 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynergicLearning: Neural Network-Based Feature Extraction for Highly-Accurate Hyperdimensional Learning
Aug 04, 2020
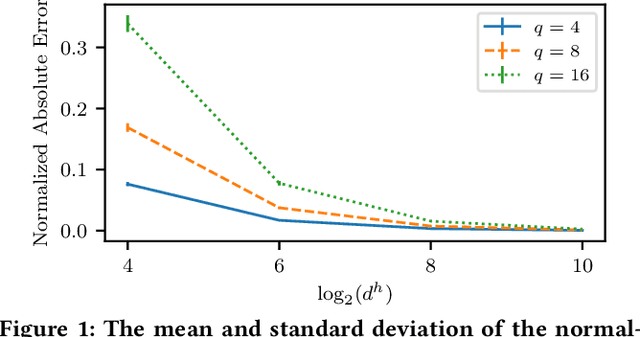
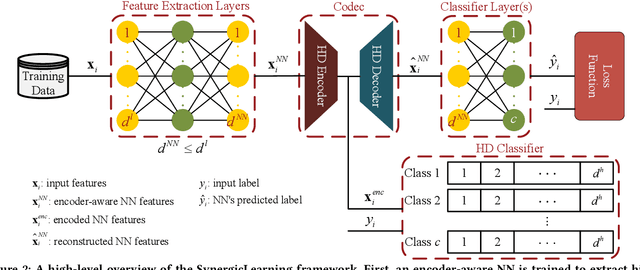

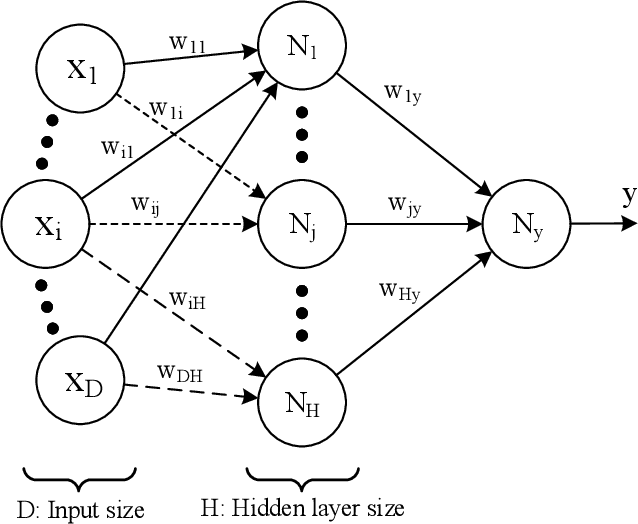
Machine learning models differ in terms of accuracy, computational/memory complexity, training time, and adaptability among other characteristics. For example, neural networks (NNs) are well-known for their high accuracy due to the quality of their automatic feature extraction while brain-inspired hyperdimensional (HD) learning models are famous for their quick training, computational efficiency, and adaptability. This work presents a hybrid, synergic machine learning model that excels at all the said characteristics and is suitable for incremental, on-line learning on a chip. The proposed model comprises an NN and a classifier. The NN acts as a feature extractor and is specifically trained to work well with the classifier that employs the HD computing framework. This work also presents a parameterized hardware implementation of the said feature extraction and classification components while introducing a compiler that maps any arbitrary NN and/or classifier to the aforementioned hardware. The proposed hybrid machine learning model has the same level of accuracy (i.e. $\pm$1%) as NNs while achieving at least 10% improvement in accuracy compared to HD learning models. Additionally, the end-to-end hardware realization of the hybrid model improves power efficiency by 1.60x compared to state-of-the-art, high-performance HD learning implementations while improving latency by 2.13x. These results have profound implications for the application of such synergic models in challenging cognitive tasks.
