 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-Space Mask Prediction for Efficient Vision Transformer Segmentation
May 18, 2026Query-based Vision Transformer segmentation models typically reconstruct dense spatial feature maps to predict masks, inheriting design patterns from convolutional architectures. We show that this explicit image-space reconstruction is not required. We introduce TokenMask, a token-space mask head that computes mask logits directly from query-token affinities and performs interpolation in logit space rather than feature space. This reformulation preserves the original linear scoring mechanism while simplifying the computational structure. Across diverse ViT backbones, datasets and segmentation tasks, TokenMask consistently improves efficiency over prior approaches by reducing computational and memory requirements while maintaining competitive accuracy, leading to tangible speedups on NVIDIA Jetson AGX Orin using TensorRT FP16 inference. Overall, TokenMask yields a simpler and more deployment-friendly design for embedded vision systems.
SVD-Prune: Training-Free Token Pruning For Efficient Vision-Language Models
Apr 13, 2026Vision-Language Models (VLM) have revolutionized multimodal learning by jointly processing visual and textual information. Yet, they face significant challenges due to the high computational and memory demands of processing long sequences of vision tokens. Many existing methods rely on local heuristics, such as attention scores or token norms. However, these criteria suffer from positional bias and information dispersion, limiting their ability to preserve essential content at high pruning ratios and leading to performance degradation on visually detailed images. To address these issues, we propose SVD-Prune, a trainingfree, plug-and-play token pruning method based on Singular Value Decomposition. It decomposes the vision token feature matrix and selects the top-K tokens using statistical leverage scores, ensuring only tokens contributing most to the dominant global variance are preserved. Experiments show that SVD-Prune consistently outperforms prior pruning methods under extreme vision token budgets, maintaining strong performance even with 32 and 16 vision tokens.
LiPS: Lightweight Panoptic Segmentation for Resource-Constrained Robotics
Apr 01, 2026Panoptic segmentation is a key enabler for robotic perception, as it unifies semantic understanding with object-level reasoning. However, the increasing complexity of state-of-the-art models makes them unsuitable for deployment on resource-constrained platforms such as mobile robots. We propose a novel approach called LiPS that addresses the challenge of efficient-to-compute panoptic segmentation with a lightweight design that retains query-based decoding while introducing a streamlined feature extraction and fusion pathway. It aims at providing a strong panoptic segmentation performance while substantially lowering the computational demands. Evaluations on standard benchmarks demonstrate that LiPS attains accuracy comparable to much heavier baselines, while providing up to 4.5 higher throughput, measured in frames per second, and requiring nearly 6.8 times fewer computations. This efficiency makes LiPS a highly relevant bridge between modern panoptic models and real-world robotic applications.
Where Do Tokens Go? Understanding Pruning Behaviors in STEP at High Resolutions
Sep 17, 2025Vision Transformers (ViTs) achieve state-of-the-art performance in semantic segmentation but are hindered by high computational and memory costs. To address this, we propose STEP (SuperToken and Early-Pruning), a hybrid token-reduction framework that combines dynamic patch merging and token pruning to enhance efficiency without significantly compromising accuracy. At the core of STEP is dCTS, a lightweight CNN-based policy network that enables flexible merging into superpatches. Encoder blocks integrate also early-exits to remove high-confident supertokens, lowering computational load. We evaluate our method on high-resolution semantic segmentation benchmarks, including images up to 1024 x 1024, and show that when dCTS is applied alone, the token count can be reduced by a factor of 2.5 compared to the standard 16 x 16 pixel patching scheme. This yields a 2.6x reduction in computational cost and a 3.4x increase in throughput when using ViT-Large as the backbone. Applying the full STEP framework further improves efficiency, reaching up to a 4x reduction in computational complexity and a 1.7x gain in inference speed, with a maximum accuracy drop of no more than 2.0%. With the proposed STEP configurations, up to 40% of tokens can be confidently predicted and halted before reaching the final encoder layer.
Is Semantic SLAM Ready for Embedded Systems ? A Comparative Survey
May 18, 2025In embedded systems, robots must perceive and interpret their environment efficiently to operate reliably in real-world conditions. Visual Semantic SLAM (Simultaneous Localization and Mapping) enhances standard SLAM by incorporating semantic information into the map, enabling more informed decision-making. However, implementing such systems on resource-limited hardware involves trade-offs between accuracy, computing efficiency, and power usage. This paper provides a comparative review of recent Semantic Visual SLAM methods with a focus on their applicability to embedded platforms. We analyze three main types of architectures - Geometric SLAM, Neural Radiance Fields (NeRF), and 3D Gaussian Splatting - and evaluate their performance on constrained hardware, specifically the NVIDIA Jetson AGX Orin. We compare their accuracy, segmentation quality, memory usage, and energy consumption. Our results show that methods based on NeRF and Gaussian Splatting achieve high semantic detail but demand substantial computing resources, limiting their use on embedded devices. In contrast, Semantic Geometric SLAM offers a more practical balance between computational cost and accuracy. The review highlights a need for SLAM algorithms that are better adapted to embedded environments, and it discusses key directions for improving their efficiency through algorithm-hardware co-design.
