 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPEX-MEM: Agentic Semi-Structured Memory with Temporal Reasoning for Long-Term Conversational AI
Apr 15, 2026Large language models still struggle with reliable long-term conversational memory: simply enlarging context windows or applying naive retrieval often introduces noise and destabilizes responses. We present APEX-MEM, a conversational memory system that combines three key innovations: (1) a property graph which uses domain-agnostic ontology to structure conversations as temporally grounded events in an entity-centric framework, (2) append-only storage that preserves the full temporal evolution of information, and (3) a multi-tool retrieval agent that understands and resolves conflicting or evolving information at query time, producing a compact and contextually relevant memory summary. This retrieval-time resolution preserves the full interaction history while suppressing irrelevant details. APEX-MEM achieves 88.88% accuracy on LOCOMO's Question Answering task and 86.2% on LongMemEval, outperforming state-of-the-art session-aware approaches and demonstrating that structured property graphs enable more temporally coherent long-term conversational reasoning.
APEX-EM: Non-Parametric Online Learning for Autonomous Agents via Structured Procedural-Episodic Experience Replay
Mar 31, 2026LLM-based autonomous agents lack persistent procedural memory: they re-derive solutions from scratch even when structurally identical tasks have been solved before. We present \textbf{APEX-EM}, a non-parametric online learning framework that accumulates, retrieves, and reuses structured procedural plans without modifying model weights. APEX-EM introduces: (1) a \emph{structured experience representation} encoding the full procedural-episodic trace of each execution -- planning steps, artifacts, iteration history with error analysis, and quality scores; (2) a \emph{Plan-Retrieve-Generate-Iterate-Ingest} (PRGII) workflow with Task Verifiers providing multi-dimensional reward signals; and (3) a \emph{dual-outcome Experience Memory} with hybrid retrieval combining semantic search, structural signature matching, and plan DAG traversal -- enabling cross-domain transfer between tasks sharing no lexical overlap but analogous operational structure. Successful experiences serve as positive in-context examples; failures as negative examples with structured error annotations. We evaluate on BigCodeBench~\cite{zhuo2025bigcodebench}, KGQAGen-10k~\cite{zhang2025kgqagen}, and Humanity's Last Exam~\cite{phan2025hle} using Claude Sonnet 4.5 and Opus 4.5. On KGQAGen-10k, APEX-EM achieves 89.6\% accuracy versus 41.3\% without memory (+48.3pp), surpassing the oracle-retrieval upper bound (84.9\%). On BigCodeBench, it reaches 83.3\% SR from a 53.9\% baseline (+29.4pp), exceeding MemRL's~\cite{memrl2025} +11.0pp gain under comparable frozen-backbone conditions (noting backbone differences controlled for in our analysis). On HLE, entity graph retrieval reaches 48.0\% from 25.2\% (+22.8pp). Ablations show component value is task-dependent: rich judge feedback is negligible for code generation but critical for structured queries (+10.3pp), while binary-signal iteration partially compensates for weaker feedback.
Controlled Text Generation with Hidden Representation Transformations
May 31, 2023



We propose CHRT (Control Hidden Representation Transformation) - a controlled language generation framework that steers large language models to generate text pertaining to certain attributes (such as toxicity). CHRT gains attribute control by modifying the hidden representation of the base model through learned transformations. We employ a contrastive-learning framework to learn these transformations that can be combined to gain multi-attribute control. The effectiveness of CHRT is experimentally shown by comparing it with seven baselines over three attributes. CHRT outperforms all the baselines in the task of detoxification, positive sentiment steering, and text simplification while minimizing the loss in linguistic qualities. Further, our approach has the lowest inference latency of only 0.01 seconds more than the base model, making it the most suitable for high-performance production environments. We open-source our code and release two novel datasets to further propel controlled language generation research.
