 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaScQA: A Question Answering Dataset for Investigating Materials Science Knowledge of Large Language Models
Aug 17, 2023



Information extraction and textual comprehension from materials literature are vital for developing an exhaustive knowledge base that enables accelerated materials discovery. Language models have demonstrated their capability to answer domain-specific questions and retrieve information from knowledge bases. However, there are no benchmark datasets in the materials domain that can evaluate the understanding of the key concepts by these language models. In this work, we curate a dataset of 650 challenging questions from the materials domain that require the knowledge and skills of a materials student who has cleared their undergraduate degree. We classify these questions based on their structure and the materials science domain-based subcategories. Further, we evaluate the performance of GPT-3.5 and GPT-4 models on solving these questions via zero-shot and chain of thought prompting. It is observed that GPT-4 gives the best performance (~62% accuracy) as compared to GPT-3.5. Interestingly, in contrast to the general observation, no significant improvement in accuracy is observed with the chain of thought prompting. To evaluate the limitations, we performed an error analysis, which revealed conceptual errors (~64%) as the major contributor compared to computational errors (~36%) towards the reduced performance of LLMs. We hope that the dataset and analysis performed in this work will promote further research in developing better materials science domain-specific LLMs and strategies for information extraction.
DKAF: KB Arbitration for Learning Task-Oriented Dialog Systems with Dialog-KB Inconsistencies
May 26, 2023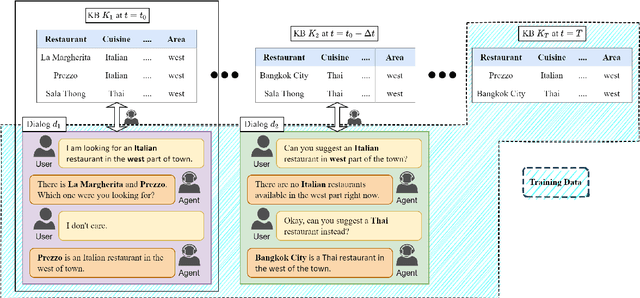

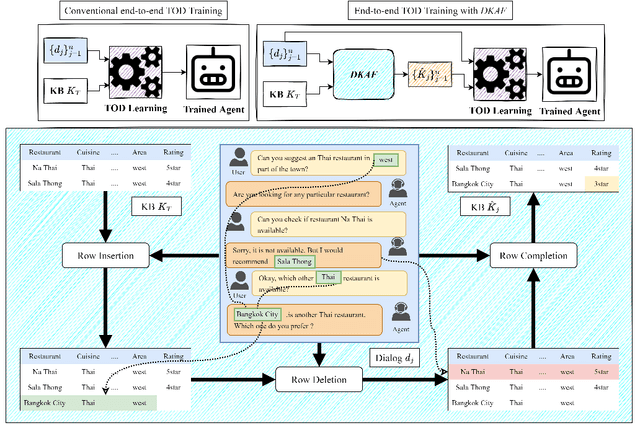
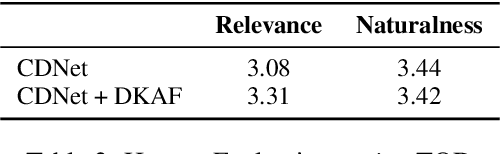
Task-oriented dialog (TOD) agents often ground their responses on external knowledge bases (KBs). These KBs can be dynamic and may be updated frequently. Existing approaches for learning TOD agents assume the KB snapshot contemporary to each individual dialog is available during training. However, in real-world scenarios, only the latest KB snapshot is available during training and as a result, the train dialogs may contain facts conflicting with the latest KB. These dialog-KB inconsistencies in the training data may potentially confuse the TOD agent learning algorithm. In this work, we define the novel problem of learning a TOD agent with dialog-KB inconsistencies in the training data. We propose a Dialog-KB Arbitration Framework (DKAF) which reduces the dialog-KB inconsistencies by predicting the contemporary KB snapshot for each train dialog. These predicted KB snapshots are then used for training downstream TOD agents. As there are no existing datasets with dialog-KB inconsistencies, we systematically introduce inconsistencies in two publicly available dialog datasets. We show that TOD agents trained with DKAF perform better than existing baselines on both these datasets
Have LLMs Advanced Enough? A Challenging Problem Solving Benchmark For Large Language Models
May 24, 2023The performance on Large Language Models (LLMs) on existing reasoning benchmarks has shot up considerably over the past years. In response, we present JEEBench, a considerably more challenging benchmark dataset for evaluating the problem solving abilities of LLMs. We curate 450 challenging pre-engineering mathematics, physics and chemistry problems from the IIT JEE-Advanced exam. Long-horizon reasoning on top of deep in-domain knowledge is essential for solving problems in this benchmark. Our evaluation on the GPT series of models reveals that although performance improves with newer models, the best being GPT-4, the highest performance, even after using techniques like Self-Consistency and Chain-of-Thought prompting is less than 40 percent. Our analysis demonstrates that errors in algebraic manipulation and failure in retrieving relevant domain specific concepts are primary contributors to GPT4's low performance. Given the challenging nature of the benchmark, we hope that it can guide future research in problem solving using LLMs. Our code and dataset is available here.
Let's Sample Step by Step: Adaptive-Consistency for Efficient Reasoning with LLMs
May 19, 2023



