 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Machine Learning in Mental Health: A Survey of Data, Algorithms, and Challenges
Jul 23, 2024
The application of machine learning (ML) in detecting, diagnosing, and treating mental health disorders is garnering increasing attention. Traditionally, research has focused on single modalities, such as text from clinical notes, audio from speech samples, or video of interaction patterns. Recently, multimodal ML, which combines information from multiple modalities, has demonstrated significant promise in offering novel insights into human behavior patterns and recognizing mental health symptoms and risk factors. Despite its potential, multimodal ML in mental health remains an emerging field, facing several complex challenges before practical applications can be effectively developed. This survey provides a comprehensive overview of the data availability and current state-of-the-art multimodal ML applications for mental health. It discusses key challenges that must be addressed to advance the field. The insights from this survey aim to deepen the understanding of the potential and limitations of multimodal ML in mental health, guiding future research and development in this evolving domain.
EquiPrompt: Debiasing Diffusion Models via Iterative Bootstrapping in Chain of Thoughts
Jun 13, 2024



In the domain of text-to-image generative models, the inadvertent propagation of biases inherent in training datasets poses significant ethical challenges, particularly in the generation of socially sensitive content. This paper introduces EquiPrompt, a novel method employing Chain of Thought (CoT) reasoning to reduce biases in text-to-image generative models. EquiPrompt uses iterative bootstrapping and bias-aware exemplar selection to balance creativity and ethical responsibility. It integrates iterative reasoning refinement with controlled evaluation techniques, addressing zero-shot CoT issues in sensitive contexts. Experiments on several generation tasks show EquiPrompt effectively lowers bias while maintaining generative quality, advancing ethical AI and socially responsible creative processes.Code will be publically available.
A Computational Analysis of the Dehumanisation of Migrants from Syria and Ukraine in Slovene News Media
Apr 10, 2024

Dehumanisation involves the perception and or treatment of a social group's members as less than human. This phenomenon is rarely addressed with computational linguistic techniques. We adapt a recently proposed approach for English, making it easier to transfer to other languages and to evaluate, introducing a new sentiment resource, the use of zero-shot cross-lingual valence and arousal detection, and a new method for statistical significance testing. We then apply it to study attitudes to migration expressed in Slovene newspapers, to examine changes in the Slovene discourse on migration between the 2015-16 migration crisis following the war in Syria and the 2022-23 period following the war in Ukraine. We find that while this discourse became more negative and more intense over time, it is less dehumanising when specifically addressing Ukrainian migrants compared to others.
Reformulating NLP tasks to Capture Longitudinal Manifestation of Language Disorders in People with Dementia
Oct 15, 2023



Dementia is associated with language disorders which impede communication. Here, we automatically learn linguistic disorder patterns by making use of a moderately-sized pre-trained language model and forcing it to focus on reformulated natural language processing (NLP) tasks and associated linguistic patterns. Our experiments show that NLP tasks that encapsulate contextual information and enhance the gradient signal with linguistic patterns benefit performance. We then use the probability estimates from the best model to construct digital linguistic markers measuring the overall quality in communication and the intensity of a variety of language disorders. We investigate how the digital markers characterize dementia speech from a longitudinal perspective. We find that our proposed communication marker is able to robustly and reliably characterize the language of people with dementia, outperforming existing linguistic approaches; and shows external validity via significant correlation with clinical markers of behaviour. Finally, our proposed linguistic disorder markers provide useful insights into gradual language impairment associated with disease progression.
Lon-eå at SemEval-2023 Task 11: A Comparison of\\Activation Functions for Soft and Hard Label Prediction
Mar 04, 2023We study the influence of different activation functions in the output layer of deep neural network models for soft and hard label prediction in the learning with disagreement task. In this task, the goal is to quantify the amount of disagreement via predicting soft labels. To predict the soft labels, we use BERT-based preprocessors and encoders and vary the activation function used in the output layer, while keeping other parameters constant. The soft labels are then used for the hard label prediction. The activation functions considered are sigmoid as well as a step-function that is added to the model post-training and a sinusoidal activation function, which is introduced for the first time in this paper.
CoRAL: a Context-aware Croatian Abusive Language Dataset
Nov 11, 2022



