 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePositive-Unlabeled Learning with Non-Negative Risk Estimator
Nov 04, 2017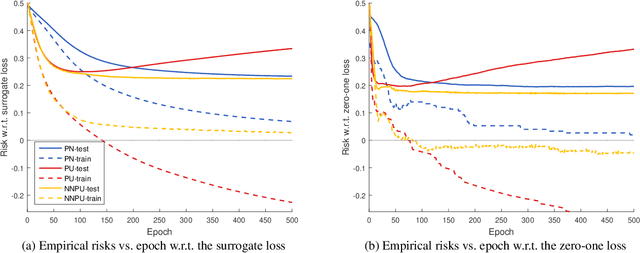

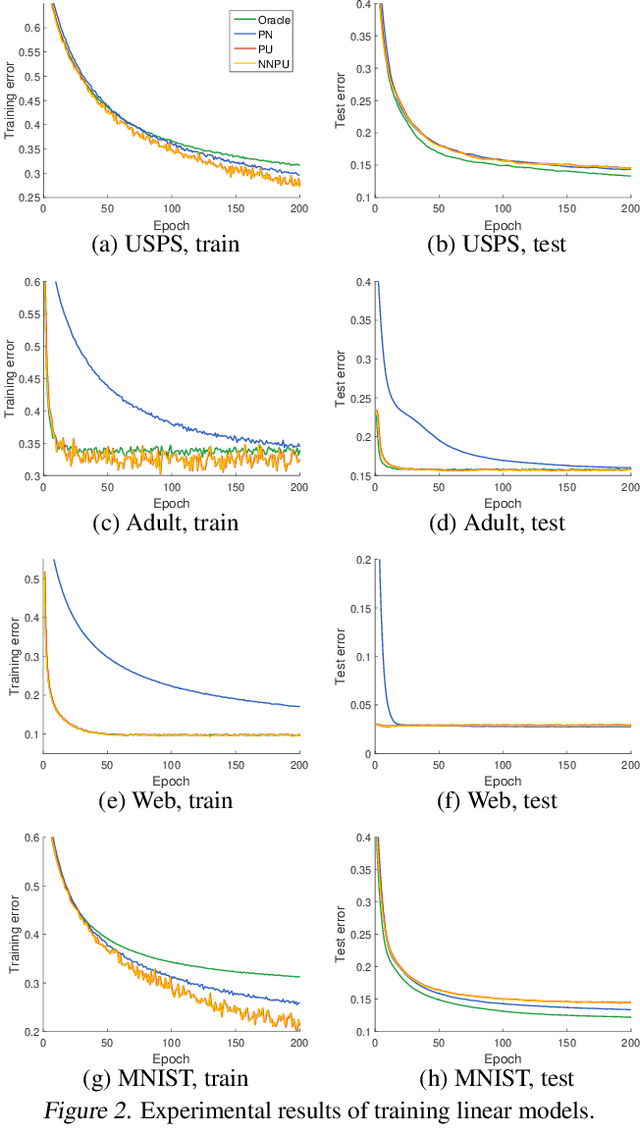
From only positive (P) and unlabeled (U) data, a binary classifier could be trained with PU learning, in which the state of the art is unbiased PU learning. However, if its model is very flexible, empirical risks on training data will go negative, and we will suffer from serious overfitting. In this paper, we propose a non-negative risk estimator for PU learning: when getting minimized, it is more robust against overfitting, and thus we are able to use very flexible models (such as deep neural networks) given limited P data. Moreover, we analyze the bias, consistency, and mean-squared-error reduction of the proposed risk estimator, and bound the estimation error of the resulting empirical risk minimizer. Experiments demonstrate that our risk estimator fixes the overfitting problem of its unbiased counterparts.
