 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcess Matters more than Output for Distinguishing Humans from Machines
May 07, 2026Reliable human-machine discrimination is becoming increasingly important as large language models and autonomous agents are deployed in online settings. Existing approaches evaluate whether a system can produce behavior or responses indistinguishable from those of a human, following the emphasis on outputs as a criterion for intelligence proposed by Alan Turing. Cognitive science offers an alternative perspective: evaluating the process by which behavior is produced. To test whether cognitive processes can reliably distinguish humans from machines, we introduce CogCAPTCHA30, a battery of 30 cognitive tasks designed to elicit diagnostic process-level features even when task performance is matched. Across the battery, process-level features provide stronger discriminative signal than performance metrics alone, reliably distinguishing humans from agents even under output matching (mean process-feature classifier AUC = 0.88). To evaluate agentic process differences, we compare off-the-shelf frontier agents (Claude Sonnet 4.5, GPT-5, Gemini 2.5 Pro), Centaur (a language model fine-tuned on 10.7M human decisions), and two task-specific fine-tuning approaches applied to Qwen2.5-1.5B-Instruct: action-level supervised fine-tuning (A-SFT) and process-level fine-tuning (P-SFT), which directly optimizes process features. Broad fine-tuning on human decisions improves human-like task processes relative to off-the-shelf agents, while task-specific process-level supervision further improves behavioral mimicry. However, this advantage diminishes under cross-task transfer when supervised process targets do not naturally generalize across tasks. Explicit process-level supervision can improve human behavioral mimicry, but only if appropriate task-specific process representations are available, highlighting process specification as a bottleneck for achieving human-like cognitive processes in machines.
When a language model is optimized for reasoning, does it still show embers of autoregression? An analysis of OpenAI o1
Oct 02, 2024In "Embers of Autoregression" (McCoy et al., 2023), we showed that several large language models (LLMs) have some important limitations that are attributable to their origins in next-word prediction. Here we investigate whether these issues persist with o1, a new system from OpenAI that differs from previous LLMs in that it is optimized for reasoning. We find that o1 substantially outperforms previous LLMs in many cases, with particularly large improvements on rare variants of common tasks (e.g., forming acronyms from the second letter of each word in a list, rather than the first letter). Despite these quantitative improvements, however, o1 still displays the same qualitative trends that we observed in previous systems. Specifically, o1 - like previous LLMs - is sensitive to the probability of examples and tasks, performing better and requiring fewer "thinking tokens" in high-probability settings than in low-probability ones. These results show that optimizing a language model for reasoning can mitigate but might not fully overcome the language model's probability sensitivity.
Bias amplification in experimental social networks is reduced by resampling
Aug 15, 2022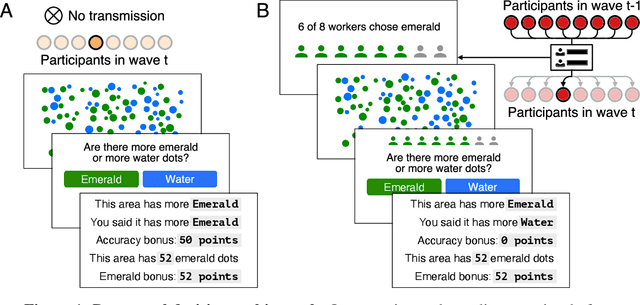
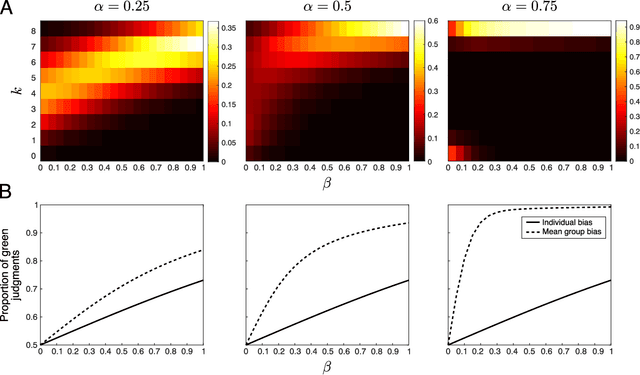
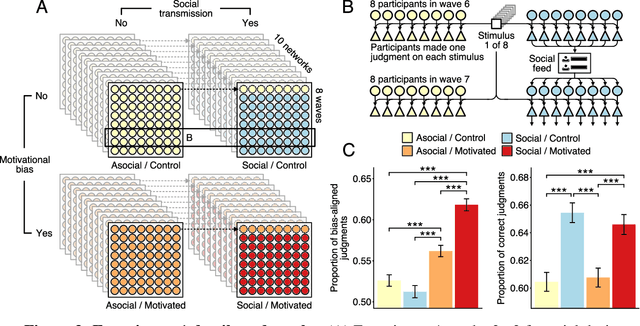
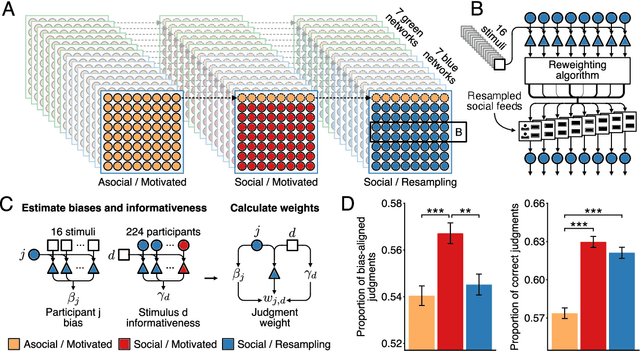
Large-scale social networks are thought to contribute to polarization by amplifying people's biases. However, the complexity of these technologies makes it difficult to identify the mechanisms responsible and to evaluate mitigation strategies. Here we show under controlled laboratory conditions that information transmission through social networks amplifies motivational biases on a simple perceptual decision-making task. Participants in a large behavioral experiment showed increased rates of biased decision-making when part of a social network relative to asocial participants, across 40 independently evolving populations. Drawing on techniques from machine learning and Bayesian statistics, we identify a simple adjustment to content-selection algorithms that is predicted to mitigate bias amplification. This algorithm generates a sample of perspectives from within an individual's network that is more representative of the population as a whole. In a second large experiment, this strategy reduced bias amplification while maintaining the benefits of information sharing.