 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe carbon cost of materials discovery: Can machine learning really accelerate the discovery of new photovoltaics?
Jul 17, 2025



Computational screening has become a powerful complement to experimental efforts in the discovery of high-performance photovoltaic (PV) materials. Most workflows rely on density functional theory (DFT) to estimate electronic and optical properties relevant to solar energy conversion. Although more efficient than laboratory-based methods, DFT calculations still entail substantial computational and environmental costs. Machine learning (ML) models have recently gained attention as surrogates for DFT, offering drastic reductions in resource use with competitive predictive performance. In this study, we reproduce a canonical DFT-based workflow to estimate the maximum efficiency limit and progressively replace its components with ML surrogates. By quantifying the CO$_2$ emissions associated with each computational strategy, we evaluate the trade-offs between predictive efficacy and environmental cost. Our results reveal multiple hybrid ML/DFT strategies that optimize different points along the accuracy--emissions front. We find that direct prediction of scalar quantities, such as maximum efficiency, is significantly more tractable than using predicted absorption spectra as an intermediate step. Interestingly, ML models trained on DFT data can outperform DFT workflows using alternative exchange--correlation functionals in screening applications, highlighting the consistency and utility of data-driven approaches. We also assess strategies to improve ML-driven screening through expanded datasets and improved model architectures tailored to PV-relevant features. This work provides a quantitative framework for building low-emission, high-throughput discovery pipelines.
Practical Marketplace Optimization at Uber Using Causally-Informed Machine Learning
Jul 26, 2024



Budget allocation of marketplace levers, such as incentives for drivers and promotions for riders, has long been a technical and business challenge at Uber; understanding lever budget changes' impact and estimating cost efficiency to achieve predefined budgets is crucial, with the goal of optimal allocations that maximize business value; we introduce an end-to-end machine learning and optimization procedure to automate budget decision-making for cities, relying on feature store, model training and serving, optimizers, and backtesting; proposing state-of-the-art deep learning (DL) estimator based on S-Learner and a novel tensor B-Spline regression model, we solve high-dimensional optimization with ADMM and primal-dual interior point convex optimization, substantially improving Uber's resource allocation efficiency.
Isometric Graph Neural Networks
Jun 16, 2020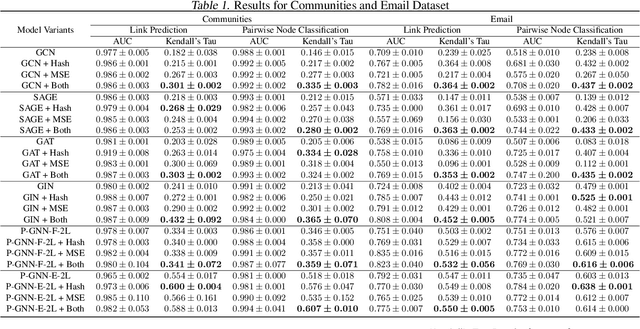
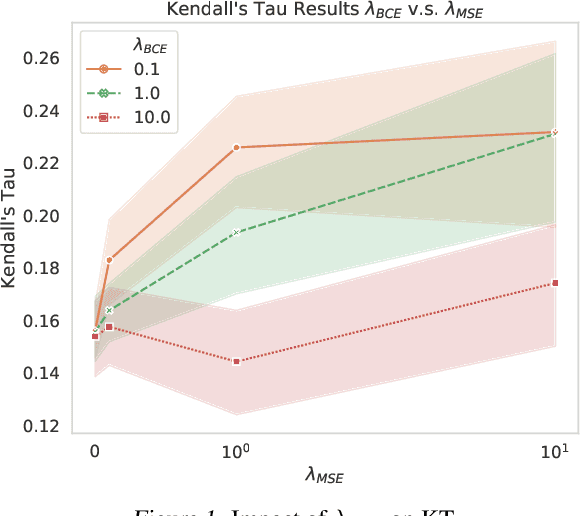
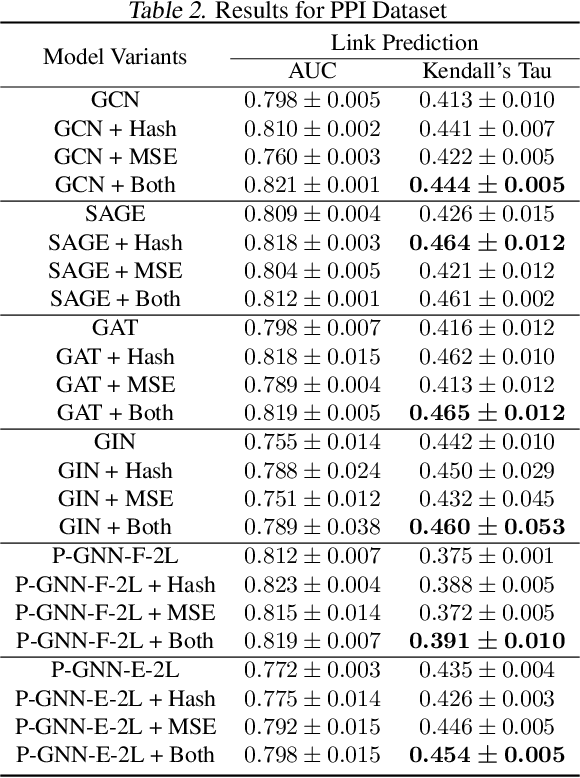
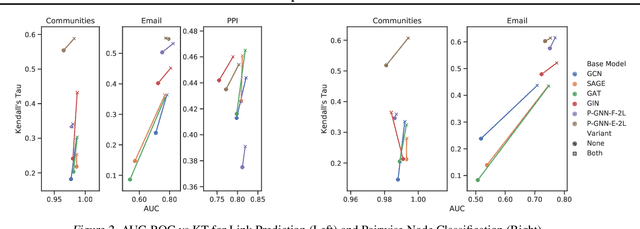
Many tasks that rely on representations of nodes in graphs would benefit if those representations were faithful to distances between nodes in the graph. Geometric techniques to extract such representations have poor scaling over large graph size, and recent advances in Graph Neural Network (GNN) algorithms have limited ability to reflect graph distance information beyond the first degree neighborhood. To enable this highly desired capability, we propose a technique to learn Isometric Graph Neural Networks (IGNN), which requires changing the input representation space and loss function to enable any GNN algorithm to generate representations that reflect distances between nodes. We experiment with the isometric technique on several GNN architectures for modeling multiple prediction tasks on multiple datasets. In addition to an improvement in AUC-ROC as high as $43\%$ in these experiments, we observe a consistent and substantial improvement as high as 400% in Kendall's Tau (KT), a measure that directly reflects distance information, demonstrating that the learned embeddings do account for graph distances.
Discovering Hypernymy in Text-Rich Heterogeneous Information Network by Exploiting Context Granularity
Sep 04, 2019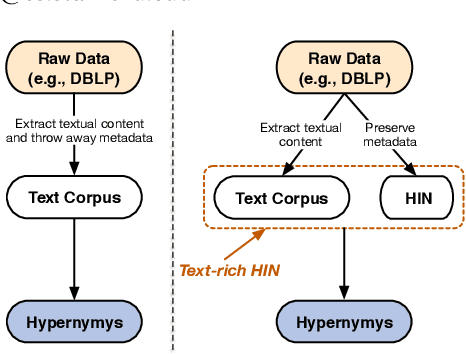