Semi-Supervised AUC Optimization based on Positive-Unlabeled Learning
Oct 16, 2017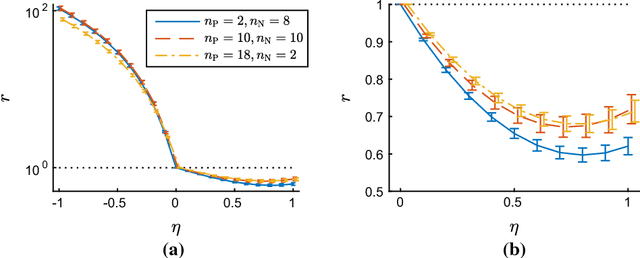
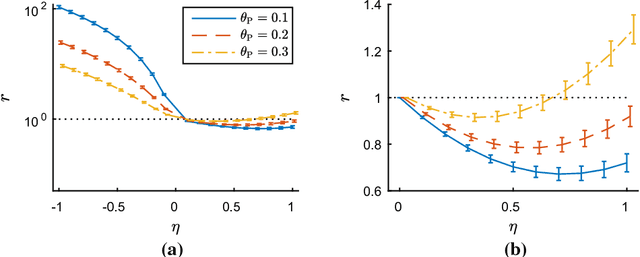
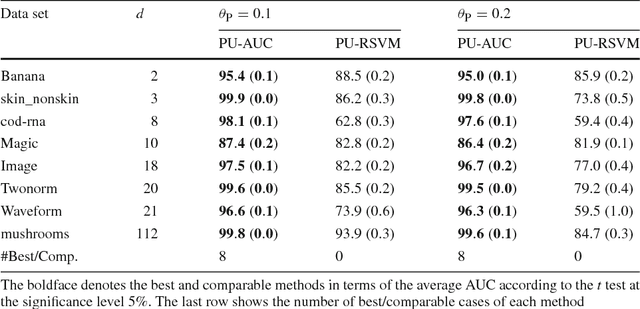
Maximizing the area under the receiver operating characteristic curve (AUC) is a standard approach to imbalanced classification. So far, various supervised AUC optimization methods have been developed and they are also extended to semi-supervised scenarios to cope with small sample problems. However, existing semi-supervised AUC optimization methods rely on strong distributional assumptions, which are rarely satisfied in real-world problems. In this paper, we propose a novel semi-supervised AUC optimization method that does not require such restrictive assumptions. We first develop an AUC optimization method based only on positive and unlabeled data (PU-AUC) and then extend it to semi-supervised learning by combining it with a supervised AUC optimization method. We theoretically prove that, without the restrictive distributional assumptions, unlabeled data contribute to improving the generalization performance in PU and semi-supervised AUC optimization methods. Finally, we demonstrate the practical usefulness of the proposed methods through experiments.
Fully adaptive algorithm for pure exploration in linear bandits
Oct 16, 2017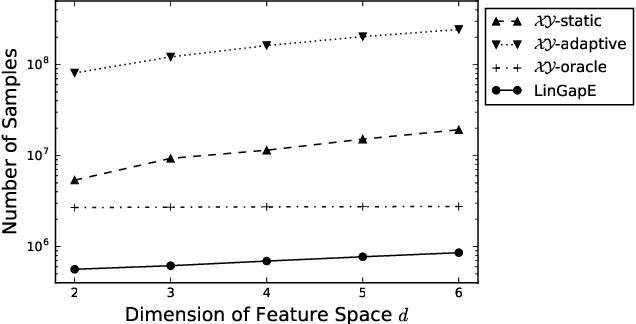
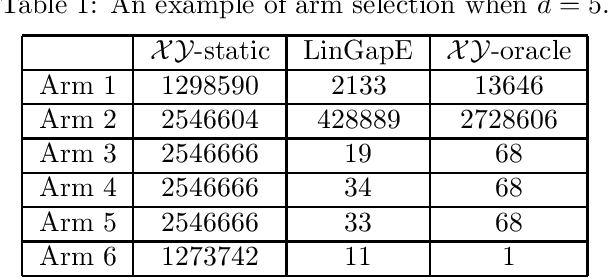
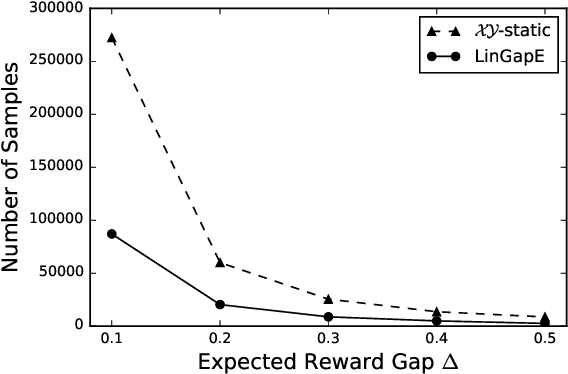
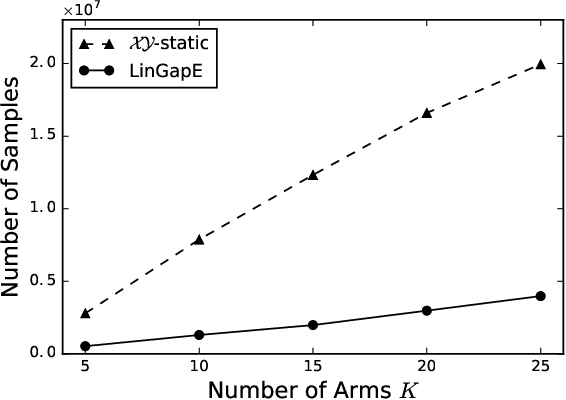
