 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Image Non-uniform Blur Kernel Estimation via Adaptive Basis Decomposition
Feb 01, 2021
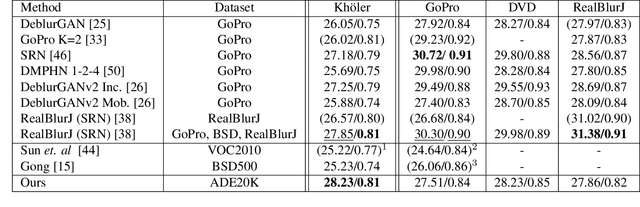

Characterizing and removing motion blur caused by camera shake or object motion remains an important task for image restoration. In recent years, removal of motion blur in photographs has seen impressive progress in the hands of deep learning-based methods, trained to map directly from blurry to sharp images. Characterization of motion blur, on the other hand, has received less attention and progress in model-based methods for restoration lags behind that of data-driven end-to-end approaches. In this paper, we propose a general, non-parametric model for dense non-uniform motion blur estimation. Given a blurry image, we estimate a set of adaptive basis kernels as well as the mixing coefficients at pixel level, producing a per-pixel map of motion blur. This rich but efficient forward model of the degradation process allows the utilization of existing tools for solving inverse problems. We show that our method overcomes the limitations of existing non-uniform motion blur estimation and that it contributes to bridging the gap between model-based and data-driven approaches for deblurring real photographs.
Polyblur: Removing mild blur by polynomial reblurring
Dec 16, 2020

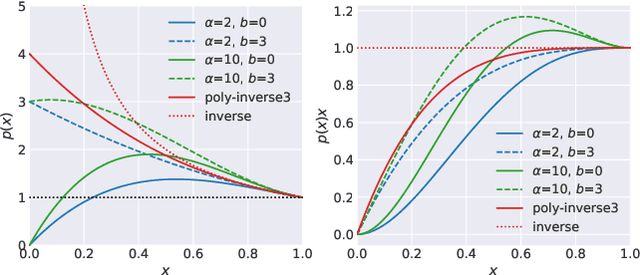
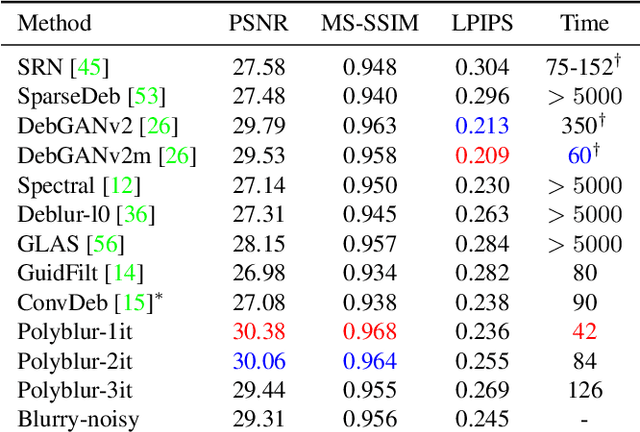
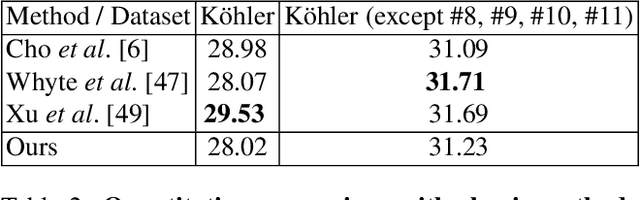
We present a highly efficient blind restoration method to remove mild blur in natural images. Contrary to the mainstream, we focus on removing slight blur that is often present, damaging image quality and commonly generated by small out-of-focus, lens blur, or slight camera motion. The proposed algorithm first estimates image blur and then compensates for it by combining multiple applications of the estimated blur in a principled way. To estimate blur we introduce a simple yet robust algorithm based on empirical observations about the distribution of the gradient in sharp natural images. Our experiments show that, in the context of mild blur, the proposed method outperforms traditional and modern blind deblurring methods and runs in a fraction of the time. Our method can be used to blindly correct blur before applying off-the-shelf deep super-resolution methods leading to superior results than other highly complex and computationally demanding techniques. The proposed method estimates and removes mild blur from a 12MP image on a modern mobile phone in a fraction of a second.
