 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtremely Dense Point Correspondences using a Learned Feature Descriptor
Mar 27, 2020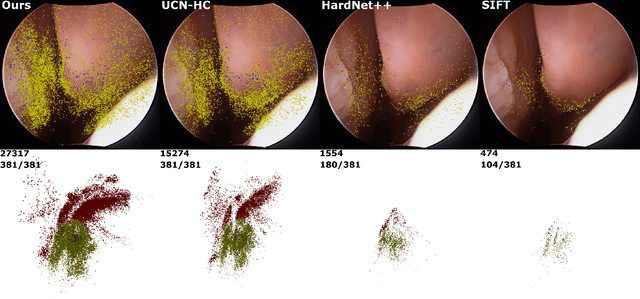

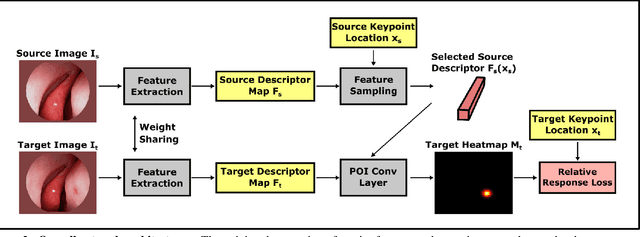
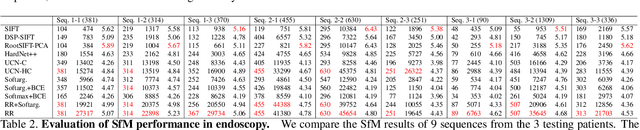
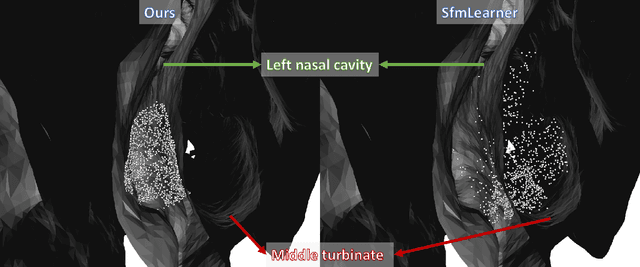
High-quality 3D reconstructions from endoscopy video play an important role in many clinical applications, including surgical navigation where they enable direct video-CT registration. While many methods exist for general multi-view 3D reconstruction, these methods often fail to deliver satisfactory performance on endoscopic video. Part of the reason is that local descriptors that establish pair-wise point correspondences, and thus drive reconstruction, struggle when confronted with the texture-scarce surface of anatomy. Learning-based dense descriptors usually have larger receptive fields enabling the encoding of global information, which can be used to disambiguate matches. In this work, we present an effective self-supervised training scheme and novel loss design for dense descriptor learning. In direct comparison to recent local and dense descriptors on an in-house sinus endoscopy dataset, we demonstrate that our proposed dense descriptor can generalize to unseen patients and scopes, thereby largely improving the performance of Structure from Motion (SfM) in terms of model density and completeness. We also evaluate our method on a public dense optical flow dataset and a small-scale SfM public dataset to further demonstrate the effectiveness and generality of our method. The source code is available at https://github.com/lppllppl920/DenseDescriptorLearning-Pytorch.
