 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcess Matters more than Output for Distinguishing Humans from Machines
May 07, 2026Reliable human-machine discrimination is becoming increasingly important as large language models and autonomous agents are deployed in online settings. Existing approaches evaluate whether a system can produce behavior or responses indistinguishable from those of a human, following the emphasis on outputs as a criterion for intelligence proposed by Alan Turing. Cognitive science offers an alternative perspective: evaluating the process by which behavior is produced. To test whether cognitive processes can reliably distinguish humans from machines, we introduce CogCAPTCHA30, a battery of 30 cognitive tasks designed to elicit diagnostic process-level features even when task performance is matched. Across the battery, process-level features provide stronger discriminative signal than performance metrics alone, reliably distinguishing humans from agents even under output matching (mean process-feature classifier AUC = 0.88). To evaluate agentic process differences, we compare off-the-shelf frontier agents (Claude Sonnet 4.5, GPT-5, Gemini 2.5 Pro), Centaur (a language model fine-tuned on 10.7M human decisions), and two task-specific fine-tuning approaches applied to Qwen2.5-1.5B-Instruct: action-level supervised fine-tuning (A-SFT) and process-level fine-tuning (P-SFT), which directly optimizes process features. Broad fine-tuning on human decisions improves human-like task processes relative to off-the-shelf agents, while task-specific process-level supervision further improves behavioral mimicry. However, this advantage diminishes under cross-task transfer when supervised process targets do not