Projected Distribution Loss for Image Enhancement
Dec 16, 2020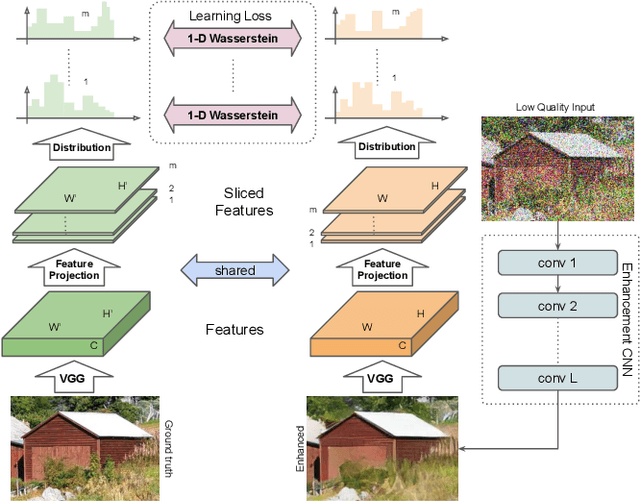
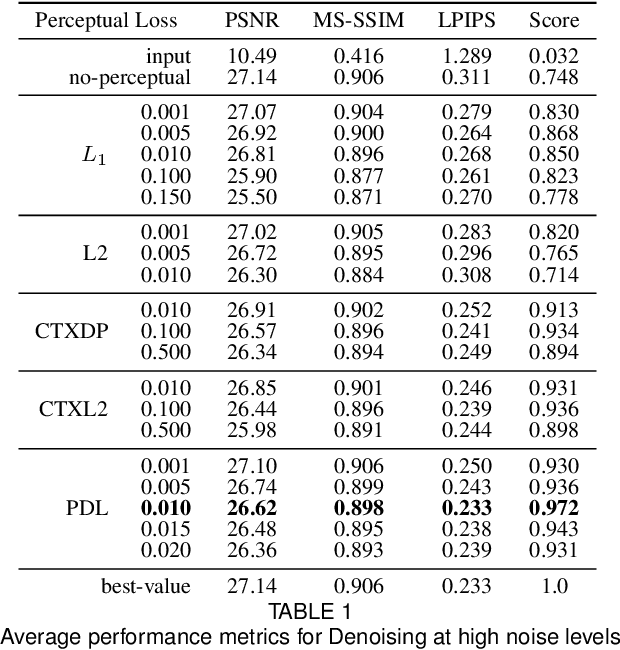
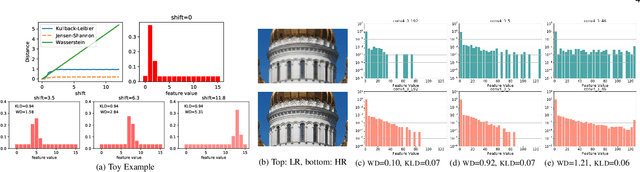
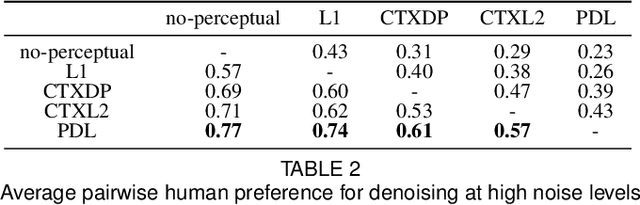
Features obtained from object recognition CNNs have been widely used for measuring perceptual similarities between images. Such differentiable metrics can be used as perceptual learning losses to train image enhancement models. However, the choice of the distance function between input and target features may have a consequential impact on the performance of the trained model. While using the norm of the difference between extracted features leads to limited hallucination of details, measuring the distance between distributions of features may generate more textures; yet also more unrealistic details and artifacts. In this paper, we demonstrate that aggregating 1D-Wasserstein distances between CNN activations is more reliable than the existing approaches, and it can significantly improve the perceptual performance of enhancement models. More explicitly, we show that in imaging applications such as denoising, super-resolution, demosaicing, deblurring and JPEG artifact removal, the proposed learning loss outperforms the current state-of-the-art on reference-based perceptual losses. This means that the proposed learning loss can be plugged into different imaging frameworks and produce perceptually realistic results.
