 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-Efficient Online Continual Object Detection in Streaming Video
Jun 01, 2022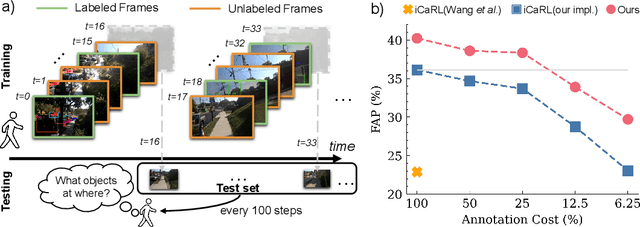
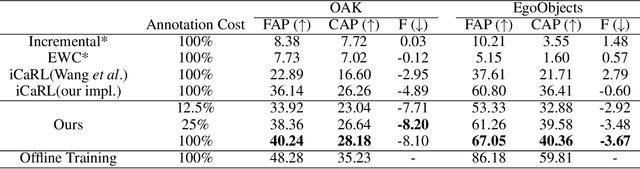
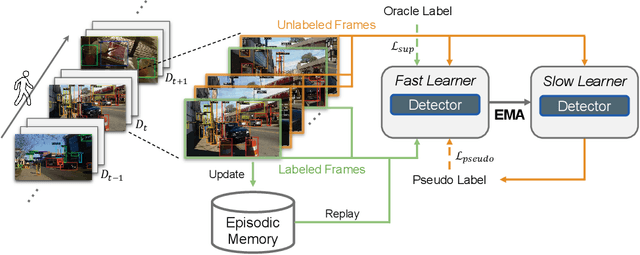

To thrive in evolving environments, humans are capable of continual acquisition and transfer of new knowledge, from a continuous video stream, with minimal supervisions, while retaining previously learnt experiences. In contrast to human learning, most standard continual learning benchmarks focus on learning from static iid images in fully supervised settings. Here, we examine a more realistic and challenging problem$\unicode{x2014}$Label-Efficient Online Continual Object Detection (LEOCOD) in video streams. By addressing this problem, it would greatly benefit many real-world applications with reduced annotation costs and retraining time. To tackle this problem, we seek inspirations from complementary learning systems (CLS) in human brains and propose a computational model, dubbed as Efficient-CLS. Functionally correlated with the hippocampus and the neocortex in CLS, Efficient-CLS posits a memory encoding mechanism involving bidirectional interaction between fast and slow learners via synaptic weight transfers and pattern replays. We test Efficient-CLS and competitive baselines in two challenging real-world video stream datasets. Like humans, Efficient-CLS learns to detect new object classes incrementally from a continuous temporal stream of non-repeating video with minimal forgetting. Remarkably, with only 25% annotated video frames, our Efficient-CLS still leads among all comparative models, which are trained with 100% annotations on all video frames. The data and source code will be publicly available at https://github.com/showlab/Efficient-CLS.
