 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStronger Neyman Regret Guarantees for Adaptive Experimental Design
Feb 24, 2025We study the design of adaptive, sequential experiments for unbiased average treatment effect (ATE) estimation in the design-based potential outcomes setting. Our goal is to develop adaptive designs offering sublinear Neyman regret, meaning their efficiency must approach that of the hindsight-optimal nonadaptive design. Recent work [Dai et al, 2023] introduced ClipOGD, the first method achieving $\widetilde{O}(\sqrt{T})$ expected Neyman regret under mild conditions. In this work, we propose adaptive designs with substantially stronger Neyman regret guarantees. In particular, we modify ClipOGD to obtain anytime $\widetilde{O}(\log T)$ Neyman regret under natural boundedness assumptions. Further, in the setting where experimental units have pre-treatment covariates, we introduce and study a class of contextual "multigroup" Neyman regret guarantees: Given any set of possibly overlapping groups based on the covariates, the adaptive design outperforms each group's best non-adaptive designs. In particular, we develop a contextual adaptive design with $\widetilde{O}(\sqrt{T})$ anytime multigroup Neyman regret. We empirically validate the proposed designs through an array of experiments.
Order of Magnitude Speedups for LLM Membership Inference
Sep 24, 2024



Large Language Models (LLMs) have the promise to revolutionize computing broadly, but their complexity and extensive training data also expose significant privacy vulnerabilities. One of the simplest privacy risks associated with LLMs is their susceptibility to membership inference attacks (MIAs), wherein an adversary aims to determine whether a specific data point was part of the model's training set. Although this is a known risk, state of the art methodologies for MIAs rely on training multiple computationally costly shadow models, making risk evaluation prohibitive for large models. Here we adapt a recent line of work which uses quantile regression to mount membership inference attacks; we extend this work by proposing a low-cost MIA that leverages an ensemble of small quantile regression models to determine if a document belongs to the model's training set or not. We demonstrate the effectiveness of this approach on fine-tuned LLMs of varying families (OPT, Pythia, Llama) and across multiple datasets. Across all scenarios we obtain comparable or improved accuracy compared to state of the art shadow model approaches, with as little as 6% of their computation budget. We demonstrate increased effectiveness across multi-epoch trained target models, and architecture miss-specification robustness, that is, we can mount an effective attack against a model using a different tokenizer and architecture, without requiring knowledge on the target model.
Reconstruction Attacks on Machine Unlearning: Simple Models are Vulnerable
May 30, 2024



Machine unlearning is motivated by desire for data autonomy: a person can request to have their data's influence removed from deployed models, and those models should be updated as if they were retrained without the person's data. We show that, counter-intuitively, these updates expose individuals to high-accuracy reconstruction attacks which allow the attacker to recover their data in its entirety, even when the original models are so simple that privacy risk might not otherwise have been a concern. We show how to mount a near-perfect attack on the deleted data point from linear regression models. We then generalize our attack to other loss functions and architectures, and empirically demonstrate the effectiveness of our attacks across a wide range of datasets (capturing both tabular and image data). Our work highlights that privacy risk is significant even for extremely simple model classes when individuals can request deletion of their data from the model.
Multicalibration for Confidence Scoring in LLMs
Apr 06, 2024This paper proposes the use of "multicalibration" to yield interpretable and reliable confidence scores for outputs generated by large language models (LLMs). Multicalibration asks for calibration not just marginally, but simultaneously across various intersecting groupings of the data. We show how to form groupings for prompt/completion pairs that are correlated with the probability of correctness via two techniques: clustering within an embedding space, and "self-annotation" - querying the LLM by asking it various yes-or-no questions about the prompt. We also develop novel variants of multicalibration algorithms that offer performance improvements by reducing their tendency to overfit. Through systematic benchmarking across various question answering datasets and LLMs, we show how our techniques can yield confidence scores that provide substantial improvements in fine-grained measures of both calibration and accuracy compared to existing methods.