We propose the first fully-adaptive algorithm for pure exploration in linear bandits---the task to find the arm with the largest expected reward, which depends on an unknown parameter linearly. While existing methods partially or entirely fix sequences of arm selections before observing rewards, our method adaptively changes the arm selection strategy based on past observations at each round. We show our sample complexity matches the achievable lower bound up to a constant factor in an extreme case. Furthermore, we evaluate the performance of the methods by simulations based on both synthetic setting and real-world data, in which our method shows vast improvement over existing methods.
Semi-Supervised Classification Based on Classification from Positive and Unlabeled Data
Jun 16, 2017
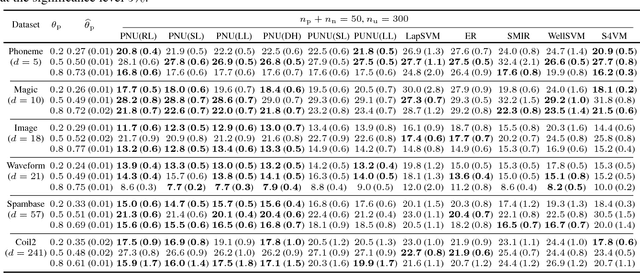
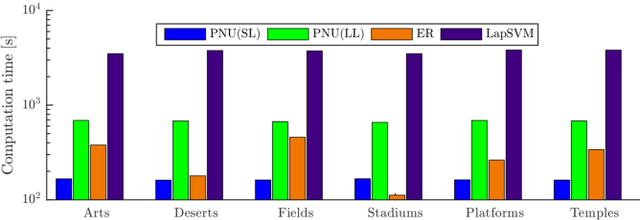
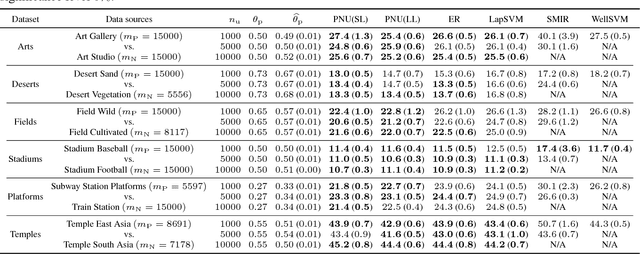
Most of the semi-supervised classification methods developed so far use unlabeled data for regularization purposes under particular distributional assumptions such as the cluster assumption. In contrast, recently developed methods of classification from positive and unlabeled data (PU classification) use unlabeled data for risk evaluation, i.e., label information is directly extracted from unlabeled data. In this paper, we extend PU classification to also incorporate negative data and propose a novel semi-supervised classification approach. We establish generalization error bounds for our novel methods and show that the bounds decrease with respect to the number of unlabeled data without the distributional assumptions that are required in existing semi-supervised classification methods. Through experiments, we demonstrate the usefulness of the proposed methods.