In light of unprecedented increases in the popularity of the internet and social media, comment moderation has never been a more relevant task. Semi-automated comment moderation systems greatly aid human moderators by either automatically classifying the examples or allowing the moderators to prioritize which comments to consider first. However, the concept of inappropriate content is often subjective, and such content can be conveyed in many subtle and indirect ways. In this work, we propose CoRAL -- a language and culturally aware Croatian Abusive dataset covering phenomena of implicitness and reliance on local and global context. We show experimentally that current models degrade when comments are not explicit and further degrade when language skill and context knowledge are required to interpret the comment.
Misspelling Semantics In Thai
Jun 20, 2022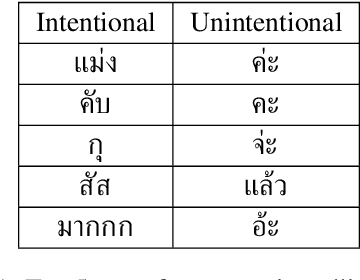
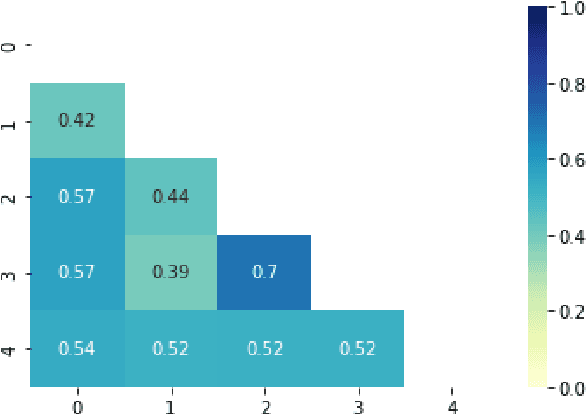
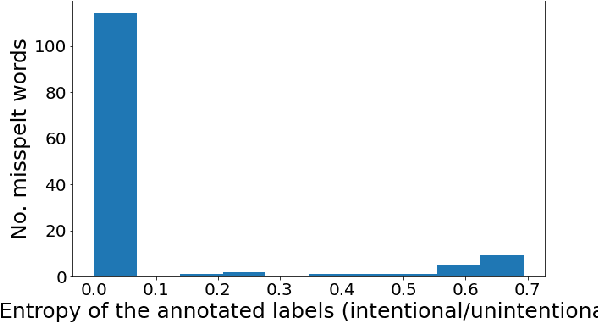
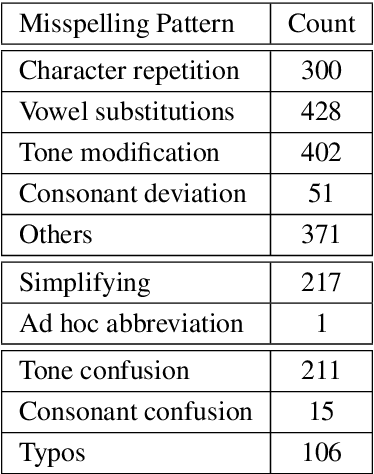
User-generated content is full of misspellings. Rather than being just random noise, we hypothesise that many misspellings contain hidden semantics that can be leveraged for language understanding tasks. This paper presents a fine-grained annotated corpus of misspelling in Thai, together with an analysis of misspelling intention and its possible semantics to get a better understanding of the misspelling patterns observed in the corpus. In addition, we introduce two approaches to incorporate the semantics of misspelling: Misspelling Average Embedding (MAE) and Misspelling Semantic Tokens (MST). Experiments on a sentiment analysis task confirm our overall hypothesis: additional semantics from misspelling can boost the micro F1 score up to 0.4-2%, while blindly normalising misspelling is harmful and suboptimal.
Measuring and Improving Compositional Generalization in Text-to-SQL via Component Alignment
May 04, 2022



