 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the surprising similarities between supervised and self-supervised models
Oct 16, 2020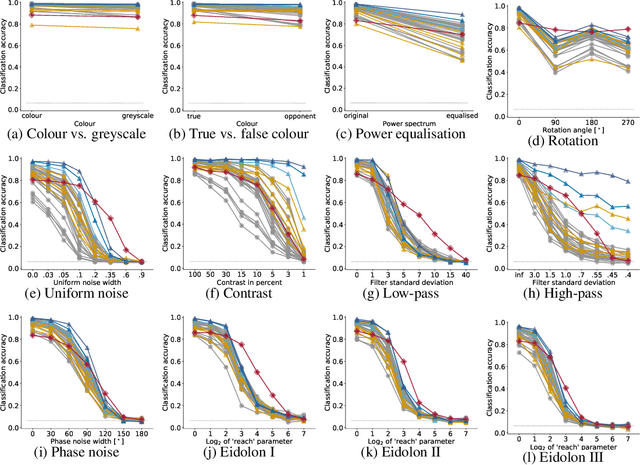
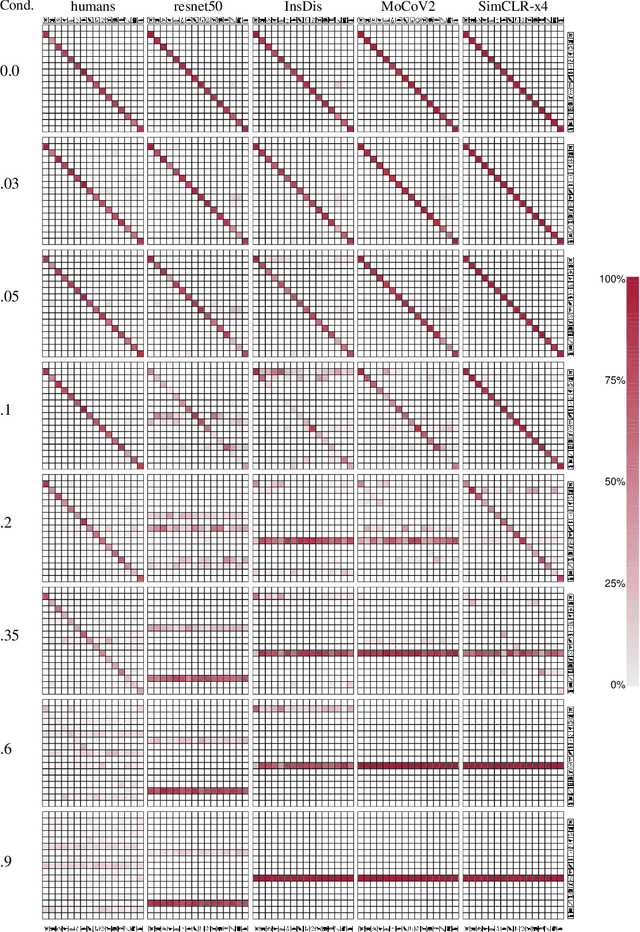
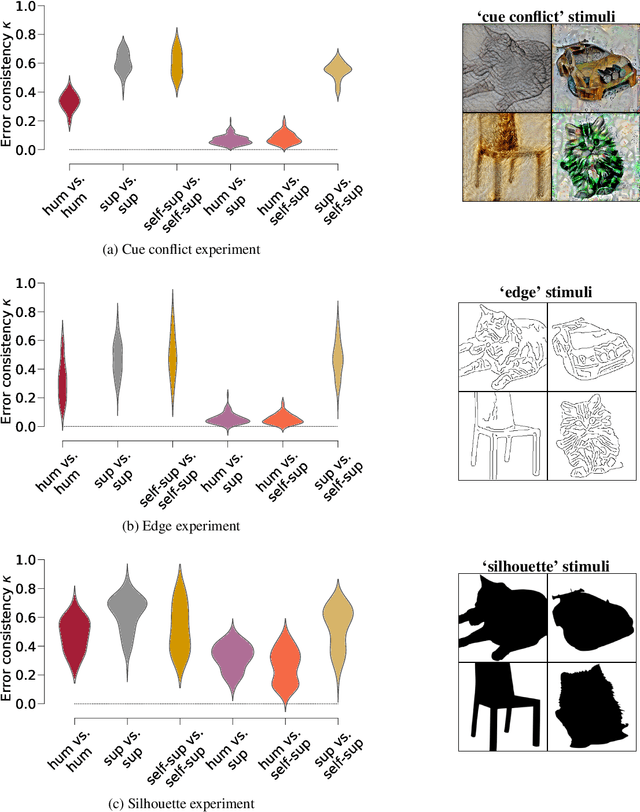
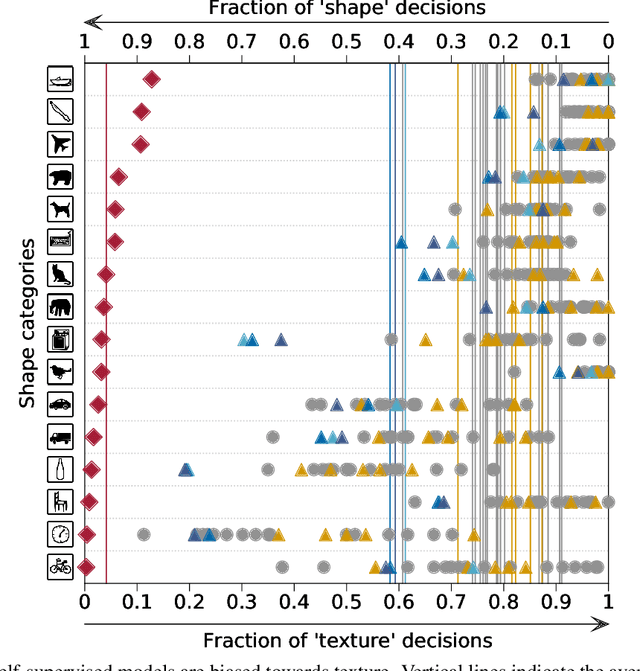
How do humans learn to acquire a powerful, flexible and robust representation of objects? While much of this process remains unknown, it is clear that humans do not require millions of object labels. Excitingly, recent algorithmic advancements in self-supervised learning now enable convolutional neural networks (CNNs) to learn useful visual object representations without supervised labels, too. In the light of this recent breakthrough, we here compare self-supervised networks to supervised models and human behaviour. We tested models on 15 generalisation datasets for which large-scale human behavioural data is available (130K highly controlled psychophysical trials). Surprisingly, current self-supervised CNNs share four key characteristics of their supervised counterparts: (1.) relatively poor noise robustness (with the notable exception of SimCLR), (2.) non-human category-level error patterns, (3.) non-human image-level error patterns (yet high similarity to supervised model errors) and (4.) a bias towards texture. Taken together, these results suggest that the strategies learned through today's supervised and self-supervised training objectives end up being surprisingly similar, but distant from human-like behaviour. That being said, we are clearly just at the beginning of what could be called a self-supervised revolution of machine vision, and we are hopeful that future self-supervised models behave differently from supervised ones, and---perhaps---more similar to robust human object recognition.
EagerPy: Writing Code That Works Natively with PyTorch, TensorFlow, JAX, and NumPy
Aug 10, 2020EagerPy is a Python framework that lets you write code that automatically works natively with PyTorch, TensorFlow, JAX, and NumPy. Library developers no longer need to choose between supporting just one of these frameworks or reimplementing the library for each framework and dealing with code duplication. Users of such libraries can more easily switch frameworks without being locked in by a specific 3rd party library. Beyond multi-framework support, EagerPy also brings comprehensive type annotations and consistent support for method chaining to any framework. The latest documentation is available online at https://eagerpy.jonasrauber.de and the code can be found on GitHub at https://github.com/jonasrauber/eagerpy.
