 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive 3D UI Placement in Mixed Reality Using Deep Reinforcement Learning
Apr 30, 2025



Mixed Reality (MR) could assist users' tasks by continuously integrating virtual content with their view of the physical environment. However, where and how to place these content to best support the users has been a challenging problem due to the dynamic nature of MR experiences. In contrast to prior work that investigates optimization-based methods, we are exploring how reinforcement learning (RL) could assist with continuous 3D content placement that is aware of users' poses and their surrounding environments. Through an initial exploration and preliminary evaluation, our results demonstrate the potential of RL to position content that maximizes the reward for users on the go. We further identify future directions for research that could harness the power of RL for personalized and optimized UI and content placement in MR.
* In Extended Abstracts of the CHI Conference on Human Factors in Computing Systems (CHI EA '24)
Enabling Data-Driven and Empathetic Interactions: A Context-Aware 3D Virtual Agent in Mixed Reality for Enhanced Financial Customer Experience
Oct 15, 2024

In this paper, we introduce a novel system designed to enhance customer service in the financial and retail sectors through a context-aware 3D virtual agent, utilizing Mixed Reality (MR) and Vision Language Models (VLMs). Our approach focuses on enabling data-driven and empathetic interactions that ensure customer satisfaction by introducing situational awareness of the physical location, personalized interactions based on customer profiles, and rigorous privacy and security standards. We discuss our design considerations critical for deployment in real-world customer service environments, addressing challenges in user data management and sensitive information handling. We also outline the system architecture and key features unique to banking and retail environments. Our work demonstrates the potential of integrating MR and VLMs in service industries, offering practical insights in customer service delivery while maintaining high standards of security and personalization.
Simple and Efficient Partial Graph Adversarial Attack: A New Perspective
Aug 15, 2023



As the study of graph neural networks becomes more intensive and comprehensive, their robustness and security have received great research interest. The existing global attack methods treat all nodes in the graph as their attack targets. Although existing methods have achieved excellent results, there is still considerable space for improvement. The key problem is that the current approaches rigidly follow the definition of global attacks. They ignore an important issue, i.e., different nodes have different robustness and are not equally resilient to attacks. From a global attacker's view, we should arrange the attack budget wisely, rather than wasting them on highly robust nodes. To this end, we propose a totally new method named partial graph attack (PGA), which selects the vulnerable nodes as attack targets. First, to select the vulnerable items, we propose a hierarchical target selection policy, which allows attackers to only focus on easy-to-attack nodes. Then, we propose a cost-effective anchor-picking policy to pick the most promising anchors for adding or removing edges, and a more aggressive iterative greedy-based attack method to perform more efficient attacks. Extensive experimental results demonstrate that PGA can achieve significant improvements in both attack effect and attack efficiency compared to other existing graph global attack methods.
Enhancing Virtual Assistant Intelligence: Precise Area Targeting for Instance-level User Intents beyond Metadata
Jun 07, 2023Virtual assistants have been widely used by mobile phone users in recent years. Although their capabilities of processing user intents have been developed rapidly, virtual assistants in most platforms are only capable of handling pre-defined high-level tasks supported by extra manual efforts of developers. However, instance-level user intents containing more detailed objectives with complex practical situations, are yet rarely studied so far. In this paper, we explore virtual assistants capable of processing instance-level user intents based on pixels of application screens, without the requirements of extra extensions on the application side. We propose a novel cross-modal deep learning pipeline, which understands the input vocal or textual instance-level user intents, predicts the targeting operational area, and detects the absolute button area on screens without any metadata of applications. We conducted a user study with 10 participants to collect a testing dataset with instance-level user intents. The testing dataset is then utilized to evaluate the performance of our model, which demonstrates that our model is promising with the achievement of 64.43% accuracy on our testing dataset.
Convolutional Neural Network with Pruning Method for Handwritten Digit Recognition
Jan 15, 2021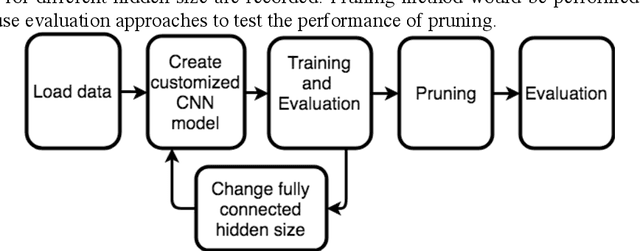
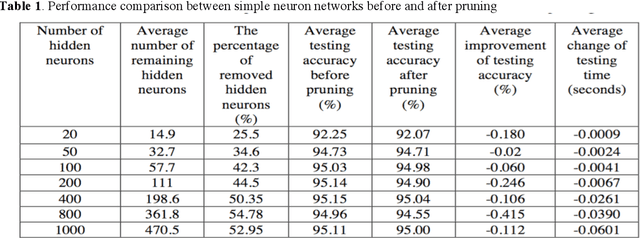
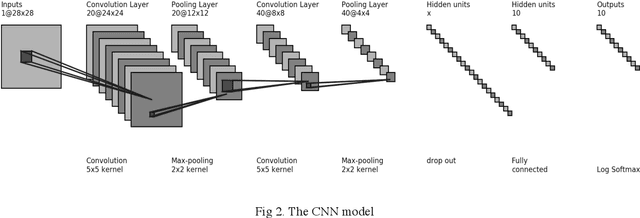

CNN model is a popular method for imagery analysis, so it could be utilized to recognize handwritten digits based on MNIST datasets. For higher recognition accuracy, various CNN models with different fully connected layer sizes are exploited to figure out the relationship between the CNN fully connected layer size and the recognition accuracy. Inspired by previous pruning work, we performed pruning methods of distinctiveness on CNN models and compared the pruning performance with NN models. For better pruning performances on CNN, the effect of angle threshold on the pruning performance was explored. The evaluation results show that: for the fully connected layer size, there is a threshold, so that when the layer size increases, the recognition accuracy grows if the layer size smaller than the threshold, and falls if the layer size larger than the threshold; the performance of pruning performed on CNN is worse than on NN; as pruning angle threshold increases, the fully connected layer size and the recognition accuracy decreases. This paper also shows that for CNN models trained by the MNIST dataset, they are capable of handwritten digit recognition and achieve the highest recognition accuracy with fully connected layer size 400. In addition, for same dataset MNIST, CNN models work better than big, deep, simple NN models in a published paper.