 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Gaussian Processes for Few-Shot Segmentation
Mar 30, 2021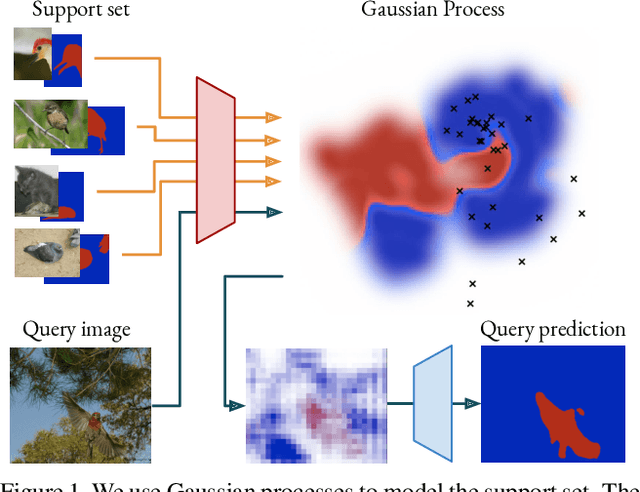
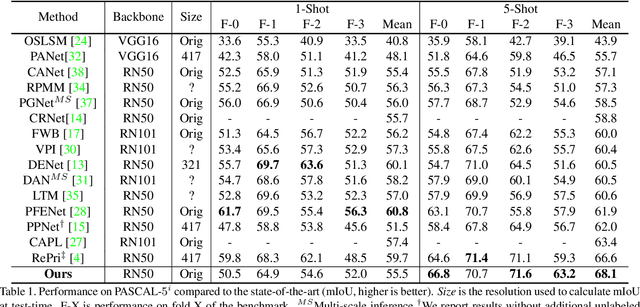
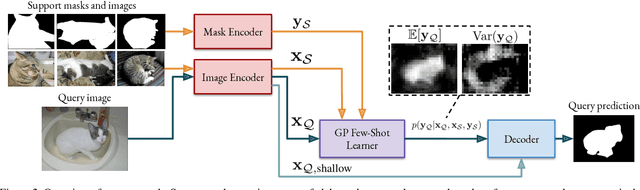
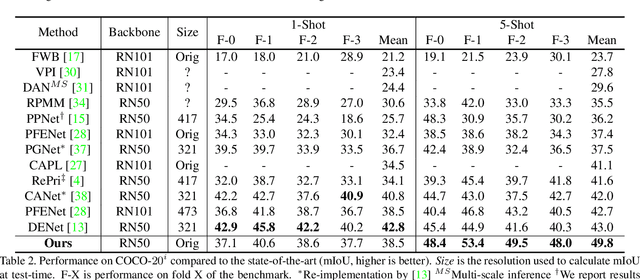
Few-shot segmentation is a challenging task, requiring the extraction of a generalizable representation from only a few annotated samples, in order to segment novel query images. A common approach is to model each class with a single prototype. While conceptually simple, these methods suffer when the target appearance distribution is multi-modal or not linearly separable in feature space. To tackle this issue, we propose a few-shot learner formulation based on Gaussian process (GP) regression. Through the expressivity of the GP, our approach is capable of modeling complex appearance distributions in the deep feature space. The GP provides a principled way of capturing uncertainty, which serves as another powerful cue for the final segmentation, obtained by a CNN decoder. We further exploit the end-to-end learning capabilities of our approach to learn the output space of the GP learner, ensuring a richer encoding of the segmentation mask. We perform comprehensive experimental analysis of our few-shot learner formulation. Our approach sets a new state-of-the-art for 5-shot segmentation, with mIoU scores of 68.1 and 49.8 on PASCAL-5i and COCO-20i, respectively
Deep Burst Super-Resolution
Jan 26, 2021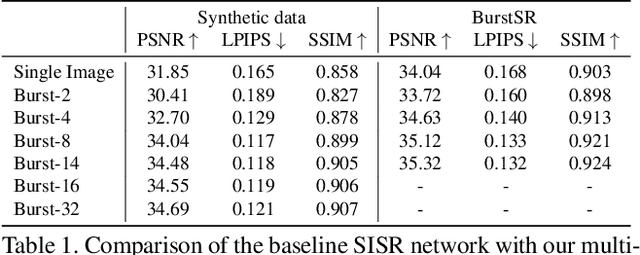
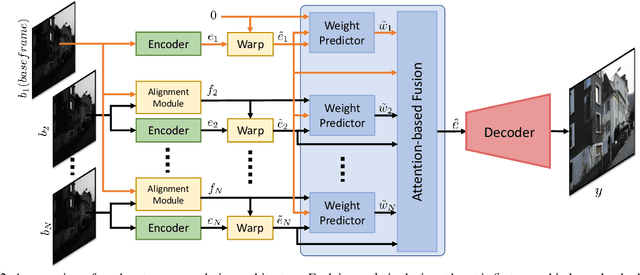
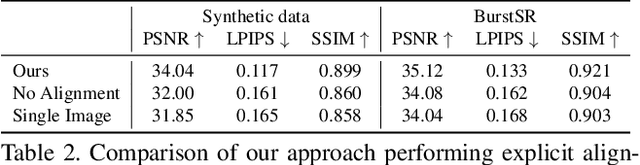
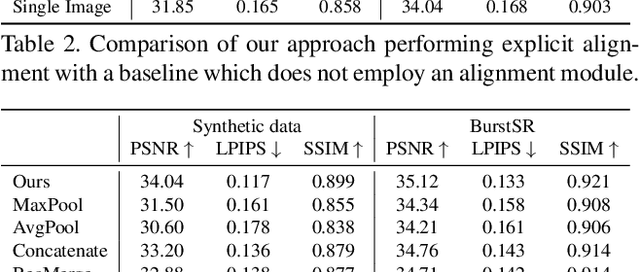
While single-image super-resolution (SISR) has attracted substantial interest in recent years, the proposed approaches are limited to learning image priors in order to add high frequency details. In contrast, multi-frame super-resolution (MFSR) offers the possibility of reconstructing rich details by combining signal information from multiple shifted