Learning Discrete Representations via Information Maximizing Self-Augmented Training
Jun 14, 2017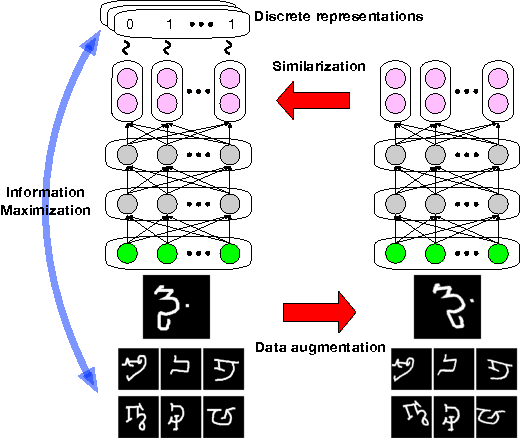
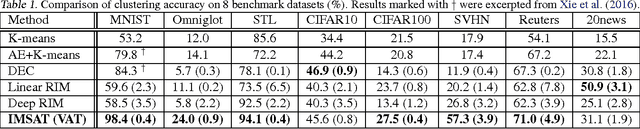


Learning discrete representations of data is a central machine learning task because of the compactness of the representations and ease of interpretation. The task includes clustering and hash learning as special cases. Deep neural networks are promising to be used because they can model the non-linearity of data and scale to large datasets. However, their model complexity is huge, and therefore, we need to carefully regularize the networks in order to learn useful representations that exhibit intended invariance for applications of interest. To this end, we propose a method called Information Maximizing Self-Augmented Training (IMSAT). In IMSAT, we use data augmentation to impose the invariance on discrete representations. More specifically, we encourage the predicted representations of augmented data points to be close to those of the original data points in an end-to-end fashion. At the same time, we maximize the information-theoretic dependency between data and their predicted discrete representations. Extensive experiments on benchmark datasets show that IMSAT produces state-of-the-art results for both clustering and unsupervised hash learning.
Expectation Propagation for t-Exponential Family Using Q-Algebra
May 28, 2017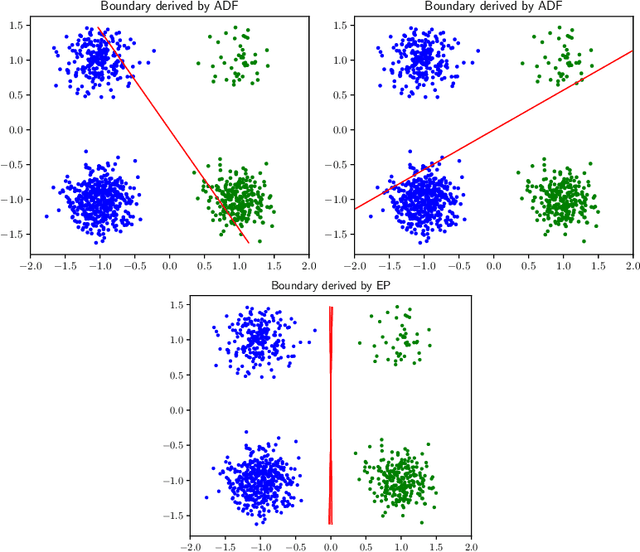
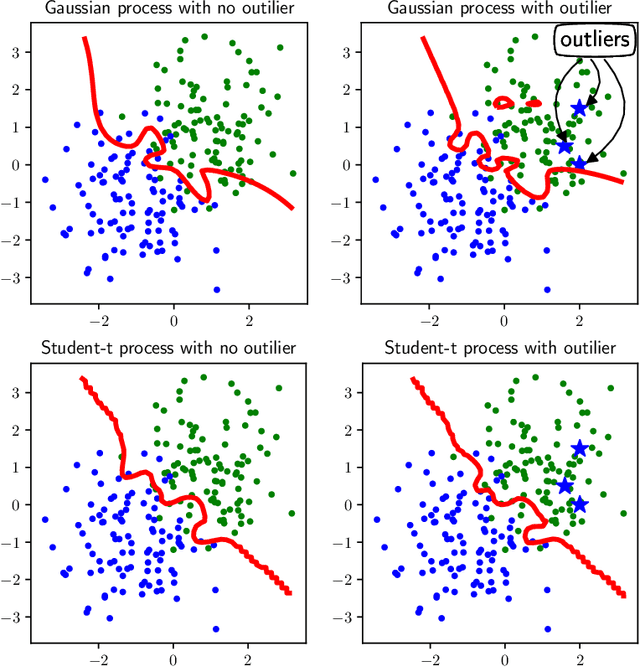
Exponential family distributions are highly useful in machine learning since their calculation can be performed efficiently through natural parameters. The exponential family has recently been extended to the t-exponential family, which contains Student-t distributions as family members and thus allows us to handle noisy data well. However, since the t-exponential family is denied by the deformed exponential, we cannot derive an efficient learning algorithm for the t-exponential family such as expectation propagation (EP). In this paper, we borrow the mathematical tools of q-algebra from statistical physics and show that the pseudo additivity of distributions allows us to perform calculation of t-exponential family distributions through natural parameters. We then develop an expectation propagation (EP) algorithm for the t-exponential family, which provides a deterministic approximation to the posterior or predictive distribution with simple moment matching. We finally apply the proposed EP algorithm to the Bayes point machine and Student-t process classication, and demonstrate their performance numerically.