Visual Search Asymmetry: Deep Nets and Humans Share Similar Inherent Biases
Jun 05, 2021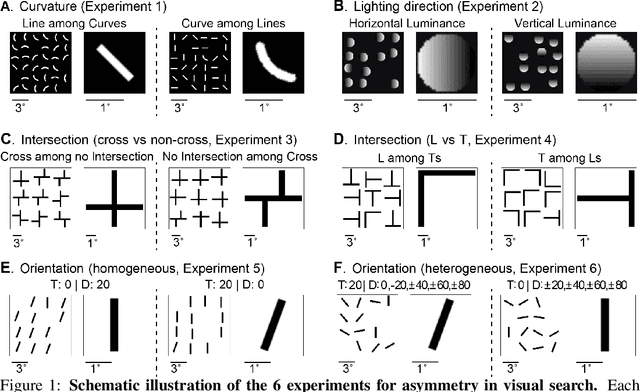
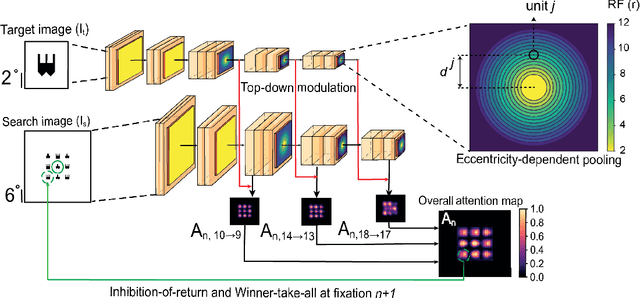
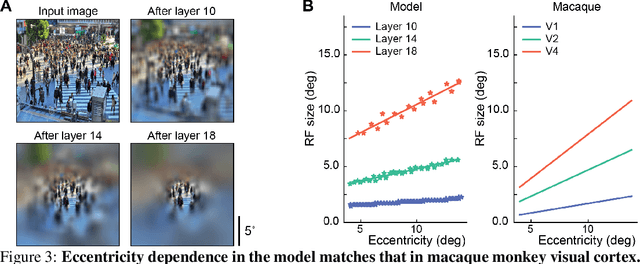
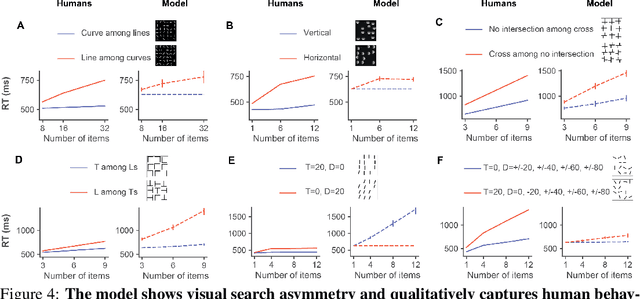
Visual search is a ubiquitous and often challenging daily task, exemplified by looking for the car keys at home or a friend in a crowd. An intriguing property of some classical search tasks is an asymmetry such that finding a target A among distractors B can be easier than finding B among A. To elucidate the mechanisms responsible for asymmetry in visual search, we propose a computational model that takes a target and a search image as inputs and produces a sequence of eye movements until the target is found. The model integrates eccentricity-dependent visual recognition with target-dependent top-down cues. We compared the model against human behavior in six paradigmatic search tasks that show asymmetry in humans. Without prior exposure to the stimuli or task-specific training, the model provides a plausible mechanism for search asymmetry. We hypothesized that the polarity of search asymmetry arises from experience with the natural environment. We tested this hypothesis by training the model on an augmented version of ImageNet where the biases of natural images were either removed or reversed. The polarity of search asymmetry disappeared or was altered depending on the training protocol. This study highlights how classical perceptual properties can emerge in neural network models, without the need for task-specific training, but rather as a consequence of the statistical properties of the developmental diet fed to the model. All source code and stimuli are publicly available https://github.com/kreimanlab/VisualSearchAsymmetry