images. This key advantage, along with the increasing popularity of burst photography, have made MFSR an important problem for real-world applications. We propose a novel architecture for the burst super-resolution task. Our network takes multiple noisy RAW images as input, and generates a denoised, super-resolved RGB image as output. This is achieved by explicitly aligning deep embeddings of the input frames using pixel-wise optical flow. The information from all frames are then adaptively merged using an attention-based fusion module. In order to enable training and evaluation on real-world data, we additionally introduce the BurstSR dataset, consisting of smartphone bursts and high-resolution DSLR ground-truth. We perform comprehensive experimental analysis, demonstrating the effectiveness of the proposed architecture.
DeFlow: Learning Complex Image Degradations from Unpaired Data with Conditional Flows
Jan 14, 2021
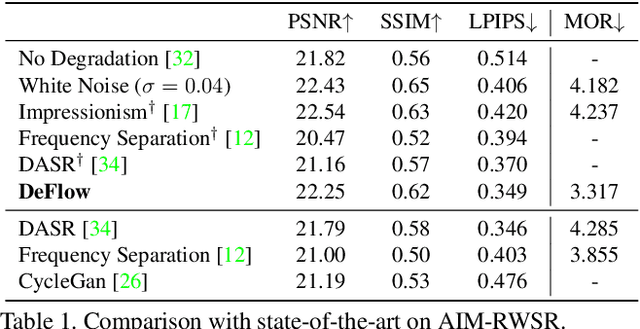
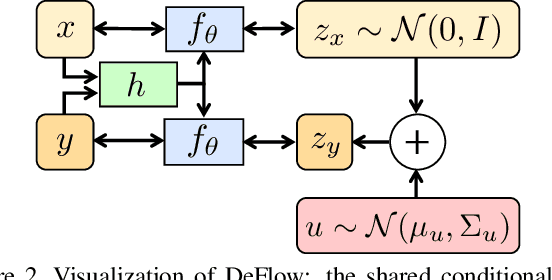
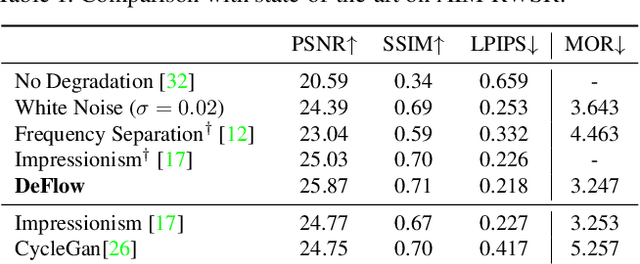
The difficulty of obtaining paired data remains a major bottleneck for learning image restoration and enhancement models for real-world applications. Current strategies aim to synthesize realistic training data by modeling noise and degradations that appear in real-world settings. We propose DeFlow, a method for learning stochastic image degradations from unpaired data. Our approach is based on a novel unpaired learning formulation for conditional normalizing flows. We model the degradation process in the latent space of a shared flow encoder-decoder network. This allows us to learn the conditional distribution of a noisy image given the clean input by solely minimizing the negative log-likelihood of the marginal distributions. We validate our DeFlow formulation on the task of joint image restoration and super-resolution. The models trained with the synthetic data generated by DeFlow outperform previous learnable approaches on all three datasets.