Learning to Reduce Defocus Blur by Realistically Modeling Dual-Pixel Data
Dec 06, 2020
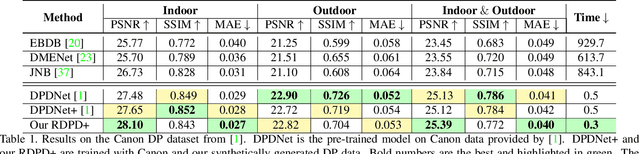
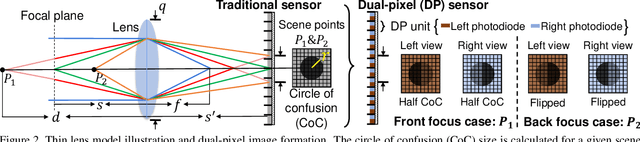
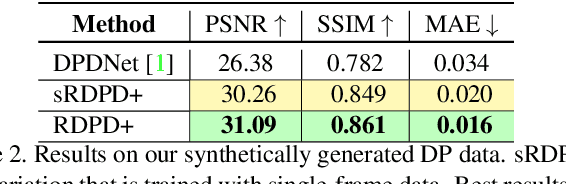
Recent work has shown impressive results on data-driven defocus deblurring using the two-image views available on modern dual-pixel (DP) sensors. One significant challenge in this line of research is access to DP data. Despite many cameras having DP sensors, only a limited number provide access to the low-level DP sensor images. In addition, capturing training data for defocus deblurring involves a time-consuming and tedious setup requiring the camera's aperture to be adjusted. Some cameras with DP sensors (e.g., smartphones) do not have adjustable apertures, further limiting the ability to produce the necessary training data. We address the data capture bottleneck by proposing a procedure to generate realistic DP data synthetically. Our synthesis approach mimics the optical image formation found on DP sensors and can be applied to virtual scenes rendered with standard computer software. Leveraging these realistic synthetic DP images, we introduce a new recurrent convolutional network (RCN) architecture that can improve deblurring results and is suitable for use with single-frame and multi-frame data captured by DP sensors. Finally, we show that our synthetic DP data is useful for training DNN models targeting video deblurring applications where access to DP data remains challenging.
Differential 3D Facial Recognition: Adding 3D to Your State-of-the-Art 2D Method
Apr 03, 2020
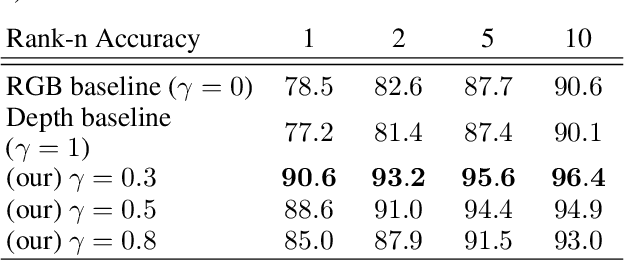
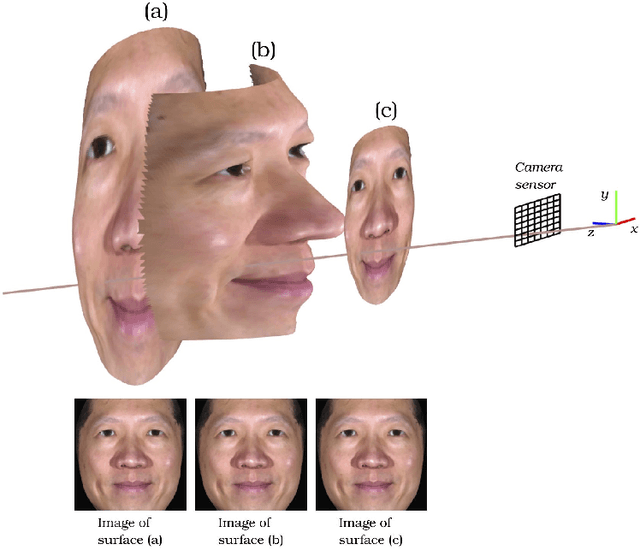
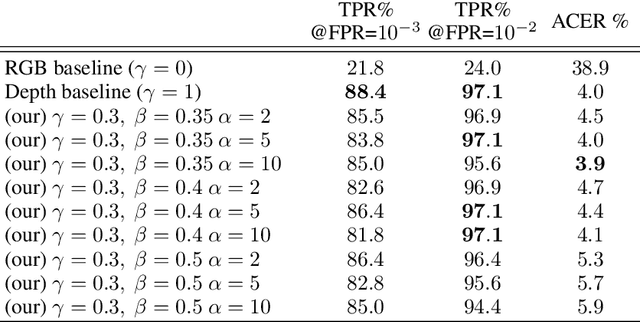
Active illumination is a prominent complement to enhance 2D face recognition and make it more robust, e.g., to spoofing attacks and low-light conditions. In the present work we show that it is possible to adopt active illumination to enhance state-of-the-art 2D face recognition approaches with 3D features, while bypassing the complicated task of 3D reconstruction. The key idea is to project over the test face a high spatial frequency pattern, which allows us to simultaneously recover real 3D information plus a standard 2D facial image. Therefore, state-of-the-art 2D face recognition solution can be transparently applied, while from the high frequency component of the input image, complementary 3D facial features are extracted. Experimental results on ND-2006 dataset show that the proposed ideas can significantly boost face recognition performance and dramatically improve the robustness to spoofing attacks.
