 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Learning with Deep Generative Models
Oct 31, 2014


The ever-increasing size of modern data sets combined with the difficulty of obtaining label information has made semi-supervised learning one of the problems of significant practical importance in modern data analysis. We revisit the approach to semi-supervised learning with generative models and develop new models that allow for effective generalisation from small labelled data sets to large unlabelled ones. Generative approaches have thus far been either inflexible, inefficient or non-scalable. We show that deep generative models and approximate Bayesian inference exploiting recent advances in variational methods can be used to provide significant improvements, making generative approaches highly competitive for semi-supervised learning.
Bayesian Structure Learning for Markov Random Fields with a Spike and Slab Prior
Aug 09, 2014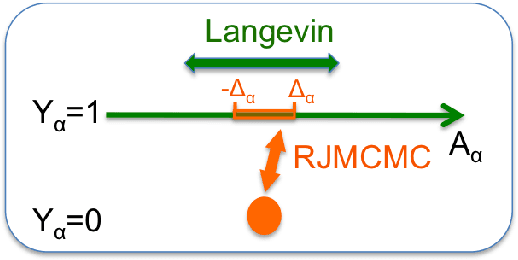
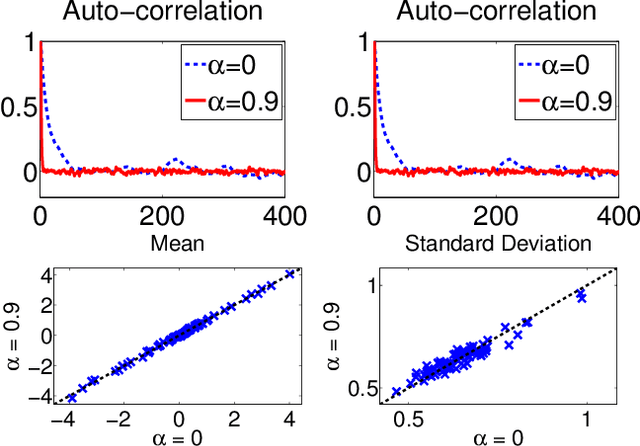
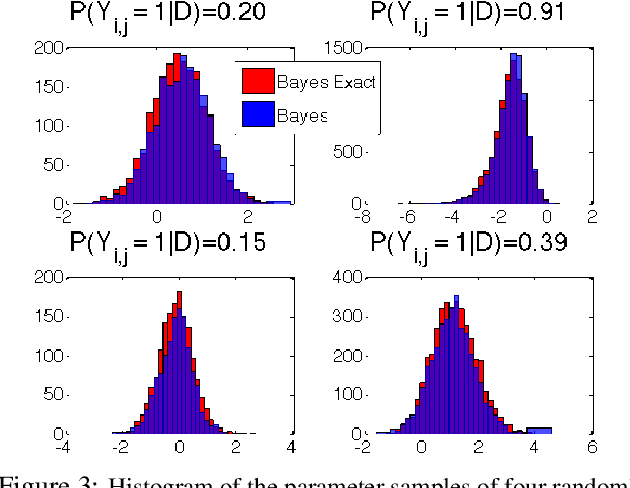
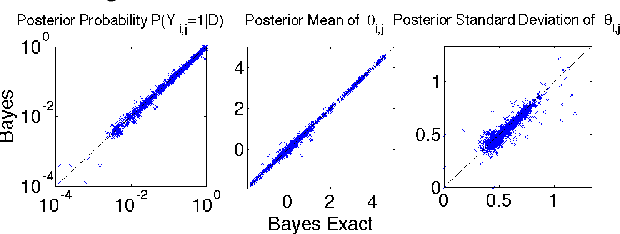
In recent years a number of methods have been developed for automatically learning the (sparse) connectivity structure of Markov Random Fields. These methods are mostly based on L1-regularized optimization which has a number of disadvantages such as the inability to assess model uncertainty and expensive crossvalidation to find the optimal regularization parameter. Moreover, the model's predictive performance may degrade dramatically with a suboptimal value of the regularization parameter (which is sometimes desirable to induce sparseness). We propose a fully Bayesian approach based on a "spike and slab" prior (similar to L0 regularization) that does not suffer from these shortcomings. We develop an approximate MCMC method combining Langevin dynamics and reversible jump MCMC to conduct inference in this model. Experiments show that the proposed model learns a good combination of the structure and parameter values without the need for separate hyper-parameter tuning. Moreover, the model's predictive performance is much more robust than L1-based methods with hyper-parameter settings that induce highly sparse model structures.