Reconstructing Sinus Anatomy from Endoscopic Video -- Towards a Radiation-free Approach for Quantitative Longitudinal Assessment
Mar 18, 2020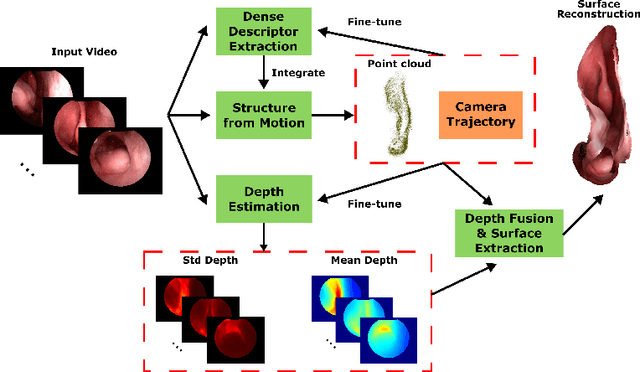
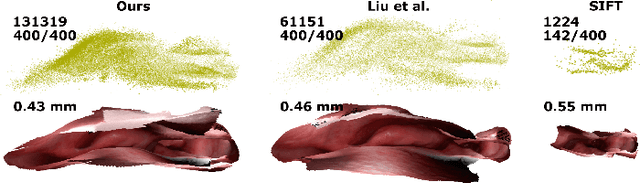
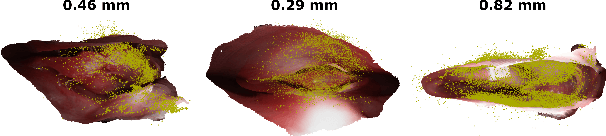
Reconstructing accurate 3D surface models of sinus anatomy directly from an endoscopic video is a promising avenue for cross-sectional and longitudinal analysis to better understand the relationship between sinus anatomy and surgical outcomes. We present a patient-specific, learning-based method for 3D reconstruction of sinus surface anatomy directly and only from endoscopic videos. We demonstrate the effectiveness and accuracy of our method on in and ex vivo data where we compare to sparse reconstructions from Structure from Motion, dense reconstruction from COLMAP, and ground truth anatomy from CT. Our textured reconstructions are watertight and enable measurement of clinically relevant parameters in good agreement with CT. The source code will be made publicly available upon publication.
Self-supervised Dense 3D Reconstruction from Monocular Endoscopic Video
Sep 06, 2019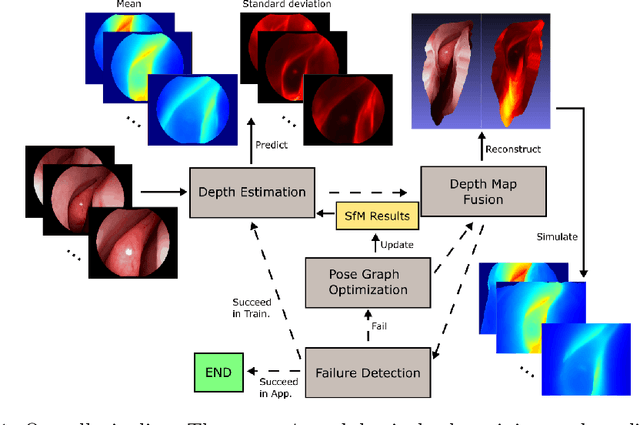
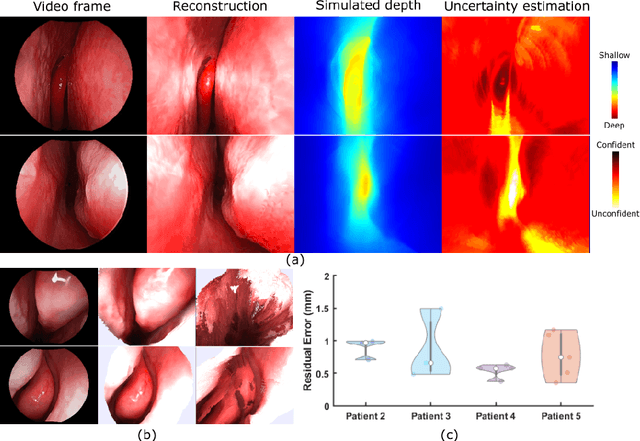
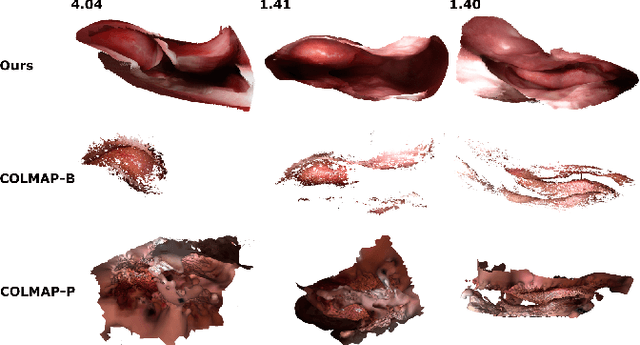
We present a self-supervised learning-based pipeline for dense 3D reconstruction from full-length monocular endoscopic videos without a priori modeling of anatomy or shading. Our method only relies on unlabeled monocular endoscopic videos and conventional multi-view stereo algorithms, and requires neither manual interaction nor patient CT in both training and application phases. In a cross-patient study using CT scans as groundtruth, we show that our method is able to produce photo-realistic dense 3D reconstructions with submillimeter mean residual errors from endoscopic videos from unseen patients and scopes.
