 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFP-NAS: Fast Probabilistic Neural Architecture Search
Nov 24, 2020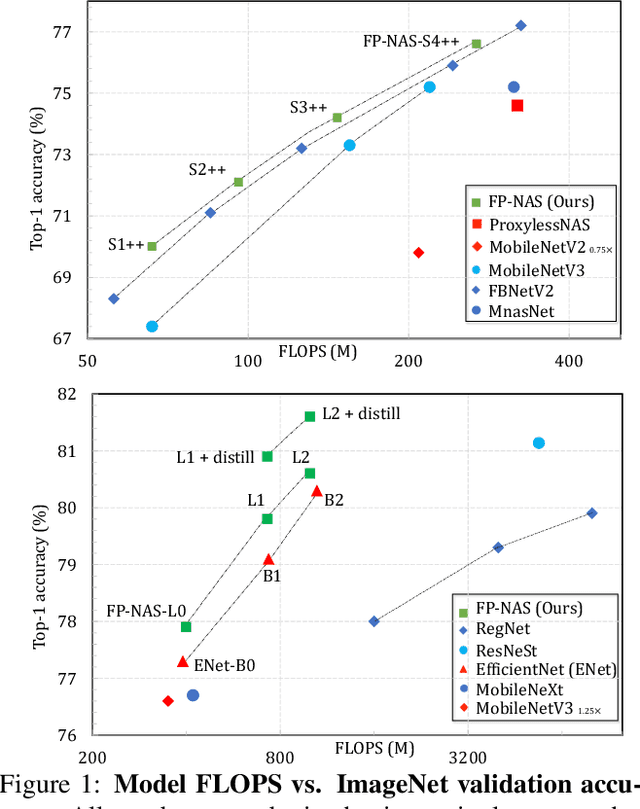
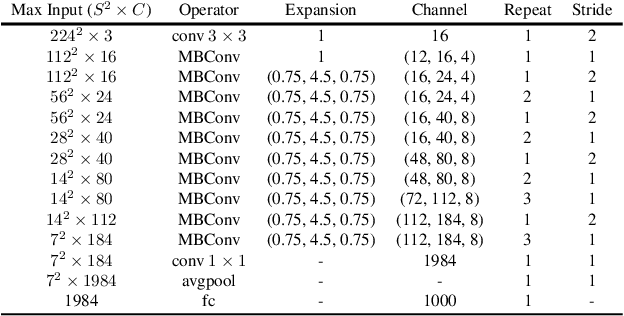
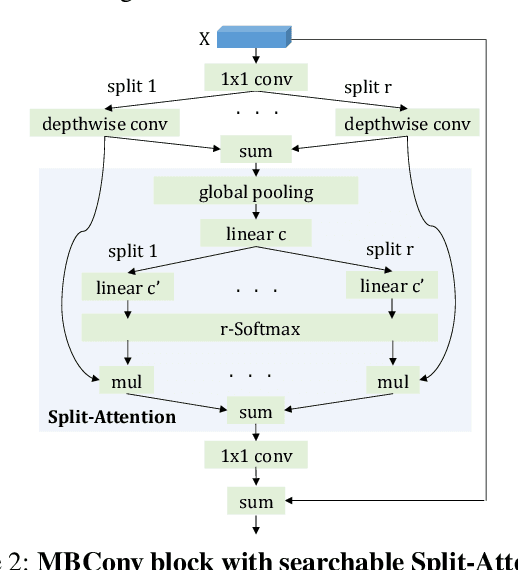

Differential Neural Architecture Search (NAS) requires all layer choices to be held in memory simultaneously; this limits the size of both search space and final architecture. In contrast, Probabilistic NAS, such as PARSEC, learns a distribution over high-performing architectures, and uses only as much memory as needed to train a single model. Nevertheless, it needs to sample many architectures, making it computationally expensive for searching in an extensive space. To solve these problems, we propose a sampling method adaptive to the distribution entropy, drawing more samples to encourage explorations at the beginning, and reducing samples as learning proceeds. Furthermore, to search fast in the multi-variate space, we propose a coarse-to-fine strategy by using a factorized distribution at the beginning which can reduce the number of architecture parameters by over an order of magnitude.We call this method Fast Probabilistic NAS (FP-NAS). Compared with PARSEC, it can sample 64% fewer architectures and search 2.1x faster. Compared with FBNetV2, FP-NAS is 1.9x - 3.6x faster, and the searched models outperform FBNetV2 models on ImageNet. FP-NAS allows us to expand the giant FBNetV2 space to be wider (i.e. larger channel choices) and deeper (i.e. more blocks), while adding Split-Attention block and enabling the search over the number of splits. When searching a model of size 0.4G FLOPS, FP-NAS is 132x faster than EfficientNet, and the searched FP-NAS-L0 model outperforms EfficientNet-B0 by 0.6% accuracy. Without using any architecture surrogate or scaling tricks, we directly search large models up to 1.0G FLOPS. Our FP-NAS-L2 model with simple distillation outperforms BigNAS-XL with advanced inplace distillation by 0.7% accuracy with less FLOPS.