Hypothesis-driven Stream Learning with Augmented Memory
Apr 07, 2021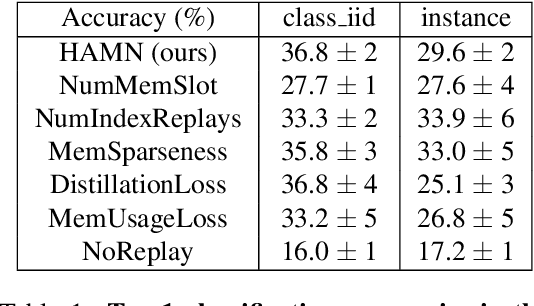
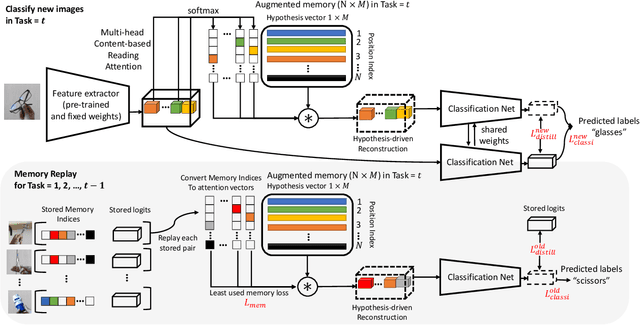
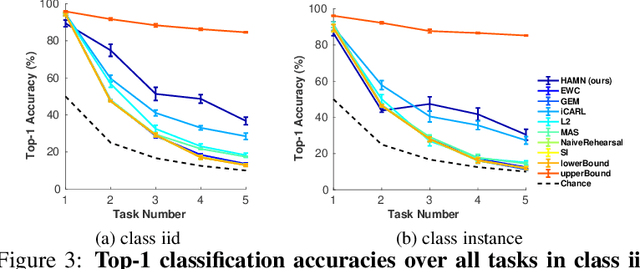
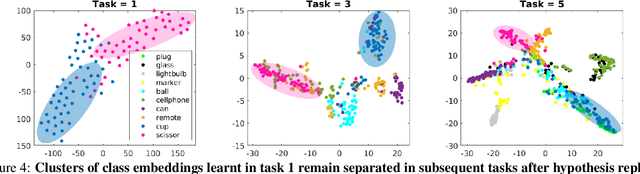
Stream learning refers to the ability to acquire and transfer knowledge across a continuous stream of data without forgetting and without repeated passes over the data. A common way to avoid catastrophic forgetting is to intersperse new examples with replays of old examples stored as image pixels or reproduced by generative models. Here, we considered stream learning in image classification tasks and proposed a novel hypotheses-driven Augmented Memory Network, which efficiently consolidates previous knowledge with a limited number of hypotheses in the augmented memory and replays relevant hypotheses to avoid catastrophic forgetting. The advantages of hypothesis-driven replay over image pixel replay and generative replay are two-fold. First, hypothesis-based knowledge consolidation avoids redundant information in the image pixel space and makes memory usage more efficient. Second, hypotheses in the augmented memory can be re-used for learning new tasks, improving generalization and transfer learning ability. We evaluated our method on three stream learning object recognition datasets. Our method performs comparably well or better than SOTA methods, while offering more efficient memory usage. All source code and data are publicly available https://github.com/kreimanlab/AugMem.
When Pigs Fly: Contextual Reasoning in Synthetic and Natural Scenes
Apr 06, 2021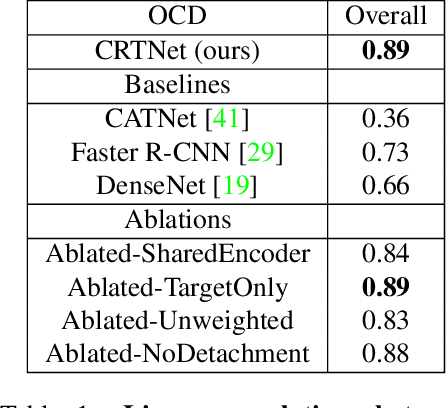