Deep-PowerX: A Deep Learning-Based Framework for Low-Power Approximate Logic Synthesis
Jul 03, 2020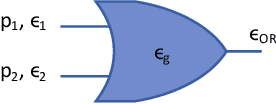
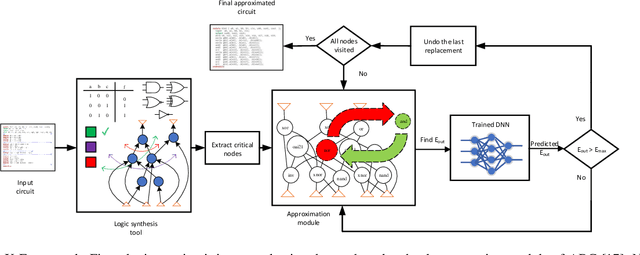
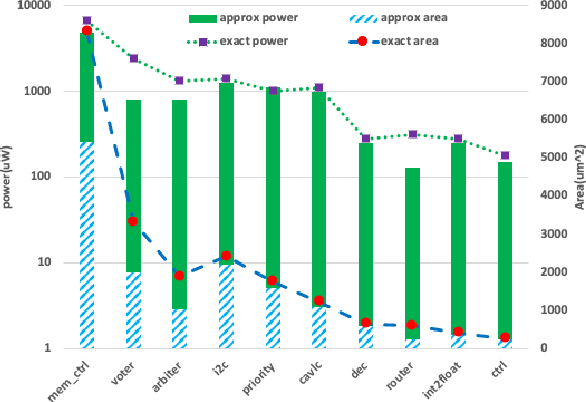
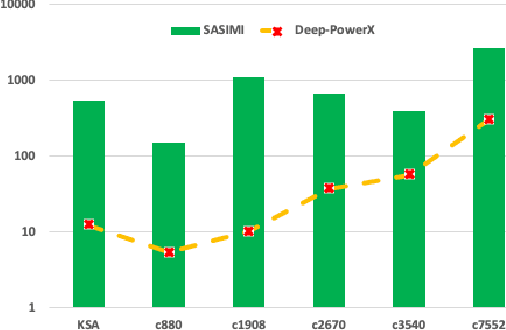
This paper aims at integrating three powerful techniques namely Deep Learning, Approximate Computing, and Low Power Design into a strategy to optimize logic at the synthesis level. We utilize advances in deep learning to guide an approximate logic synthesis engine to minimize the dynamic power consumption of a given digital CMOS circuit, subject to a predetermined error rate at the primary outputs. Our framework, Deep-PowerX, focuses on replacing or removing gates on a technology-mapped network and uses a Deep Neural Network (DNN) to predict error rates at primary outputs of the circuit when a specific part of the netlist is approximated. The primary goal of Deep-PowerX is to reduce the dynamic power whereas area reduction serves as a secondary objective. Using the said DNN, Deep-PowerX is able to reduce the exponential time complexity of standard approximate logic synthesis to linear time. Experiments are done on numerous open source benchmark circuits. Results show significant reduction in power and area by up to 1.47 times and 1.43 times compared to exact solutions and by up to 22% and 27% compared to state-of-the-art approximate logic synthesis tools while having orders of magnitudes lower run-time.
NN-PARS: A Parallelized Neural Network Based Circuit Simulation Framework
Feb 13, 2020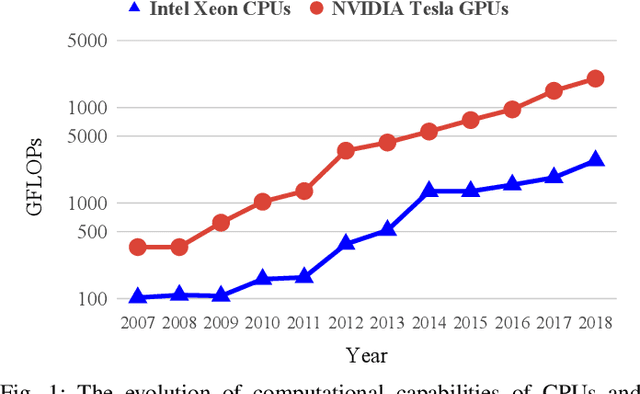
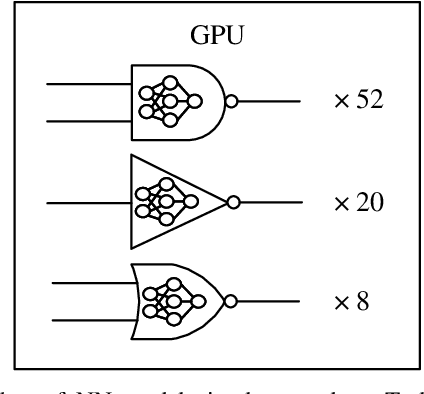
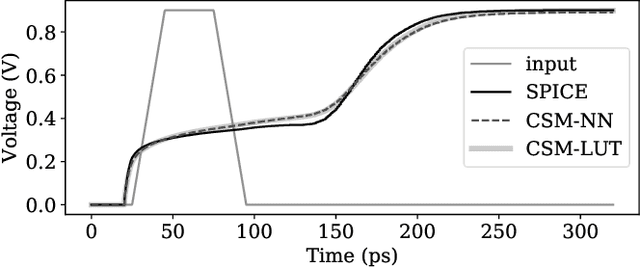
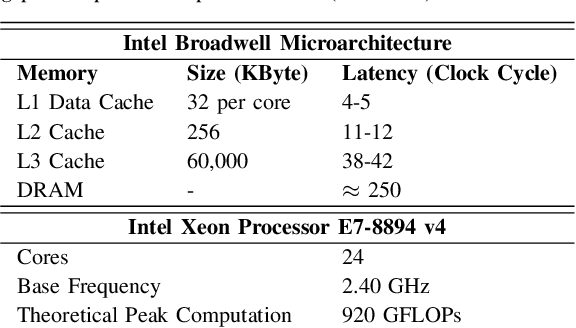