SF-Net: Single-Frame Supervision for Temporal Action Localization
Mar 20, 2020In this paper, we study an intermediate form of supervision, i.e., single-frame supervision, for temporal action localization (TAL). To obtain the single-frame supervision, the annotators are asked to identify only a single frame within the temporal window of an action. This can significantly reduce the labor cost of obtaining full supervision which requires annotating the action boundary. Compared to the weak supervision that only annotates the video-level label, the single-frame supervision introduces extra temporal action signals while maintaining low annotation overhead. To make full use of such single-frame supervision, we propose a unified system called SF-Net. First, we propose to predict an actionness score for each video frame. Along with a typical category score, the actionness score can provide comprehensive information about the occurrence of a potential action and aid the temporal boundary refinement during inference. Second, we mine pseudo action and background frames based on the single-frame annotations. We identify pseudo action frames by adaptively expanding each annotated single frame to its nearby, contextual frames and we mine pseudo background frames from all the unannotated frames across multiple videos. Together with the ground-truth labeled frames, these pseudo-labeled frames are further used for training the classifier. In extensive experiments on THUMOS14, GTEA, and BEOID, SF-Net significantly improves upon state-of-the-art weakly-supervised methods in terms of both segment localization and single-frame localization. Notably, SF-Net achieves comparable results to its fully-supervised counterpart which requires much more resource intensive annotations.
Don't Judge an Object by Its Context: Learning to Overcome Contextual Bias
Jan 09, 2020
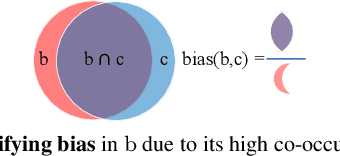
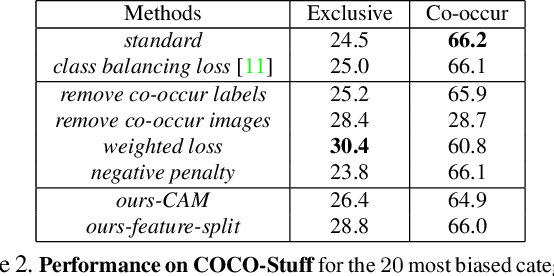
Existing models often leverage co-occurrences between objects and their context to improve recognition accuracy. However, strongly relying on context risks a model's generalizability, especially when typical co-occurrence patterns are absent. This work focuses on addressing such contextual biases to improve the robustness of the learnt feature representations. Our goal is to accurately recognize a category in the absence of its context, without compromising on performance when it co-occurs with context. Our key idea is to decorrelate feature representations of a category from its co-occurring context. We achieve this by learning a feature subspace that explicitly represents categories occurring in the absence of context along side a joint feature subspace that represents both categories and context. Our very simple yet effective method is extensible to two multi-label tasks -- object and attribute classification. On 4 challenging datasets, we demonstrate the effectiveness of our method in reducing contextual bias.