Towards Nonlinear Disentanglement in Natural Data with Temporal Sparse Coding
Jul 21, 2020
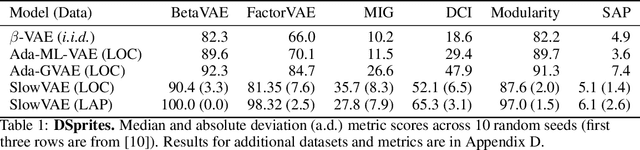
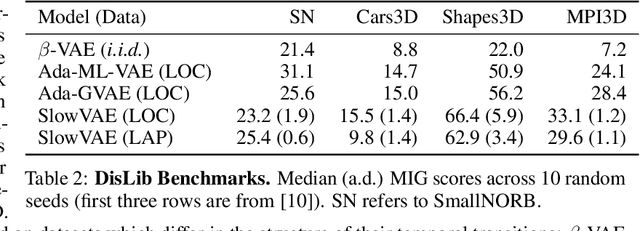
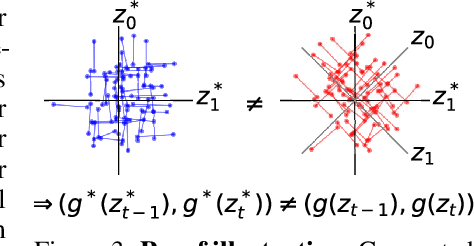
We construct an unsupervised learning model that achieves nonlinear disentanglement of underlying factors of variation in naturalistic videos. Previous work suggests that representations can be disentangled if all but a few factors in the environment stay constant at any point in time. As a result, algorithms proposed for this problem have only been tested on carefully constructed datasets with this exact property, leaving it unclear whether they will transfer to natural scenes. Here we provide evidence that objects in segmented natural movies undergo transitions that are typically small in magnitude with occasional large jumps, which is characteristic of a temporally sparse distribution. We leverage this finding and present SlowVAE, a model for unsupervised representation learning that uses a sparse prior on temporally adjacent observations to disentangle generative factors without any assumptions on the number of changing factors. We provide a proof of identifiability and show that the model reliably learns disentangled representations on several established benchmark datasets, often surpassing the current state-of-the-art. We additionally demonstrate transferability towards video datasets with natural dynamics, Natural Sprites and KITTI Masks, which we contribute as benchmarks for guiding disentanglement research towards more natural data domains.
Fast Differentiable Clipping-Aware Normalization and Rescaling
Jul 15, 2020Rescaling a vector $\vec{\delta} \in \mathbb{R}^n$ to a desired length is a common operation in many areas such as data science and machine learning. When the rescaled perturbation $\eta \vec{\delta}$ is added to a starting point $\vec{x} \in D$ (where $D$ is the data domain, e.g. $D = [0, 1]^n$), the resulting vector $\vec{v} = \vec{x} + \eta \vec{\delta}$ will in general not be in $D$. To enforce that the perturbed vector $v$ is in $D$, the values of $\vec{v}$ can be clipped to $D$. This subsequent element-wise clipping to the data domain does however reduce the effective perturbation size and thus interferes with the rescaling of $\vec{\delta}$. The optimal rescaling $\eta$ to obtain a perturbation with the desired norm after the clipping can be iteratively approximated using a binary search. However, such an iterative approach is slow and non-differentiable. Here we show that the optimal rescaling can be found analytically using a fast and differentiable algorithm. Our algorithm works for any p-norm and can be used to train neural networks on inputs with normalized perturbations. We provide native implementations for PyTorch, TensorFlow, JAX, and NumPy based on EagerPy.