The shrinking of transistor geometries as well as the increasing complexity of integrated circuits, significantly aggravate nonlinear design behavior. This demands accurate and fast circuit simulation to meet the design quality and time-to-market constraints. The existing circuit simulators which utilize lookup tables and/or closed-form expressions are either slow or inaccurate in analyzing the nonlinear behavior of designs with billions of transistors. To address these shortcomings, we present NN-PARS, a neural network (NN) based and parallelized circuit simulation framework with optimized event-driven scheduling of simulation tasks to maximize concurrency, according to the underlying GPU parallel processing capabilities. NN-PARS replaces the required memory queries in traditional techniques with parallelized NN-based computation tasks. Experimental results show that compared to a state-of-the-art current-based simulation method, NN-PARS reduces the simulation time by over two orders of magnitude in large circuits. NN-PARS also provides high accuracy levels in signal waveform calculations, with less than $2\%$ error compared to HSPICE.
CSM-NN: Current Source Model Based Logic Circuit Simulation -- A Neural Network Approach
Feb 13, 2020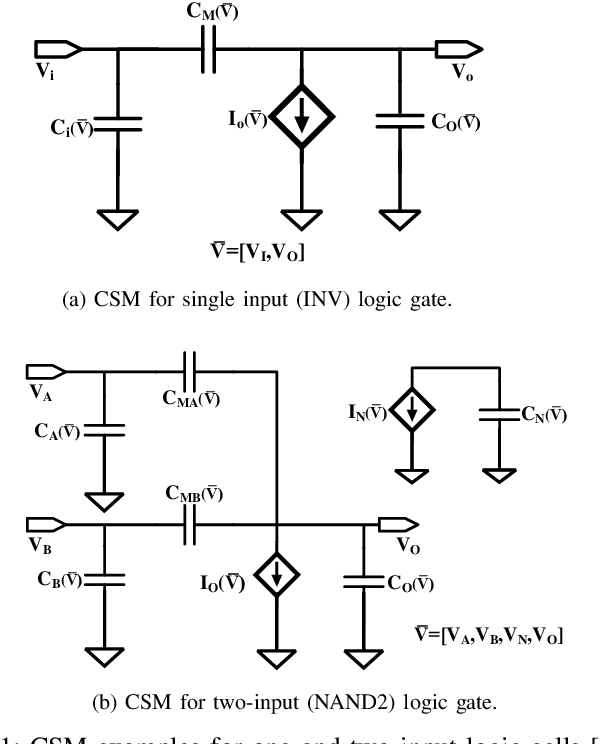
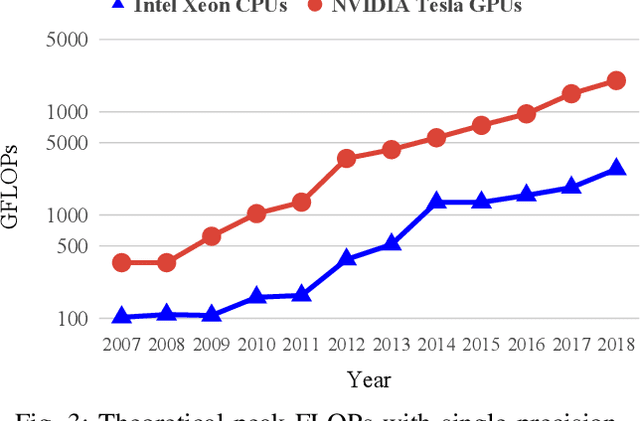
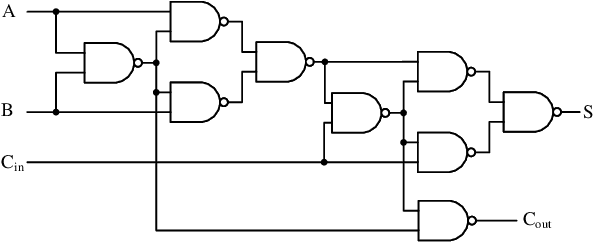
The miniaturization of transistors down to 5nm and beyond, plus the increasing complexity of integrated circuits, significantly aggravate short channel effects, and demand analysis and optimization of more design corners and modes. Simulators need to model output variables related to circuit timing, power, noise, etc., which exhibit nonlinear behavior. The existing simulation and sign-off tools, based on a combination