Solving Inverse Problems by Joint Posterior Maximization with a VAE Prior
Nov 14, 2019
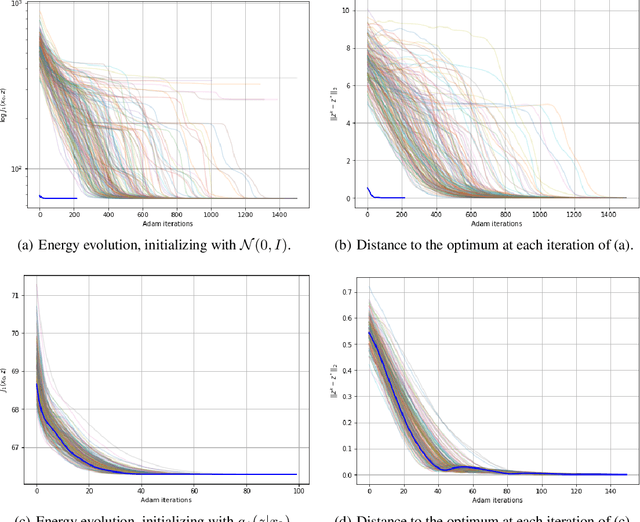

In this paper we address the problem of solving ill-posed inverse problems in imaging where the prior is a neural generative model. Specifically we consider the decoupled case where the prior is trained once and can be reused for many different log-concave degradation models without retraining. Whereas previous MAP-based approaches to this problem lead to highly non-convex optimization algorithms, our approach computes the joint (space-latent) MAP that naturally leads to alternate optimization algorithms and to the use of a stochastic encoder to accelerate computations. The resulting technique is called JPMAP because it performs Joint Posterior Maximization using an Autoencoding Prior. We show theoretical and experimental evidence that the proposed objective function is quite close to bi-convex. Indeed it satisfies a weak bi-convexity property which is sufficient to guarantee that our optimization scheme converges to a stationary point. Experimental results also show the higher quality of the solutions obtained by our JPMAP approach with respect to other non-convex MAP approaches which more often get stuck in spurious local optima.
Efficient Blind Deblurring under High Noise Levels
May 16, 2019


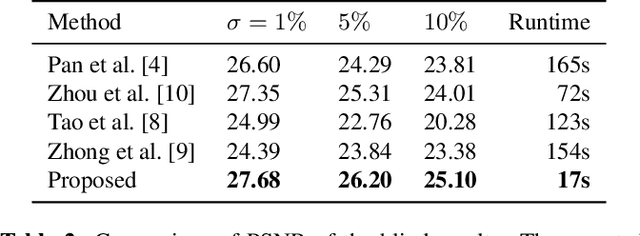
The goal of blind image deblurring is to recover a sharp image from a motion blurred one without knowing the camera motion. Current state-of-the-art methods have a remarkably good performance on images with no noise or very low noise levels. However, the noiseless assumption is not realistic considering that low light conditions are the main reason for the presence of motion blur due to requiring longer exposure times. In fact, motion blur and high to moderate noise often appear together. Most works approach this problem by first estimating the blur kernel $k$ and then deconvolving the noisy blurred image. In this work, we first show that current state-of-the-art kernel estimation methods based on the $\ell_0$ gradient prior can be adapted to handle high noise levels while keeping their efficiency. Then, we show that a fast non-blind deconvolution method can be significantly improved by first denoising the blurry image. The proposed approach yields results that are equivalent to those obtained with much more computationally demanding methods.
