 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExact Optimization of Conformal Predictors via Incremental and Decremental Learning
Feb 05, 2021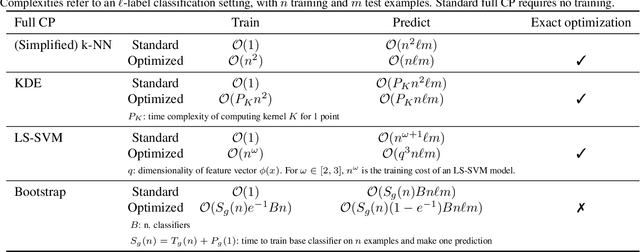
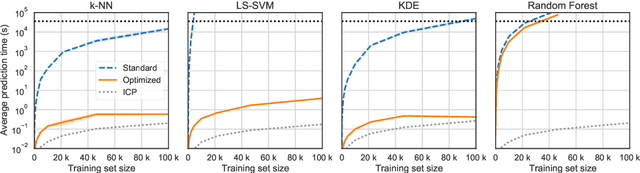
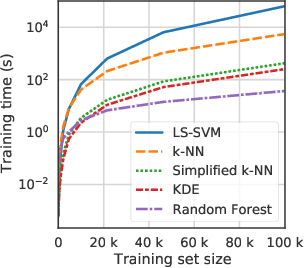
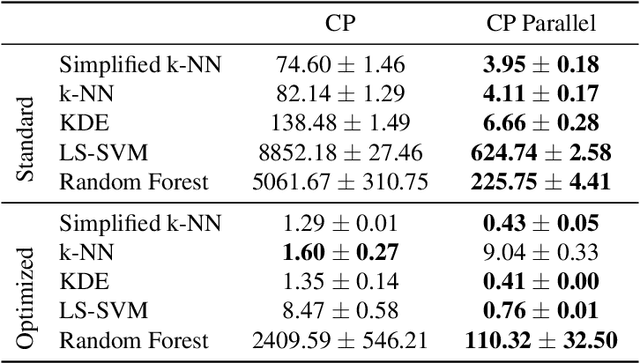
Conformal Predictors (CP) are wrappers around ML methods, providing error guarantees under weak assumptions on the data distribution. They are suitable for a wide range of problems, from classification and regression to anomaly detection. Unfortunately, their high computational complexity limits their applicability to large datasets. In this work, we show that it is possible to speed up a CP classifier considerably, by studying it in conjunction with the underlying ML method, and by exploiting incremental&decremental learning. For methods such as k-NN, KDE, and kernel LS-SVM, our approach reduces the running time by one order of magnitude, whilst producing exact solutions. With similar ideas, we also achieve a linear speed up for the harder case of bootstrapping. Finally, we extend these techniques to improve upon an optimization of k-NN CP for regression. We evaluate our findings empirically, and discuss when methods are suitable for CP optimization.
