 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Alignment Beyond KL: Variance Minimisation as Effective Policy Optimiser
Feb 12, 2026Diffusion alignment adapts pretrained diffusion models to sample from reward-tilted distributions along the denoising trajectory. This process naturally admits a Sequential Monte Carlo (SMC) interpretation, where the denoising model acts as a proposal and reward guidance induces importance weights. Motivated by this view, we introduce Variance Minimisation Policy Optimisation (VMPO), which formulates diffusion alignment as minimising the variance of log importance weights rather than directly optimising a Kullback-Leibler (KL) based objective. We prove that the variance objective is minimised by the reward-tilted target distribution and that, under on-policy sampling, its gradient coincides with that of standard KL-based alignment. This perspective offers a common lens for understanding diffusion alignment. Under different choices of potential functions and variance minimisation strategies, VMPO recovers various existing methods, while also suggesting new design directions beyond KL.
Clustering-driven Memory Compression for On-device Large Language Models
Jan 24, 2026Large language models (LLMs) often rely on user-specific memories distilled from past interactions to enable personalized generation. A common practice is to concatenate these memories with the input prompt, but this approach quickly exhausts the limited context available in on-device LLMs. Compressing memories by averaging can mitigate context growth, yet it frequently harms performance due to semantic conflicts across heterogeneous memories. In this work, we introduce a clustering-based memory compression strategy that balances context efficiency and personalization quality. Our method groups memories by similarity and merges them within clusters prior to concatenation, thereby preserving coherence while reducing redundancy. Experiments demonstrate that our approach substantially lowers the number of memory tokens while outperforming baseline strategies such as naive averaging or direct concatenation. Furthermore, for a fixed context budget, clustering-driven merging yields more compact memory representations and consistently enhances generation quality.
Data-driven Clustering and Merging of Adapters for On-device Large Language Models
Jan 24, 2026On-device large language models commonly employ task-specific adapters (e.g., LoRAs) to deliver strong performance on downstream tasks. While storing all available adapters is impractical due to memory constraints, mobile devices typically have sufficient capacity to store a limited number of these parameters. This raises a critical challenge: how to select representative adapters that generalize well across multiple tasks - a problem that remains unexplored in existing literature. We propose a novel method D2C for adapter clustering that leverages minimal task-specific examples (e.g., 10 per task) and employs an iterative optimization process to refine cluster assignments. The adapters within each cluster are merged, creating multi-task adapters deployable on resource-constrained devices. Experimental results demonstrate that our method effectively boosts performance for considered storage budgets.
CG-TTRL: Context-Guided Test-Time Reinforcement Learning for On-Device Large Language Models
Nov 09, 2025Test-time Reinforcement Learning (TTRL) has shown promise in adapting foundation models for complex tasks at test-time, resulting in large performance improvements. TTRL leverages an elegant two-phase sampling strategy: first, multi-sampling derives a pseudo-label via majority voting, while subsequent downsampling and reward-based fine-tuning encourages the model to explore and learn diverse valid solutions, with the pseudo-label modulating the reward signal. Meanwhile, in-context learning has been widely explored at inference time and demonstrated the ability to enhance model performance without weight updates. However, TTRL's two-phase sampling strategy under-utilizes contextual guidance, which can potentially improve pseudo-label accuracy in the initial exploitation phase while regulating exploration in the second. To address this, we propose context-guided TTRL (CG-TTRL), integrating context dynamically into both sampling phases and propose a method for efficient context selection for on-device applications. Our evaluations on mathematical and scientific QA benchmarks show CG-TTRL outperforms TTRL (e.g. additional 7% relative accuracy improvement over TTRL), while boosting efficiency by obtaining strong performance after only a few steps of test-time training (e.g. 8% relative improvement rather than 1% over TTRL after 3 steps).
HydraOpt: Navigating the Efficiency-Performance Trade-off of Adapter Merging
Jul 23, 2025Large language models (LLMs) often leverage adapters, such as low-rank-based adapters, to achieve strong performance on downstream tasks. However, storing a separate adapter for each task significantly increases memory requirements, posing a challenge for resource-constrained environments such as mobile devices. Although model merging techniques can reduce storage costs, they typically result in substantial performance degradation. In this work, we introduce HydraOpt, a new model merging technique that capitalizes on the inherent similarities between the matrices of low-rank adapters. Unlike existing methods that produce a fixed trade-off between storage size and performance, HydraOpt allows us to navigate this spectrum of efficiency and performance. Our experiments show that HydraOpt significantly reduces storage size (48% reduction) compared to storing all adapters, while achieving competitive performance (0.2-1.8% drop). Furthermore, it outperforms existing merging techniques in terms of performance at the same or slightly worse storage efficiency.