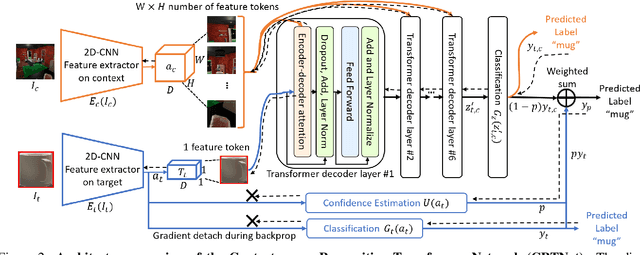
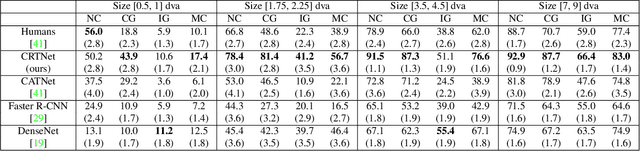
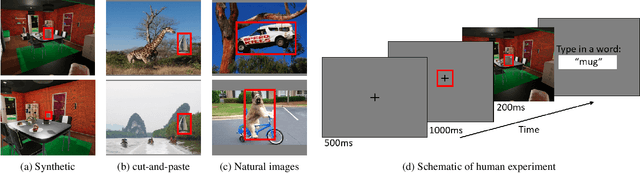
Context is of fundamental importance to both human and machine vision -- an object in the air is more likely to be an airplane, than a pig. The rich notion of context incorporates several aspects including physics rules, statistical co-occurrences, and relative object sizes, among others. While previous works have crowd-sourced out-of-context photographs from the web to study scene context, controlling the nature and extent of contextual violations has been an extremely daunting task. Here we introduce a diverse, synthetic Out-of-Context Dataset (OCD) with fine-grained control over scene context. By leveraging a 3D simulation engine, we systematically control the gravity, object co-occurrences and relative sizes across 36 object categories in a virtual household environment. We then conduct a series of experiments to gain insights into the impact of contextual cues on both human and machine vision using OCD. First, we conduct psycho-physics experiments to establish a human benchmark for out-of-context recognition, and then compare it with state-of-the-art computer vision models to quantify the gap between the two. Finally, we propose a context-aware recognition transformer model, fusing object and contextual information via multi-head attention. Our model captures useful information for contextual reasoning, enabling human-level performance and significantly better robustness in out-of-context conditions compared to baseline models across OCD and other existing out-of-context natural image datasets. All source code and data are publicly available https://github.com/kreimanlab/WhenPigsFlyContext.