Only Time Can Tell: Discovering Temporal Data for Temporal Modeling
Jul 19, 2019
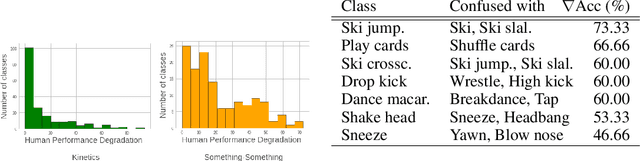


Understanding temporal information and how the visual world changes over time is a fundamental ability of intelligent systems. In video understanding, temporal information is at the core of many current challenges, including compression, efficient inference, motion estimation or summarization. However, in current video datasets it has been observed that action classes can often be recognized without any temporal information from a single frame of video. As a result, both benchmarking and training in these datasets may give an unintentional advantage to models with strong image understanding capabilities, as opposed to those with strong temporal understanding. In this paper we address this problem head on by identifying action classes where temporal information is actually necessary to recognize them and call these "temporal classes". Selecting temporal classes using a computational method would bias the process. Instead, we propose a methodology based on a simple and effective human annotation experiment. We remove just the temporal information by shuffling frames in time and measure if the action can still be recognized. Classes that cannot be recognized when frames are not in order are included in the temporal Dataset. We observe that this set is statistically different from other static classes, and that performance in it correlates with a network's ability to capture temporal information. Thus we use it as a benchmark on current popular networks, which reveals a series of interesting facts. We also explore the effect of training on the temporal dataset, and observe that this leads to better generalization in unseen classes, demonstrating the need for more temporal data. We hope that the proposed dataset of temporal categories will help guide future research in temporal modeling for better video understanding.
FASTER Recurrent Networks for Video Classification
Jun 10, 2019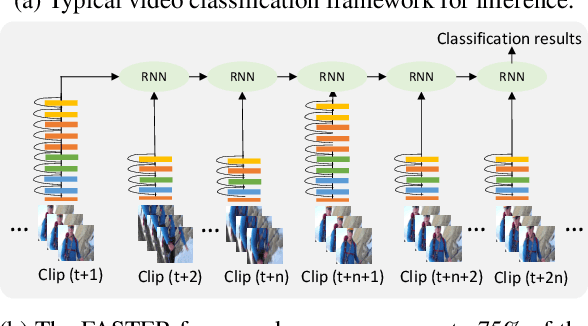
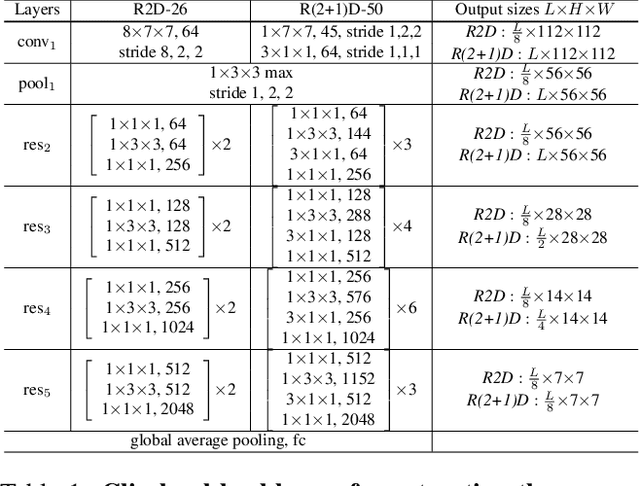
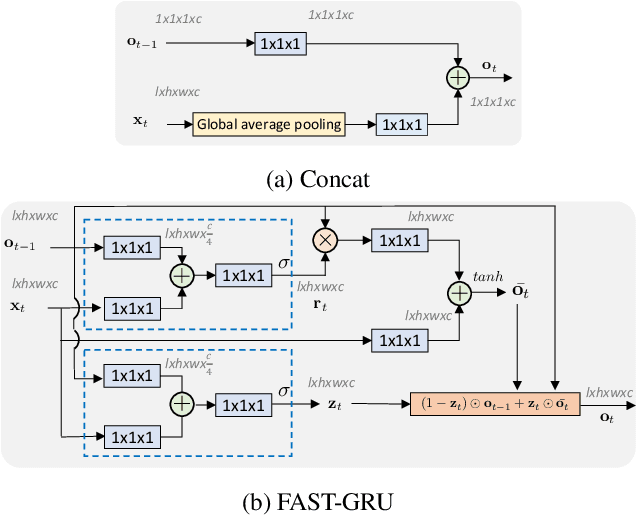
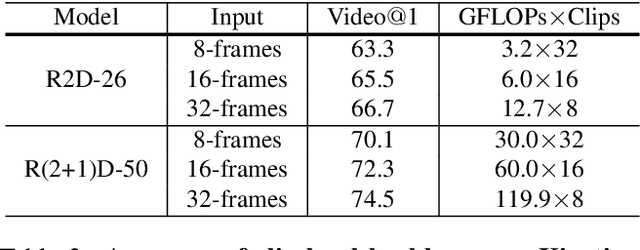
Video classification methods often divide the video into short clips, do inference on these clips independently, and then aggregate these predictions to generate the final classification result. Treating these highly-correlated clips as independent both ignores the temporal structure of the signal and carries a large computational cost: the model must process each clip from scratch. To reduce this cost, recent