Unlocking the Value of Decentralized Data: A Federated Dual Learning Approach for Model Aggregation
Mar 26, 2025Artificial Intelligence (AI) technologies have revolutionized numerous fields, yet their applications often rely on costly and time-consuming data collection processes. Federated Learning (FL) offers a promising alternative by enabling AI models to be trained on decentralized data where data is scattered across clients (distributed nodes). However, existing FL approaches struggle to match the performance of centralized training due to challenges such as heterogeneous data distribution and communication delays, limiting their potential for breakthroughs. We observe that many real-world use cases involve hybrid data regimes, in which a server (center node) has access to some data while a large amount of data is distributed across associated clients. To improve the utilization of decentralized data under this regime, address data heterogeneity issue, and facilitate asynchronous communication between the server and clients, we propose a dual learning approach that leverages centralized data at the server to guide the merging of model updates from clients. Our method accommodates scenarios where server data is out-of-domain relative to decentralized client data, making it applicable to a wide range of use cases. We provide theoretical analysis demonstrating the faster convergence of our method compared to existing methods. Furthermore, experimental results across various scenarios show that our approach significantly outperforms existing technologies, highlighting its potential to unlock the value of large amounts of decentralized data.
Randomized Asymmetric Chain of LoRA: The First Meaningful Theoretical Framework for Low-Rank Adaptation
Oct 10, 2024



Fine-tuning has become a popular approach to adapting large foundational models to specific tasks. As the size of models and datasets grows, parameter-efficient fine-tuning techniques are increasingly important. One of the most widely used methods is Low-Rank Adaptation (LoRA), with adaptation update expressed as the product of two low-rank matrices. While LoRA was shown to possess strong performance in fine-tuning, it often under-performs when compared to full-parameter fine-tuning (FPFT). Although many variants of LoRA have been extensively studied empirically, their theoretical optimization analysis is heavily under-explored. The starting point of our work is a demonstration that LoRA and its two extensions, Asymmetric LoRA and Chain of LoRA, indeed encounter convergence issues. To address these issues, we propose Randomized Asymmetric Chain of LoRA (RAC-LoRA) -- a general optimization framework that rigorously analyzes the convergence rates of LoRA-based methods. Our approach inherits the empirical benefits of LoRA-style heuristics, but introduces several small but important algorithmic modifications which turn it into a provably convergent method. Our framework serves as a bridge between FPFT and low-rank adaptation. We provide provable guarantees of convergence to the same solution as FPFT, along with the rate of convergence. Additionally, we present a convergence analysis for smooth, non-convex loss functions, covering gradient descent, stochastic gradient descent, and federated learning settings. Our theoretical findings are supported by experimental results.
