 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Inference for Gaussian Process with Panel Count Data
Mar 12, 2018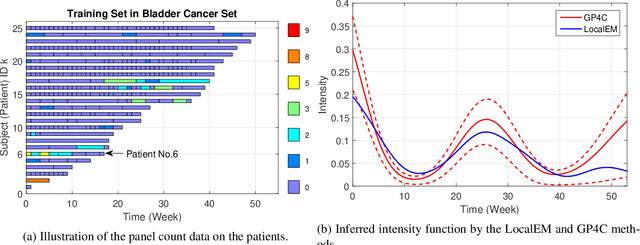
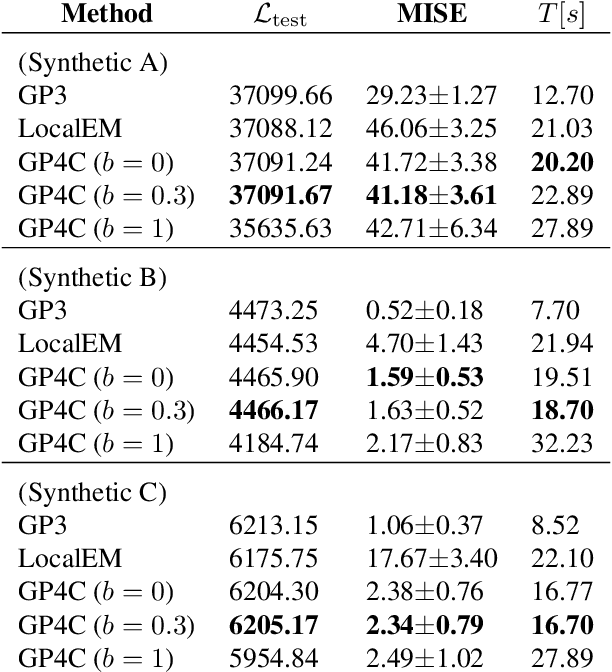
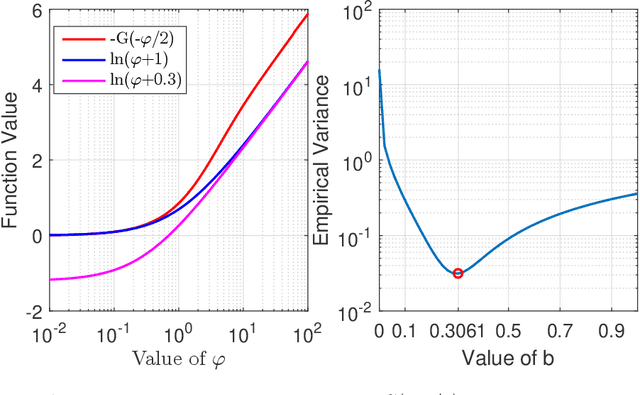
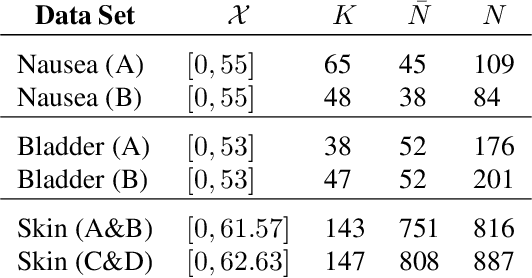
We present the first framework for Gaussian-process-modulated Poisson processes when the temporal data appear in the form of panel counts. Panel count data frequently arise when experimental subjects are observed only at discrete time points and only the numbers of occurrences of the events between subsequent observation times are available. The exact occurrence timestamps of the events are unknown. The method of conducting the efficient variational inference is presented, based on the assumption of a Gaussian-process-modulated intensity function. We derive a tractable lower bound to alleviate the problems of the intractable evidence lower bound inherent in the variational inference framework. Our algorithm outperforms classical methods on both synthetic and three real panel count sets.