of closed-form expressions and lookup tables are either inaccurate or slow, when dealing with circuits with more than billions of transistors. In this work, we present CSM-NN, a scalable simulation framework with optimized neural network structures and processing algorithms. CSM-NN is aimed at optimizing the simulation time by accounting for the latency of the required memory query and computation, given the underlying CPU and GPU parallel processing capabilities. Experimental results show that CSM-NN reduces the simulation time by up to $6\times$ compared to a state-of-the-art current source model based simulator running on a CPU. This speedup improves by up to $15\times$ when running on a GPU. CSM-NN also provides high accuracy levels, with less than $2\%$ error, compared to HSPICE.
Efficient Training of Deep Convolutional Neural Networks by Augmentation in Embedding Space
Feb 12, 2020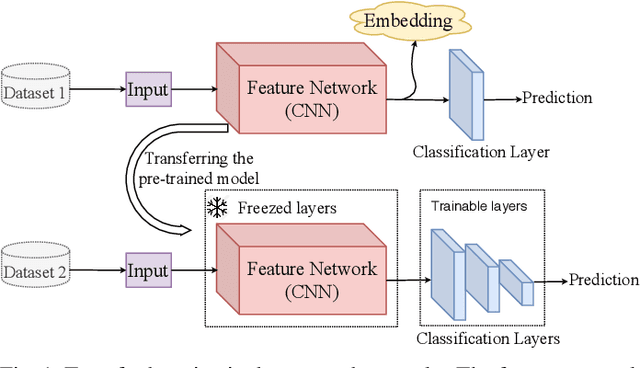
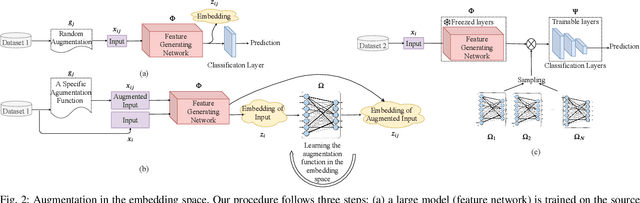
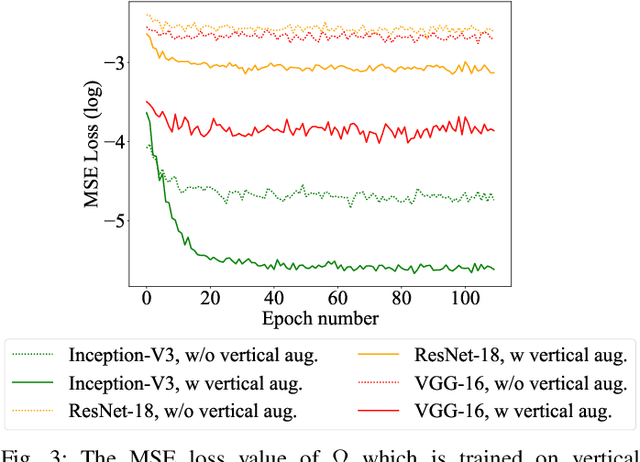
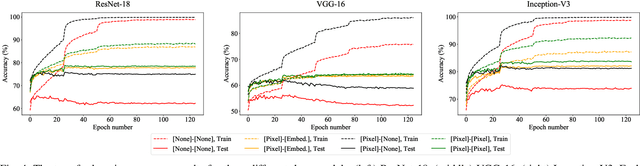
Recent advances in the field of artificial intelligence have been made possible by deep neural networks. In applications where data are scarce, transfer learning and data augmentation techniques are commonly used to improve the generalization of deep learning models. However, fine-tuning a transfer model with data augmentation in the raw input space has a high computational cost to run the full network for every augmented input. This is particularly critical when large models are implemented on embedded devices with limited computational and energy resources. In this work, we propose a method that replaces the augmentation in the raw input space with an approximate one that acts purely in the embedding space. Our experimental results show that the proposed method drastically reduces the computation, while the accuracy of models is negligibly compromised.