Learning from History for Byzantine Robust Optimization
Dec 18, 2020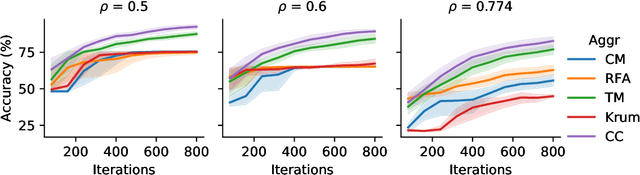
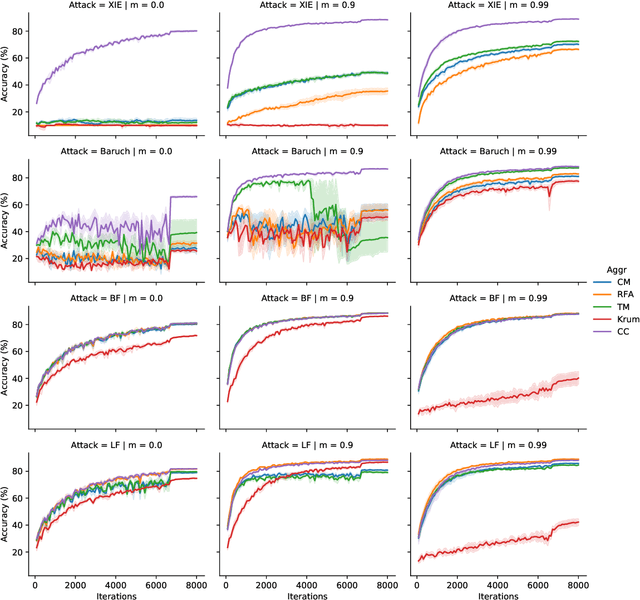
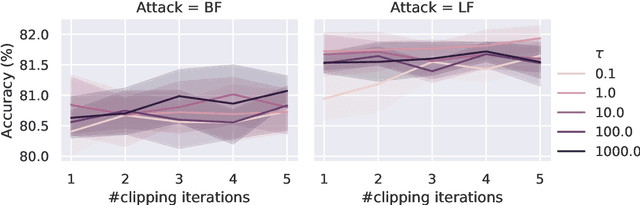
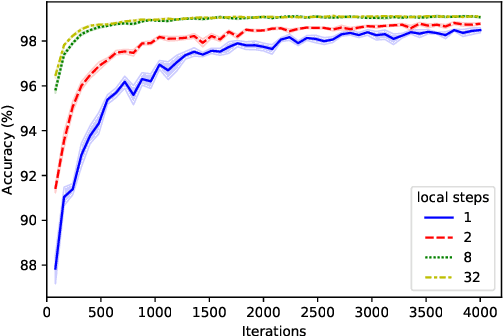
Byzantine robustness has received significant attention recently given its importance for distributed and federated learning. In spite of this, we identify severe flaws in existing algorithms even when the data across the participants is assumed to be identical. First, we show that most existing robust aggregation rules may not converge even in the absence of any Byzantine attackers, because they are overly sensitive to the distribution of the noise in the stochastic gradients. Secondly, we show that even if the aggregation rules may succeed in limiting the influence of the attackers in a single round, the attackers can couple their attacks across time eventually leading to divergence. To address these issues, we present two surprisingly simple strategies: a new iterative clipping procedure, and incorporating worker momentum to overcome time-coupled attacks. This is the first provably robust method for the standard stochastic non-convex optimization setting.
A Linearly Convergent Algorithm for Decentralized Optimization: Sending Less Bits for Free!
Nov 03, 2020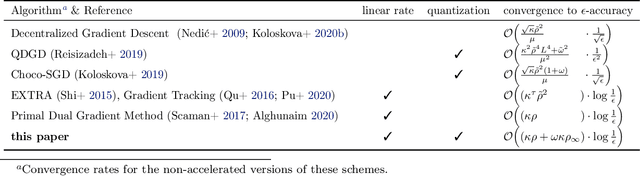
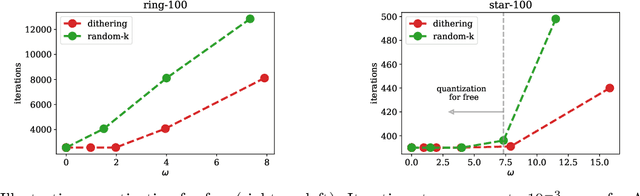

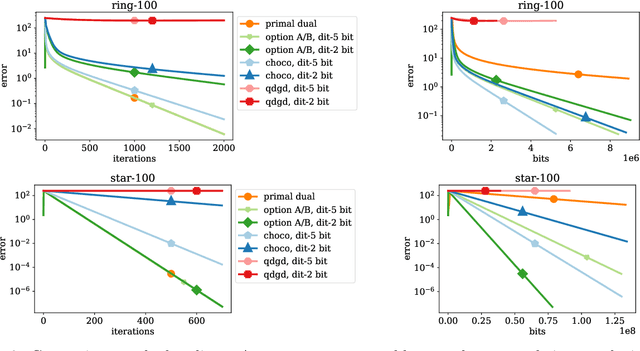
Decentralized optimization methods enable on-device training of machine learning models without a central coordinator. In many scenarios communication between devices is energy demanding and time consuming and forms the bottleneck of the entire system. We propose a new randomized first-order method which tackles the communication bottleneck by applying randomized compression operators to the communicated messages. By combining our scheme with a new variance reduction technique that progressively throughout the iterations reduces the adverse effect of the injected quantization noise, we obtain the first scheme that converges linearly on strongly convex decentralized problems while using compressed communication only. We prove that our method can solve the problems without any increase in the number of communications compared to the baseline which does not perform any communication compression while still allowing for a significant compression factor which depends on the conditioning of the problem and the topology of the network. Our key theoretical findings are supported by numerical experiments.
