 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"What's This?" -- Learning to Segment Unknown Objects from Manipulation Sequences
Nov 06, 2020


We present a novel framework for self-supervised grasped object segmentation with a robotic manipulator. Our method successively learns an agnostic foreground segmentation followed by a distinction between manipulator and object solely by observing the motion between consecutive RGB frames. In contrast to previous approaches, we propose a single, end-to-end trainable architecture which jointly incorporates motion cues and semantic knowledge. Furthermore, while the motion of the manipulator and the object are substantial cues for our algorithm, we present means to robustly deal with distraction objects moving in the background, as well as with completely static scenes. Our method neither depends on any visual registration of a kinematic robot or 3D object models, nor on precise hand-eye calibration or any additional sensor data. By extensive experimental evaluation we demonstrate the superiority of our framework and provide detailed insights on its capability of dealing with the aforementioned extreme cases of motion. We also show that training a semantic segmentation network with the automatically labeled data achieves results on par with manually annotated training data. Code and pretrained models will be made publicly available.
BOP Challenge 2020 on 6D Object Localization
Oct 13, 2020
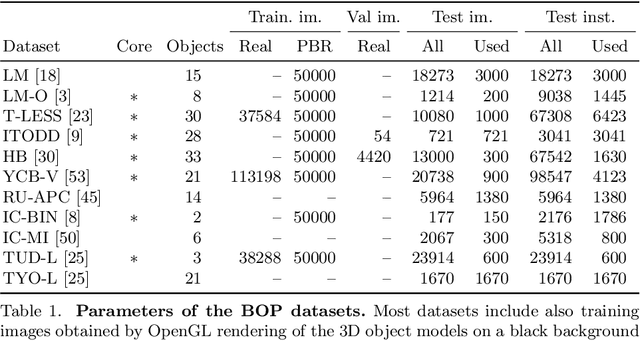

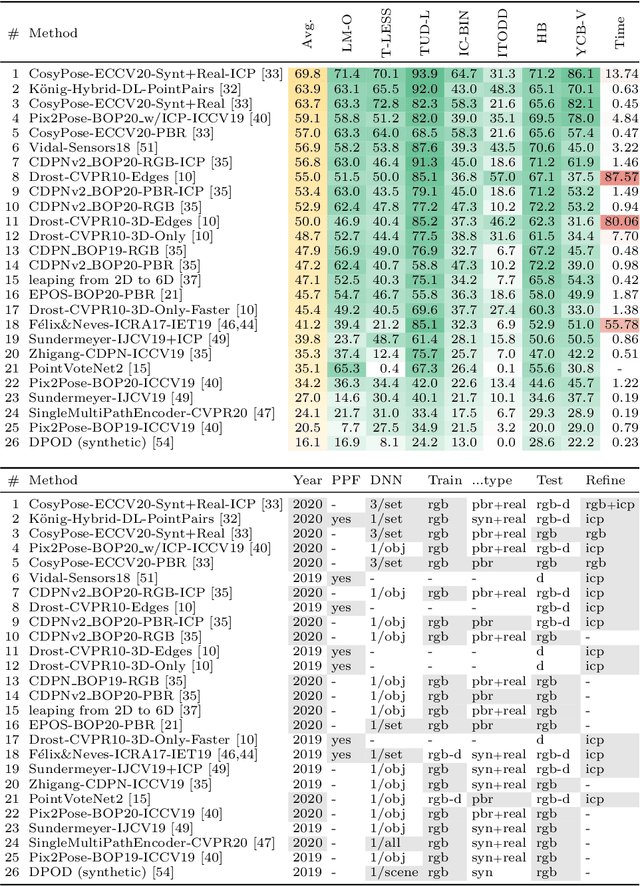
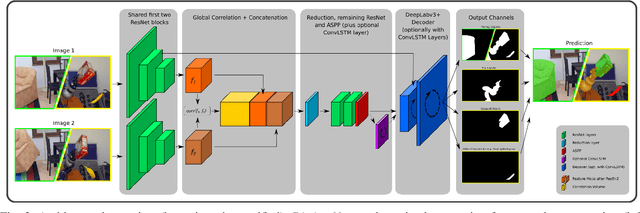
This paper presents the evaluation methodology, datasets, and results of the BOP Challenge 2020, the third in a series of public competitions organized with the goal to capture the status quo in the field of 6D object pose estimation from an RGB-D image. In 2020, to reduce the domain gap between synthetic training and real test RGB images, the participants were provided 350K photorealistic training images generated by BlenderProc4BOP, a new open-source and light-weight physically-based renderer (PBR) and procedural data generator. Methods based on deep neural networks have finally caught up with methods based on point pair features, which were dominating previous editions of the challenge. Although the top-performing methods rely