Pre-defined Sparsity for Low-Complexity Convolutional Neural Networks
Feb 04, 2020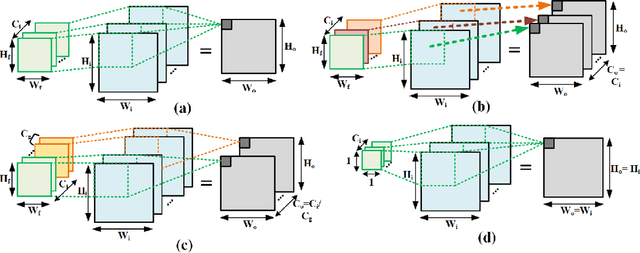

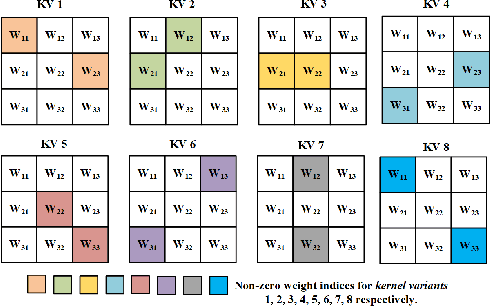
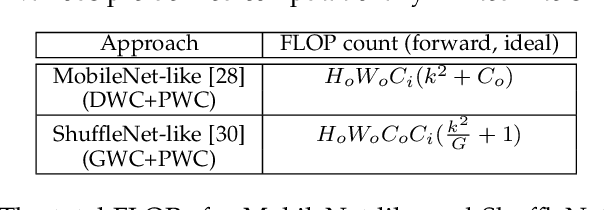
The high energy cost of processing deep convolutional neural networks impedes their ubiquitous deployment in energy-constrained platforms such as embedded systems and IoT devices. This work introduces convolutional layers with pre-defined sparse 2D kernels that have support sets that repeat periodically within and across filters. Due to the efficient storage of our periodic sparse kernels, the parameter savings can translate into considerable improvements in energy efficiency due to reduced DRAM accesses, thus promising significant improvements in the trade-off between energy consumption and accuracy for both training and inference. To evaluate this approach, we performed experiments with two widely accepted datasets, CIFAR-10 and Tiny ImageNet in sparse variants of the ResNet18 and VGG16 architectures. Compared to baseline models, our proposed sparse variants require up to 82% fewer model parameters with 5.6times fewer FLOPs with negligible loss in accuracy for ResNet18 on CIFAR-10. For VGG16 trained on Tiny ImageNet, our approach requires 5.8times fewer FLOPs and up to 83.3% fewer model parameters with a drop in top-5 (top-1) accuracy of only 1.2% (2.1%). We also compared the performance of our proposed architectures with that of ShuffleNet andMobileNetV2. Using similar hyperparameters and FLOPs, our ResNet18 variants yield an average accuracy improvement of 2.8%.