Self-supervised Learning for Dense Depth Estimation in Monocular Endoscopy
Feb 20, 2019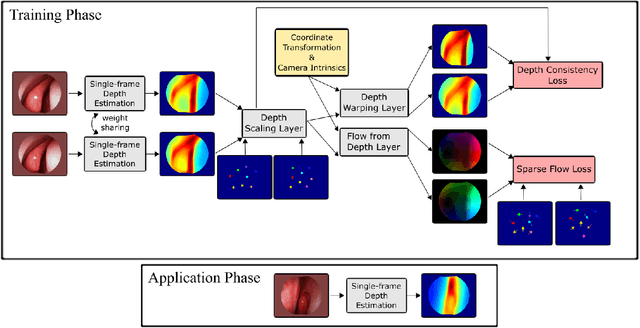
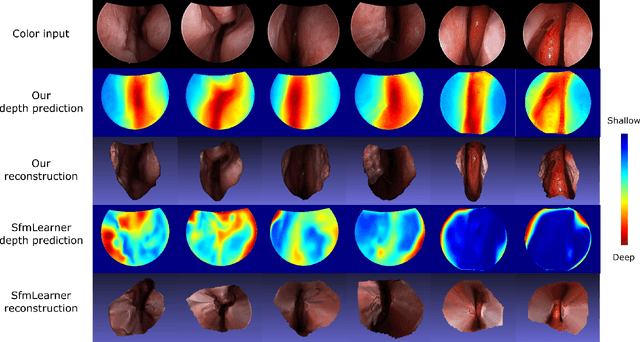
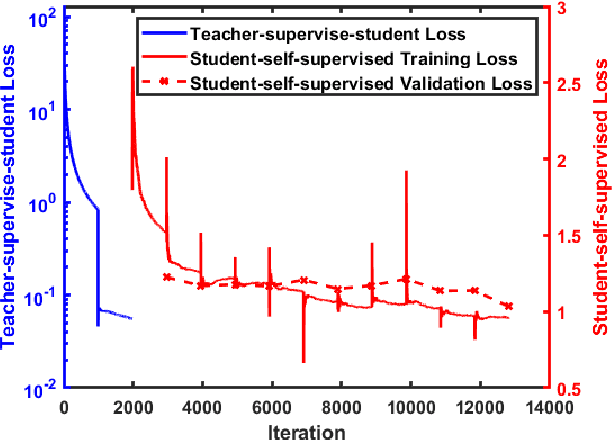
We present a self-supervised approach to training convolutional neural networks for dense depth estimation from monocular endoscopy data without a priori modeling of anatomy or shading. Our method only requires monocular endoscopic video and a multi-view stereo method, e.g. structure from motion, to supervise learning in a sparse manner. Consequently, our method requires neither manual labeling nor patient computed tomography (CT) scan in the training and application phases. In a cross-patient experiment using CT scans as groundtruth, the proposed method achieved submillimeter root mean squared error. In a comparison study to a recent self-supervised depth estimation method designed for natural video on in vivo sinus endoscopy data, we demonstrate that the proposed approach outperforms the previous method by a large margin. The source code for this work is publicly available online at https://github.com/lppllppl920/EndoscopyDepthEstimation-Pytorch.
