 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOasisSimp: An Open-source Asian-English Sentence Simplification Dataset
Mar 14, 2026Sentence simplification aims to make complex text more accessible by reducing linguistic complexity while preserving the original meaning. However, progress in this area remains limited for mid-resource and low-resource languages due to the scarcity of high-quality data. To address this gap, we introduce the OasisSimp dataset, a multilingual dataset for sentence-level simplification covering five languages: English, Sinhala, Tamil, Pashto, and Thai. Among these, no prior sentence simplification datasets exist for Thai, Pashto, and Tamil, while limited data is available for Sinhala. Each language simplification dataset was created by trained annotators who followed detailed guidelines to simplify sentences while maintaining meaning, fluency, and grammatical correctness. We evaluate eight open-weight multilingual Large Language Models (LLMs) on the OasisSimp dataset and observe substantial performance disparities between high-resource and low-resource languages, highlighting the simplification challenges in multilingual settings. The OasisSimp dataset thus provides both a valuable multilingual resource and a challenging benchmark, revealing the limitations of current LLM-based simplification methods and paving the way for future research in low-resource sentence simplification. The dataset is available at https://OasisSimpDataset.github.io/.
Misspelling Semantics In Thai
Jun 20, 2022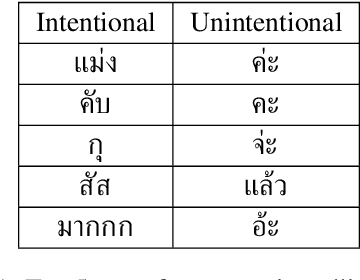
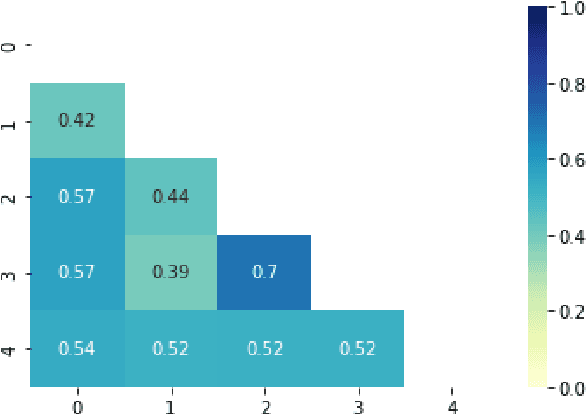
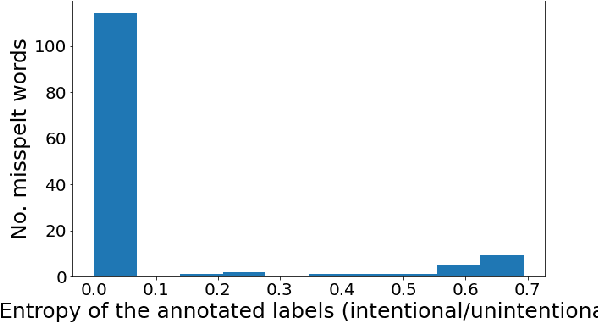
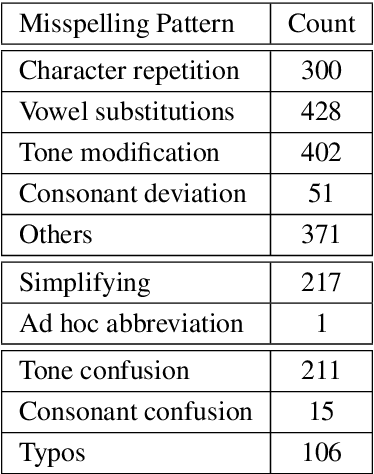
User-generated content is full of misspellings. Rather than being just random noise, we hypothesise that many misspellings contain hidden semantics that can be leveraged for language understanding tasks. This paper presents a fine-grained annotated corpus of misspelling in Thai, together with an analysis of misspelling intention and its possible semantics to get a better understanding of the misspelling patterns observed in the corpus. In addition, we introduce two approaches to incorporate the semantics of misspelling: Misspelling Average Embedding (MAE) and Misspelling Semantic Tokens (MST). Experiments on a sentiment analysis task confirm our overall hypothesis: additional semantics from misspelling can boost the micro F1 score up to 0.4-2%, while blindly normalising misspelling is harmful and suboptimal.