Run-time Deep Model Multiplexing
Jan 14, 2020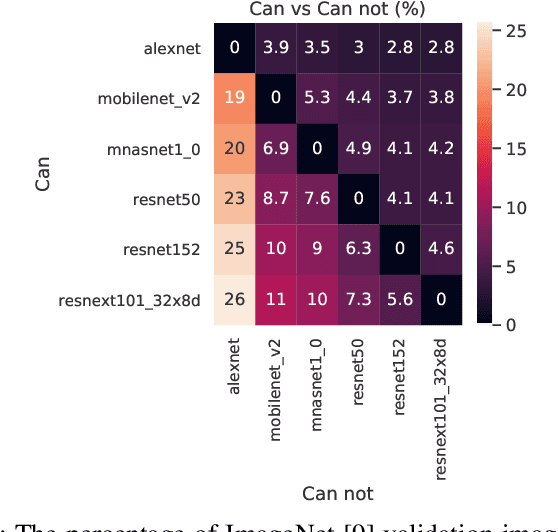
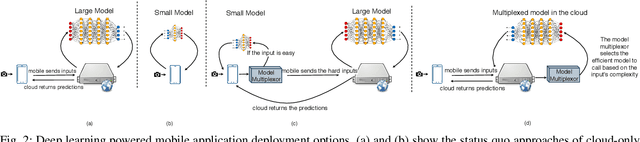
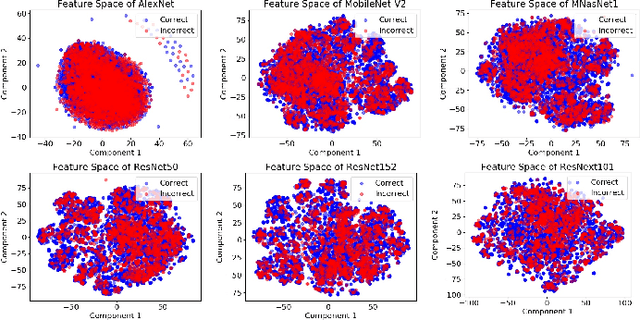
We propose a framework to design a light-weight neural multiplexer that given input and resource budgets, decides upon the appropriate model to be called for the inference. Mobile devices can use this framework to offload the hard inputs to the cloud while inferring the easy ones locally. Besides, in the large scale cloud-based intelligent applications, instead of replicating the most-accurate model, a range of small and large models can be multiplexed from depending on the input's complexity and resource budgets. Our experimental results demonstrate the effectiveness of our framework benefiting both mobile users and cloud providers.
Energy-aware Scheduling of Jobs in Heterogeneous Cluster Systems Using Deep Reinforcement Learning
Dec 11, 2019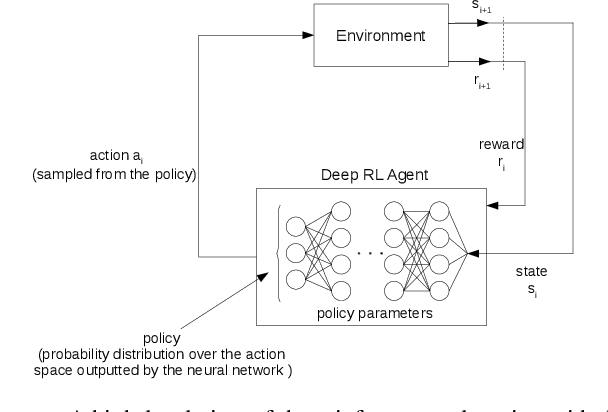

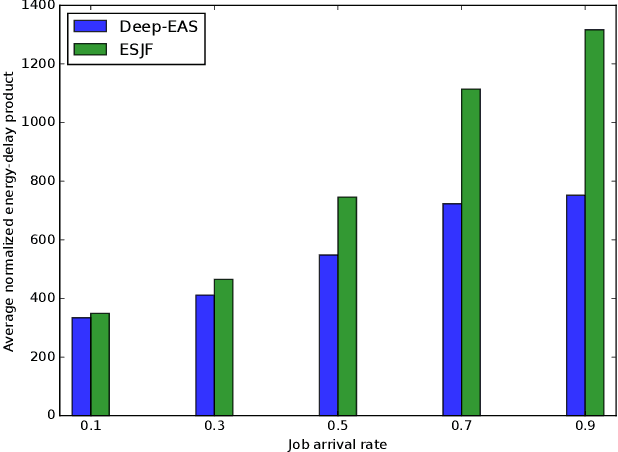
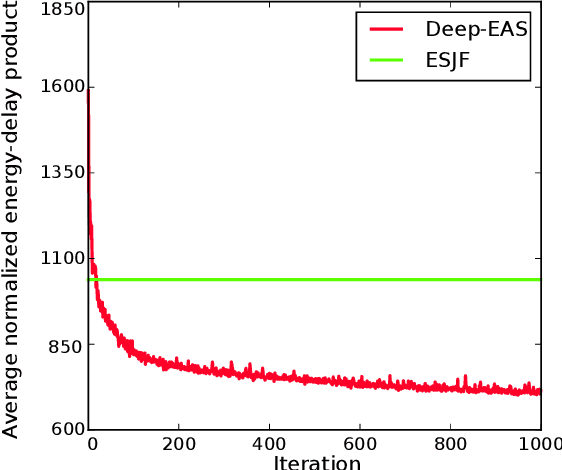
Energy consumption is one of the most critical concerns in designing computing devices, ranging from portable embedded systems to computer cluster systems. Furthermore, in the past decade, cluster systems have increasingly risen as popular platforms to run computing-intensive real-time applications in which the performance is of great importance. However, due to different characteristics of real-time workloads, developing general job scheduling solutions that efficiently address both energy consumption and performance in real-time cluster systems is a challenging problem. In this paper, inspired