Variational Inference based on Robust Divergences
Feb 28, 2018
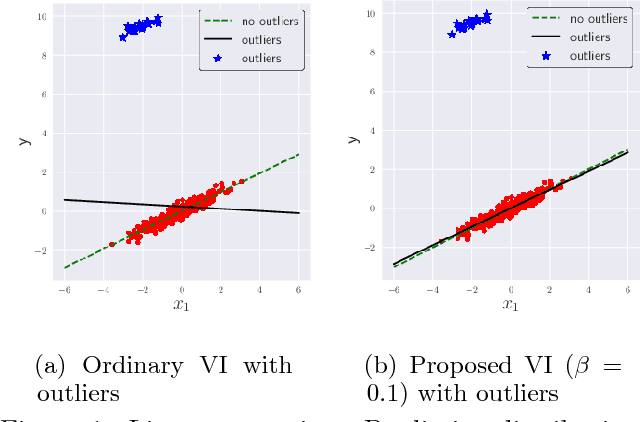

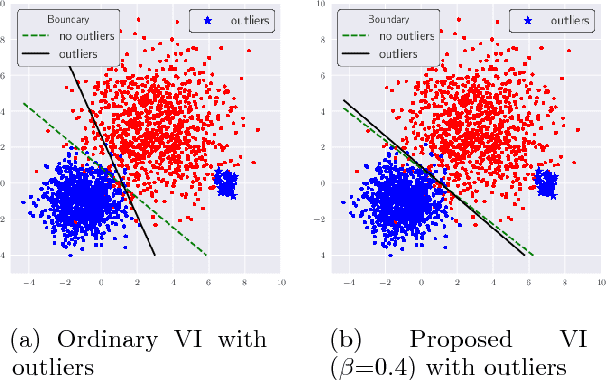
Robustness to outliers is a central issue in real-world machine learning applications. While replacing a model to a heavy-tailed one (e.g., from Gaussian to Student-t) is a standard approach for robustification, it can only be applied to simple models. In this paper, based on Zellner's optimization and variational formulation of Bayesian inference, we propose an outlier-robust pseudo-Bayesian variational method by replacing the Kullback-Leibler divergence used for data fitting to a robust divergence such as the beta- and gamma-divergences. An advantage of our approach is that superior but complex models such as deep networks can also be handled. We theoretically prove that, for deep networks with ReLU activation functions, the \emph{influence function} in our proposed method is bounded, while it is unbounded in the ordinary variational inference. This implies that our proposed method is robust to both of input and output outliers, while the ordinary variational method is not. We experimentally demonstrate that our robust variational method outperforms ordinary variational inference in regression and classification with deep networks.
Guide Actor-Critic for Continuous Control
Feb 22, 2018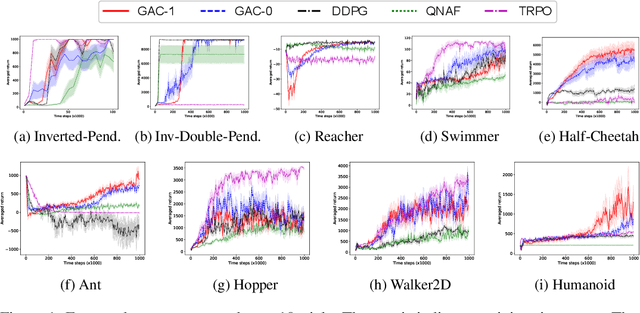
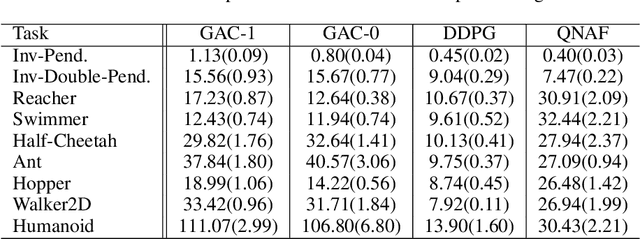
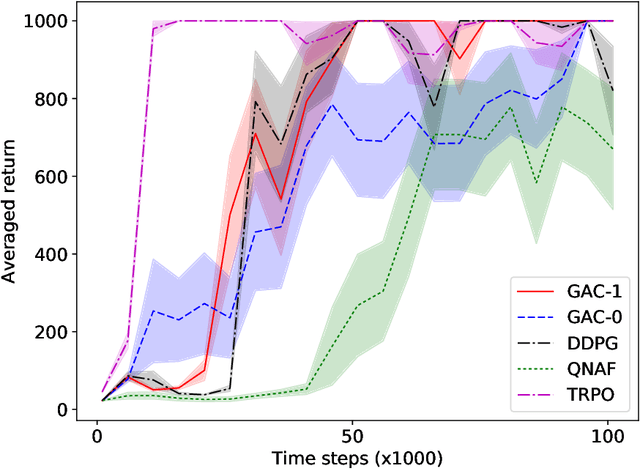
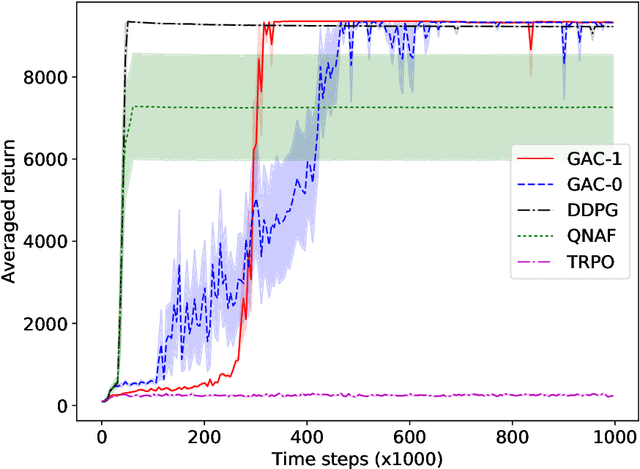
Actor-critic methods solve reinforcement learning problems by updating a parameterized policy known as an actor in a direction that increases an estimate of the expected return known as a critic. However, existing actor-critic methods only use values or gradients of the critic to update the policy parameter. In this paper, we