 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Deep Learning for Biometrics: Overview, Challenges and Trends in Ear of Frugal AI
Feb 09, 2026Recent advances in deep learning, whether on discriminative or generative tasks have been beneficial for various applications, among which security and defense. However, their increasing computational demands during training and deployment translates directly into high energy consumption. As a consequence, this induces a heavy carbon footprint which hinders their widespread use and scalability, but also a limitation when deployed on resource-constrained edge devices for real-time use. In this paper, we briefly survey efficient deep learning methods for biometric applications. Specifically, we tackle the challenges one might incur when training and deploying deep learning approaches, and provide a taxonomy of the various efficient deep learning families. Additionally, we discuss complementary metrics for evaluating the efficiency of these models such as memory, computation, latency, throughput, and advocate for universal and reproducible metrics for better comparison. Last, we give future research directions to consider.
Where Do Tokens Go? Understanding Pruning Behaviors in STEP at High Resolutions
Sep 17, 2025Vision Transformers (ViTs) achieve state-of-the-art performance in semantic segmentation but are hindered by high computational and memory costs. To address this, we propose STEP (SuperToken and Early-Pruning), a hybrid token-reduction framework that combines dynamic patch merging and token pruning to enhance efficiency without significantly compromising accuracy. At the core of STEP is dCTS, a lightweight CNN-based policy network that enables flexible merging into superpatches. Encoder blocks integrate also early-exits to remove high-confident supertokens, lowering computational load. We evaluate our method on high-resolution semantic segmentation benchmarks, including images up to 1024 x 1024, and show that when dCTS is applied alone, the token count can be reduced