efforts have focused on designing more efficient clip-level network architectures. Less attention, however, has been paid to the overall framework, including how to benefit from correlations between neighboring clips and improving the aggregation strategy itself. In this paper we leverage the correlation between adjacent video clips to address the problem of computational cost efficiency in video classification at the aggregation stage. More specifically, given a clip feature representation, the problem of computing next clip's representation becomes much easier. We propose a novel recurrent architecture called FASTER for video-level classification, that combines high quality, expensive representations of clips, that capture the action in detail, and lightweight representations, which capture scene changes in the video and avoid redundant computation. We also propose a novel processing unit to learn integration of clip-level representations, as well as their temporal structure. We call this unit FAST-GRU, as it is based on the Gated Recurrent Unit (GRU). The proposed framework achieves significantly better FLOPs vs. accuracy trade-off at inference time. Compared to existing approaches, our proposed framework reduces the FLOPs by more than 10x while maintaining similar accuracy across popular datasets, such as Kinetics, UCF101 and HMDB51.
Video Modeling with Correlation Networks
Jun 07, 2019
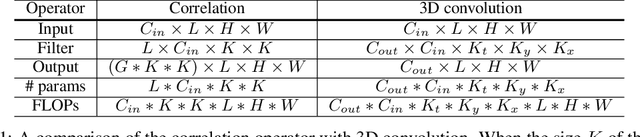
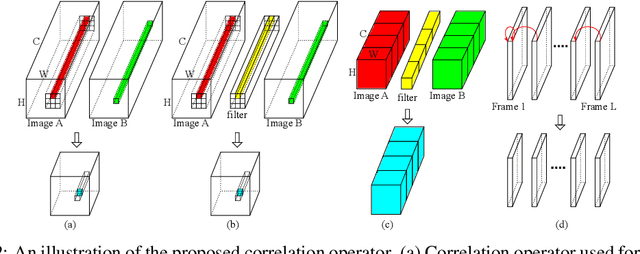
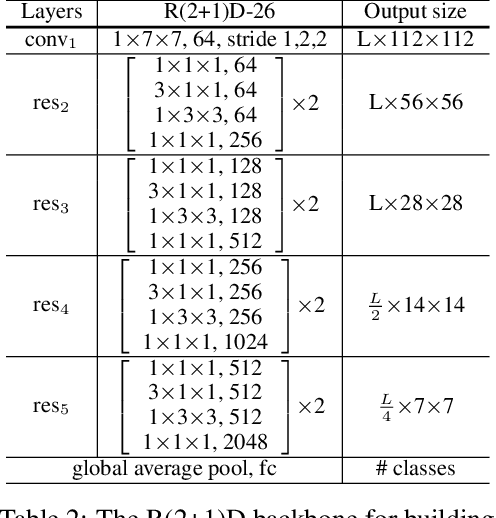
Motion is a salient cue to recognize actions in video. Modern action recognition models leverage motion information either explicitly by using optical flow as input or implicitly by means of 3D convolutional filters that simultaneously capture appearance and motion information. This paper proposes an alternative approach based on a learnable correlation operator that can be used to establish frame-to-frame matches over convolutional feature maps in the different layers of the network. The proposed architecture enables the fusion of this explicit temporal matching information with traditional appearance cues captured by 2D convolution. Our correlation network compares favorably with widely-used 3D CNNs for video modeling, and achieves competitive results over the prominent two-stream network while being much faster to train. We empirically demonstrate that correlation networks produce strong results on a variety of video datasets, and outperform the state of the art on three popular benchmarks for action recognition: Kinetics, Something-Something and Diving48.