naturally generalize across tasks. Explicit process-level supervision can improve human behavioral mimicry, but only if appropriate task-specific process representations are available, highlighting process specification as a bottleneck for achieving human-like cognitive processes in machines.
Muscle-inspired flexible mechanical logic architecture for colloidal robotics
Dec 17, 2020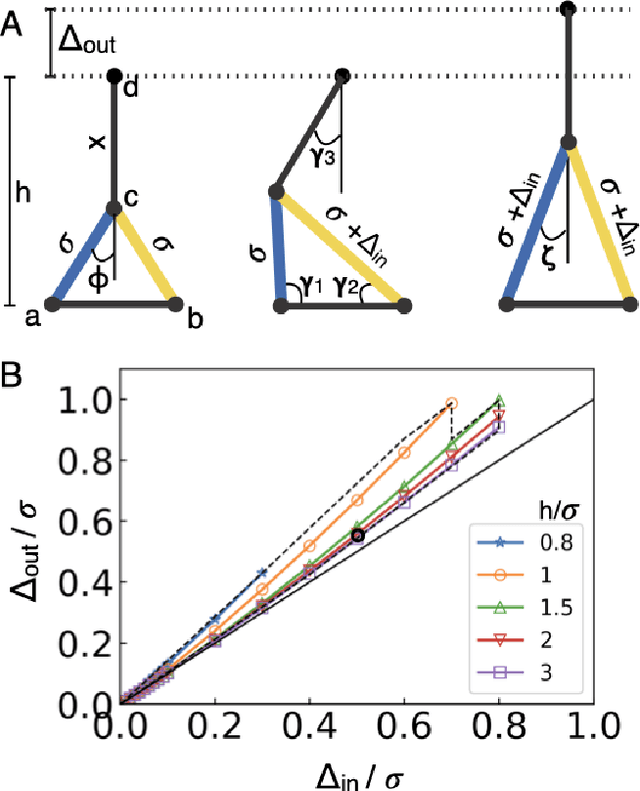
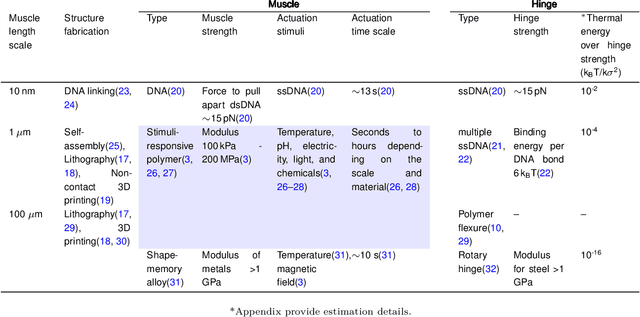
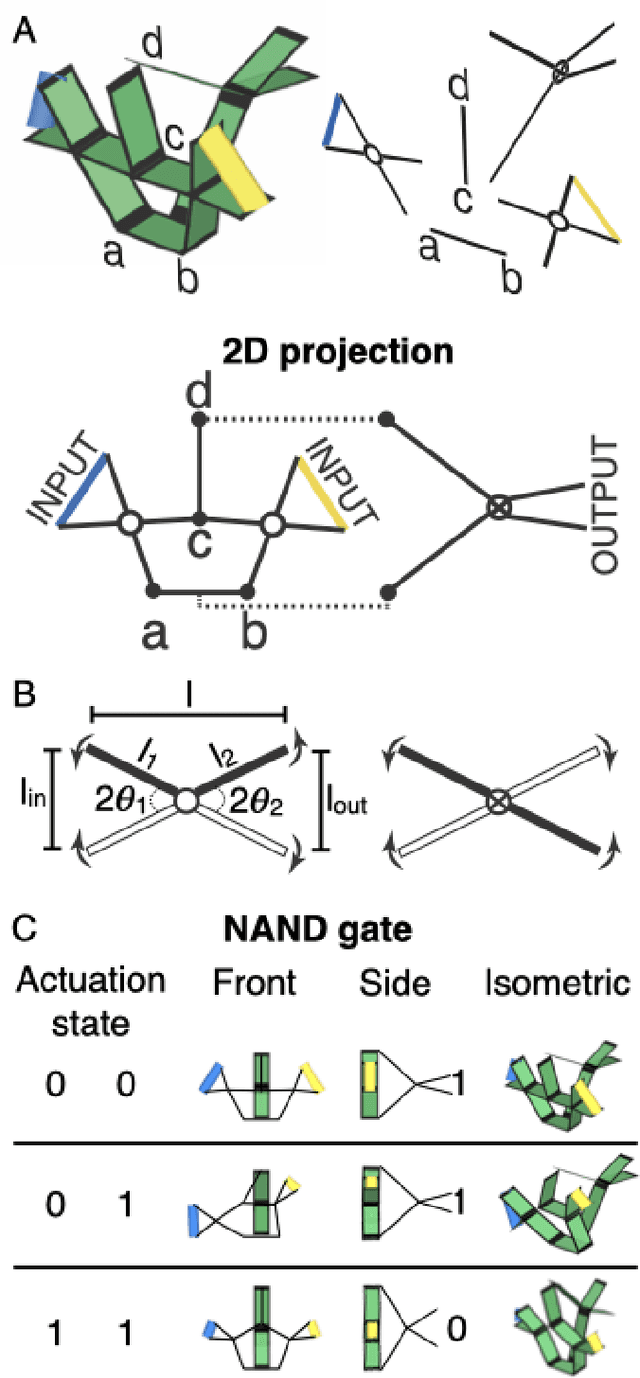
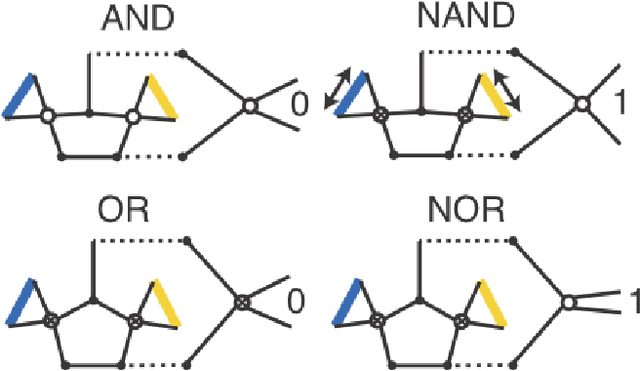
Materials that respond to external stimuli by expanding or contracting provide a transduction route that integrates sensing and actuation powered directly by the stimuli. This motivates us to build colloidal scale robots using these materials that can morph into arbitrary configurations. For intelligent use of global stimuli in robotic systems, computation ability needs to be incorporated within them. The challenge is to design an architecture that is compact, material agnostic, stable under stochastic forces and can employ stimuli-responsive materials. We present an architecture that computes combinatorial logic using mechanical gates that use muscle-like response - expansion and contraction - as circuit signal with additional benefits of logic circuitry being physically flexible and able to be retrofit to arbitrary robot bodies. We mathematically analyze gate geometry and discuss tuning it for the given requirements of signal dimension and magnitude. We validate the function and stability of the design at the colloidal scale using Brownian dynamics simulations. We also demonstrate the gate design using a 3D printed model. Finally, we simulate a complete robot that folds into Tetris shapes.