on RGB-D image channels, strong results were achieved when only RGB channels were used at both training and test time - out of the 26 evaluated methods, the third method was trained on RGB channels of PBR and real images, while the fifth on RGB channels of PBR images only. Strong data augmentation was identified as a key component of the top-performing CosyPose method, and the photorealism of PBR images was demonstrated effective despite the augmentation. The online evaluation system stays open and is available on the project website: bop.felk.cvut.cz.
Self-Supervised Object-in-Gripper Segmentation from Robotic Motions
Mar 03, 2020
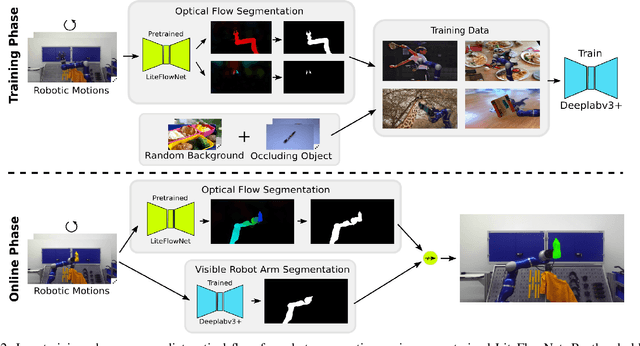

We present a novel technique to automatically generate annotated data for important robotic perception tasks such as object segmentation and 3D object reconstruction using a robot manipulator. Our self-supervised method can segment unknown objects from a robotic gripper in RGB video sequences by exploiting motion and temporal cues. The key aspect of our approach in contrast to existing systems is its independence of any hardware specifics such as extrinsic and intrinsic camera calibration and a robot model. We achieve this using a two-step process: First, we learn to predict segmentation masks for our given manipulator using optical flow estimation. Then, these masks are used in combination with motion cues to automatically distinguish between the manipulator, the background, and the unknown, grasped object. We perform a thorough comparison with alternative baselines and approaches in the literature. The obtained object views and masks are suitable training data for segmentation networks that generalize to novel environments and also allow for watertight 3D object reconstruction.
BlenderProc
Oct 25, 2019BlenderProc is a modular procedural pipeline, which helps in generating real looking images for the training of convolutional neural networks. These can be used in a variety of use cases including segmentation, depth, normal and pose estimation and many others. A key feature of our extension of blender is the simple to use modular pipeline, which was designed to be easily extendable. By offering standard modules, which cover a variety of scenarios, we provide a starting point on which new modules can be created.