What Makes Training Multi-Modal Networks Hard?
May 29, 2019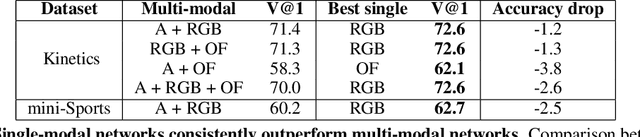
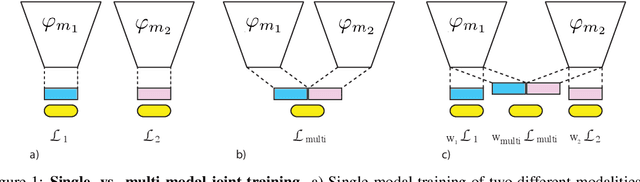
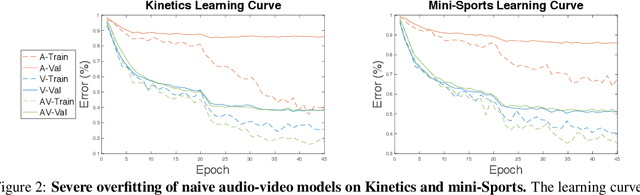

Consider end-to-end training of a multi-modal vs. a single-modal network on a task with multiple input modalities: the multi-modal network receives more information, so it should match or outperform its single-modal counterpart. In our experiments, however, we observe the opposite: the best single-modal network always outperforms the multi-modal network. This observation is consistent across different combinations of modalities and on different tasks and benchmarks. This paper identifies two main causes for this performance drop: first, multi-modal networks are often prone to overfitting due to increased capacity. Second, different modalities overfit and generalize at different rates, so training them jointly with a single optimization strategy is sub-optimal. We address these two problems with a technique we call Gradient Blending, which computes an optimal blend of modalities based on their overfitting behavior. We demonstrate that Gradient Blending outperforms widely-used baselines for avoiding overfitting and achieves state-of-the-art accuracy on various tasks including fine-grained sport classification, human action recognition, and acoustic event detection.