Scaling up Psychology via Scientific Regret Minimization: A Case Study in Moral Decision-Making
Oct 16, 2019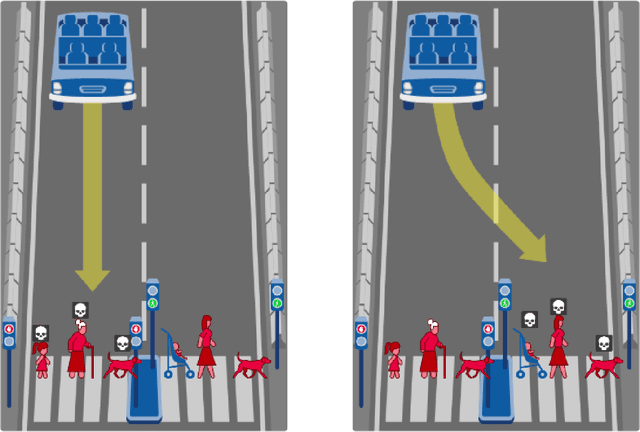
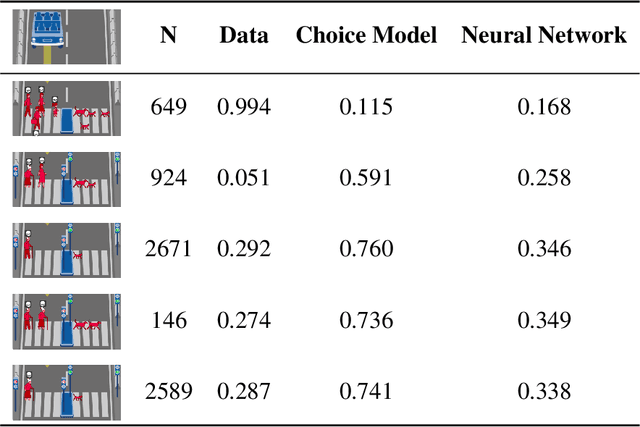
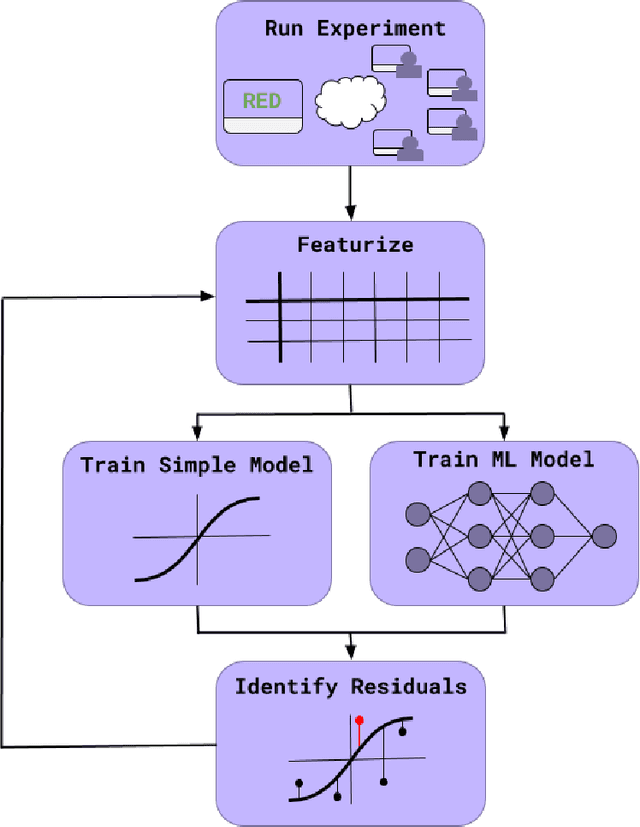
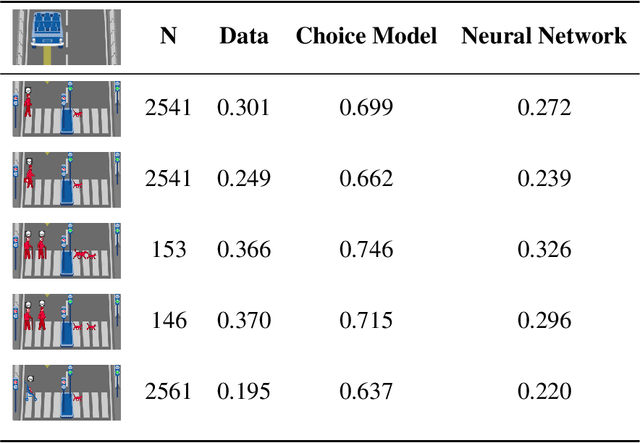
Do large datasets provide value to psychologists? Without a systematic methodology for working with such datasets, there is a valid concern that analyses will produce noise artifacts rather than true effects. In this paper, we offer a way to enable researchers to systematically build models and identify novel phenomena in large datasets. One traditional approach is to analyze the residuals of models---the biggest errors they make in predicting the data---to discover what might be missing from those models. However, once a dataset is sufficiently large, machine learning algorithms approximate the true underlying function better than the data, suggesting instead that the predictions of these data-driven models should be used to guide model-building. We call this approach "Scientific Regret Minimization" (SRM) as it focuses on minimizing errors for cases that we know should have been predictable. We demonstrate this methodology on a subset of the Moral Machine dataset, a public collection of roughly forty million moral decisions. Using SRM, we found that incorporating a set of deontological principles that capture dimensions along which groups of agents can vary (e.g. sex and age) improves a computational model of human moral judgment. Furthermore, we were able to identify and independently validate three interesting moral phenomena: criminal dehumanization, age of responsibility, and asymmetric notions of responsibility.