Sparse Communication for Training Deep Networks
Sep 19, 2020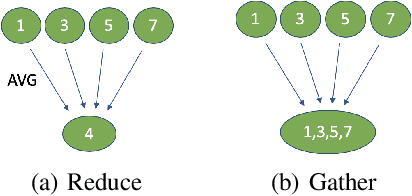
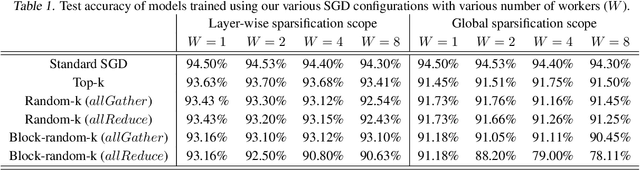
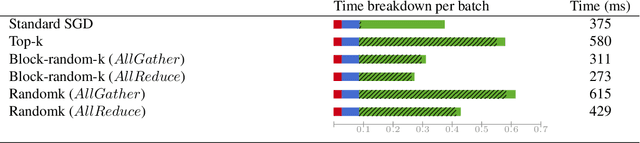
Synchronous stochastic gradient descent (SGD) is the most common method used for distributed training of deep learning models. In this algorithm, each worker shares its local gradients with others and updates the parameters using the average gradients of all workers. Although distributed training reduces the computation time, the communication overhead associated with the gradient exchange forms a scalability bottleneck for the algorithm. There are many compression techniques proposed to reduce the number of gradients that needs to be communicated. However, compressing the gradients introduces yet another overhead to the problem. In this work, we study several compression schemes and identify how three key parameters affect the performance. We also provide a set of insights on how to increase performance and introduce a simple sparsification scheme, random-block sparsification, that reduces communication while keeping the performance close to standard SGD.
Mime: Mimicking Centralized Stochastic Algorithms in Federated Learning
Aug 08, 2020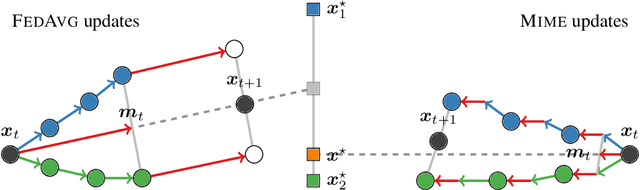

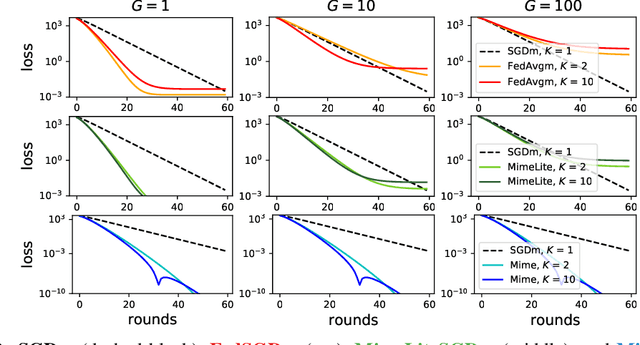

Federated learning is a challenging optimization problem due to the heterogeneity of the data across different clients. Such heterogeneity has been observed to induce client drift and significantly degrade the performance of algorithms designed for this setting. In contrast, centralized learning with centrally collected data does not experience such drift, and has seen great empirical and theoretical progress with innovations such as momentum, adaptivity, etc. In this work, we propose a general framework Mime which mitigates client-drift and adapts arbitrary centralized optimization algorithms (e.g.\ SGD, Adam, etc.) to federated learning. Mime uses a combination of control-variates and server-level statistics (e.g. momentum) at every client-update step to ensure that each local update mimics that of the centralized method. Our thorough theoretical and empirical analyses strongly establish Mime's superiority over other baselines.
