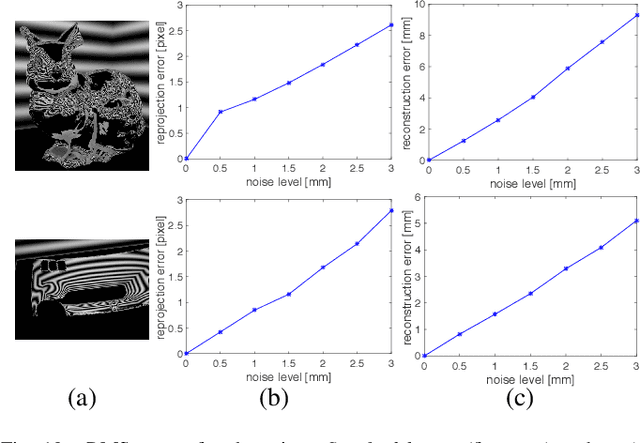
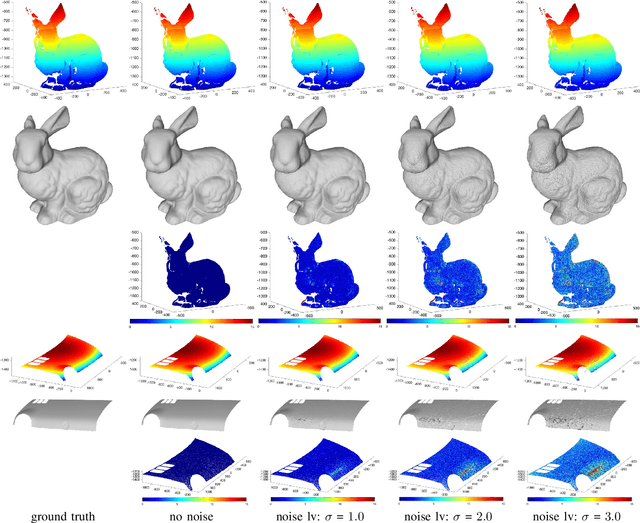
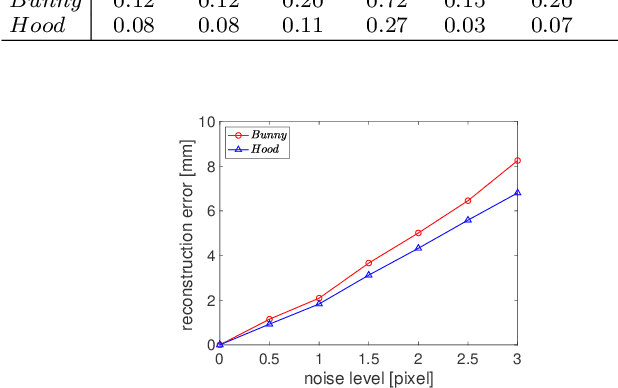
This paper addresses the problem of mirror surface reconstruction, and proposes a solution based on observing the reflections of a moving reference plane on the mirror surface. Unlike previous approaches which require tedious calibration, our method can recover the camera intrinsics, the poses of the reference plane, as well as the mirror surface from the observed reflections of the reference plane under at least three unknown distinct poses. We first show that the 3D poses of the reference plane can be estimated from the reflection correspondences established between the images and the reference plane. We then form a bunch of 3D lines from the reflection correspondences, and derive an analytical solution to recover the line projection matrix. We transform the line projection matrix to its equivalent camera projection matrix, and propose a cross-ratio based formulation to optimize the camera projection matrix by minimizing reprojection errors. The mirror surface is then reconstructed based on the optimized cross-ratio constraint. Experimental results on both synthetic and real data are presented, which demonstrate the feasibility and accuracy of our method.