Learning the Irreducible Representations of Commutative Lie Groups
May 25, 2014
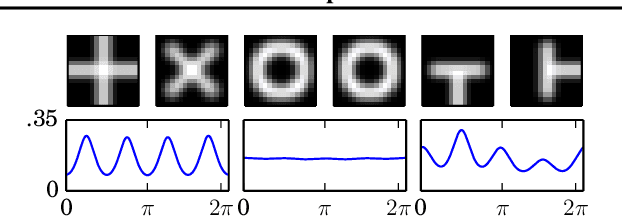

We present a new probabilistic model of compact commutative Lie groups that produces invariant-equivariant and disentangled representations of data. To define the notion of disentangling, we borrow a fundamental principle from physics that is used to derive the elementary particles of a system from its symmetries. Our model employs a newfound Bayesian conjugacy relation that enables fully tractable probabilistic inference over compact commutative Lie groups -- a class that includes the groups that describe the rotation and cyclic translation of images. We train the model on pairs of transformed image patches, and show that the learned invariant representation is highly effective for classification.
Auto-Encoding Variational Bayes
May 01, 2014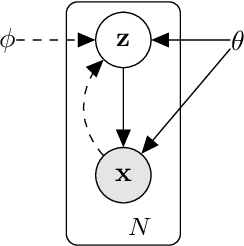
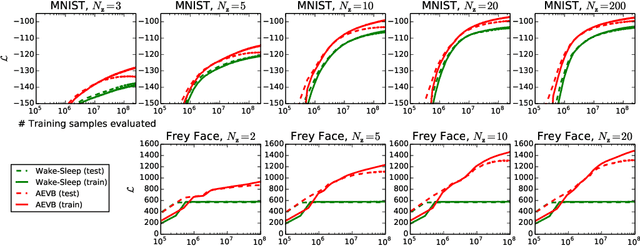
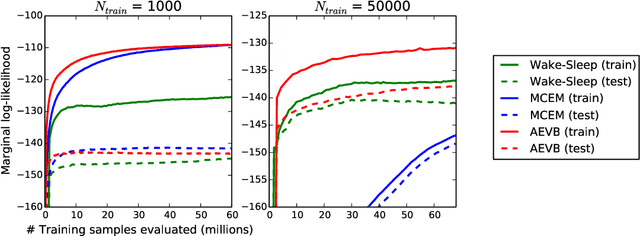

How can we perform efficient inference and learning in directed probabilistic models, in the presence of continuous latent variables with intractable posterior distributions, and large datasets? We introduce a stochastic variational inference and learning algorithm that scales to large datasets and, under some mild differentiability conditions, even works in the intractable case. Our contributions is two-fold. First, we show that a reparameterization of the variational lower bound yields a lower bound estimator that can be straightforwardly optimized using standard stochastic gradient methods. Second, we show that for i.i.d. datasets with continuous latent variables per datapoint, posterior inference can be made especially efficient by fitting an approximate inference model (also called a recognition model) to the intractable posterior using the proposed lower bound estimator. Theoretical advantages are reflected in experimental results.