A popular approach for improving the correctness of output from large language models (LLMs) is Self-Consistency - poll the LLM multiple times and output the most frequent solution. Existing Self-Consistency techniques always draw a constant number of samples per question, where a better approach will be to non-uniformly distribute the available budget based on the amount of agreement in the samples drawn so far. In response, we introduce Adaptive-Consistency, a cost-efficient, model-agnostic technique that dynamically adjusts the number of samples per question using a lightweight stopping criterion. Our experiments over 13 datasets and two LLMs demonstrate that Adaptive-Consistency reduces sample budget by up to 6.0 times with an average accuracy drop of less than 0.1%.
NeuSTIP: A Novel Neuro-Symbolic Model for Link and Time Prediction in Temporal Knowledge Graphs
May 15, 2023



While Knowledge Graph Completion (KGC) on static facts is a matured field, Temporal Knowledge Graph Completion (TKGC), that incorporates validity time into static facts is still in its nascent stage. The KGC methods fall into multiple categories including embedding-based, rule-based, GNN-based, pretrained Language Model based approaches. However, such dimensions have not been explored in TKG. To that end, we propose a novel temporal neuro-symbolic model, NeuSTIP, that performs link prediction and time interval prediction in a TKG. NeuSTIP learns temporal rules in the presence of the Allen predicates that ensure the temporal consistency between neighboring predicates in a given rule. We further design a unique scoring function that evaluates the confidence of the candidate answers while performing link prediction and time interval prediction by utilizing the learned rules. Our empirical evaluation on two time interval based TKGC datasets suggests that our model outperforms state-of-the-art models for both link prediction and the time interval prediction task.
DeGPR: Deep Guided Posterior Regularization for Multi-Class Cell Detection and Counting
Apr 03, 2023Multi-class cell detection and counting is an essential task for many pathological diagnoses. Manual counting is tedious and often leads to inter-observer variations among pathologists. While there exist multiple, general-purpose, deep learning-based object detection and counting methods, they may not readily transfer to detecting and counting cells in medical images, due to the limited data, presence of tiny overlapping objects, multiple cell types, severe class-imbalance, minute differences in size/shape of cells, etc. In response, we propose guided posterior regularization (DeGPR), which assists an object detector by guiding it to exploit discriminative features among cells. The features may be pathologist-provided or inferred directly from visual data. We validate our model on two publicly available datasets (CoNSeP and MoNuSAC), and on MuCeD, a novel dataset that we contribute. MuCeD consists of 55 biopsy images of the human duodenum for predicting celiac disease. We perform extensive experimentation with three object detection baselines on three datasets to show that DeGPR is model-agnostic, and consistently improves baselines obtaining up to 9% (absolute) mAP gains.
Do I have the Knowledge to Answer? Investigating Answerability of Knowledge Base Questions
Dec 20, 2022