Multi-path Learning for Object Pose Estimation Across Domains
Aug 01, 2019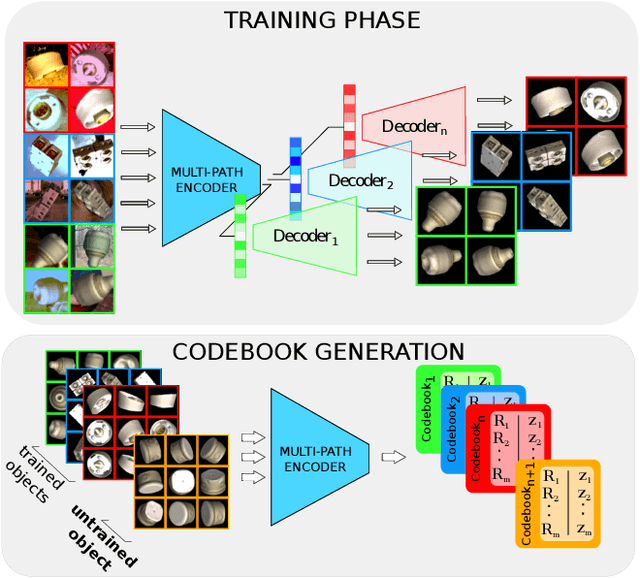

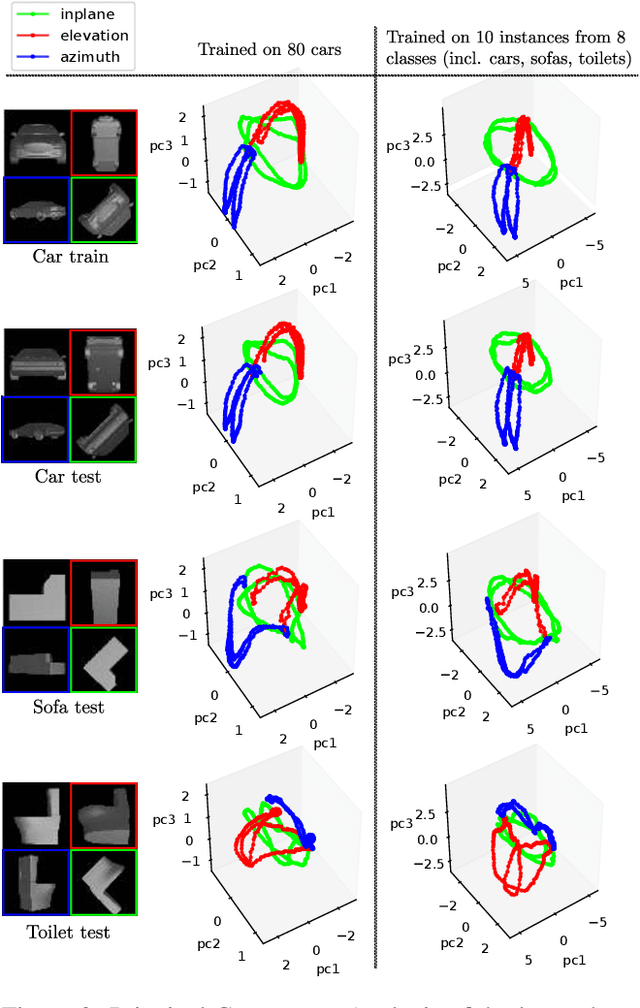
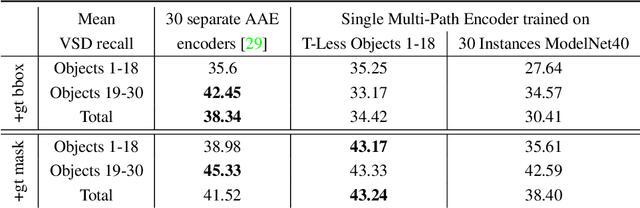
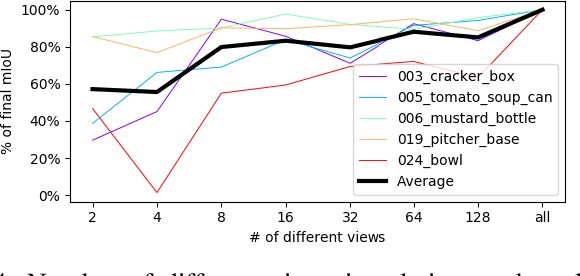
We introduce a scalable approach for object pose estimation trained on simulated RGB views of multiple 3D models together. We learn an encoding of object views that does not only describe the orientation of all objects seen during training, but can also relate views of untrained objects. Our single-encoder-multi-decoder network is trained using a technique we denote "multi-path learning": While the encoder is shared by all objects, each decoder only reconstructs views of a single object. Consequently, views of different instances do not need to be separated in the latent space and can share common features. The resulting encoder generalizes well from synthetic to real data and across various instances, categories, model types and datasets. We systematically investigate the learned encodings, their generalization capabilities and iterative refinement strategies on the ModelNet40 and T-LESS dataset. On T-LESS, we achieve state-of-the-art results with our 6D Object Detection pipeline, both in the RGB and depth domain, outperforming learning-free pipelines at much lower runtimes.