Exploiting the Statistics of Learning and Inference
Mar 04, 2014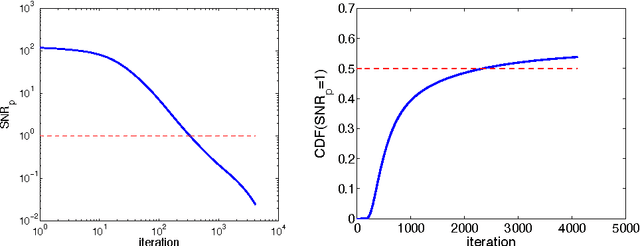
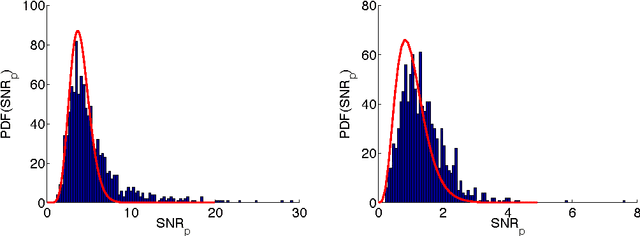
When dealing with datasets containing a billion instances or with simulations that require a supercomputer to execute, computational resources become part of the equation. We can improve the efficiency of learning and inference by exploiting their inherent statistical nature. We propose algorithms that exploit the redundancy of data relative to a model by subsampling data-cases for every update and reasoning about the uncertainty created in this process. In the context of learning we propose to test for the probability that a stochastically estimated gradient points more than 180 degrees in the wrong direction. In the context of MCMC sampling we use stochastic gradients to improve the efficiency of MCMC updates, and hypothesis tests based on adaptive mini-batches to decide whether to accept or reject a proposed parameter update. Finally, we argue that in the context of likelihood free MCMC one needs to store all the information revealed by all simulations, for instance in a Gaussian process. We conclude that Bayesian methods will remain to play a crucial role in the era of big data and big simulations, but only if we overcome a number of computational challenges.
Austerity in MCMC Land: Cutting the Metropolis-Hastings Budget
Feb 14, 2014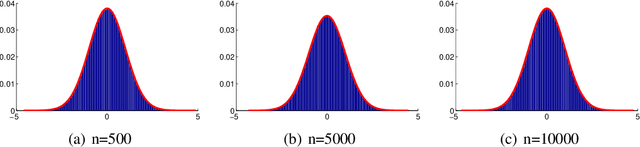
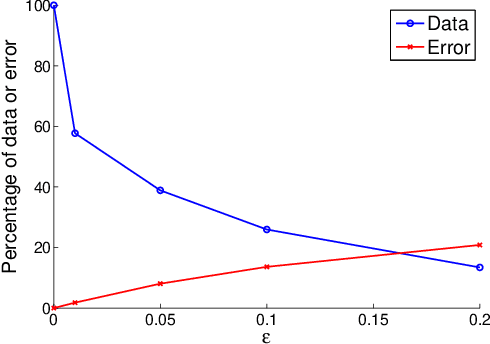
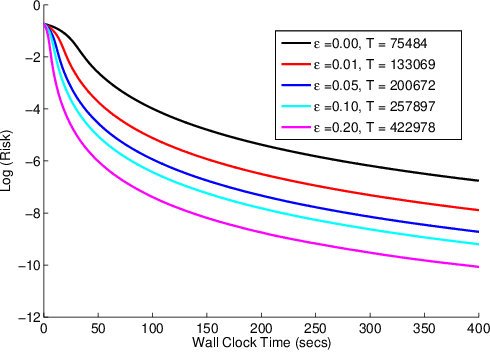
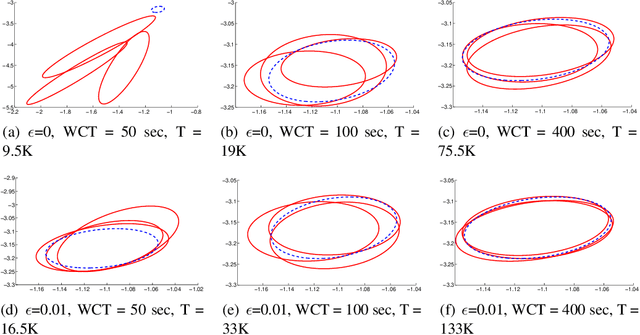
Can we make Bayesian posterior MCMC sampling more efficient when faced with very large datasets? We argue that computing the likelihood for N datapoints in the Metropolis-Hastings (MH) test to reach a single binary decision is computationally inefficient. We introduce an approximate MH rule based on a sequential hypothesis test that allows us to accept or reject samples with high confidence using only a fraction of the data required for the exact MH rule. While this method introduces an asymptotic bias, we show that this bias can be controlled and is more than offset by a decrease in variance due to our ability to draw more samples per unit of time.