by recent advances in applying deep reinforcement learning for resource management problems, we present the Deep-EAS scheduler that learns efficient energy-aware scheduling strategies for workloads with different characteristics without initially knowing anything about the scheduling task at hand. Results show that Deep-EAS converges quickly, and performs better compared to standard manually-tuned heuristics, especially in heavy load conditions.
Coarse2Fine: A Two-stage Training Method for Fine-grained Visual Classification
Sep 06, 2019

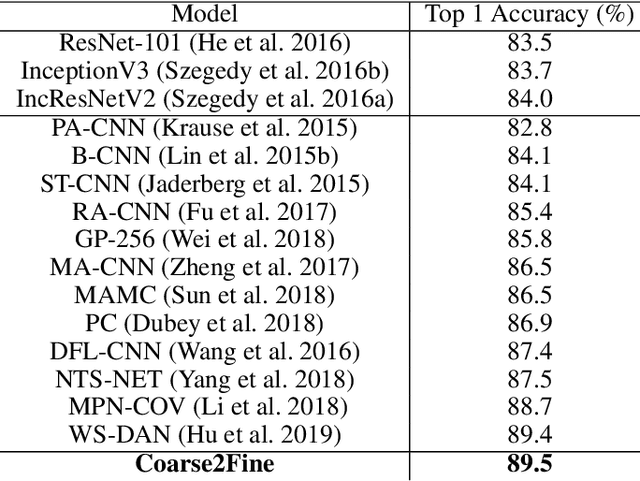
Small inter-class and large intra-class variations are the main challenges in fine-grained visual classification. Objects from different classes share visually similar structures and objects in the same class can have different poses and viewpoints. Therefore, the proper extraction of discriminative local features (e.g. bird's beak or car's headlight) is crucial. Most of the recent successes on this problem are based upon the attention models which can localize and attend the local discriminative objects parts. In this work, we propose a training method for visual attention networks, Coarse2Fine, which creates a differentiable path from the input space to the attended feature maps. Coarse2Fine learns an inverse mapping function from the attended feature maps to the informative regions in the raw image, which will guide the attention maps to better attend the fine-grained features. We show Coarse2Fine and orthogonal initialization of the attention weights can surpass the state-of-the-art accuracies on common fine-grained classification tasks.