propose a novel actor-critic method called the guide actor-critic (GAC). GAC firstly learns a guide actor that locally maximizes the critic and then it updates the policy parameter based on the guide actor by supervised learning. Our main theoretical contributions are two folds. First, we show that GAC updates the guide actor by performing second-order optimization in the action space where the curvature matrix is based on the Hessians of the critic. Second, we show that the deterministic policy gradient method is a special case of GAC when the Hessians are ignored. Through experiments, we show that our method is a promising reinforcement learning method for continuous controls.
Information-Theoretic Representation Learning for Positive-Unlabeled Classification
Feb 12, 2018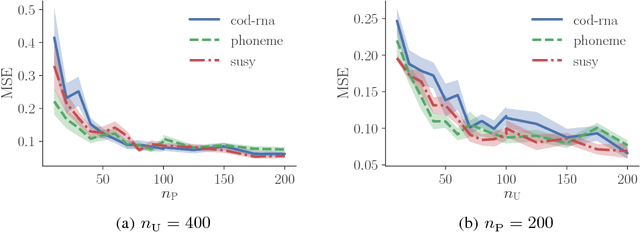
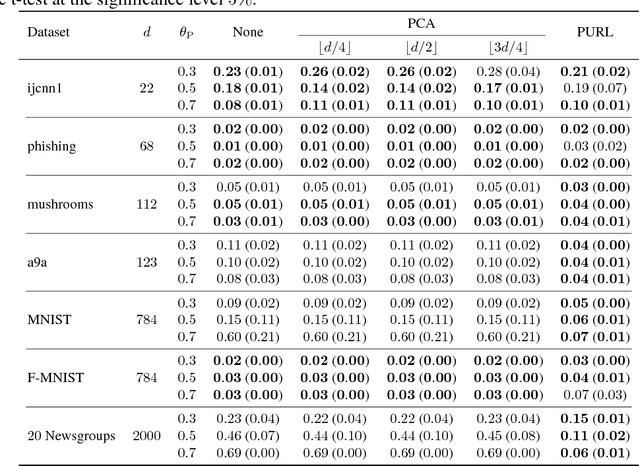
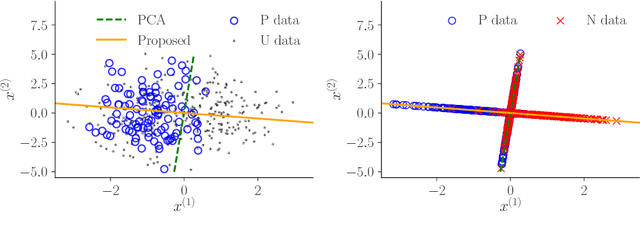
Recent advances in weakly supervised classification allow us to train a classifier only from positive and unlabeled (PU) data. However, existing PU classification methods typically require an accurate estimate of the class-prior probability, which is a critical bottleneck particularly for high-dimensional data. This problem has been commonly addressed by applying principal component analysis in advance, but such unsupervised dimension reduction can collapse underlying class structure. In this paper, we propose a novel representation learning method from PU data based on the information-maximization principle. Our method does not require class-prior estimation and thus can be used as a preprocessing method for PU classification. Through experiments, we demonstrate that our method combined with deep neural networks highly improves the accuracy of PU class-prior estimation, leading to state-of-the-art PU classification performance.