Dual Pixel Exploration: Simultaneous Depth Estimation and Image Restoration
Dec 01, 2020
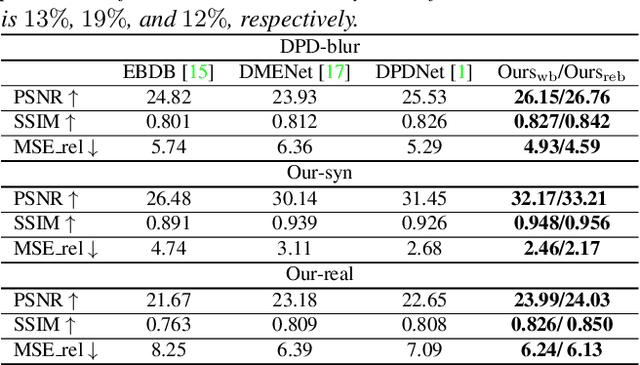
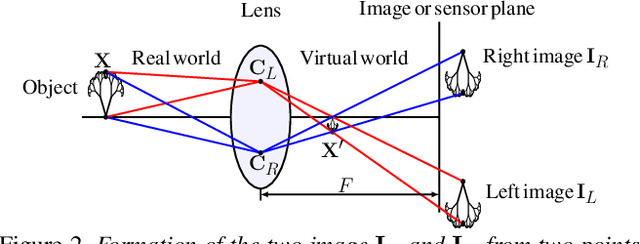
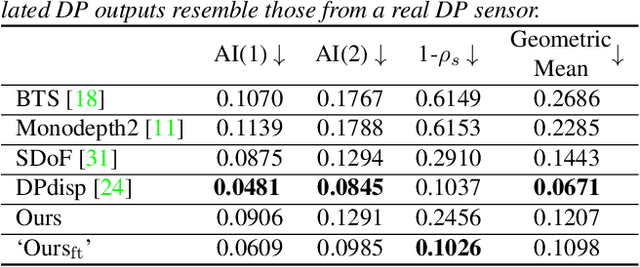
The dual-pixel (DP) hardware works by splitting each pixel in half and creating an image pair in a single snapshot. Several works estimate depth/inverse depth by treating the DP pair as a stereo pair. However, dual-pixel disparity only occurs in image regions with the defocus blur. The heavy defocus blur in DP pairs affects the performance of matching-based depth estimation approaches. Instead of removing the blur effect blindly, we study the formation of the DP pair which links the blur and the depth information. In this paper, we propose a mathematical DP model which can benefit depth estimation by the blur. These explorations motivate us to propose an end-to-end DDDNet (DP-based Depth and Deblur Network) to jointly estimate the depth and restore the image. Moreover, we define a reblur loss, which reflects the relationship of the DP image formation process with depth information, to regularise our depth estimate in training. To meet the requirement of a large amount of data for learning, we propose the first DP image simulator which allows us to create datasets with DP pairs from any existing RGBD dataset. As a side contribution, we collect a real dataset for further research. Extensive experimental evaluation on both synthetic and real datasets shows that our approach achieves competitive performance compared to state-of-the-art approaches.
History Repeats Itself: Human Motion Prediction via Motion Attention
Jul 23, 2020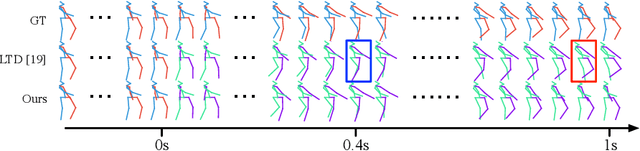
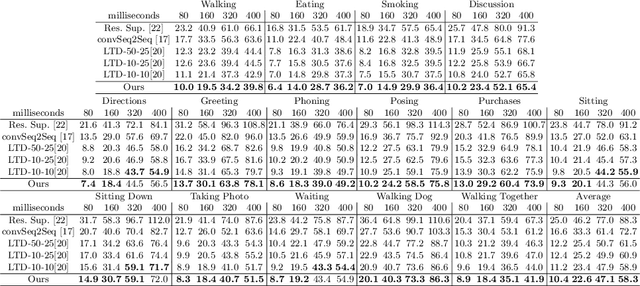
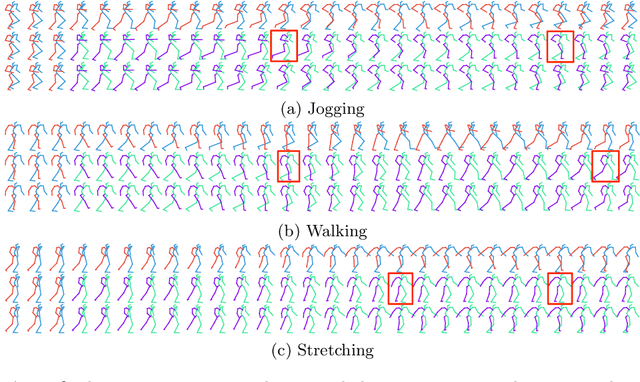
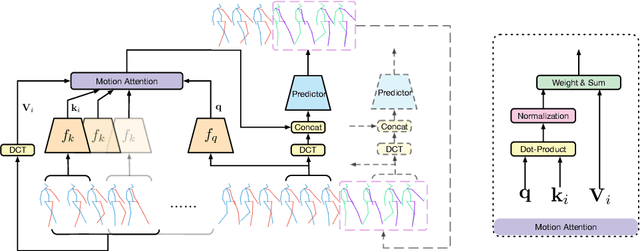