Towards automatic initialization of registration algorithms using simulated endoscopy images
Jun 28, 2018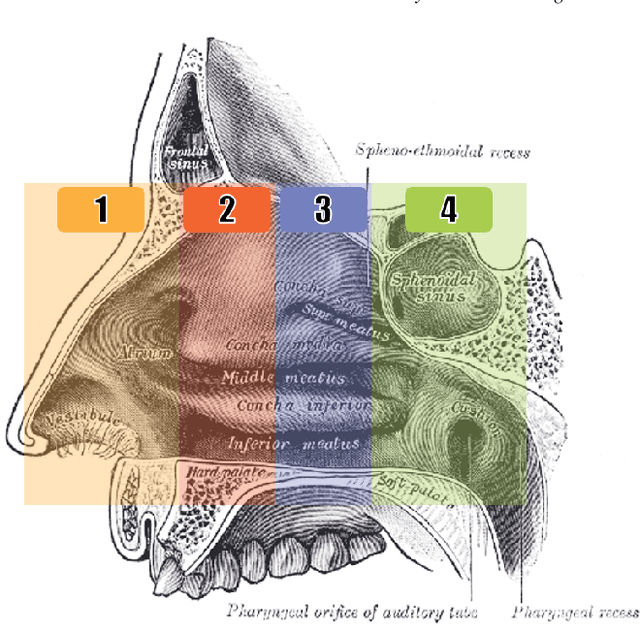
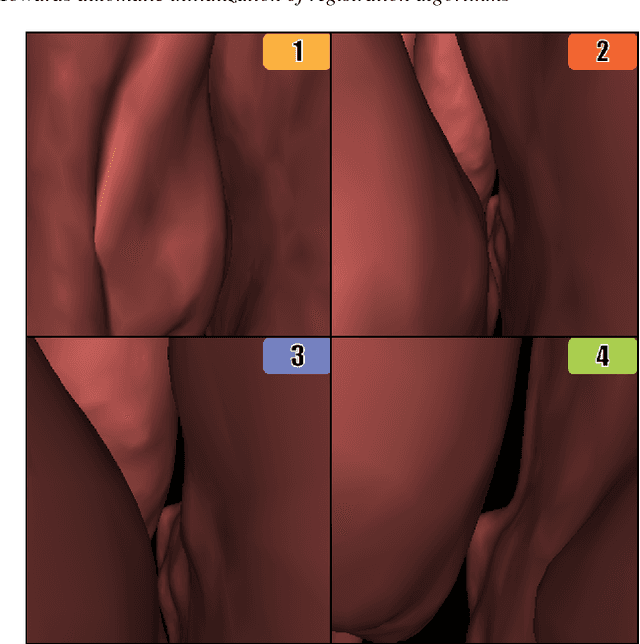
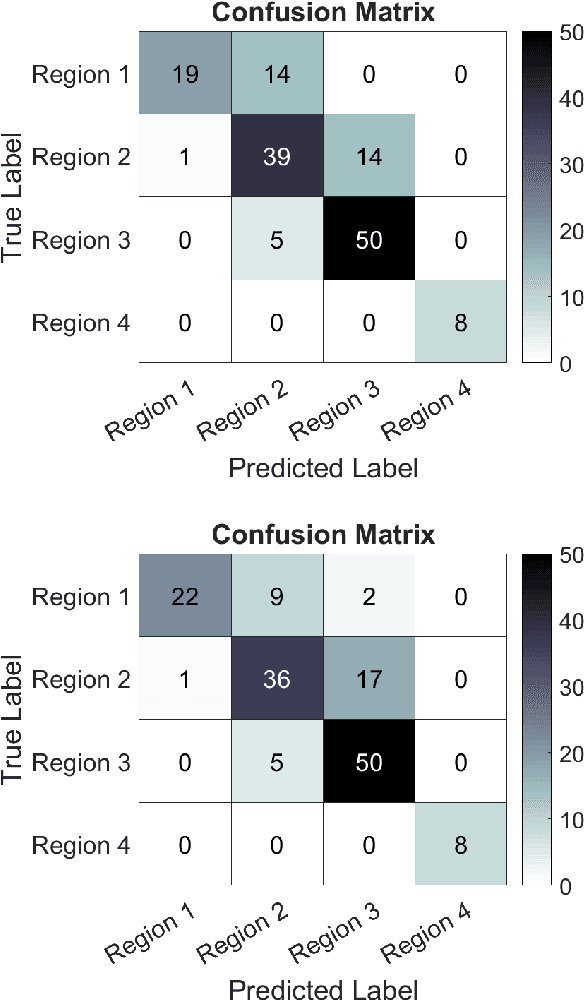
Registering images from different modalities is an active area of research in computer aided medical interventions. Several registration algorithms have been developed, many of which achieve high accuracy. However, these results are dependent on many factors, including the quality of the extracted features or segmentations being registered as well as the initial alignment. Although several methods have been developed towards improving segmentation algorithms and automating the segmentation process, few automatic initialization algorithms have been explored. In many cases, the initial alignment from which a registration is initiated is performed manually, which interferes with the clinical workflow. Our aim is to use scene classification in endoscopic procedures to achieve coarse alignment of the endoscope and a preoperative image of the anatomy. In this paper, we show using simulated scenes that a neural network can predict the region of anatomy (with respect to a