Gaussian Process Classification with Privileged Information by Soft-to-Hard Labeling Transfer
Feb 12, 2018
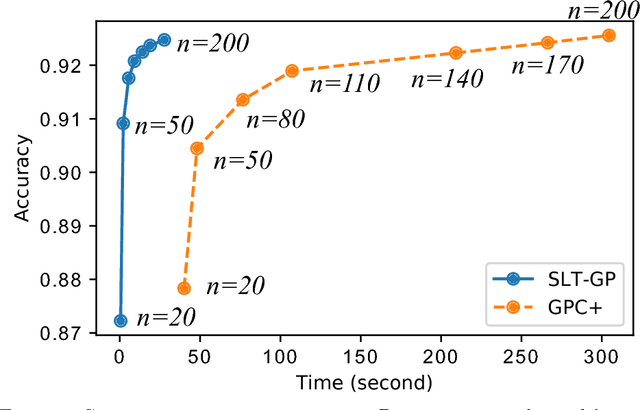
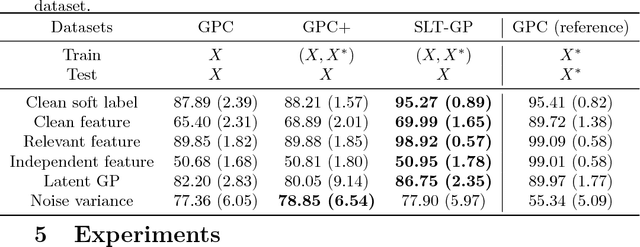
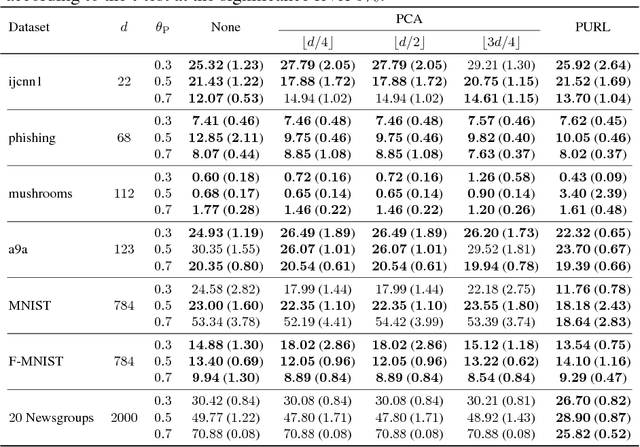
Learning using privileged information is an attractive problem setting that helps many learning scenarios in the real world. A state-of-the-art method of Gaussian process classification (GPC) with privileged information is GPC+, which incorporates privileged information into a noise term of the likelihood. A drawback of GPC+ is that it requires numerical quadrature to calculate the posterior distribution of the latent function, which is extremely time-consuming. To overcome this limitation, we propose a novel classification method with privileged information based on Gaussian processes, called "soft-label-transferred Gaussian process (SLT-GP)." Our basic idea is that we construct another learning task of predicting soft labels (continuous values) obtained from privileged information and we perform transfer learning from this task to the target task of predicting hard labels. We derive a PAC-Bayesian bound of our proposed method, which justifies optimizing hyperparameters by the empirical Bayes method. We also experimentally show the usefulness of our proposed method compared with GPC and GPC+.
Binary Classification from Positive-Confidence Data
Feb 11, 2018
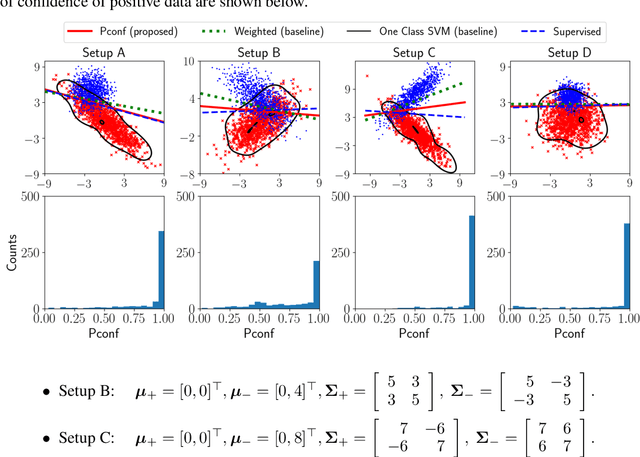
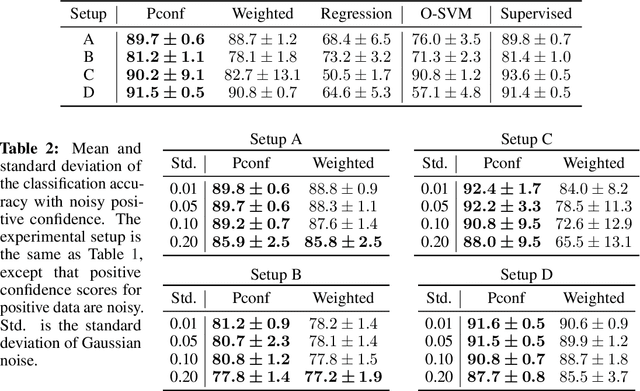
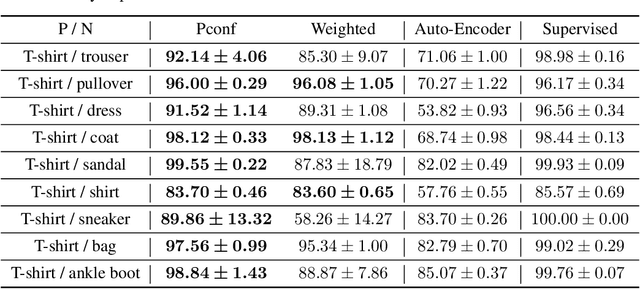
Reducing labeling costs in supervised learning is a critical issue in many practical machine learning applications. In this paper, we consider positive-confidence (Pconf) classification, the problem of training a binary classifier only from positive data equipped with confidence. Pconf classification can be regarded as a discriminative extension of one-class classification (which is aimed at "describing" the positive class by clustering-related methods), with ability to tune hyper-parameters for "classifying" positive