Look Twice: A Computational Model of Return Fixations across Tasks and Species
Jan 05, 2021
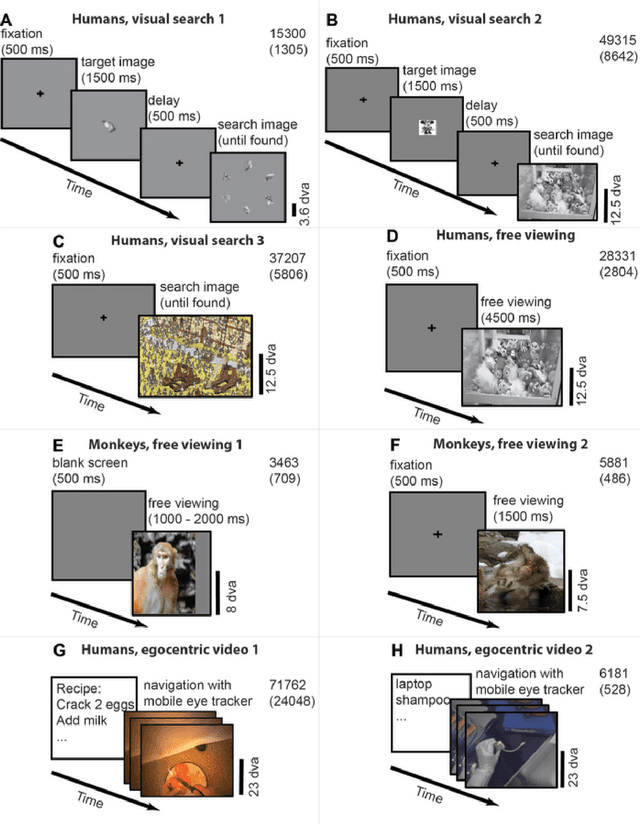
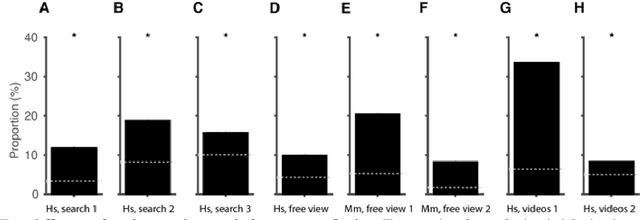
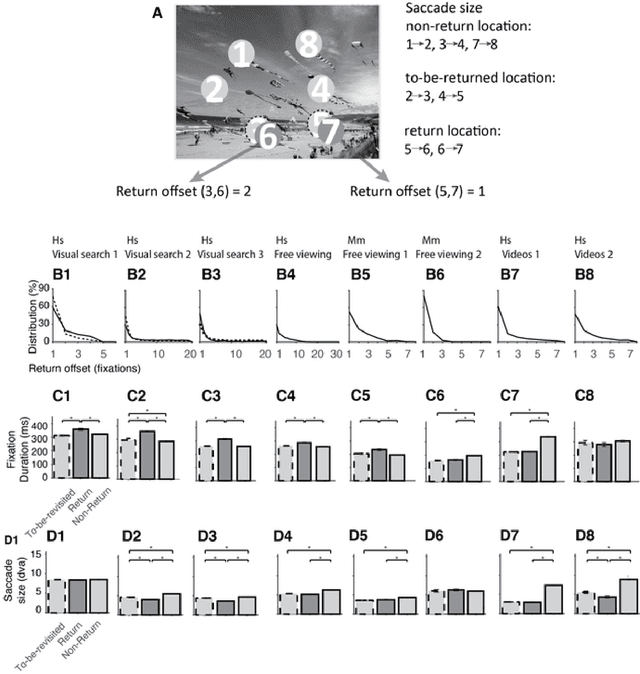
Saccadic eye movements allow animals to bring different parts of an image into high-resolution. During free viewing, inhibition of return incentivizes exploration by discouraging previously visited locations. Despite this inhibition, here we show that subjects make frequent return fixations. We systematically studied a total of 44,328 return fixations out of 217,440 fixations across different tasks, in monkeys and humans, and in static images or egocentric videos. The ubiquitous return fixations were consistent across subjects, tended to occur within short offsets, and were characterized by longer duration than non-return fixations. The locations of return fixations corresponded to image areas of higher saliency and higher similarity to the sought target during visual search tasks. We propose a biologically-inspired computational model that capitalizes on a deep convolutional neural network for object recognition to predict a sequence of fixations. Given an input image, the model computes four maps that constrain the location of the next saccade: a saliency map, a target similarity map, a saccade size map, and a memory map. The model exhibits frequent return fixations and approximates the properties of return fixations across tasks and species. The model provides initial steps towards capturing the trade-off between exploitation of informative image locations combined with exploration of novel image locations during scene viewing.
What am I Searching for: Zero-shot Target Identity Inference in Visual Search
May 28, 2020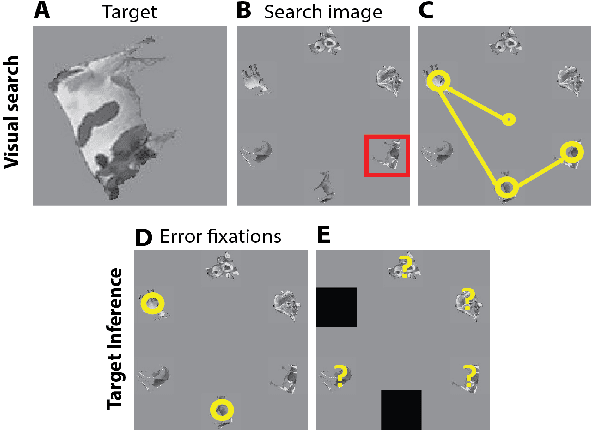
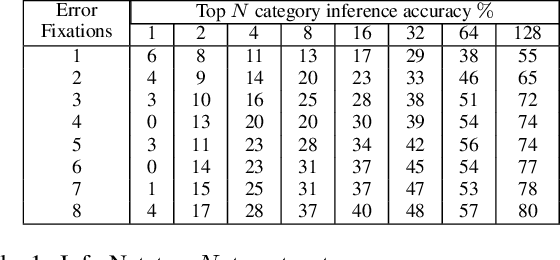
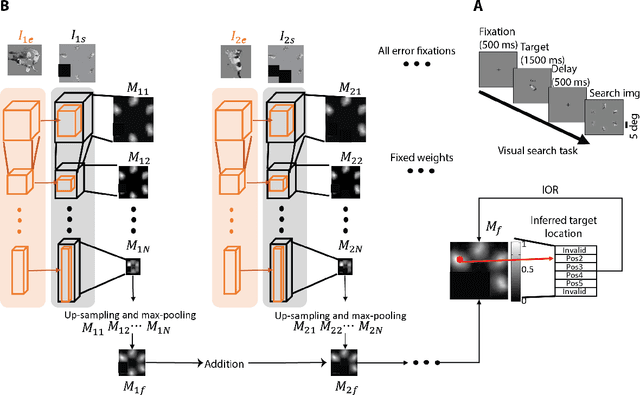
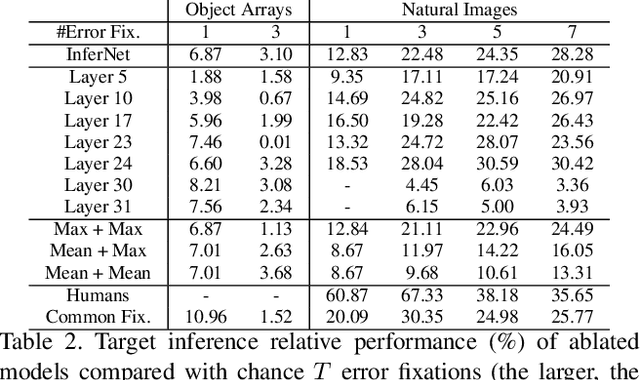
Can we infer intentions from a person's actions? As an example problem, here we consider how to decipher what a person is searching for by decoding their eye movement behavior. We conducted two psychophysics experiments where we monitored eye movements while subjects searched for a target object. We defined the fixations falling on \textit{non-target} objects as "error fixations". Using those error fixations, we developed a model (InferNet) to infer what the target was. InferNet uses a pre-trained convolutional neural network to extract features from the error fixations and computes a similarity map between the error fixations and all locations across the search image. The model consolidates the similarity maps across layers and integrates these maps across all error fixations. InferNet successfully identifies the subject's goal and outperforms competitive null models, even without any object-specific training on the inference task.
Putting visual object recognition in context
Dec 09, 2019


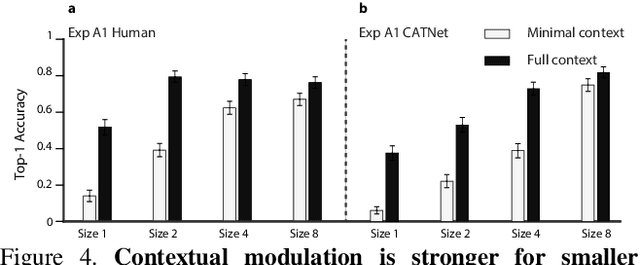
Context plays an important role in visual recognition. Recent studies have shown that visual recognition networks can be fooled by placing objects in inconsistent contexts (e.g. a cow in the ocean). To understand and model the role of contextual information in visual recognition, we systematically and quantitatively investigated ten critical properties of where, when, and how context modulates recognition including amount of context, context and object resolution, geometrical structure of context, context congruence, time required to incorporate contextual information, and temporal dynamics of contextual modulation. The tasks involve recognizing a target object surrounded with context in a natural image. As an essential benchmark, we first describe a series of psychophysics experiments, where we alter one aspect of context at a time, and quantify human recognition accuracy. To computationally assess performance on the same tasks, we propose a biologically inspired context aware object recognition model consisting of a two-stream architecture. The model processes visual information at the fovea and periphery in parallel, dynamically incorporates both object and contextual information, and sequentially reasons about the class label for the target object. Across a wide range of behavioral tasks, the model approximates human level performance without retraining for each task, captures the dependence of context enhancement on image properties, and provides initial steps towards integrating scene and object information for visual recognition.