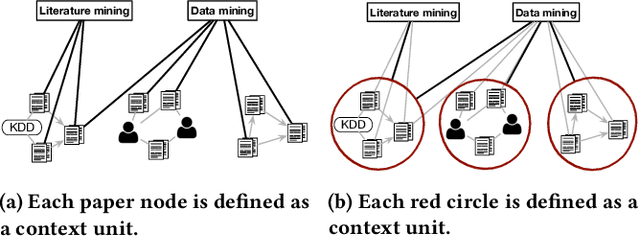

Text-rich heterogeneous information networks (text-rich HINs) are ubiquitous in real-world applications. Hypernymy, also known as is-a relation or subclass-of relation, lays in the core of many knowledge graphs and benefits many downstream applications. Existing methods of hypernymy discovery either leverage textual patterns to extract explicitly mentioned hypernym-hyponym pairs, or learn a distributional representation for each term of interest based its context. These approaches rely on statistical signals from the textual corpus, and their effectiveness would therefore be hindered when the signals from the corpus are not sufficient for all terms of interest. In this work, we propose to discover hypernymy in text-rich HINs, which can introduce additional high-quality signals. We develop a new framework, named HyperMine, that exploits multi-granular contexts and combines signals from both text and network without human labeled data. HyperMine extends the definition of context to the scenario of text-rich HIN. For example, we can define typed nodes and communities as contexts. These contexts encode signals of different granularities and we feed them into a hypernymy inference model. HyperMine learns this model using weak supervision acquired based on high-precision textual patterns. Extensive experiments on two large real-world datasets demonstrate the effectiveness of HyperMine and the utility of modeling context granularity. We further show a case study that a high-quality taxonomy can be generated solely based on the hypernymy discovered by HyperMine.