and negative samples. Pconf classification is also related to positive-unlabeled (PU) classification (which uses hard-labeled positive data and unlabeled data), but the difference is that it enables us to avoid estimating the class priors, which is a critical bottleneck in typical PU classification methods. For the Pconf classification problem, we provide a simple empirical risk minimization framework and give a formulation for linear-in-parameter models that can be implemented easily and computationally efficiently. We also theoretically establish the consistency and estimation error bound for Pconf classification, and demonstrate the practical usefulness of the proposed method for deep neural networks through experiments.
Good Arm Identification via Bandit Feedback
Feb 10, 2018
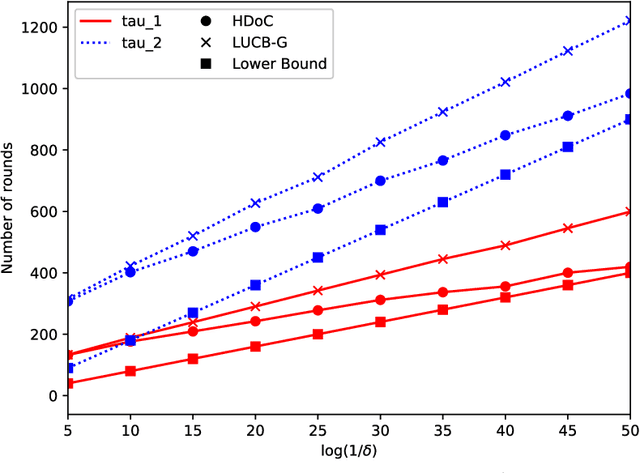
We consider a novel stochastic multi-armed bandit problem called {\em good arm identification} (GAI), where a good arm is defined as an arm with expected reward greater than or equal to a given threshold. GAI is a pure-exploration problem that a single agent repeats a process of outputting an arm as soon as it is identified as a good one before confirming the other arms are actually not good. The objective of GAI is to minimize the number of samples for each process. We find that GAI faces a new kind of dilemma, the {\em exploration-exploitation dilemma of confidence}, which is different difficulty from the best arm identification. As a result, an efficient design of algorithms for GAI is quite different from that for the best arm identification. We derive a lower bound on the sample complexity of GAI that is tight up to the logarithmic factor $\mathrm{O}(\log \frac{1}{\delta})$ for acceptance error rate $\delta$. We also develop an algorithm whose sample complexity almost matches the lower bound. We also confirm experimentally that our proposed algorithm outperforms naive algorithms in synthetic settings based on a conventional bandit problem and clinical trial researches for rheumatoid arthritis.