Challenging deep image descriptors for retrieval in heterogeneous iconographic collections
Sep 19, 2019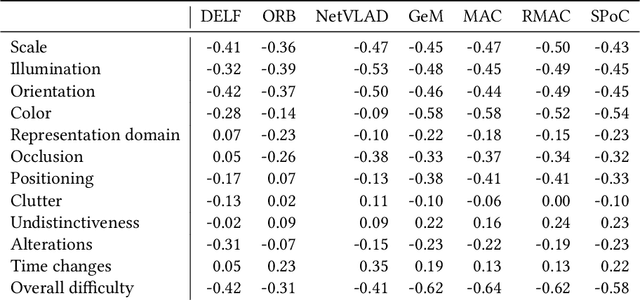
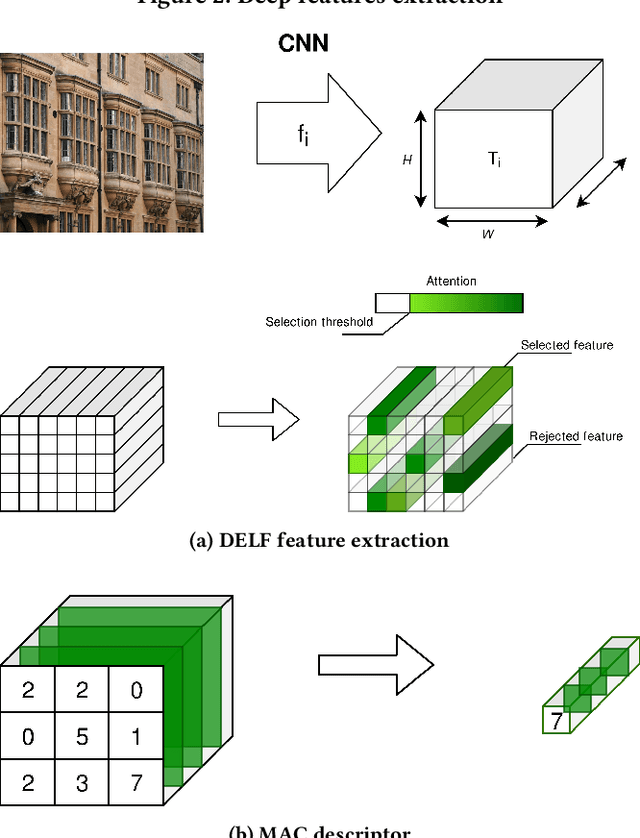

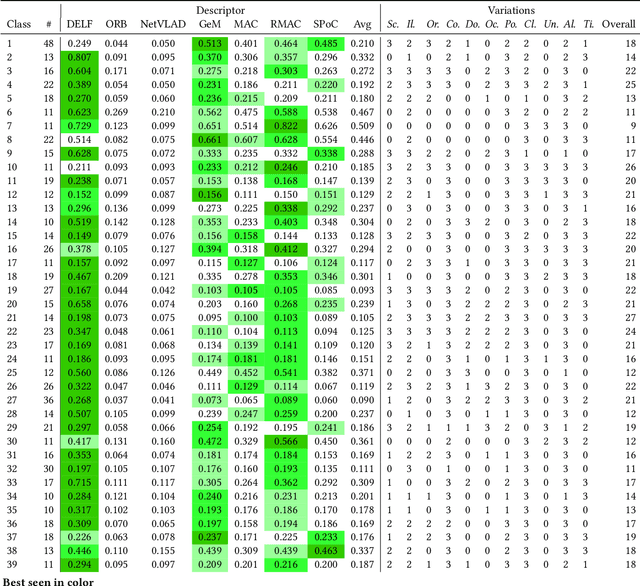
This article proposes to study the behavior of recent and efficient state-of-the-art deep-learning based image descriptors for content-based image retrieval, facing a panel of complex variations appearing in heterogeneous image datasets, in particular in cultural collections that may involve multi-source, multi-date and multi-view Permission to make digital