When answering natural language questions over knowledge bases (KBs), incompleteness in the KB can naturally lead to many questions being unanswerable. While answerability has been explored in other QA settings, it has not been studied for QA over knowledge bases (KBQA). We first identify various forms of KB incompleteness that can result in a question being unanswerable. We then propose GrailQAbility, a new benchmark dataset, which systematically modifies GrailQA (a popular KBQA dataset) to represent all these incompleteness issues. Testing two state-of-the-art KBQA models (trained on original GrailQA as well as our GrailQAbility), we find that both models struggle to detect unanswerable questions, or sometimes detect them for the wrong reasons. Consequently, both models suffer significant loss in performance, underscoring the need for further research in making KBQA systems robust to unanswerability.
mOKB6: A Multilingual Open Knowledge Base Completion Benchmark
Nov 13, 2022Automated completion of open knowledge bases (KBs), which are constructed from triples of the form (subject phrase, relation phrase, object phrase) obtained via open information extraction (IE) from text, is useful for discovering novel facts that may not directly be present in the text. However, research in open knowledge base completion (KBC) has so far been limited to resource-rich languages like English. Using the latest advances in multilingual open IE, we construct the first multilingual open KBC dataset, called mOKB6, that contains facts from Wikipedia in six languages (including English). Improving the previous open KB construction pipeline by doing multilingual coreference resolution and keeping only entity-linked triples, we create a dense open KB. We experiment with several baseline models that have been proposed for both open and closed KBs and observe a consistent benefit of using knowledge gained from other languages. The dataset and accompanying code will be made publicly available.
"Covid vaccine is against Covid but Oxford vaccine is made at Oxford!" Semantic Interpretation of Proper Noun Compounds
Oct 24, 2022Proper noun compounds, e.g., "Covid vaccine", convey information in a succinct manner (a "Covid vaccine" is a "vaccine that immunizes against the Covid disease"). These are commonly used in short-form domains, such as news headlines, but are largely ignored in information-seeking applications. To address this limitation, we release a new manually annotated dataset, ProNCI, consisting of 22.5K proper noun compounds along with their free-form semantic interpretations. ProNCI is 60 times larger than prior noun compound datasets and also includes non-compositional examples, which have not been previously explored. We experiment with various neural models for automatically generating the semantic interpretations from proper noun compounds, ranging from few-shot prompting to supervised learning, with varying degrees of knowledge about the constituent nouns. We find that adding targeted knowledge, particularly about the common noun, results in performance gains of upto 2.8%. Finally, we integrate our model generated interpretations with an existing Open IE system and observe an 7.5% increase in yield at a precision of 85%. The dataset and code are available at https://github.com/dair-iitd/pronci.
A Solver-Free Framework for Scalable Learning in Neural ILP Architectures
Oct 17, 2022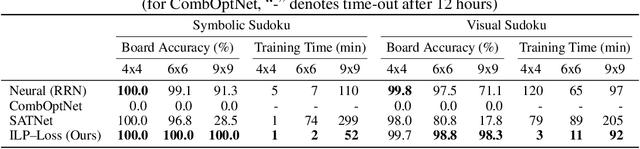
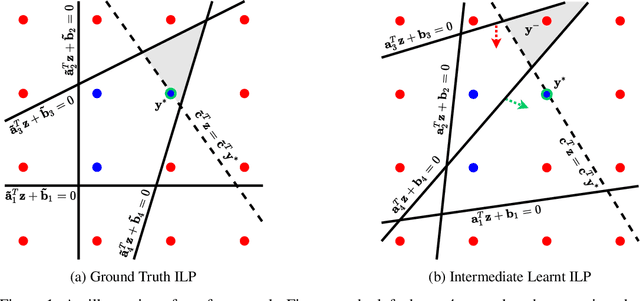
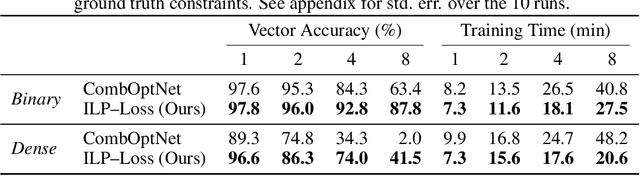

There is a recent focus on designing architectures that have an Integer Linear Programming (ILP) layer within a neural model (referred to as Neural ILP in this paper). Neural ILP architectures are suitable for pure reasoning tasks that require data-driven constraint learning or for tasks requiring both perception (neural) and reasoning (ILP). A recent SOTA approach for end-to-end training of Neural ILP explicitly defines gradients through the ILP black box (Paulus et al. 2021) - this trains extremely slowly, owing to a call to the underlying ILP solver for every training data point in a minibatch. In response, we present an alternative training strategy that is solver-free, i.e., does not call the ILP solver at all at training time. Neural ILP has a set of trainable hyperplanes (for cost and constraints in ILP), together representing a polyhedron. Our key idea is that the training loss should impose that the final polyhedron separates the positives (all constraints satisfied) from the negatives (at least one violated constraint or a suboptimal cost value), via a soft-margin formulation. While positive example(s) are provided as part of the training data, we devise novel techniques for generating negative samples. Our solution is flexible enough to handle equality as well as inequality constraints. Experiments on several problems, both perceptual as well as symbolic, which require learning the constraints of an ILP, show that our approach has superior performance and scales much better compared to purely neural baselines and other state-of-the-art models that require solver-based training. In particular, we are able to obtain excellent performance in 9 x 9 symbolic and visual sudoku, to which the other Neural ILP solver is not able to scale.