GPS-ABC: Gaussian Process Surrogate Approximate Bayesian Computation
Jan 13, 2014
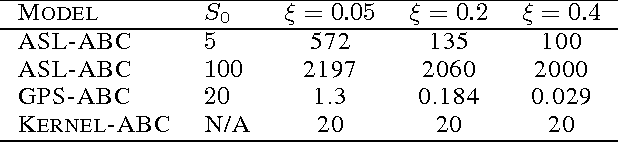
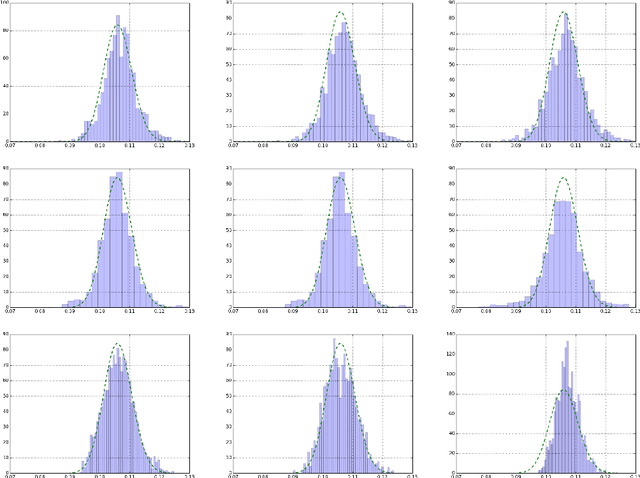
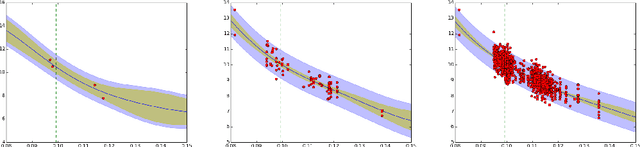
Scientists often express their understanding of the world through a computationally demanding simulation program. Analyzing the posterior distribution of the parameters given observations (the inverse problem) can be extremely challenging. The Approximate Bayesian Computation (ABC) framework is the standard statistical tool to handle these likelihood free problems, but they require a very large number of simulations. In this work we develop two new ABC sampling algorithms that significantly reduce the number of simulations necessary for posterior inference. Both algorithms use confidence estimates for the accept probability in the Metropolis Hastings step to adaptively choose the number of necessary simulations. Our GPS-ABC algorithm stores the information obtained from every simulation in a Gaussian process which acts as a surrogate function for the simulated statistics. Experiments on a challenging realistic biological problem illustrate the potential of these algorithms.