preoperative image) that the endoscope is located in by observing a single endoscopic video frame. With limited training and without any hyperparameter tuning, our method achieves an accuracy of 76.53 (+/-1.19)%. There are several avenues for improvement, making this a promising direction of research. Code is available at https://github.com/AyushiSinha/AutoInitialization.
Endoscopic navigation in the absence of CT imaging
Jun 08, 2018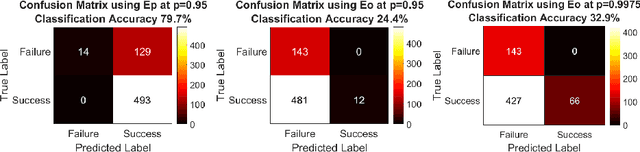
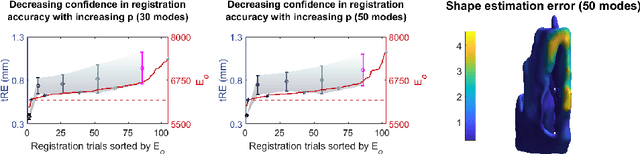
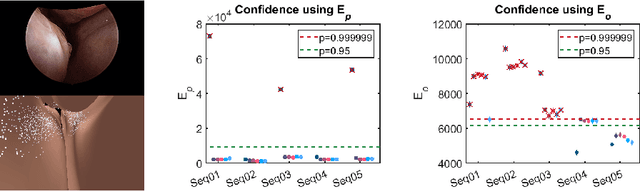
Clinical examinations that involve endoscopic exploration of the nasal cavity and sinuses often do not have a reference image to provide structural context to the clinician. In this paper, we present a system for navigation during clinical endoscopic exploration in the absence of computed tomography (CT) scans by making use of shape statistics from past CT scans. Using a deformable registration algorithm along with dense reconstructions from video, we show that we are able to achieve submillimeter registrations in in-vivo clinical data and are able to assign confidence to these registrations using confidence criteria established using simulated data.