Optimizing Routerless Network-on-Chip Designs: An Innovative Learning-Based Framework
May 11, 2019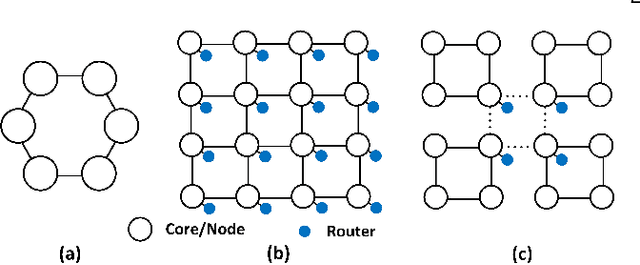
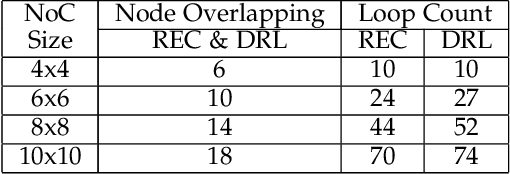
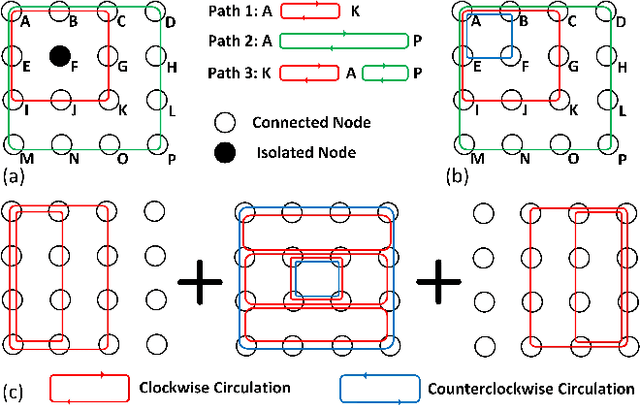
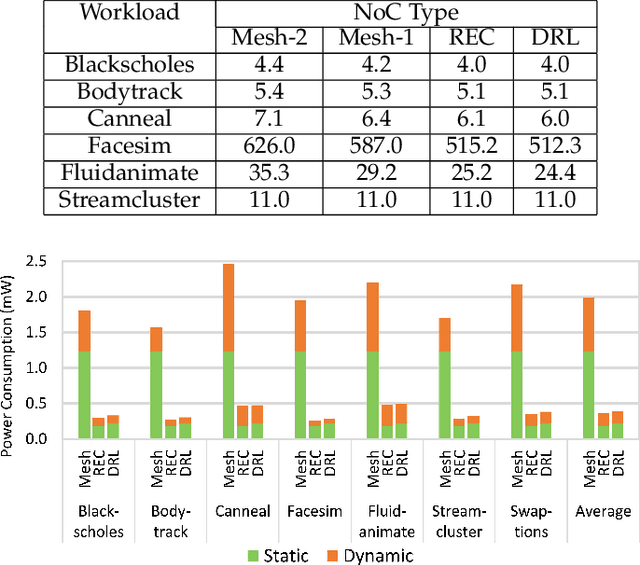
Machine learning applied to architecture design presents a promising opportunity with broad applications. Recent deep reinforcement learning (DRL) techniques, in particular, enable efficient exploration in vast design spaces where conventional design strategies may be inadequate. This paper proposes a novel deep reinforcement framework, taking routerless networks-on-chip (NoC) as an evaluation case study. The new framework successfully resolves problems with prior design approaches being either unreliable due to random searches or inflexible due to severe design space restrictions. The framework learns (near-)optimal loop placement for routerless NoCs with various design constraints. A deep neural network is developed using parallel threads that efficiently explore the immense routerless NoC design space with a Monte Carlo search tree. Experimental results show that, compared with conventional mesh, the proposed deep reinforcement learning (DRL) routerless design achieves a 3.25x increase in throughput, 1.6x reduction in packet latency, and 5x reduction in power. Compared with the state-of-the-art routerless NoC, DRL achieves a 1.47x increase in throughput, 1.18x reduction in packet latency, and 1.14x reduction in average hop count albeit with slightly more power overhead.