Stochastic Collapsed Variational Bayesian Inference for Latent Dirichlet Allocation
May 10, 2013
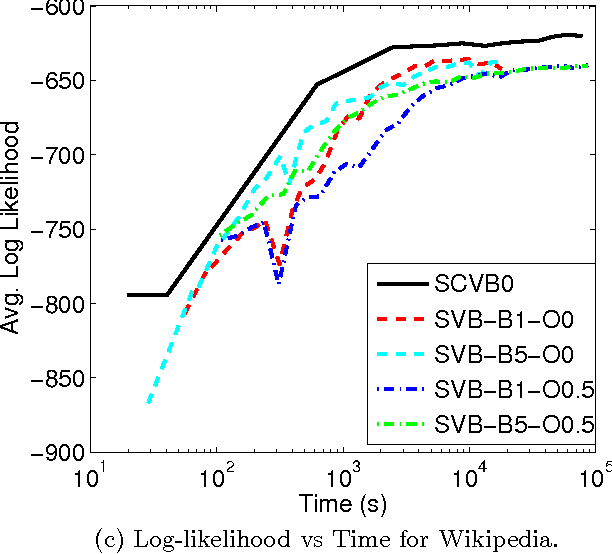
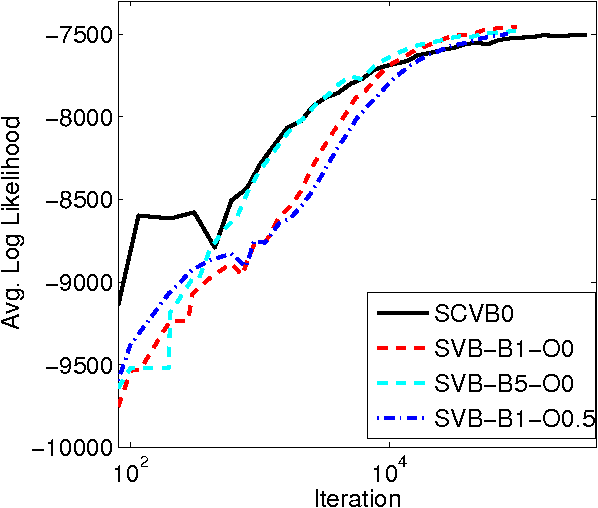
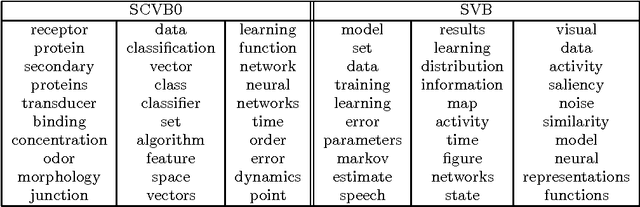
In the internet era there has been an explosion in the amount of digital text information available, leading to difficulties of scale for traditional inference algorithms for topic models. Recent advances in stochastic variational inference algorithms for latent Dirichlet allocation (LDA) have made it feasible to learn topic models on large-scale corpora, but these methods do not currently take full advantage of the collapsed representation of the model. We propose a stochastic algorithm for collapsed variational Bayesian inference for LDA, which is simpler and more efficient than the state of the art method. We show connections between collapsed variational Bayesian inference and MAP estimation for LDA, and leverage these connections to prove convergence properties of the proposed algorithm. In experiments on large-scale text corpora, the algorithm was found to converge faster and often to a better solution than the previous method. Human-subject experiments also demonstrated that the method can learn coherent topics in seconds on small corpora, facilitating the use of topic models in interactive document analysis software.
Herded Gibbs Sampling
Mar 16, 2013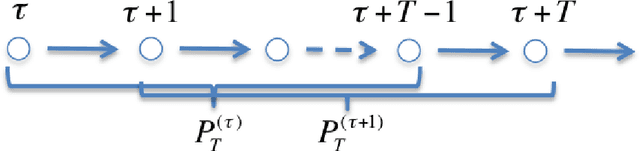
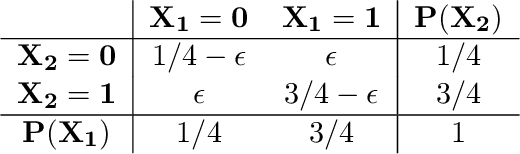
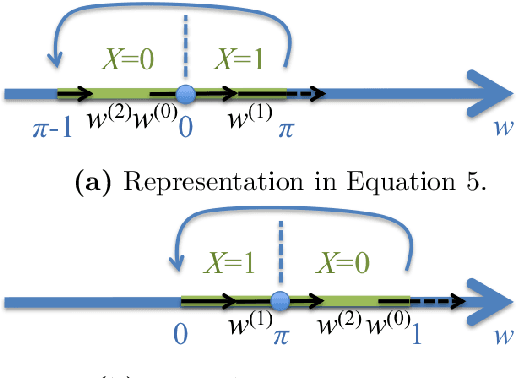
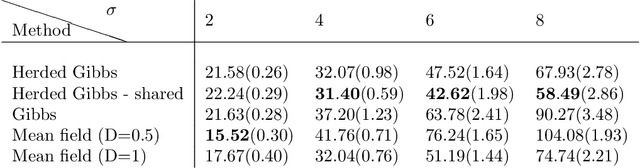
The Gibbs sampler is one of the most popular algorithms for inference in statistical models. In this paper, we introduce a herding variant of this algorithm, called herded Gibbs, that is entirely deterministic. We prove that herded Gibbs has an $O(1/T)$ convergence rate for models with independent variables and for fully connected probabilistic graphical models. Herded Gibbs is shown to outperform Gibbs in the tasks of image denoising with MRFs and named entity recognition with CRFs. However, the convergence for herded Gibbs for sparsely connected probabilistic graphical models is still an open problem.