Towards computational fluorescence microscopy: Machine learning-based integrated prediction of morphological and molecular tumor profiles
May 28, 2018
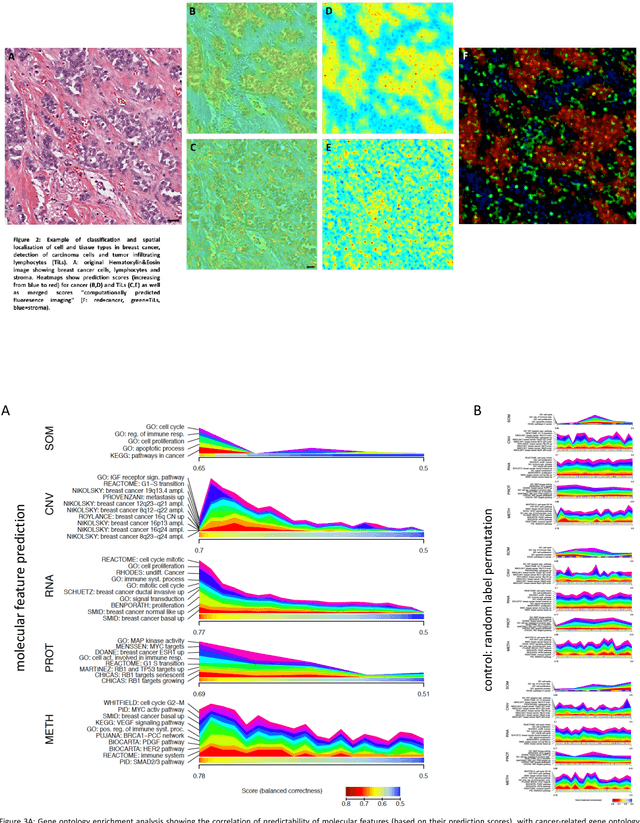

Recent advances in cancer research largely rely on new developments in microscopic or molecular profiling techniques offering high level of detail with respect to either spatial or molecular features, but usually not both. Here, we present a novel machine learning-based computational approach that allows for the identification of morphological tissue features and the prediction of molecular properties from breast cancer imaging data. This integration of microanatomic information of tumors with complex molecular profiling data, including protein or gene expression, copy number variation, gene methylation and somatic mutations, provides a novel means to computationally score molecular markers with respect to their relevance to cancer and their spatial associations within the tumor microenvironment.
Anatomically Constrained Video-CT Registration via the V-IMLOP Algorithm
Oct 25, 2016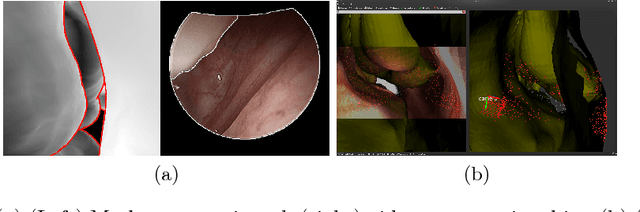
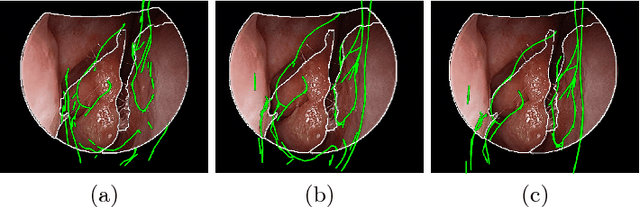
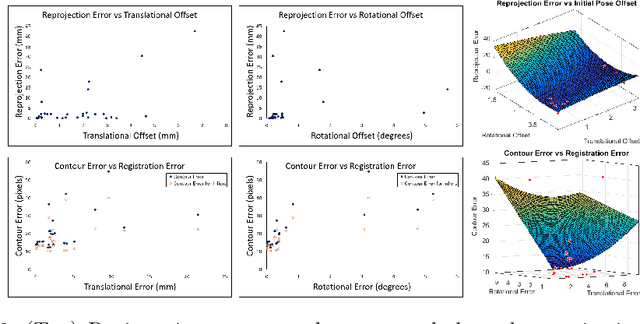
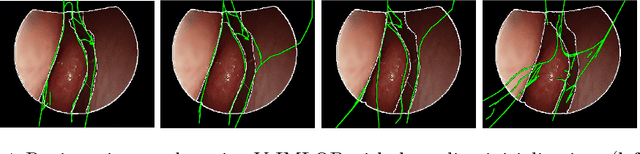
Functional endoscopic sinus surgery (FESS) is a surgical procedure used to treat acute cases of sinusitis and other sinus diseases. FESS is fast becoming the preferred choice of treatment due to its minimally invasive nature. However, due to the limited field of view of the endoscope, surgeons rely on navigation systems to guide them within the nasal cavity. State of the art navigation systems report registration accuracy of over 1mm, which is large compared to the size of the nasal airways. We present an anatomically constrained video-CT registration algorithm that incorporates multiple video features. Our algorithm is robust in the presence of outliers. We also test our algorithm on simulated and in-vivo data, and test its accuracy against degrading initializations.
