 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEM Distillation for One-step Diffusion Models
May 27, 2024



While diffusion models can learn complex distributions, sampling requires a computationally expensive iterative process. Existing distillation methods enable efficient sampling, but have notable limitations, such as performance degradation with very few sampling steps, reliance on training data access, or mode-seeking optimization that may fail to capture the full distribution. We propose EM Distillation (EMD), a maximum likelihood-based approach that distills a diffusion model to a one-step generator model with minimal loss of perceptual quality. Our approach is derived through the lens of Expectation-Maximization (EM), where the generator parameters are updated using samples from the joint distribution of the diffusion teacher prior and inferred generator latents. We develop a reparametrized sampling scheme and a noise cancellation technique that together stabilizes the distillation process. We further reveal an interesting connection of our method with existing methods that minimize mode-seeking KL. EMD outperforms existing one-step generative methods in terms of FID scores on ImageNet-64 and ImageNet-128, and compares favorably with prior work on distilling text-to-image diffusion models.
Auto-Encoding Variational Bayes
May 01, 2014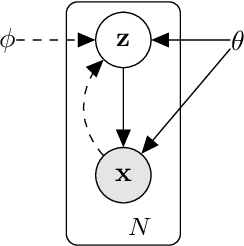
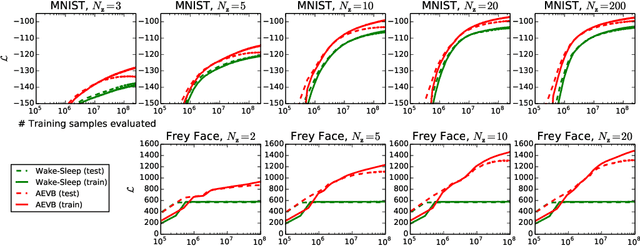
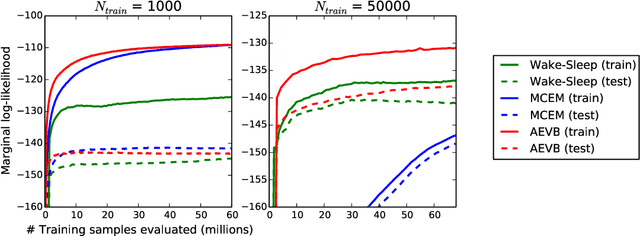

How can we perform efficient inference and learning in directed probabilistic models, in the presence of continuous latent variables with intractable posterior distributions, and large datasets? We introduce a stochastic variational inference and learning algorithm that scales to large datasets and, under some mild differentiability conditions, even works in the intractable case. Our contributions is two-fold. First, we show that a reparameterization of the variational lower bound yields a lower bound estimator that can be straightforwardly optimized using standard stochastic gradient methods. Second, we show that for i.i.d. datasets with continuous latent variables per datapoint, posterior inference can be made especially efficient by fitting an approximate inference model (also called a recognition model) to the intractable posterior using the proposed lower bound estimator. Theoretical advantages are reflected in experimental results.
Fast Gradient-Based Inference with Continuous Latent Variable Models in Auxiliary Form
Jun 04, 2013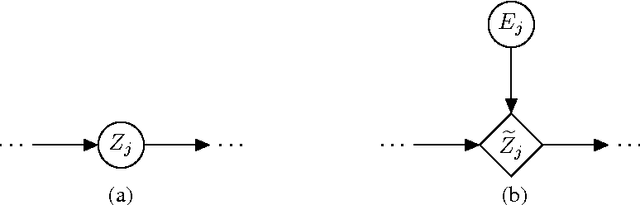
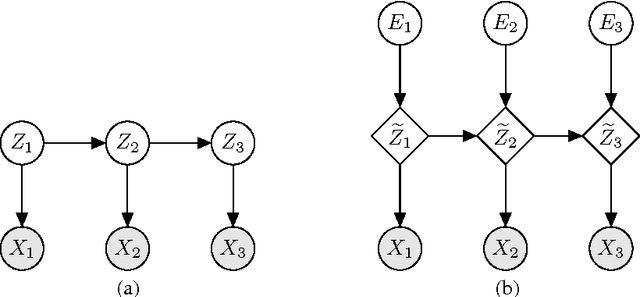
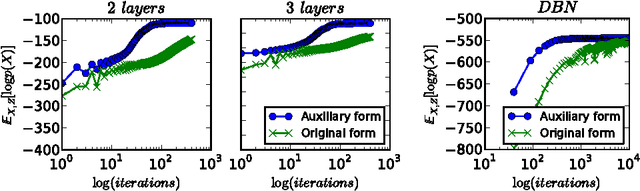
We propose a technique for increasing the efficiency of gradient-based inference and learning in Bayesian networks with multiple layers of continuous latent vari- ables. We show that, in many cases, it is possible to express such models in an auxiliary form, where continuous latent variables are conditionally deterministic given their parents and a set of independent auxiliary variables. Variables of mod- els in this auxiliary form have much larger Markov blankets, leading to significant speedups in gradient-based inference, e.g. rapid mixing Hybrid Monte Carlo and efficient gradient-based optimization. The relative efficiency is confirmed in ex- periments.