Implicit 3D Orientation Learning for 6D Object Detection from RGB Images
Feb 04, 2019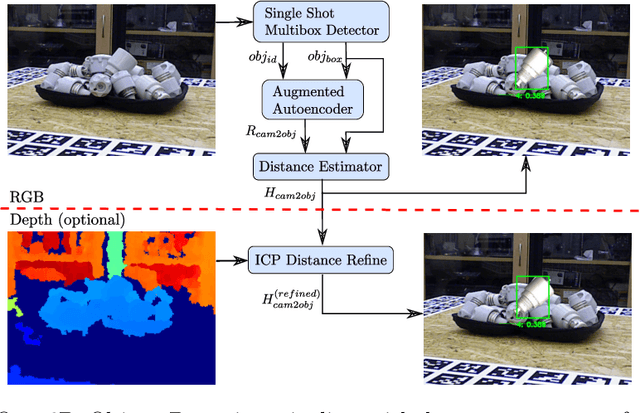

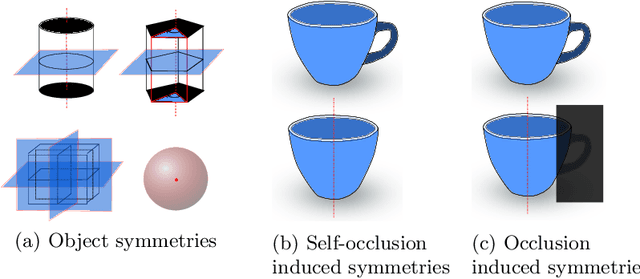
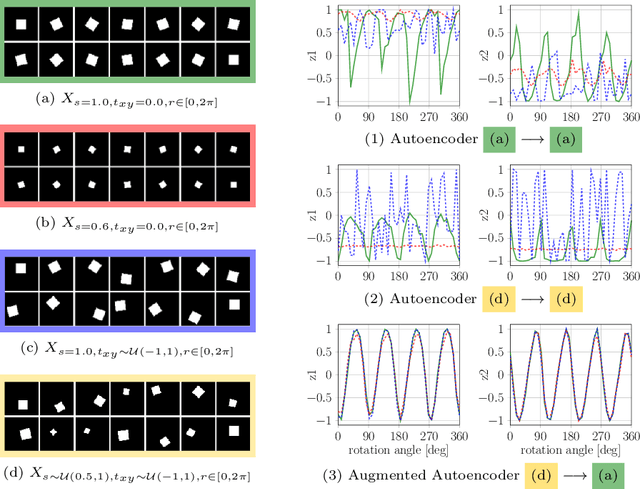
We propose a real-time RGB-based pipeline for object detection and 6D pose estimation. Our novel 3D orientation estimation is based on a variant of the Denoising Autoencoder that is trained on simulated views of a 3D model using Domain Randomization. This so-called Augmented Autoencoder has several advantages over existing methods: It does not require real, pose-annotated training data, generalizes to various test sensors and inherently handles object and view symmetries. Instead of learning an explicit mapping from input images to object poses, it provides an implicit representation of object orientations defined by samples in a latent space. Experiments on the T-LESS and LineMOD datasets show that our method outperforms similar model-based approaches and competes with state-of-the art approaches that require real pose-annotated images.
* Code available at: https://github.com/DLR-RM/AugmentedAutoencoder