PowerGossip: Practical Low-Rank Communication Compression in Decentralized Deep Learning
Aug 04, 2020Lossy gradient compression has become a practical tool to overcome the communication bottleneck in centrally coordinated distributed training of machine learning models. However, algorithms for decentralized training with compressed communication over arbitrary connected networks have been more complicated, requiring additional memory and hyperparameters. We introduce a simple algorithm that directly compresses the model differences between neighboring workers using low-rank linear compressors applied on model differences. Inspired by the PowerSGD algorithm for centralized deep learning, this algorithm uses power iteration steps to maximize the information transferred per bit. We prove that our method requires no additional hyperparameters, converges faster than prior methods, and is asymptotically independent of both the network and the compression. Out of the box, these compressors perform on par with state-of-the-art tuned compression algorithms in a series of deep learning benchmarks.
Multi-Head Attention: Collaborate Instead of Concatenate
Jun 29, 2020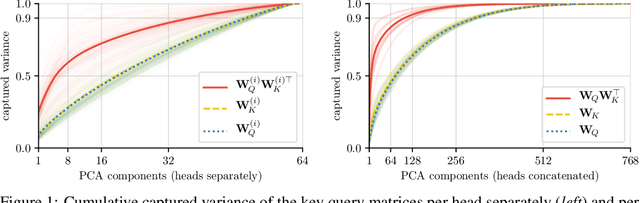
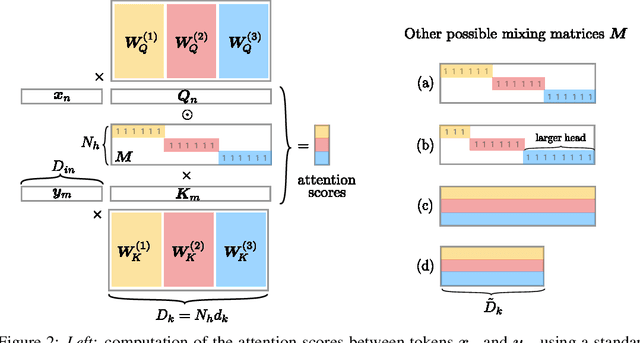
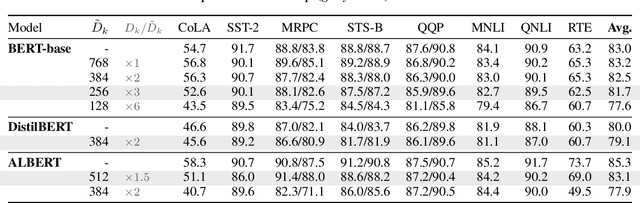

Attention layers are widely used in natural language processing (NLP) and are beginning to influence computer vision architectures. However, they suffer from over-parameterization. For instance, it was shown that the majority of attention heads could be pruned without impacting accuracy. This work aims to enhance current understanding on how multiple heads interact. Motivated by the observation that trained attention heads share common key/query projections, we propose a collaborative multi-head attention layer that enables heads to learn shared projections. Our scheme improves the computational cost and number of parameters in an attention layer and can be used as a drop-in replacement in any transformer architecture. For instance, by allowing heads to collaborate on a neural machine translation task, we can reduce the key dimension by a factor of eight without any loss in performance. We also show that it is possible to re-parametrize a pre-trained multi-head attention layer into our collaborative attention layer. Even without retraining, collaborative multi-head attention manages to reduce the size of the key and query projections by half without sacrificing accuracy. Our code is public.