Prototype Reminding for Continual Learning
May 23, 2019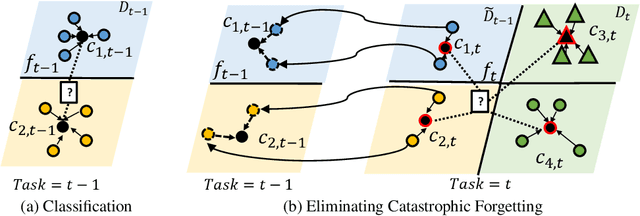
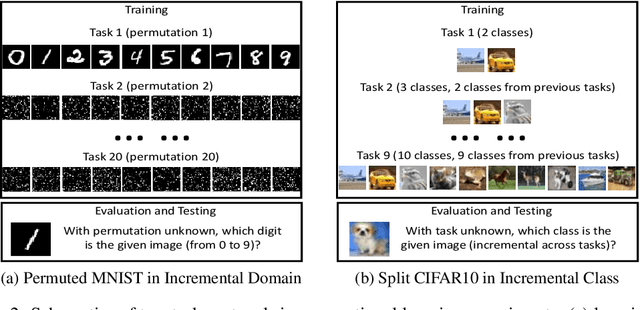
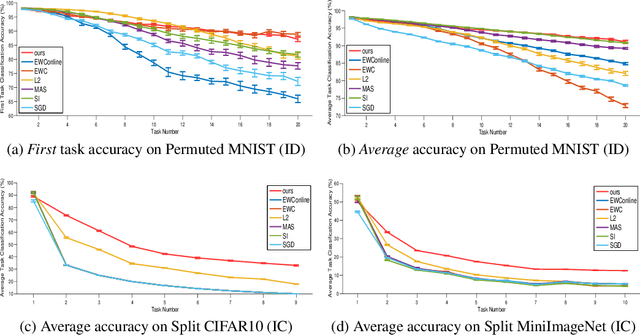
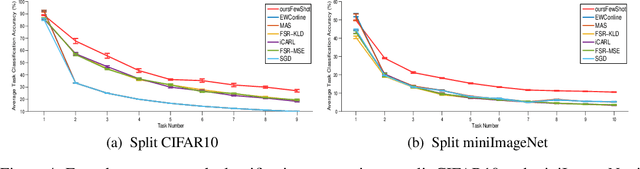
Continual learning is a critical ability of continually acquiring and transferring knowledge without catastrophically forgetting previously learned knowledge. However, enabling continual learning for AI remains a long-standing challenge. In this work, we propose a novel method, Prototype Reminding, that efficiently embeds and recalls previously learnt knowledge to tackle catastrophic forgetting issue. In particular, we consider continual learning in classification tasks. For each classification task, our method learns a metric space containing a set of prototypes where embedding of the samples from the same class cluster around prototypes and class-representative prototypes are separated apart. To alleviate catastrophic forgetting, our method preserves the embedding function from the samples to the previous metric space, through our proposed prototype reminding from previous tasks. Specifically, the reminding process is implemented by replaying a small number of samples from previous tasks and correspondingly matching their embedding to their nearest class-representative prototypes. Compared with recent continual learning methods, our contributions are fourfold: first, our method achieves the best memory retention capability while adapting quickly to new tasks. Second, our method uses metric learning for classification, and does not require adding in new neurons given new object classes. Third, our method is more memory efficient since only class-representative prototypes need to be recalled. Fourth, our method suggests a promising solution for few-shot continual learning. Without tampering with the performance on initial tasks, our method learns novel concepts given a few training examples of each class in new tasks.
Lift-the-Flap: Context Reasoning Using Object-Centered Graphs
Feb 01, 2019
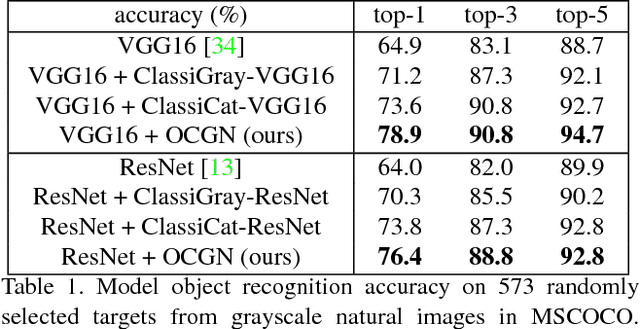
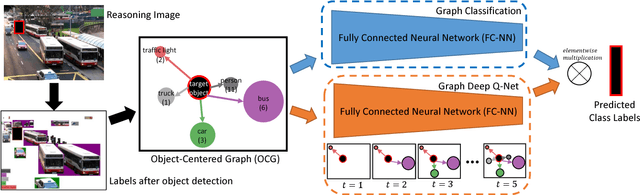
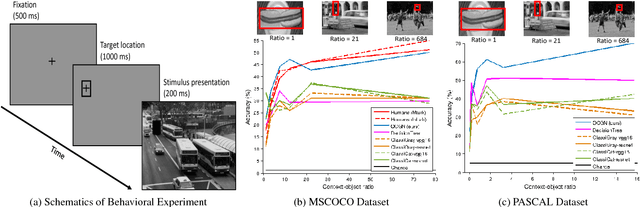
Children benefit from lift-the-flap books by taking on an active role in guessing what is behind the flap based on the context. In this paper, we introduce lift-the-flap games for computational models. The task is to reason about the scene context and infer what the target behind the flap is in a natural image. Context reasoning is critical in many computer vision applications, such as object