Large-scale weakly-supervised pre-training for video action recognition
May 02, 2019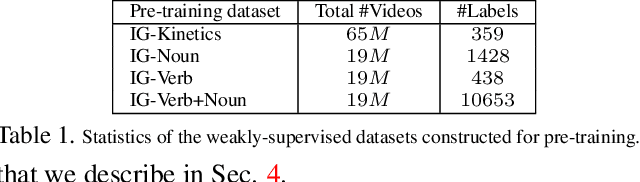
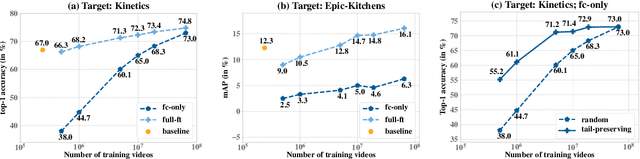
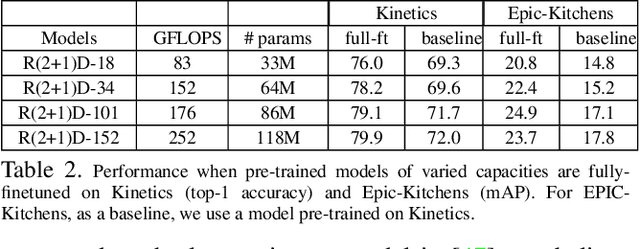

Current fully-supervised video datasets consist of only a few hundred thousand videos and fewer than a thousand domain-specific labels. This hinders the progress towards advanced video architectures. This paper presents an in-depth study of using large volumes of web videos for pre-training video models for the task of action recognition. Our primary empirical finding is that pre-training at a very large scale (over 65 million videos), despite on noisy social-media videos and hashtags, substantially improves the state-of-the-art on three challenging public action recognition datasets. Further, we examine three questions in the construction of weakly-supervised video action datasets. First, given that actions involve interactions with objects, how should one construct a verb-object pre-training label space to benefit transfer learning the most? Second, frame-based models perform quite well on action recognition; is pre-training for good image features sufficient or is pre-training for spatio-temporal features valuable for optimal transfer learning? Finally, actions are generally less well-localized in long videos vs. short videos; since action labels are provided at a video level, how should one choose video clips for best performance, given some fixed budget of number or minutes of videos?
Video Classification with Channel-Separated Convolutional Networks
Apr 04, 2019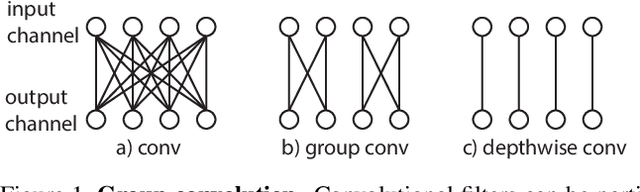
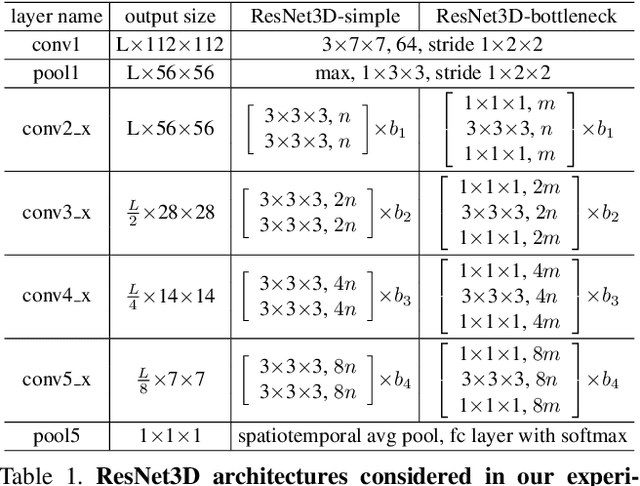
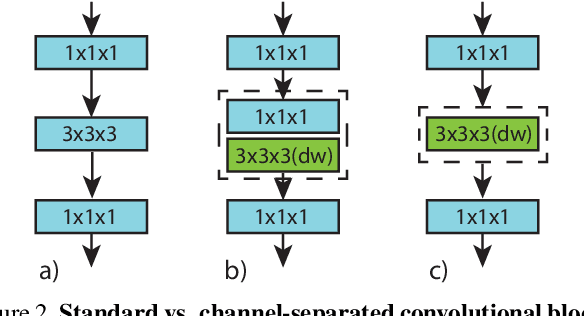
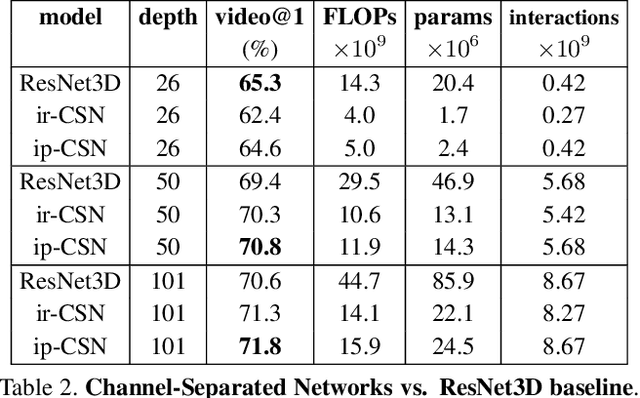
Group convolution has been shown to offer great computational savings in various 2D convolutional architectures for image classification. It is natural to ask: 1) if group convolution can help to alleviate the high computational cost of video classification networks; 2) what factors matter the most in 3D group convolutional networks; and 