Taming GANs with Lookahead
Jun 25, 2020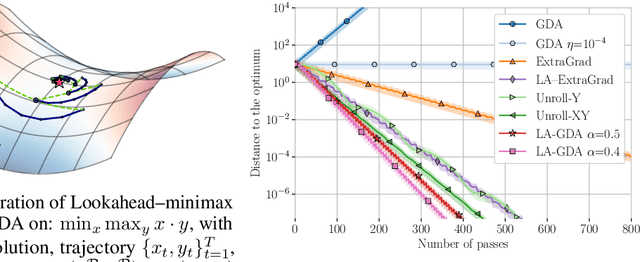
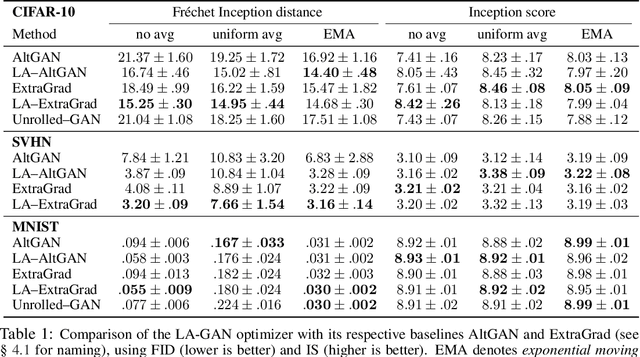


Generative Adversarial Networks are notoriously challenging to train. The underlying minimax optimization is highly susceptible to the variance of the stochastic gradient and the rotational component of the associated game vector field. We empirically demonstrate the effectiveness of the Lookahead meta-optimization method for optimizing games, originally proposed for standard minimization. The backtracking step of Lookahead naturally handles the rotational game dynamics, which in turn enables the gradient ascent descent method to converge on challenging toy games often analyzed in the literature. Moreover, it implicitly handles high variance without using large mini-batches, known to be essential for reaching state of the art performance. Experimental results on MNIST, SVHN, and CIFAR-10, demonstrate a clear advantage of combining Lookahead with Adam or extragradient, in terms of performance, memory footprint, and improved stability. Using 30-fold fewer parameters and 16-fold smaller minibatches we outperform the reported performance of the class-dependent BigGAN on CIFAR-10 by obtaining FID of $13.65$ \emph{without} using the class labels, bringing state-of-the-art GAN training within reach of common computational resources.
Byzantine-Robust Learning on Heterogeneous Datasets via Resampling
Jun 23, 2020

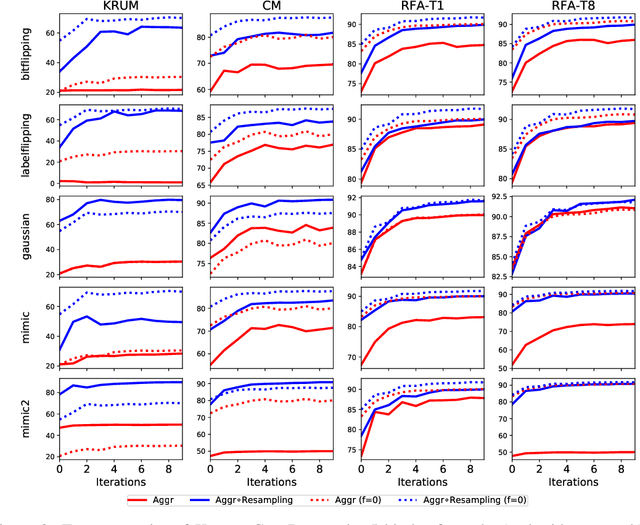
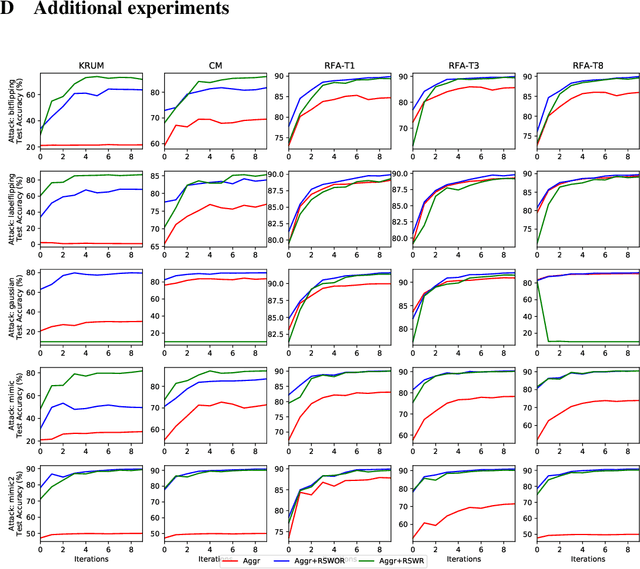