Synthesizing Mixed-type Electronic Health Records using Diffusion Models
Feb 28, 2023



Electronic Health Records (EHRs) contain sensitive patient information, which presents privacy concerns when sharing such data. Synthetic data generation is a promising solution to mitigate these risks, often relying on deep generative models such as Generative Adversarial Networks (GANs). However, recent studies have shown that diffusion models offer several advantages over GANs, such as generation of more realistic synthetic data and stable training in generating data modalities, including image, text, and sound. In this work, we investigate the potential of diffusion models for generating realistic mixed-type tabular EHRs, comparing TabDDPM model with existing methods on four datasets in terms of data quality, utility, privacy, and augmentation. Our experiments demonstrate that TabDDPM outperforms the state-of-the-art models across all evaluation metrics, except for privacy, which confirms the trade-off between privacy and utility.
Mixture of Input-Output Hidden Markov Models for Heterogeneous Disease Progression Modeling
Jul 24, 2022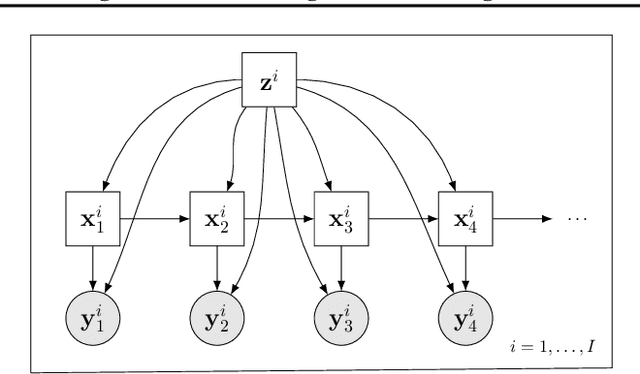
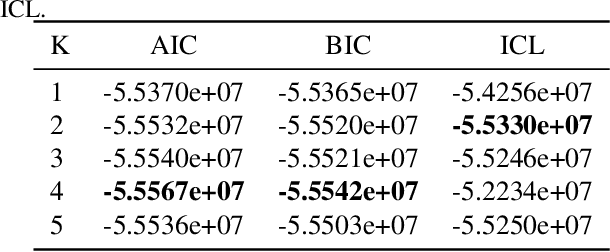
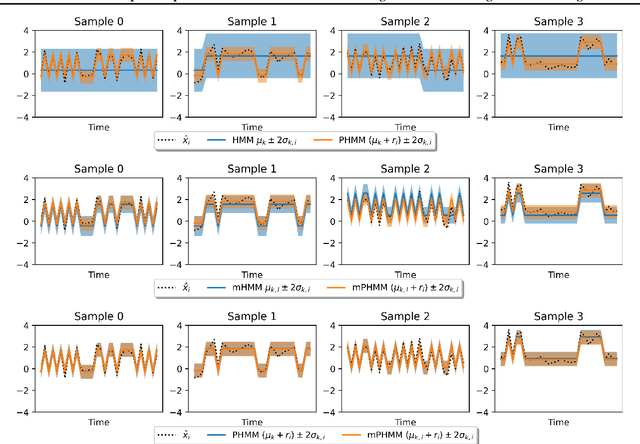
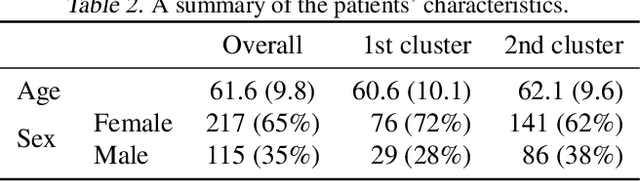
A particular challenge for disease progression modeling is the heterogeneity of a disease and its manifestations in the patients. Existing approaches often assume the presence of a single disease progression characteristics which is unlikely for neurodegenerative disorders such as Parkinson's disease. In this paper, we propose a hierarchical time-series model that can discover multiple disease progression dynamics. The proposed model is an extension of an input-output hidden Markov model that takes into account the clinical assessments of patients' health status and prescribed medications. We illustrate the benefits of our model using a synthetically generated dataset and a real-world longitudinal dataset for Parkinson's disease.
Identifying the Units of Measurement in Tabular Data
Nov 23, 2021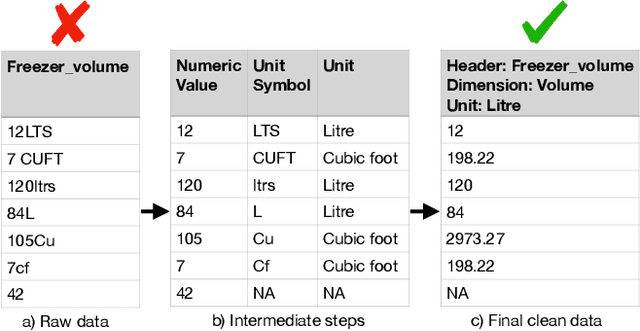
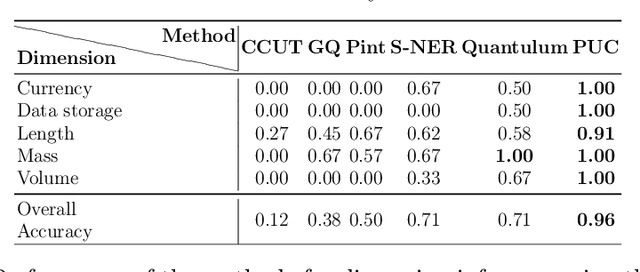
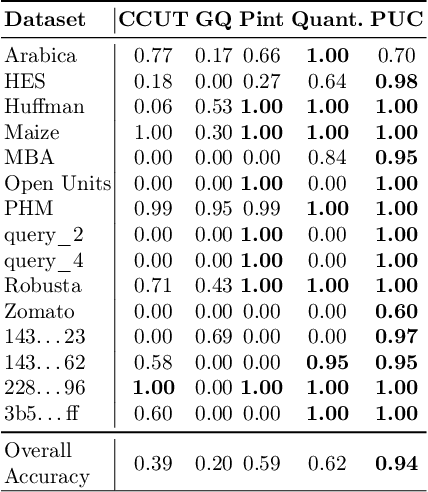
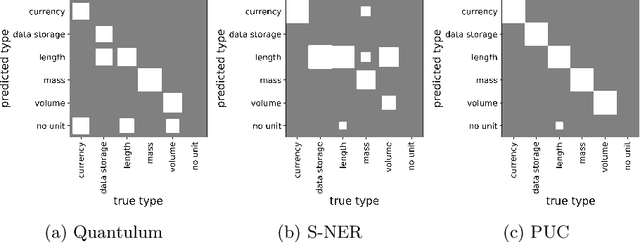
We consider the problem of identifying the units of measurement in a data column that contains both numeric values and unit symbols in each row, e.g., "5.2 l", "7 pints". In this case we seek to identify the dimension of the column (e.g. volume) and relate the unit symbols to valid units (e.g. litre, pint) obtained from a knowledge graph. Below we present PUC, a Probabilistic Unit Canonicalizer that can accurately identify the units of measurement, extract semantic descriptions of quantitative data columns and canonicalize their entries. We present the first messy real-world tabular datasets annotated for units of measurement, which can enable and accelerate the research in this area. Our experiments on these datasets show that PUC achieves better results than existing solutions.