Federated Fairness without Access to Sensitive Groups
Feb 22, 2024Current approaches to group fairness in federated learning assume the existence of predefined and labeled sensitive groups during training. However, due to factors ranging from emerging regulations to dynamics and location-dependency of protected groups, this assumption may be unsuitable in many real-world scenarios. In this work, we propose a new approach to guarantee group fairness that does not rely on any predefined definition of sensitive groups or additional labels. Our objective allows the federation to learn a Pareto efficient global model ensuring worst-case group fairness and it enables, via a single hyper-parameter, trade-offs between fairness and utility, subject only to a group size constraint. This implies that any sufficiently large subset of the population is guaranteed to receive at least a minimum level of utility performance from the model. The proposed objective encompasses existing approaches as special cases, such as empirical risk minimization and subgroup robustness objectives from centralized machine learning. We provide an algorithm to solve this problem in federation that enjoys convergence and excess risk guarantees. Our empirical results indicate that the proposed approach can effectively improve the worst-performing group that may be present without unnecessarily hurting the average performance, exhibits superior or comparable performance to relevant baselines, and achieves a large set of solutions with different fairness-utility trade-offs.
Scalable Membership Inference Attacks via Quantile Regression
Jul 07, 2023



Membership inference attacks are designed to determine, using black box access to trained models, whether a particular example was used in training or not. Membership inference can be formalized as a hypothesis testing problem. The most effective existing attacks estimate the distribution of some test statistic (usually the model's confidence on the true label) on points that were (and were not) used in training by training many \emph{shadow models} -- i.e. models of the same architecture as the model being attacked, trained on a random subsample of data. While effective, these attacks are extremely computationally expensive, especially when the model under attack is large. We introduce a new class of attacks based on performing quantile regression on the distribution of confidence