Whitening-Free Least-Squares Non-Gaussian Component Analysis
May 24, 2017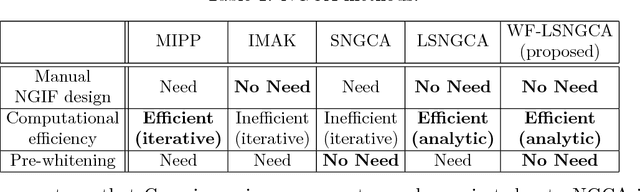

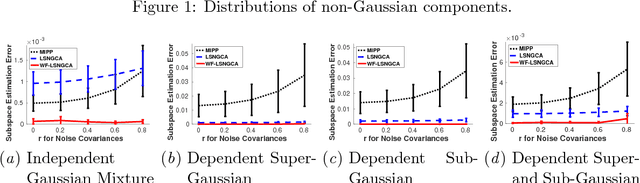
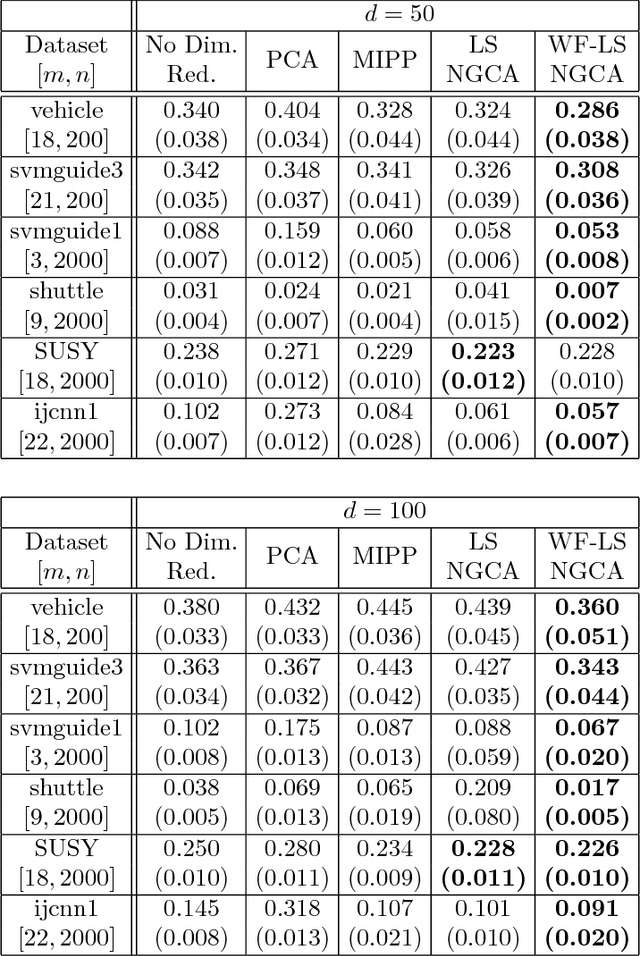
Non-Gaussian component analysis (NGCA) is an unsupervised linear dimension reduction method that extracts low-dimensional non-Gaussian "signals" from high-dimensional data contaminated with Gaussian noise. NGCA can be regarded as a generalization of projection pursuit (PP) and independent component analysis (ICA) to multi-dimensional and dependent non-Gaussian components. Indeed, seminal approaches to NGCA are based on PP and ICA. Recently, a novel NGCA approach called least-squares NGCA (LSNGCA) has been developed, which gives a solution analytically through least-squares estimation of log-density gradients and eigendecomposition. However, since pre-whitening of data is involved in LSNGCA, it performs unreliably when the data covariance matrix is ill-conditioned, which is often the case in high-dimensional data analysis. In this paper, we propose a whitening-free LSNGCA method and experimentally demonstrate its superiority.