by a factor of 2.5 compared to the standard 16 x 16 pixel patching scheme. This yields a 2.6x reduction in computational cost and a 3.4x increase in throughput when using ViT-Large as the backbone. Applying the full STEP framework further improves efficiency, reaching up to a 4x reduction in computational complexity and a 1.7x gain in inference speed, with a maximum accuracy drop of no more than 2.0%. With the proposed STEP configurations, up to 40% of tokens can be confidently predicted and halted before reaching the final encoder layer.
Minimizing subject-dependent calibration for BCI with Riemannian transfer learning
Nov 23, 2021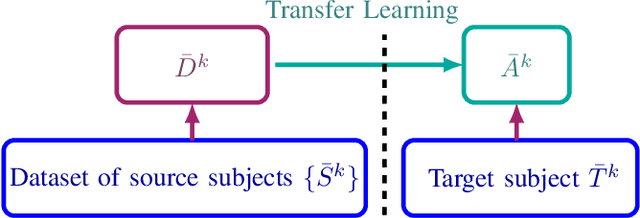
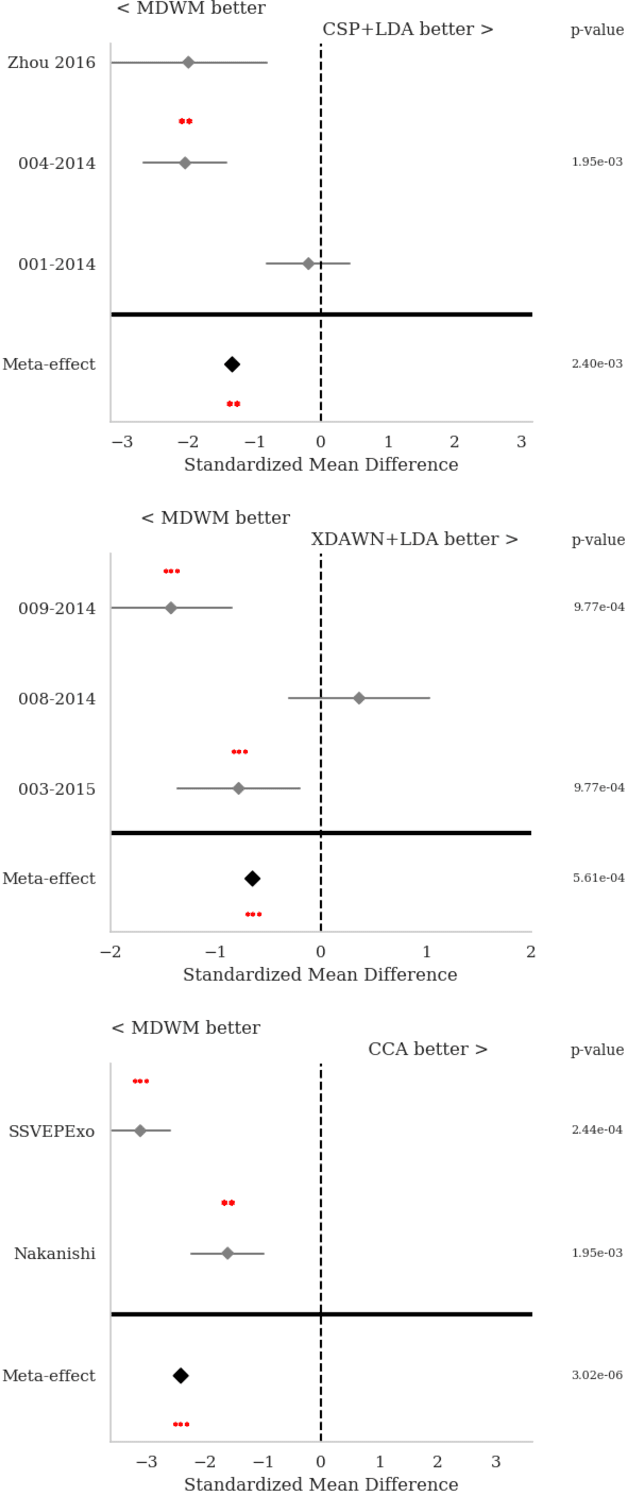
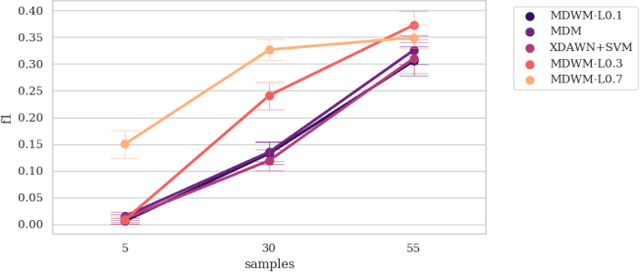
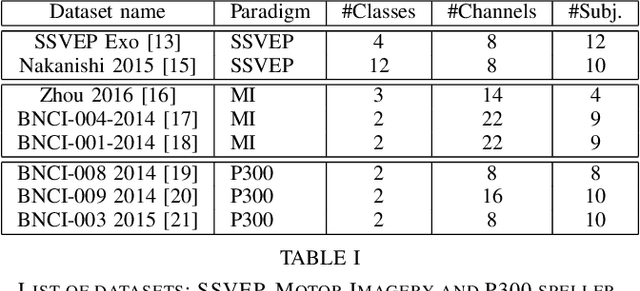
Calibration is still an important issue for user experience in Brain-Computer Interfaces (BCI). Common experimental designs often involve a lengthy training period that raises the cognitive fatigue, before even starting to use the BCI. Reducing or suppressing this subject-dependent calibration is possible by relying on advanced machine learning techniques, such as transfer learning. Building on Riemannian BCI, we present a simple and effective scheme to train a classifier on data recorded from different subjects, to reduce the calibration while preserving good performances. The main novelty of this paper is to propose a unique approach that could be applied on very different paradigms. To demonstrate the robustness of this approach, we conducted a meta-analysis on multiple datasets for three BCI paradigms: event-related potentials (P300), motor imagery and SSVEP. Relying on the MOABB open source framework to ensure the reproducibility of the experiments and the statistical analysis, the results clearly show that the proposed approach could be applied on any kind of BCI paradigm and in most of the cases to significantly improve the classifier reliability. We point out some key features to further improve transfer learning methods.