Improving robustness against common corruptions by covariate shift adaptation
Jun 30, 2020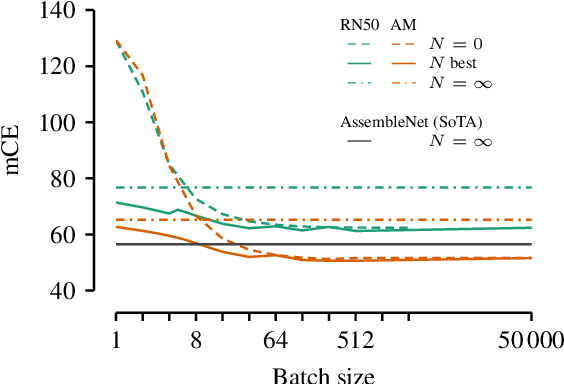
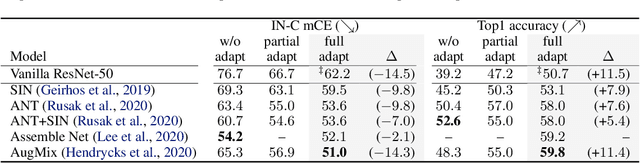
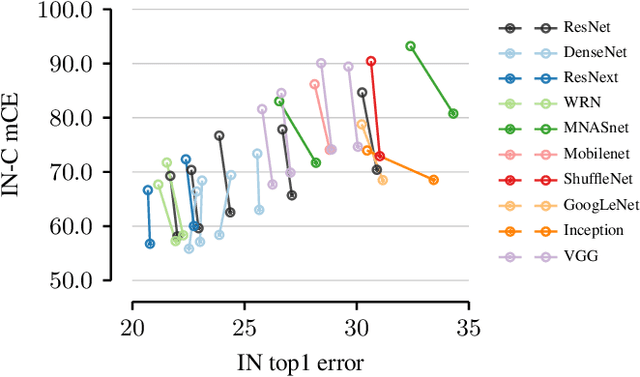
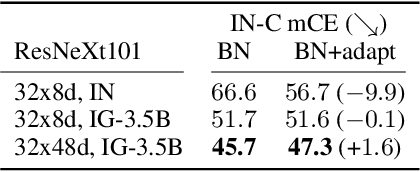
Today's state-of-the-art machine vision models are vulnerable to image corruptions like blurring or compression artefacts, limiting their performance in many real-world applications. We here argue that popular benchmarks to measure model robustness against common corruptions (like ImageNet-C) underestimate model robustness in many (but not all) application scenarios. The key insight is that in many scenarios, multiple unlabeled examples of the corruptions are available and can be used for unsupervised online adaptation. Replacing the activation statistics estimated by batch normalization on the training set with the statistics of the corrupted images consistently improves the robustness across 25 different popular computer vision models. Using the corrected statistics, ResNet-50 reaches 62.2% mCE on ImageNet-C compared to 76.7% without adaptation. With the more robust AugMix model, we improve the state of the art from 56.5% mCE to 51.0% mCE. Even adapting to a single sample improves robustness for the ResNet-50 and AugMix models, and 32 samples are sufficient to improve the current state of the art for a ResNet-50 architecture. We argue that results with adapted statistics should be included whenever reporting scores in corruption benchmarks and other out-of-distribution generalization settings.
Unmasking the Inductive Biases of Unsupervised Object Representations for Video Sequences
Jun 12, 2020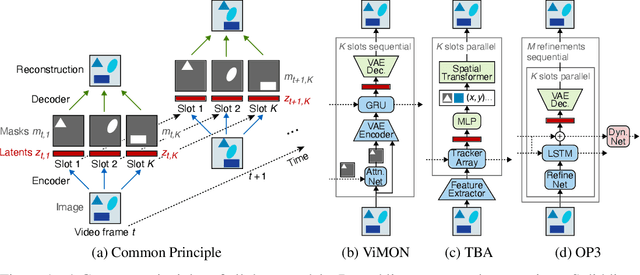
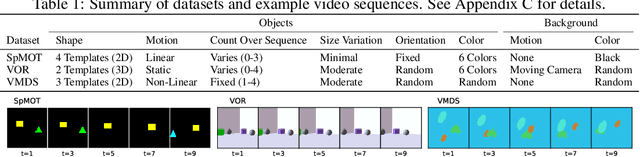
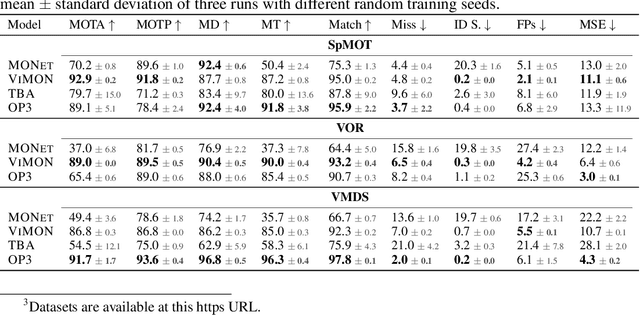
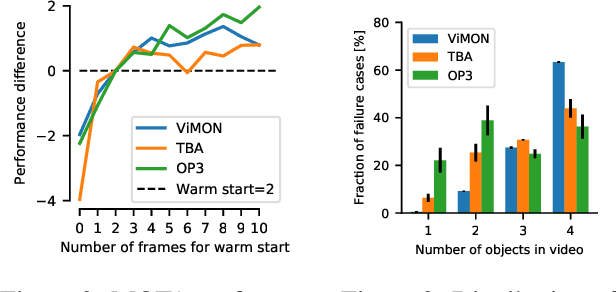
Perceiving the world in terms of objects is a crucial prerequisite for reasoning and scene understanding. Recently, several methods have been proposed for unsupervised learning of object-centric representations. However, since these models have been evaluated with respect to different downstream tasks, it remains unclear how they compare in terms of basic perceptual abilities such as detection, figure-ground segmentation and tracking of individual objects. In this paper, we argue that