scores induced by the model under attack on points that are not used in training. We show that our method is competitive with state-of-the-art shadow model attacks, while requiring substantially less compute because our attack requires training only a single model. Moreover, unlike shadow model attacks, our proposed attack does not require any knowledge of the architecture of the model under attack and is therefore truly ``black-box". We show the efficacy of this approach in an extensive series of experiments on various datasets and model architectures.
Efficient Embedding of Semantic Similarity in Control Policies via Entangled Bisimulation
Jan 28, 2022



Learning generalizeable policies from visual input in the presence of visual distractions is a challenging problem in reinforcement learning. Recently, there has been renewed interest in bisimulation metrics as a tool to address this issue; these metrics can be used to learn representations that are, in principle, invariant to irrelevant distractions by measuring behavioural similarity between states. An accurate, unbiased, and scalable estimation of these metrics has proved elusive in continuous state and action scenarios. We propose entangled bisimulation, a bisimulation metric that allows the specification of the distance function between states, and can be estimated without bias in continuous state and action spaces. We show how entangled bisimulation can meaningfully improve over previous methods on the Distracting Control Suite (DCS), even when added on top of data augmentation techniques.
Minimax Demographic Group Fairness in Federated Learning
Jan 25, 2022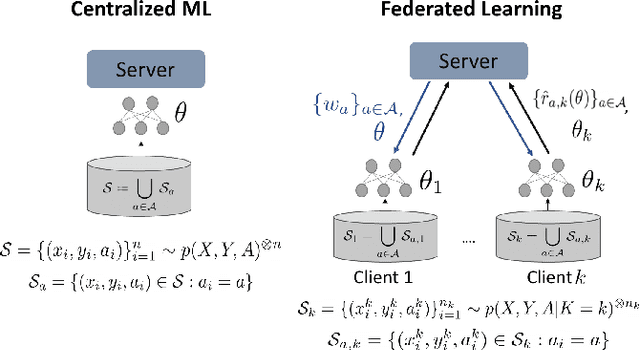
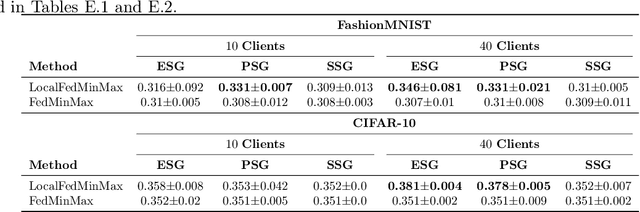
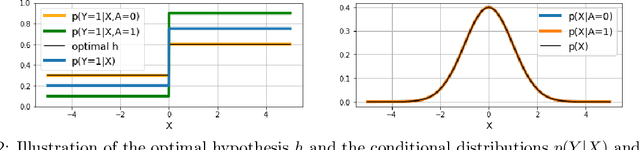
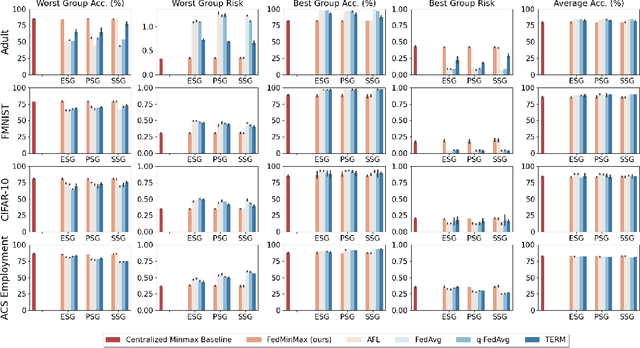
Federated learning is an increasingly popular paradigm that enables a large number of entities to collaboratively learn better models. In this work, we study minimax group fairness in federated learning scenarios where different participating entities may only have access to a subset of the population groups during the training phase. We formally analyze how our proposed group fairness objective differs from existing federated learning fairness criteria that impose similar performance across participants instead of demographic groups. We provide an optimization algorithm -- FedMinMax -- for solving the proposed problem that provably enjoys the performance guarantees of centralized learning algorithms. We experimentally compare the proposed approach against other state-of-the-art methods in terms of group fairness in various federated learning setups, showing that our approach exhibits competitive or superior performance.