3) what are good computation/accuracy trade-offs with 3D group convolutional networks. This paper studies different effects of group convolution in 3D convolutional networks for video classification. We empirically demonstrate that the amount of channel interactions plays an important role in the accuracy of group convolutional networks. Our experiments suggest two main findings. First, it is a good practice to factorize 3D convolutions by separating channel interactions and spatiotemporal interactions as this leads to improved accuracy and lower computational cost. Second, 3D channel-separated convolutions provide a form of regularization, yielding lower training accuracy but higher test accuracy compared to 3D convolutions. These two empirical findings lead us to design an architecture -- Channel-Separated Convolutional Network (CSN) -- which is simple, efficient, yet accurate. On Kinetics and Sports1M, our CSNs significantly outperform state-of-the-art models while being 11-times more efficient.
Latent Geometry and Memorization in Generative Models
May 25, 2017
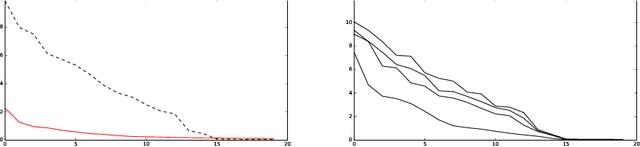
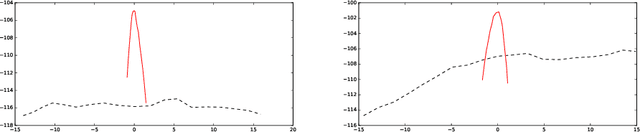
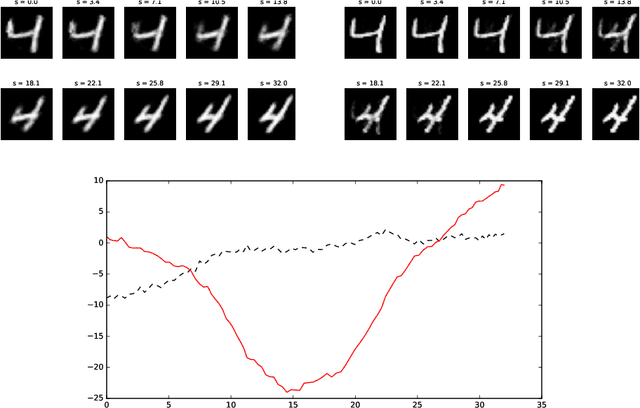
It can be difficult to tell whether a trained generative model has learned to generate novel examples or has simply memorized a specific set of outputs. In published work, it is common to attempt to address this visually, for example by displaying a generated example and its nearest neighbor(s) in the training set (in, for example, the L2 metric). As any generative model induces a probability density on its output domain, we propose studying this density directly. We first study the geometry of the latent representation and generator, relate this to the output density, and then develop techniques to compute and inspect the output density. As an application, we demonstrate that "memorization" tends to a density made of delta functions concentrated on the memorized examples. We note that without first understanding the geometry, the measurement would be essentially impossible to make.