Support vector comparison machines
Dec 20, 2017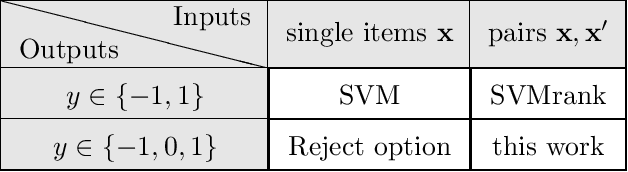
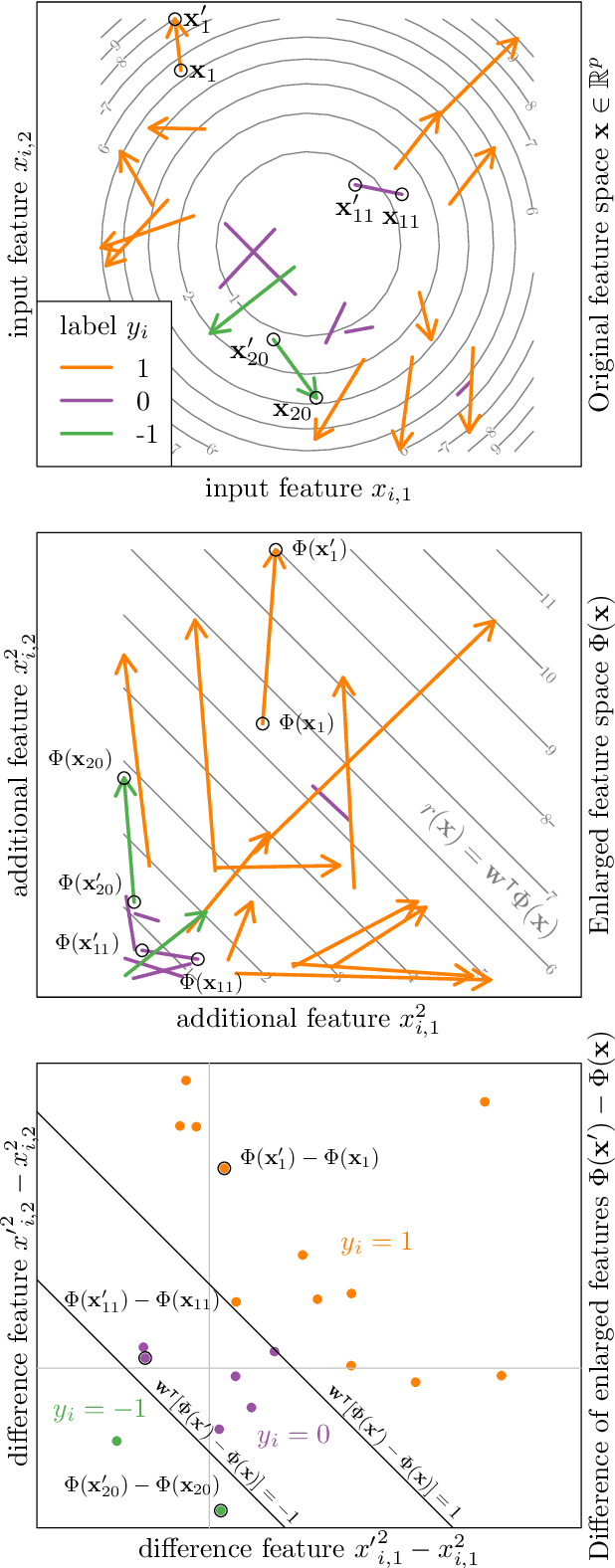
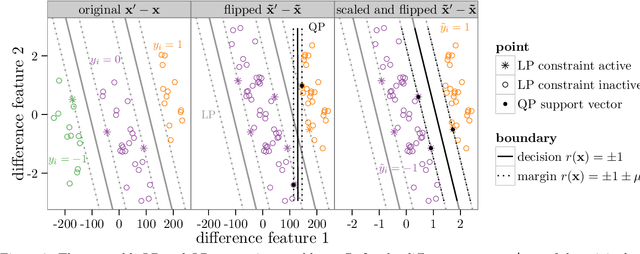
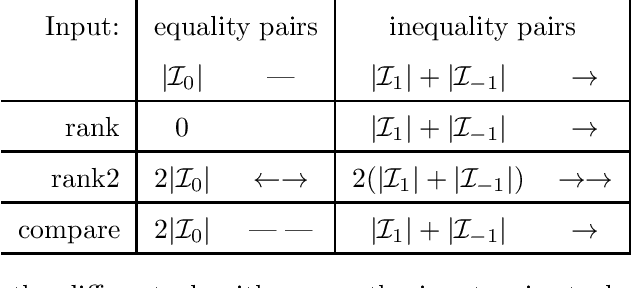
In ranking problems, the goal is to learn a ranking function from labeled pairs of input points. In this paper, we consider the related comparison problem, where the label indicates which element of the pair is better, or if there is no significant difference. We cast the learning problem as a margin maximization, and show that it can be solved by converting it to a standard SVM. We use simulated nonlinear patterns, a real learning to rank sushi data set, and a chess data set to show that our proposed SVMcompare algorithm outperforms SVMrank when there are equality pairs.