Misdirected Registration Uncertainty
May 17, 2017
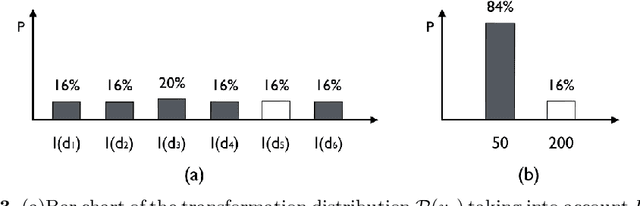
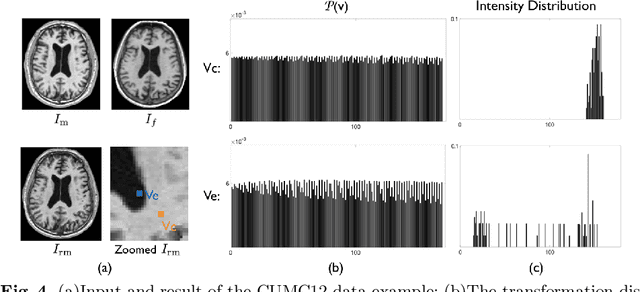
Being a task of establishing spatial correspondences, medical image registration is often formalized as finding the optimal transformation that best aligns two images. Since the transformation is such an essential component of registration, most existing researches conventionally quantify the registration uncertainty, which is the confidence in the estimated spatial correspondences, by the transformation uncertainty. In this paper, we give concrete examples and reveal that using the transformation uncertainty to quantify the registration uncertainty is inappropriate and sometimes misleading. Based on this finding, we also raise attention to an important yet subtle aspect of probabilistic image registration, that is whether it is reasonable to determine the correspondence of a registered voxel solely by the mode of its transformation distribution.
Stochastic Divergence Minimization for Biterm Topic Model
May 01, 2017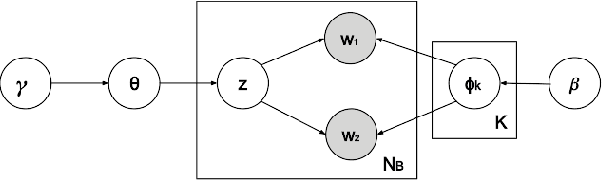
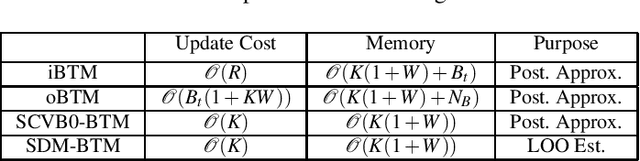
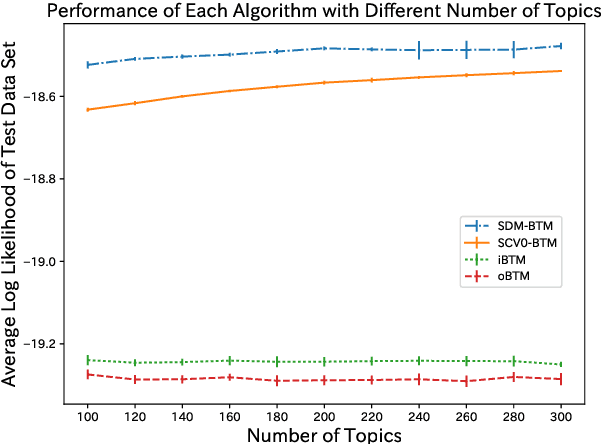
As the emergence and the thriving development of social networks, a huge number of short texts are accumulated and need to be processed. Inferring latent topics of collected short texts is useful for understanding its hidden structure and predicting new contents. Unlike conventional topic models such as latent Dirichlet allocation (LDA), a biterm topic model (BTM) was recently proposed for short texts to overcome the sparseness of document-level word co-occurrences by directly modeling the generation process of word pairs. Stochastic inference algorithms based on collapsed Gibbs sampling (CGS) and collapsed variational inference have been proposed for BTM. However, they either require large computational complexity, or rely on very crude estimation. In this work, we develop a stochastic divergence minimization inference algorithm for BTM to estimate latent topics more accurately in a scalable way. Experiments demonstrate the superiority of our proposed algorithm compared with existing inference algorithms.