Reducing Anomaly Detection in Images to Detection in Noise
Apr 25, 2019

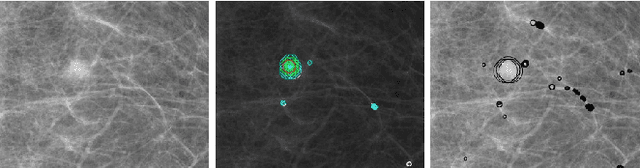
Anomaly detectors address the difficult problem of detecting automatically exceptions in an arbitrary background image. Detection methods have been proposed by the thousands because each problem requires a different background model. By analyzing the existing approaches, we show that the problem can be reduced to detecting anomalies in residual images (extracted from the target image) in which noise and anomalies prevail. Hence, the general and impossible background modeling problem is replaced by simpler noise modeling, and allows the calculation of rigorous thresholds based on the a contrario detection theory. Our approach is therefore unsupervised and works on arbitrary images.
* ICIP 2018
Image Anomalies: a Review and Synthesis of Detection Methods
Aug 07, 2018
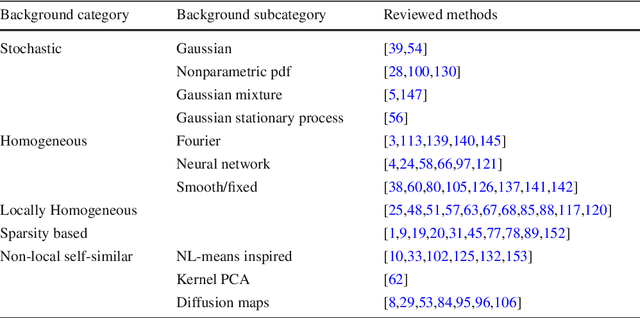

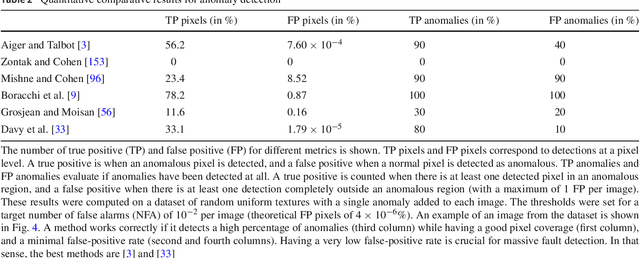
We review the broad variety of methods that have been proposed for anomaly detection in images. Most methods found in the literature have in mind a particular application. Yet we show that the methods can be classified mainly by the structural assumption they make on the "normal" image. Five different structural assumptions emerge. Our analysis leads us to reformulate the best representative algorithms by attaching to them an a contrario detection that controls the number of false positives and thus derive universal detection thresholds. By combining the most general structural assumptions expressing the background's normality with the best proposed statistical detection tools, we end up proposing generic algorithms that seem to generalize or reconcile most methods. We compare the six best representatives of our proposed classes of algorithms on anomalous images taken from classic papers on the subject, and on a synthetic database. Our conclusion is that it is possible to perform automatic anomaly detection on a single image.
Modeling Realistic Degradations in Non-blind Deconvolution
Jun 04, 2018

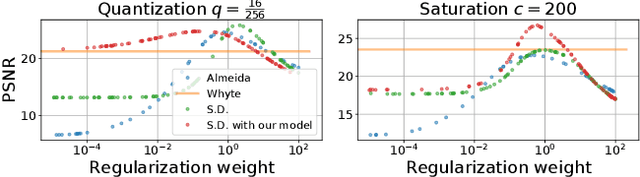

Most image deblurring methods assume an over-simplistic image formation model and as a result are sensitive to more realistic image degradations. We propose a novel variational framework, that explicitly handles pixel saturation, noise, quantization, as well as non-linear camera response function due to e.g., gamma correction. We show that accurately modeling a more realistic image acquisition pipeline leads to significant improvements, both in terms of image quality and PSNR. Furthermore, we show that incorporating the non-linear response in both the data and the regularization terms of the proposed energy leads to a more detailed restoration than a naive inversion of the non-linear curve. The minimization of the proposed energy is performed using stochastic optimization. A dataset consisting of realistically degraded images is created in order to evaluate the method.