the established evaluation protocol of multi-object tracking tests precisely these perceptual qualities and we propose a new benchmark dataset based on procedurally generated video sequences. Using this benchmark, we compare the perceptual abilities of three state-of-the-art unsupervised object-centric learning approaches. Towards this goal, we propose a video-extension of MONet, a seminal object-centric model for static scenes, and compare it to two recent video models: OP3, which exploits clustering via spatial mixture models, and TBA, which uses an explicit factorization via spatial transformers. Our results indicate that architectures which employ unconstrained latent representations based on per-object variational autoencoders and full-image object masks are able to learn more powerful representations in terms of object detection, segmentation and tracking than the explicitly parameterized spatial transformer based architecture. We also observe that none of the methods are able to gracefully handle the most challenging tracking scenarios, suggesting that our synthetic video benchmark may provide fruitful guidance towards learning more robust object-centric video representations.
Shortcut Learning in Deep Neural Networks
May 20, 2020
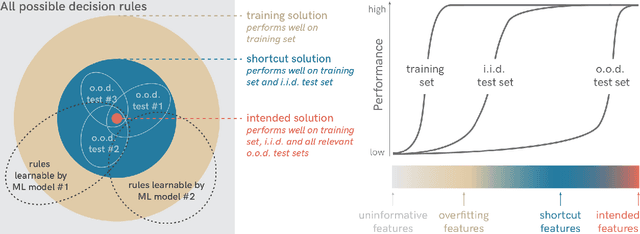

Deep learning has triggered the current rise of artificial intelligence and is the workhorse of today's machine intelligence. Numerous success stories have rapidly spread all over science, industry and society, but its limitations have only recently come into focus. In this perspective we seek to distil how many of deep learning's problem can be seen as different symptoms of the same underlying problem: shortcut learning. Shortcuts are decision rules that perform well on standard benchmarks but fail to transfer to more challenging testing conditions, such as real-world scenarios. Related issues are known in Comparative Psychology, Education and Linguistics, suggesting that shortcut learning may be a common characteristic of learning systems, biological and artificial alike. Based on these observations, we develop a set of recommendations for model interpretation and benchmarking, highlighting recent advances in machine learning to improve robustness and transferability from the lab to real-world applications.