In Byzantine robust distributed optimization, a central server wants to train a machine learning model over data distributed across multiple workers. However, a fraction of these workers may deviate from the prescribed algorithm and send arbitrary messages to the server. While this problem has received significant attention recently, most current defenses assume that the workers have identical data. For realistic cases when the data across workers is heterogeneous (non-iid), we design new attacks which circumvent these defenses leading to significant loss of performance. We then propose a simple resampling scheme that adapts existing robust algorithms to heterogeneous datasets at a negligible computational cost. We theoretically and experimentally validate our approach, showing that combining resampling with existing robust algorithms is effective against challenging attacks.
Dynamic Model Pruning with Feedback
Jun 12, 2020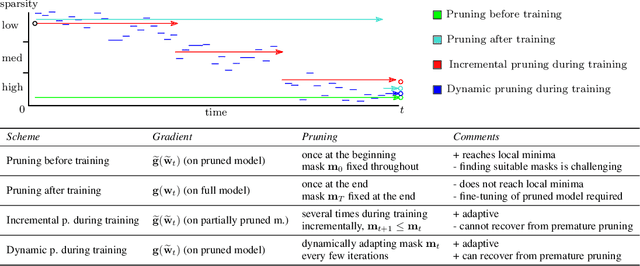
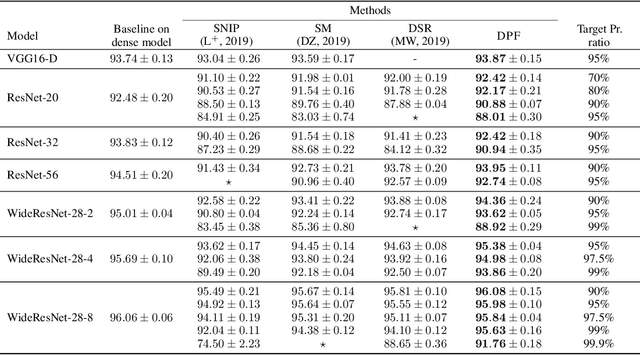
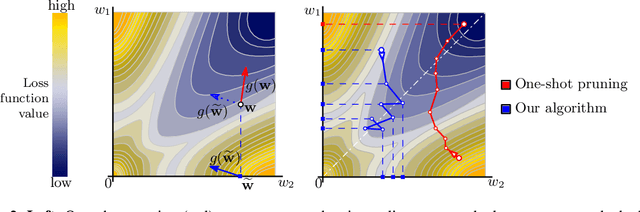
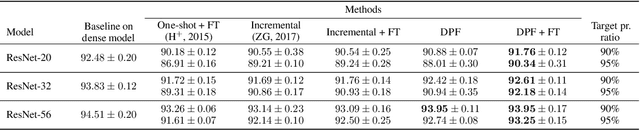
Deep neural networks often have millions of parameters. This can hinder their deployment to low-end devices, not only due to high memory requirements but also because of increased latency at inference. We propose a novel model compression method that generates a sparse trained model without additional overhead: by allowing (i) dynamic allocation of the sparsity pattern and (ii) incorporating feedback signal to reactivate prematurely pruned weights we obtain a performant sparse model in one single training pass (retraining is not needed, but can further improve the performance). We evaluate our method on CIFAR-10 and ImageNet, and show that the obtained sparse models can reach the state-of-the-art performance of dense models. Moreover, their performance surpasses that of models generated by all previously proposed pruning schemes.