Online Cluster Validity Indices for Streaming Data
Jan 08, 2018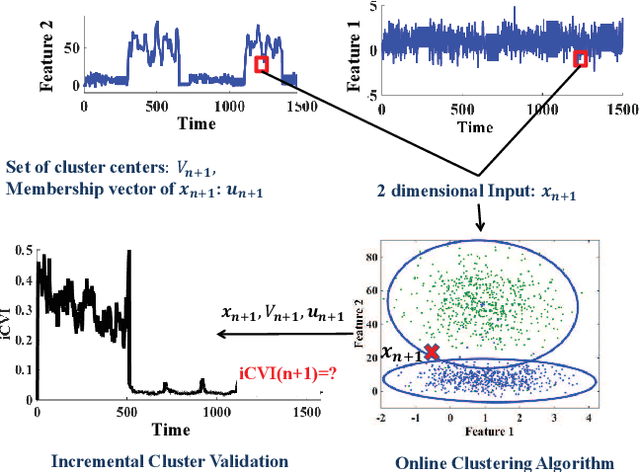
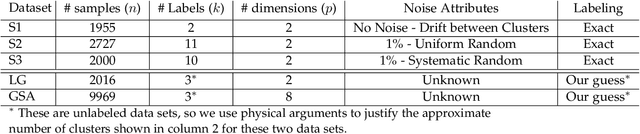
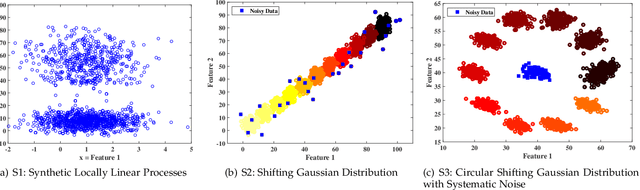
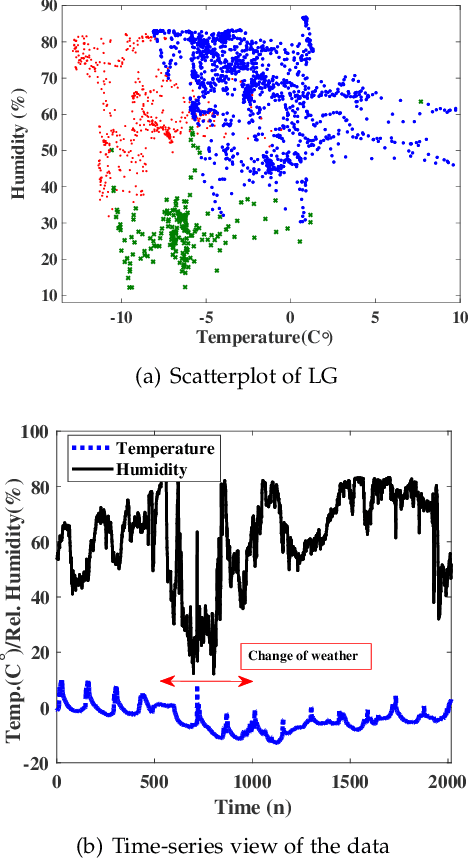
Cluster analysis is used to explore structure in unlabeled data sets in a wide range of applications. An important part of cluster analysis is validating the quality of computationally obtained clusters. A large number of different internal indices have been developed for validation in the offline setting. However, this concept has not been extended to the online setting. A key challenge is to find an efficient incremental formulation of an index that can capture both cohesion and separation of the clusters over potentially infinite data streams. In this paper, we develop two online versions (with and without forgetting factors) of the Xie-Beni and Davies-Bouldin internal validity indices, and analyze their characteristics, using two streaming clustering algorithms (sk-means and online ellipsoidal clustering), and illustrate their use in monitoring evolving clusters in streaming data. We also show that incremental cluster validity indices are capable of sending a distress signal to online monitors when evolving clusters go awry. Our numerical examples indicate that the incremental Xie-Beni index with forgetting factor is superior to the other three indices tested.