Belief Optimization for Binary Networks: A Stable Alternative to Loopy Belief Propagation
Jan 10, 2013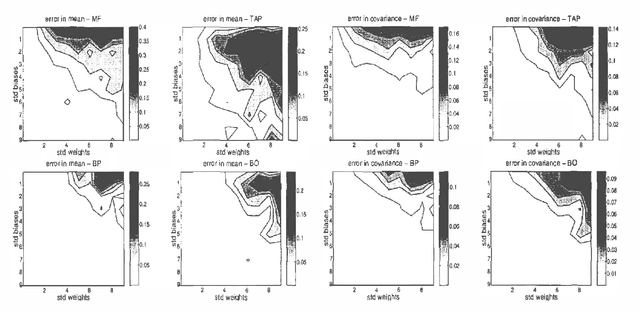
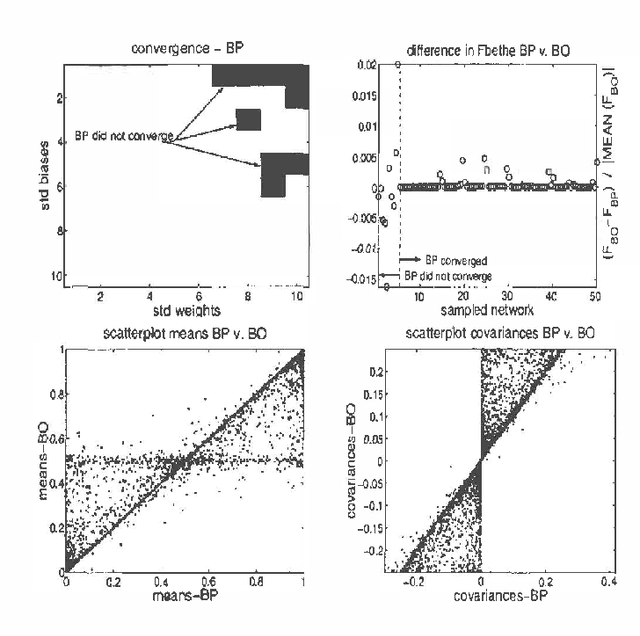
We present a novel inference algorithm for arbitrary, binary, undirected graphs. Unlike loopy belief propagation, which iterates fixed point equations, we directly descend on the Bethe free energy. The algorithm consists of two phases, first we update the pairwise probabilities, given the marginal probabilities at each unit,using an analytic expression. Next, we update the marginal probabilities, given the pairwise probabilities by following the negative gradient of the Bethe free energy. Both steps are guaranteed to decrease the Bethe free energy, and since it is lower bounded, the algorithm is guaranteed to converge to a local minimum. We also show that the Bethe free energy is equal to the TAP free energy up to second order in the weights. In experiments we confirm that when belief propagation converges it usually finds identical solutions as our belief optimization method. However, in cases where belief propagation fails to converge, belief optimization continues to converge to reasonable beliefs. The stable nature of belief optimization makes it ideally suited for learning graphical models from data.