Human motion prediction aims to forecast future human poses given a past motion. Whether based on recurrent or feed-forward neural networks, existing methods fail to model the observation that human motion tends to repeat itself, even for complex sports actions and cooking activities. Here, we introduce an attention-based feed-forward network that explicitly leverages this observation. In particular, instead of modeling frame-wise attention via pose similarity, we propose to extract motion attention to capture the similarity between the current motion context and the historical motion sub-sequences. Aggregating the relevant past motions and processing the result with a graph convolutional network allows us to effectively exploit motion patterns from the long-term history to predict the future poses. Our experiments on Human3.6M, AMASS and 3DPW evidence the benefits of our approach for both periodical and non-periodical actions. Thanks to our attention model, it yields state-of-the-art results on all three datasets. Our code is available at https://github.com/wei-mao-2019/HisRepItself.
Single Image Optical Flow Estimation with an Event Camera
Apr 01, 2020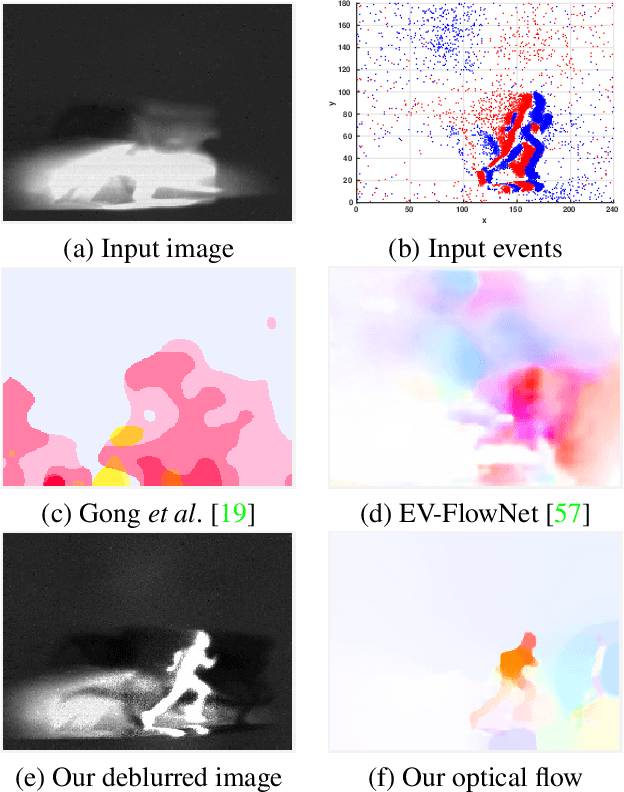

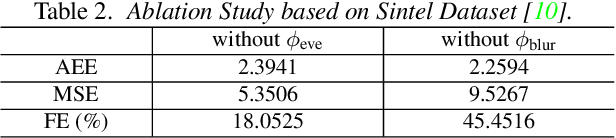
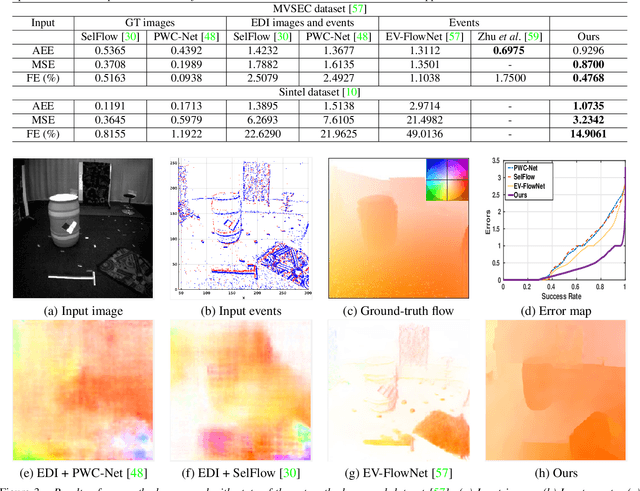
Event cameras are bio-inspired sensors that asynchronously report intensity changes in microsecond resolution. DAVIS can capture high dynamics of a scene and simultaneously output high temporal resolution events and low frame-rate intensity images. In this paper, we propose a single image (potentially blurred) and events based optical flow estimation approach. First, we demonstrate how events can be used to improve flow estimates. To this end, we encode the relation between flow and events effectively by presenting an event-based photometric consistency formulation. Then, we consider the special case of image blur caused by high dynamics in the visual environments and show that including the blur