Towards causal generative scene models via competition of experts
Apr 27, 2020

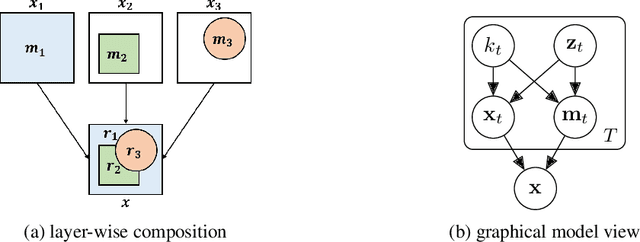
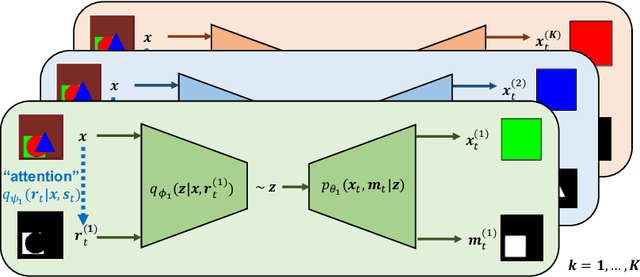
Learning how to model complex scenes in a modular way with recombinable components is a pre-requisite for higher-order reasoning and acting in the physical world. However, current generative models lack the ability to capture the inherently compositional and layered nature of visual scenes. While recent work has made progress towards unsupervised learning of object-based scene representations, most models still maintain a global representation space (i.e., objects are not explicitly separated), and cannot generate scenes with novel object arrangement and depth ordering. Here, we present an alternative approach which uses an inductive bias encouraging modularity by training an ensemble of generative models (experts). During training, experts compete for explaining parts of a scene, and thus specialise on different object classes, with objects being identified as parts that re-occur across multiple scenes. Our model allows for controllable sampling of individual objects and recombination of experts in physically plausible ways. In contrast to other methods, depth layering and occlusion are handled correctly, moving this approach closer to a causal generative scene model. Experiments on simple toy data qualitatively demonstrate the conceptual advantages of the proposed approach.
The Notorious Difficulty of Comparing Human and Machine Perception
Apr 20, 2020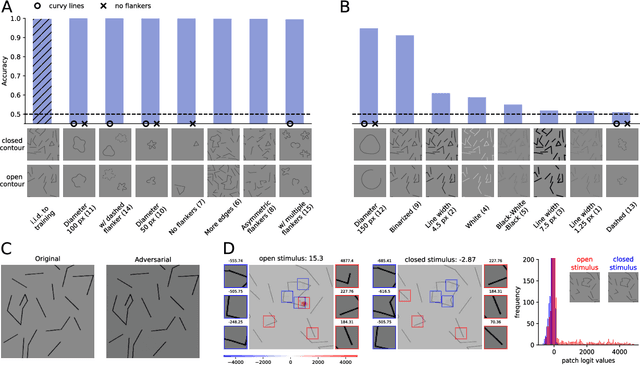
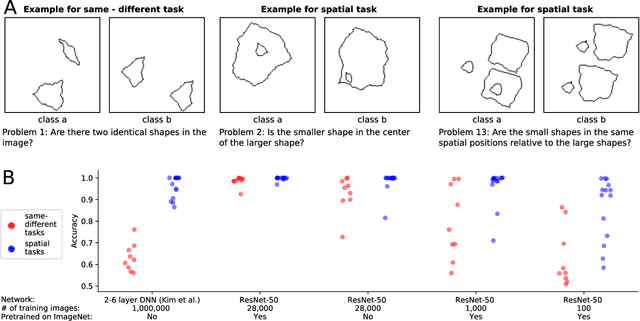
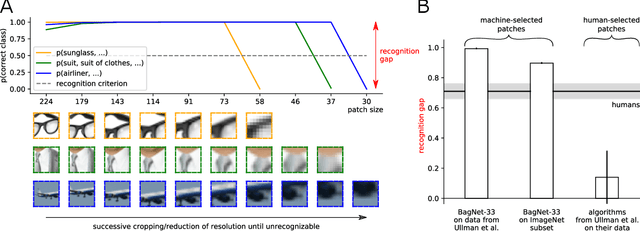
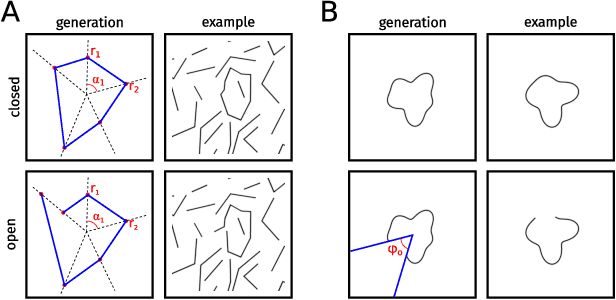
With the rise of machines to human-level performance in complex recognition tasks, a growing amount of work is directed towards comparing information processing in humans and machines. These works have the potential to deepen our understanding of the inner mechanisms of human perception and to improve machine learning. Drawing robust conclusions from comparison studies, however, turns out to be difficult. Here, we highlight common shortcomings that can easily lead to fragile