* 8 pages, 4 figures, MICCAI
Automated Objective Surgical Skill Assessment in the Operating Room Using Unstructured Tool Motion
Dec 18, 2014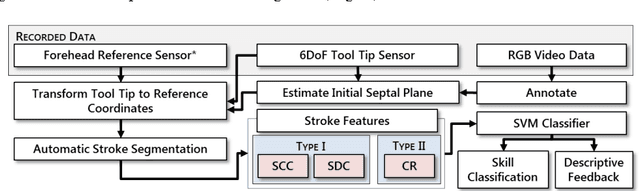
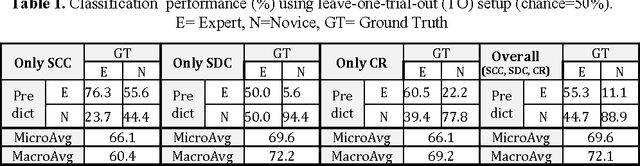
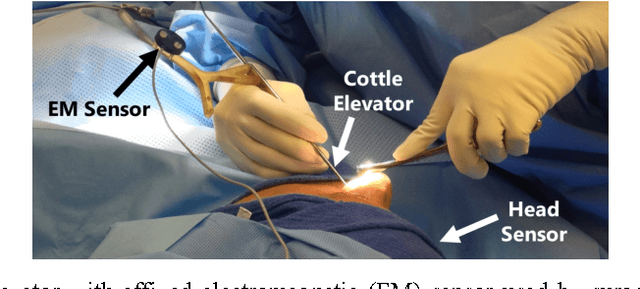
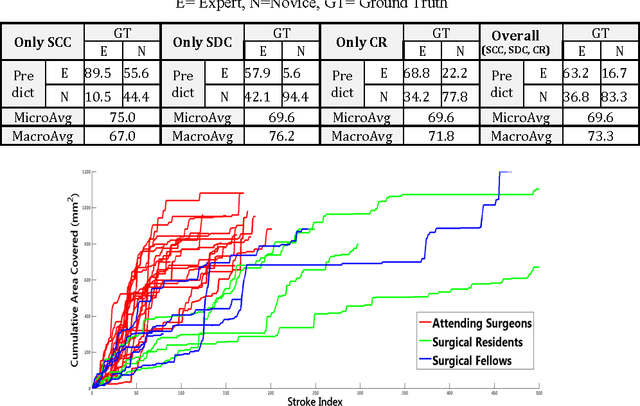
Previous work on surgical skill assessment using intraoperative tool motion in the operating room (OR) has focused on highly-structured surgical tasks such as cholecystectomy. Further, these methods only considered generic motion metrics such as time and number of movements, which are of limited instructive value. In this paper, we developed and evaluated an automated approach to the surgical skill assessment of nasal septoplasty in the OR. The obstructed field of view and highly unstructured nature of septoplasty precludes trainees from efficiently learning the procedure. We propose a descriptive structure of septoplasty consisting of two types of activity: (1) brushing activity directed away from the septum plane characterizing the consistency of the surgeon's wrist motion and (2) activity along the septal plane characterizing the surgeon's coverage pattern. We derived features related to these two activity types that classify a surgeon's level of training with an average accuracy of about 72%. The features we developed provide surgeons with personalized, actionable feedback regarding their tool motion.