Using Machine Learning to Guide Cognitive Modeling: A Case Study in Moral Reasoning
Feb 25, 2019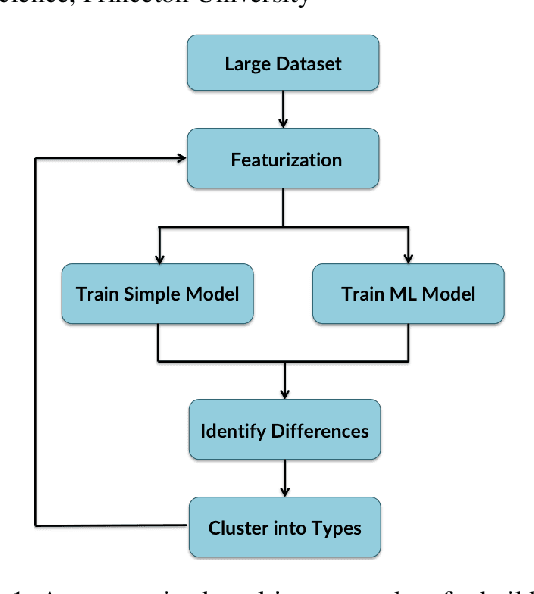
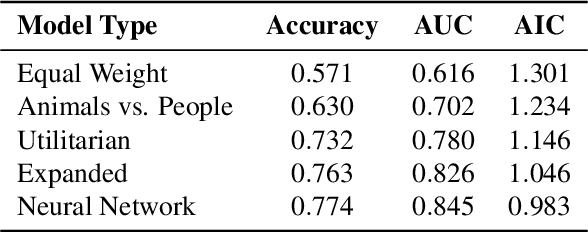
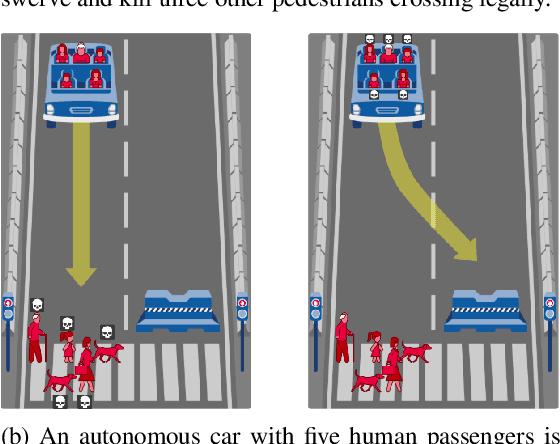
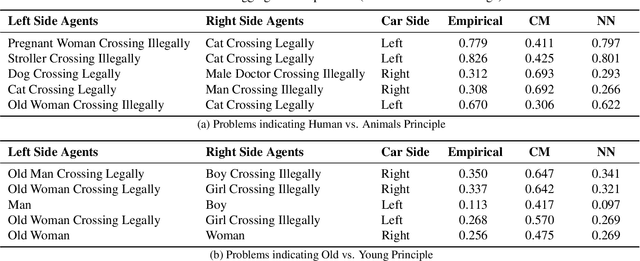
Large-scale behavioral datasets enable researchers to use complex machine learning algorithms to better predict human behavior, yet this increased predictive power does not always lead to a better understanding of the behavior in question. In this paper, we outline a data-driven, iterative procedure that allows cognitive scientists to use machine learning to generate models that are both interpretable and accurate. We demonstrate this method in the domain of moral decision-making, where standard experimental approaches often identify relevant principles that influence human judgments, but fail to generalize these findings to "real world" situations that place these principles in conflict. The recently released Moral Machine dataset allows us to build a powerful model that can predict the outcomes of these conflicts while remaining simple enough to explain the basis behind human decisions.