Policy Search with High-Dimensional Context Variables
Nov 10, 2016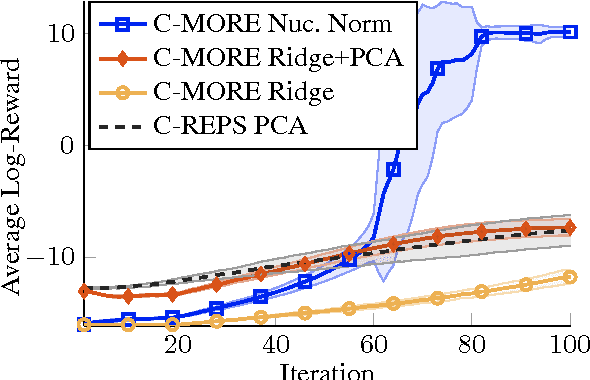
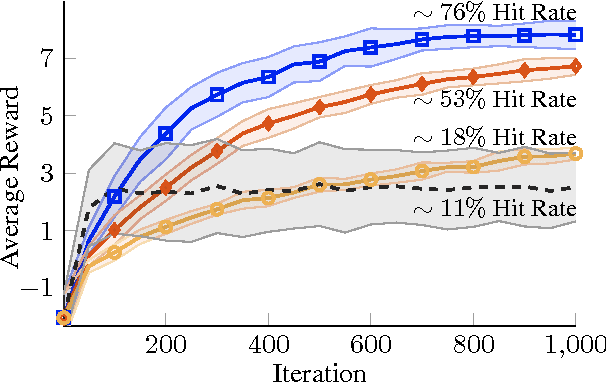
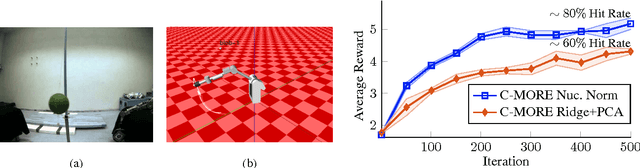
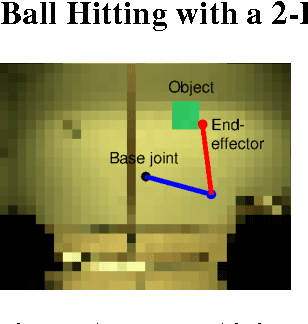
Direct contextual policy search methods learn to improve policy parameters and simultaneously generalize these parameters to different context or task variables. However, learning from high-dimensional context variables, such as camera images, is still a prominent problem in many real-world tasks. A naive application of unsupervised dimensionality reduction methods to the context variables, such as principal component analysis, is insufficient as task-relevant input may be ignored. In this paper, we propose a contextual policy search method in the model-based relative entropy stochastic search framework with integrated dimensionality reduction. We learn a model of the reward that is locally quadratic in both the policy parameters and the context variables. Furthermore, we perform supervised linear dimensionality reduction on the context variables by nuclear norm regularization. The experimental results show that the proposed method outperforms naive dimensionality reduction via principal component analysis and a state-of-the-art contextual policy search method.