Hierarchical Policy Search via Return-Weighted Density Estimation
Nov 30, 2017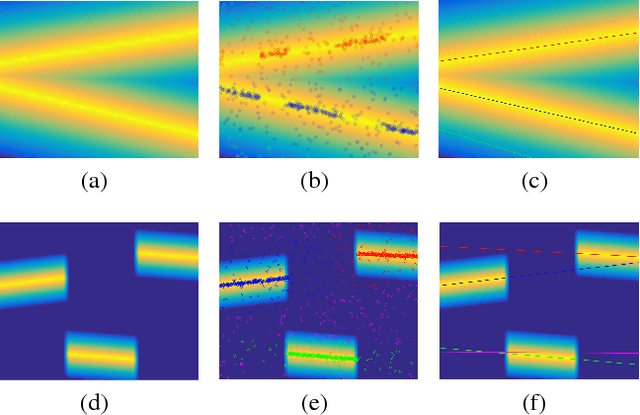
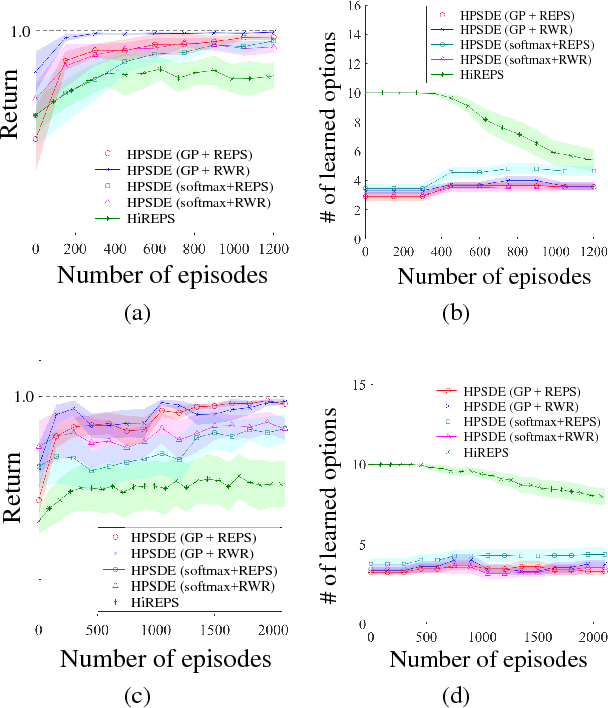
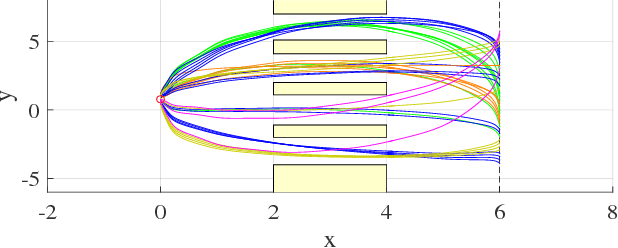
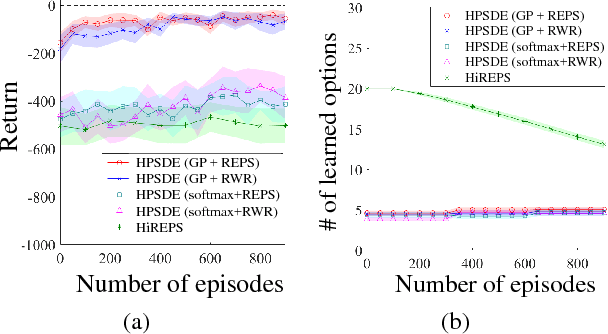
Learning an optimal policy from a multi-modal reward function is a challenging problem in reinforcement learning (RL). Hierarchical RL (HRL) tackles this problem by learning a hierarchical policy, where multiple option policies are in charge of different strategies corresponding to modes of a reward function and a gating policy selects the best option for a given context. Although HRL has been demonstrated to be promising, current state-of-the-art methods cannot still perform well in complex real-world problems due to the difficulty of identifying modes of the reward function. In this paper, we propose a novel method called hierarchical policy search via return-weighted density estimation (HPSDE), which can efficiently identify the modes through density estimation with return-weighted importance sampling. Our proposed method finds option policies corresponding to the modes of the return function and automatically determines the number and the location of option policies, which significantly reduces the burden of hyper-parameters tuning. Through experiments, we demonstrate that the proposed HPSDE successfully learns option policies corresponding to modes of the return function and that it can be successfully applied to a challenging motion planning problem of a redundant robotic manipulator.