conclusions. First, if a model does achieve high performance on a task similar to humans, its decision-making process is not necessarily human-like. Moreover, further analyses can reveal differences. Second, the performance of neural networks is sensitive to training procedures and architectural details. Thus, generalizing conclusions from specific architectures is difficult. Finally, when comparing humans and machines, equivalent experimental settings are crucial in order to identify innate differences. Addressing these shortcomings alters or refines the conclusions of studies. We show that, despite their ability to solve closed-contour tasks, our neural networks use different decision-making strategies than humans. We further show that there is no fundamental difference between same-different and spatial tasks for common feed-forward neural networks and finally, that neural networks do experience a "recognition gap" on minimal recognizable images. All in all, care has to be taken to not impose our human systematic bias when comparing human and machine perception.
Increasing the robustness of DNNs against image corruptions by playing the Game of Noise
Feb 26, 2020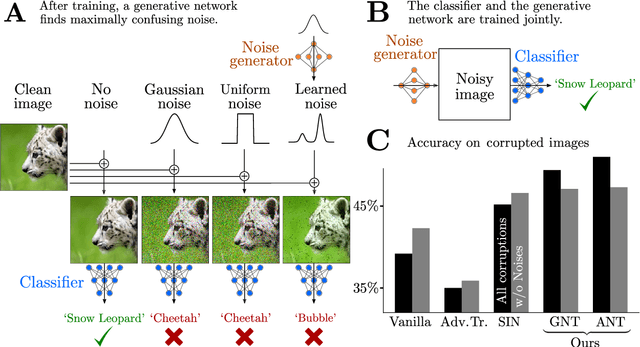
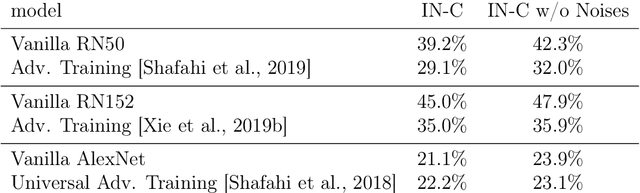
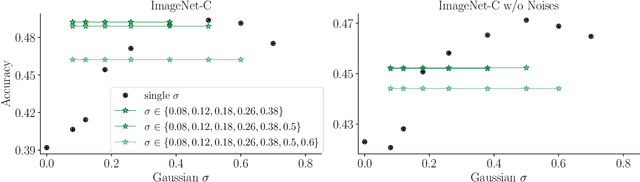
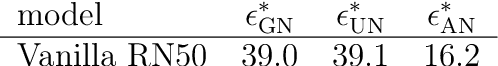
The human visual system is remarkably robust against a wide range of naturally occurring variations and corruptions like rain or snow. In contrast, the performance of modern image recognition models strongly degrades when evaluated on previously unseen corruptions. Here, we demonstrate that a simple but properly tuned training with additive Gaussian and Speckle noise generalizes surprisingly well to unseen corruptions, easily reaching the previous state of the art on the corruption benchmark ImageNet-C (with ResNet50) and on MNIST-C. We build on top of these strong baseline results and show that an adversarial training of the recognition model against uncorrelated worst-case noise distributions leads to an additional increase in performance. This regularization can be combined with previously proposed defense methods for further improvement.