In text-to-SQL tasks -- as in much of NLP -- compositional generalization is a major challenge: neural networks struggle with compositional generalization where training and test distributions differ. However, most recent attempts to improve this are based on word-level synthetic data or specific dataset splits to generate compositional biases. In this work, we propose a clause-level compositional example generation method. We first split the sentences in the Spider text-to-SQL dataset into sub-sentences, annotating each sub-sentence with its corresponding SQL clause, resulting in a new dataset Spider-SS. We then construct a further dataset, Spider-CG, by composing Spider-SS sub-sentences in different combinations, to test the ability of models to generalize compositionally. Experiments show that existing models suffer significant performance degradation when evaluated on Spider-CG, even though every sub-sentence is seen during training. To deal with this problem, we modify a number of state-of-the-art models to train on the segmented data of Spider-SS, and we show that this method improves the generalization performance.
Not All Comments are Equal: Insights into Comment Moderation from a Topic-Aware Model
Sep 21, 2021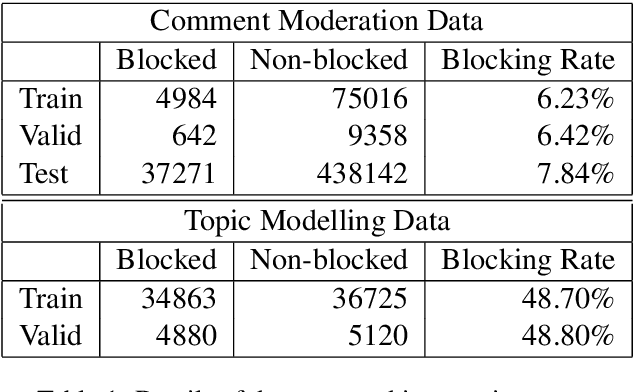
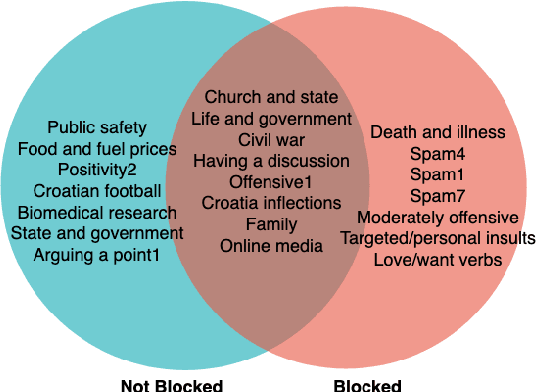
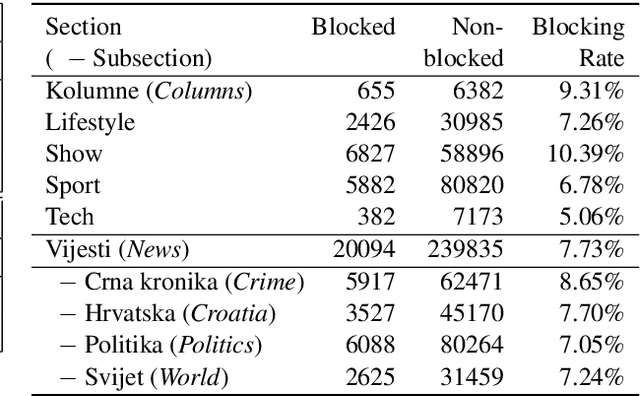
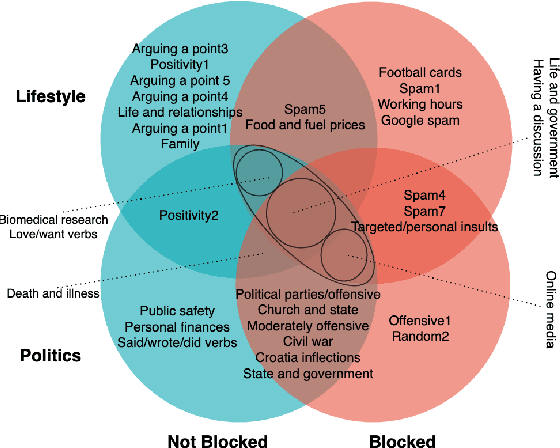
Moderation of reader comments is a significant problem for online news platforms. Here, we experiment with models for automatic moderation, using a dataset of comments from a popular Croatian newspaper. Our analysis shows that while comments that violate the moderation rules mostly share common linguistic and thematic features, their content varies across the different sections of the newspaper. We therefore make our models topic-aware, incorporating semantic features from a topic model into the classification decision. Our results show that topic information improves the performance of the model, increases its confidence in correct outputs, and helps us understand the model's outputs.
Exploring Underexplored Limitations of Cross-Domain Text-to-SQL Generalization
Sep 11, 2021

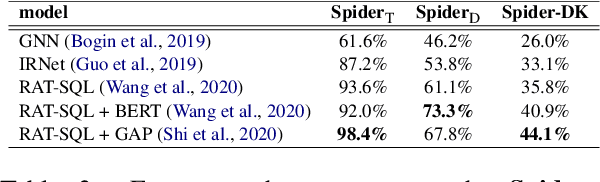
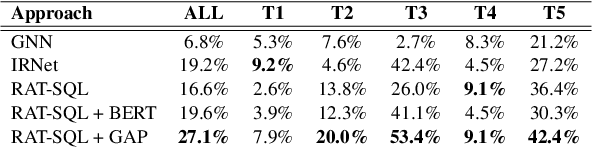
Recently, there has been significant progress in studying neural networks for translating text descriptions into SQL queries under the zero-shot cross-domain setting. Despite achieving good performance on some public benchmarks, we observe that existing text-to-SQL models do not generalize when facing domain knowledge that does not frequently appear in the training data, which may render the worse prediction performance for unseen domains. In this work, we investigate the robustness of text-to-SQL models when the questions require rarely observed domain knowledge. In particular, we define five types of domain knowledge and introduce Spider-DK (DK is the abbreviation of domain knowledge), a human-curated dataset based on the Spider benchmark for text-to-SQL translation. NL questions in Spider-DK are selected from Spider, and we modify some samples by adding domain knowledge that reflects real-world question paraphrases. We demonstrate that the prediction accuracy dramatically drops on samples that require such domain knowledge, even if the domain knowledge appears in the training set, and the model provides the correct predictions for related training samples.