Learning from Complementary Labels
Nov 12, 2017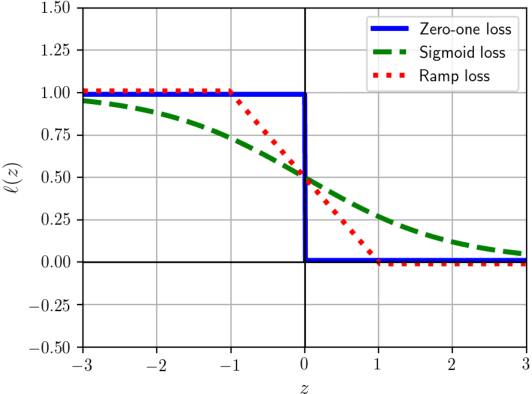
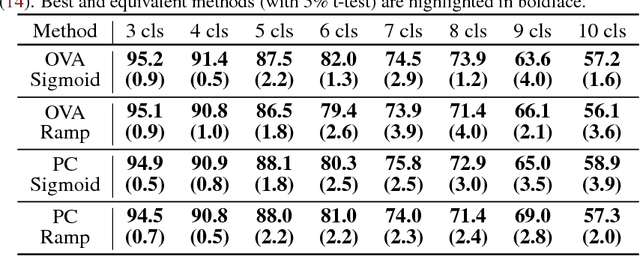
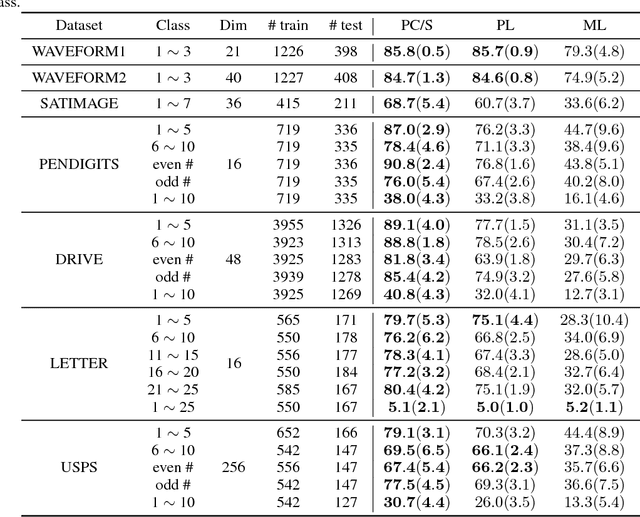
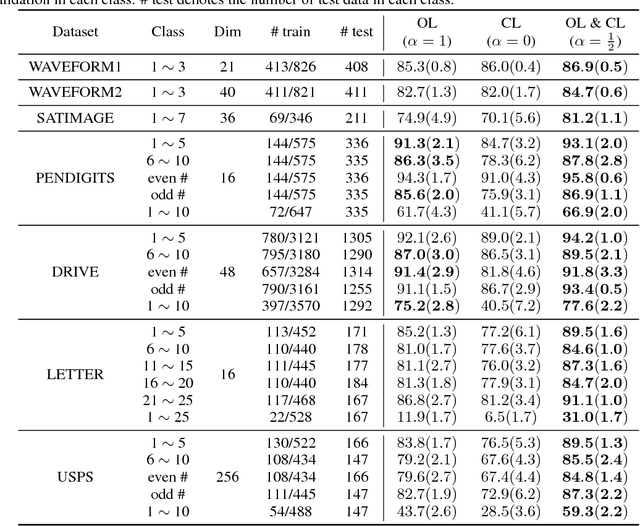
Collecting labeled data is costly and thus a critical bottleneck in real-world classification tasks. To mitigate this problem, we propose a novel setting, namely learning from complementary labels for multi-class classification. A complementary label specifies a class that a pattern does not belong to. Collecting complementary labels would be less laborious than collecting ordinary labels, since users do not have to carefully choose the correct class from a long list of candidate classes. However, complementary labels are less informative than ordinary labels and thus a suitable approach is needed to better learn from them. In this paper, we show that an unbiased estimator to the classification risk can be obtained only from complementarily labeled data, if a loss function satisfies a particular symmetric condition. We derive estimation error bounds for the proposed method and prove that the optimal parametric convergence rate is achieved. We further show that learning from complementary labels can be easily combined with learning from ordinary labels (i.e., ordinary supervised learning), providing a highly practical implementation of the proposed method. Finally, we experimentally demonstrate the usefulness of the proposed methods.