formation in our model further constrains flow estimation. This is in sharp contrast to existing works that ignore the blurred images while our formulation can naturally handle either blurred or sharp images to achieve accurate flow estimation. Finally, we reduce flow estimation, as well as image deblurring, to an alternative optimization problem of an objective function using the primal-dual algorithm. Experimental results on both synthetic and real data (with blurred and non-blurred images) show the superiority of our model in comparison to state-of-the-art approaches.
Joint Unsupervised Learning of Optical Flow and Egomotion with Bi-Level Optimization
Feb 26, 2020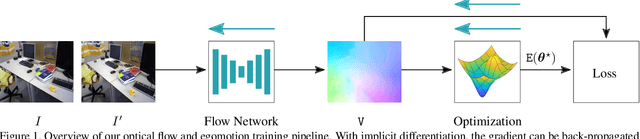
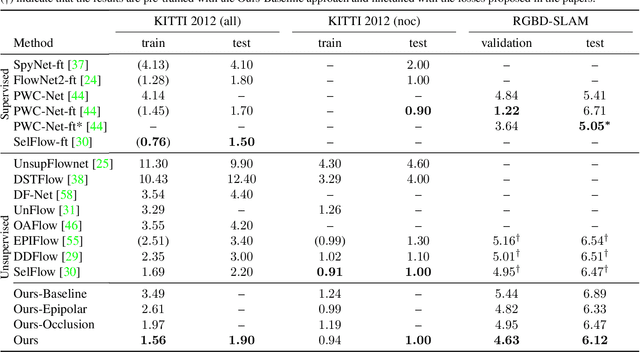

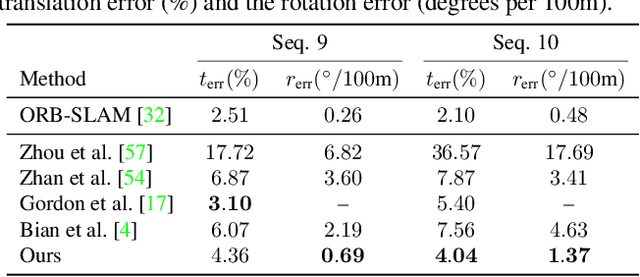
We address the problem of joint optical flow and camera motion estimation in rigid scenes by incorporating geometric constraints into an unsupervised deep learning framework. Unlike existing approaches which rely on brightness constancy and local smoothness for optical flow estimation, we exploit the global relationship between optical flow and camera motion using epipolar geometry. In particular, we formulate the prediction of optical flow and camera motion as a bi-level optimization problem, consisting of an upper-level problem to estimate the flow that conforms to the predicted camera motion, and a lower-level problem to estimate the camera motion given the predicted optical flow. We use implicit differentiation to enable back-propagation through the lower-level geometric optimization layer independent of its implementation, allowing end-to-end training of the network. With globally-enforced geometric constraints, we are able to improve the quality of the estimated optical flow in challenging scenarios and obtain better camera motion estimates compared to other unsupervised learning methods.