Distributionally Robust Group Backwards Compatibility
Dec 20, 2021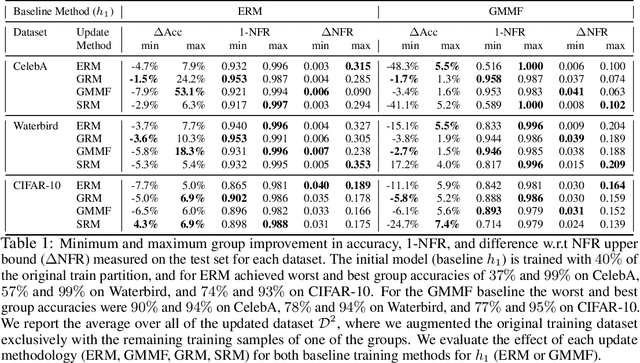
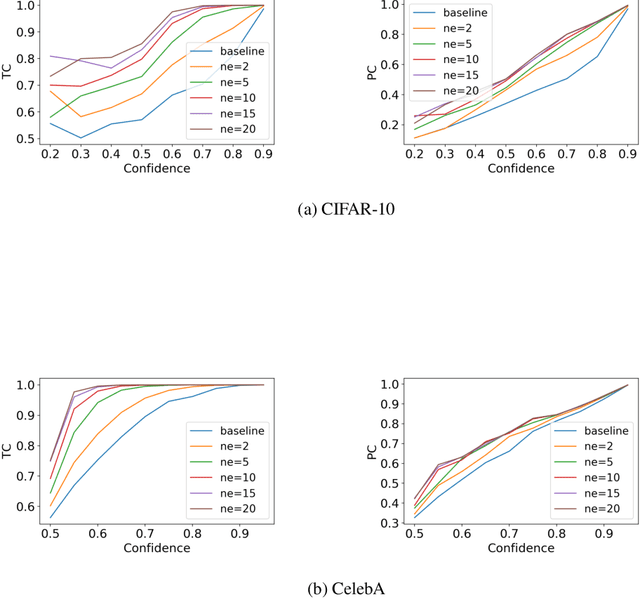
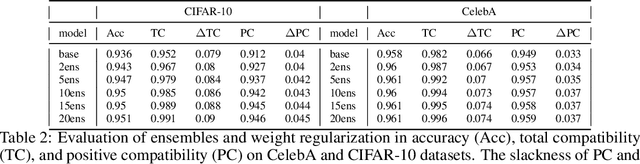

Machine learning models are updated as new data is acquired or new architectures are developed. These updates usually increase model performance, but may introduce backward compatibility errors, where individual users or groups of users see their performance on the updated model adversely affected. This problem can also be present when training datasets do not accurately reflect overall population demographics, with some groups having overall lower participation in the data collection process, posing a significant fairness concern. We analyze how ideas from distributional robustness and minimax fairness can aid backward compatibility in this scenario, and propose two methods to directly address this issue. Our theoretical analysis is backed by experimental results on CIFAR-10, CelebA, and Waterbirds, three standard image classification datasets. Code available at github.com/natalialmg/GroupBC
Federating for Learning Group Fair Models
Oct 07, 2021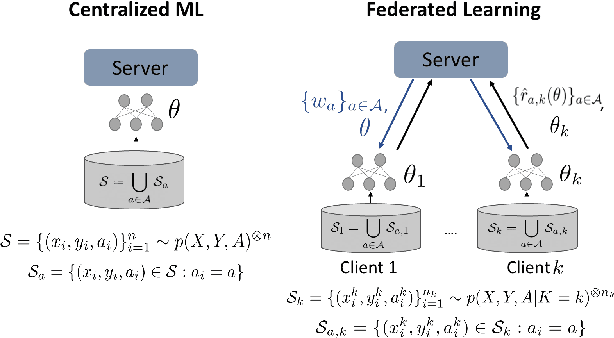
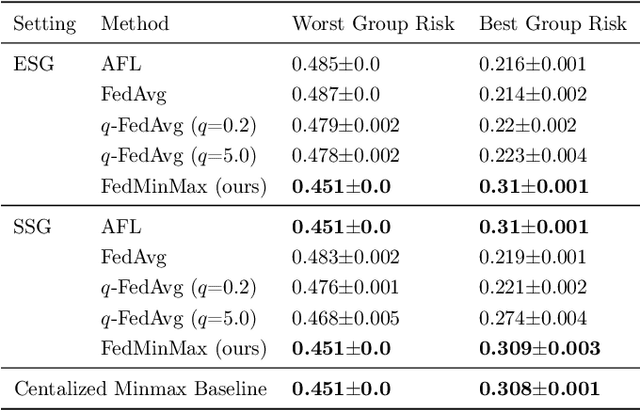
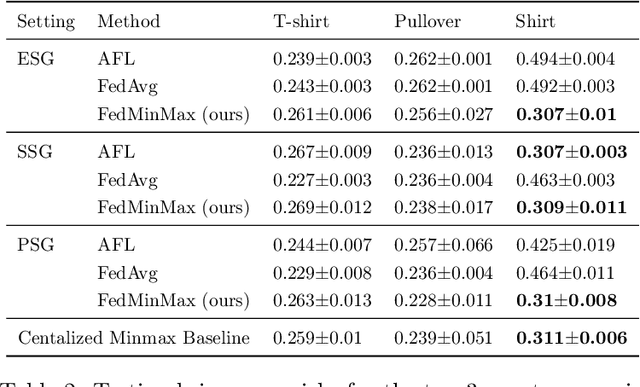
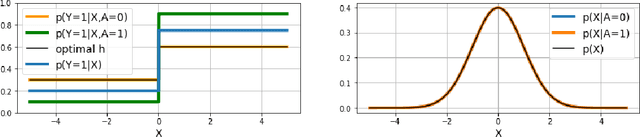
Federated learning is an increasingly popular paradigm that enables a large number of entities to collaboratively learn better models. In this work, we study minmax group fairness in paradigms where different participating entities may only have access to a subset of the population groups during the training phase. We formally analyze how this fairness objective differs from existing federated learning fairness criteria that impose similar performance across participants instead of demographic groups. We provide an optimization algorithm -- FedMinMax -- for solving the proposed problem that provably enjoys the performance guarantees of centralized learning algorithms. We experimentally compare the proposed approach against other methods in terms of group fairness in various federated learning setups.