recognition and semantic segmentation. To tackle this problem, we propose an object-centered graph representing the scene configuration of the image where each node corresponds to a group of objects belonging to the same category. To infer the target's class label, we introduce an object-centered graph network model consisting of two sub-networks. The classification sub-network takes the complete graph as input and outputs a classification vector assigning the probability for each class. The reinforcement learning sub-network exploits the class label dependencies and learns the joint probability among objects in order to generate multiple reasonable answers for the missing target. To evaluate our model's performance, we carry out human behavioral experiments for lift-the-flap games as a benchmark. Our model makes reasonable inferences compared to humans, and significantly outperforms all the null models. We also demonstrate the usefulness of our object-centered graph network model in context-aware object recognition and target priming in visual search.
Egocentric Spatial Memory
Jul 31, 2018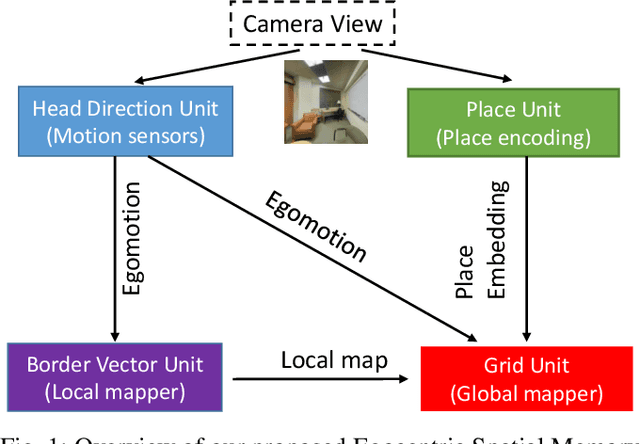
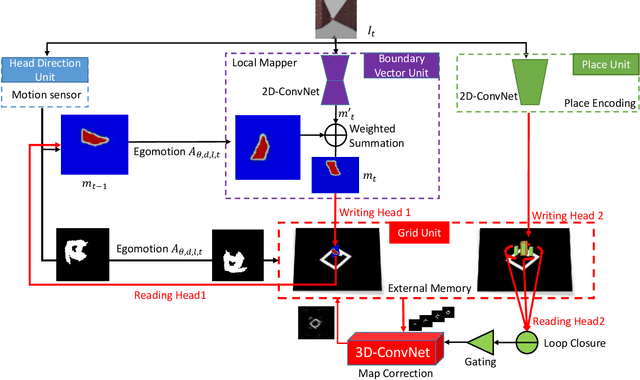

Egocentric spatial memory (ESM) defines a memory system with encoding, storing, recognizing and recalling the spatial information about the environment from an egocentric perspective. We introduce an integrated deep neural network architecture for modeling ESM. It learns to estimate the occupancy state of the world and progressively construct top-down 2D global maps from egocentric views in a spatially extended environment. During the exploration, our proposed ESM model updates belief of the global map based on local observations using a recurrent neural network. It also augments the local mapping with a novel external memory to encode and store latent representations of the visited places over long-term exploration in large environments which enables agents to perform place recognition and hence, loop closure. Our proposed ESM network contributes in the following aspects: (1) without feature engineering, our model predicts free space based on egocentric views efficiently in an end-to-end manner; (2) different from other deep learning-based mapping system, ESMN deals with continuous actions and states which is vitally important for robotic control in real applications. In the experiments, we demonstrate its accurate and robust global mapping capacities in 3D virtual mazes and realistic indoor environments by comparing with several competitive baselines.