Generating Masks from Boxes by Mining Spatio-Temporal Consistencies in Videos
Jan 06, 2021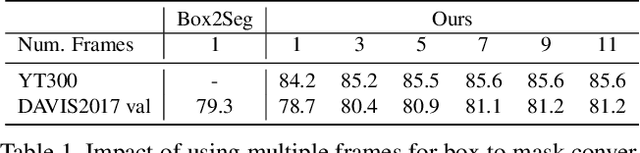
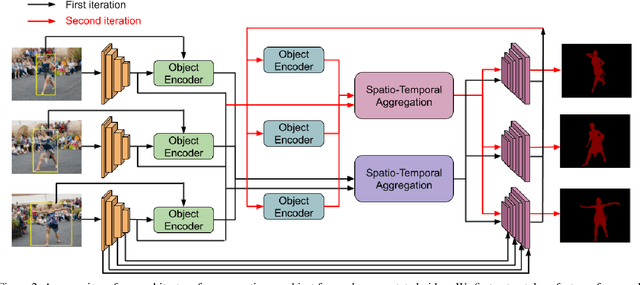


Segmenting objects in videos is a fundamental computer vision task. The current deep learning based paradigm offers a powerful, but data-hungry solution. However, current datasets are limited by the cost and human effort of annotating object masks in videos. This effectively limits the performance and generalization capabilities of existing video segmentation methods. To address this issue, we explore weaker form of bounding box annotations. We introduce a method for generating segmentation masks from per-frame bounding box annotations in videos. To this end, we propose a spatio-temporal aggregation module that effectively mines consistencies in the object and background appearance across multiple frames. We use our resulting accurate masks for weakly supervised training of video object segmentation (VOS) networks. We generate segmentation masks for large scale tracking datasets, using only their bounding box annotations. The additional data provides substantially better generalization performance leading to state-of-the-art results in both the VOS and more challenging tracking domain.
Local Memory Attention for Fast Video Semantic Segmentation
Jan 05, 2021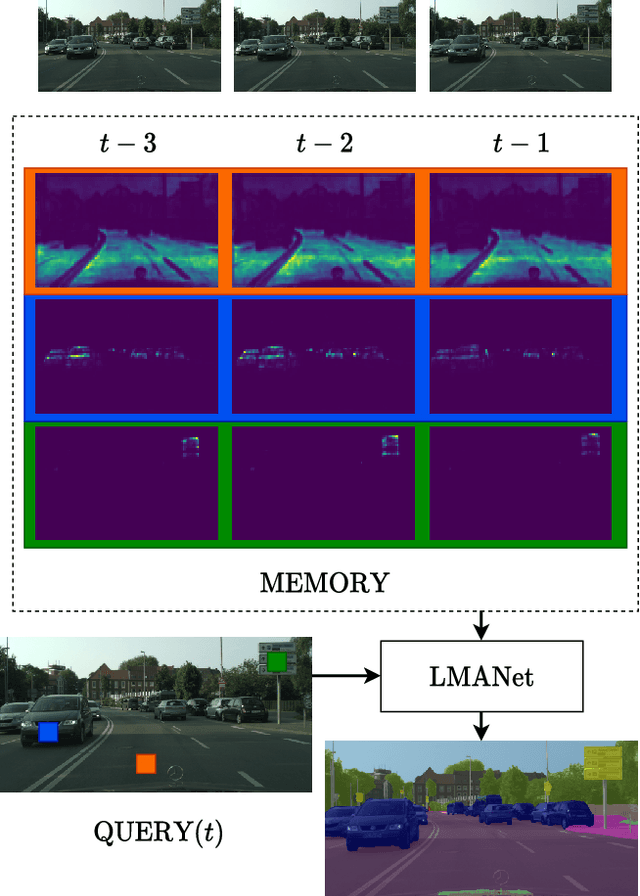
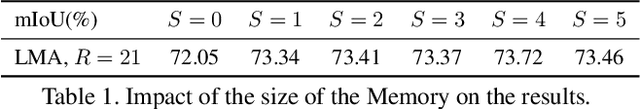

We propose a novel neural network module that transforms an existing single-frame semantic segmentation model into a video semantic segmentation pipeline. In contrast to prior works, we strive towards a simple and general module that can be integrated into virtually any single-frame architecture. Our approach aggregates a rich representation of the semantic information in past frames into a memory module. Information stored in the memory is then accessed through an attention mechanism. This provides temporal appearance cues from prior frames, which are then fused with an encoding of the current frame through a second attention-based module. The segmentation decoder processes the fused representation to predict the final semantic segmentation. We integrate our approach into two popular semantic segmentation networks: ERFNet and PSPNet. We observe an improvement in segmentation performance on Cityscapes by 1.7% and 2.1% in mIoU respectively, while increasing inference time of ERFNet by only 1.5ms.
Learning Accurate Dense Correspondences and When to Trust Them
Jan 05, 2021
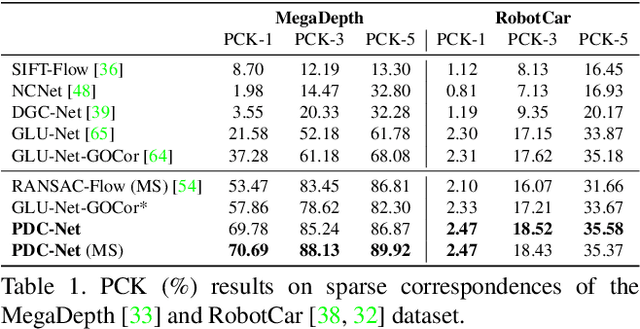

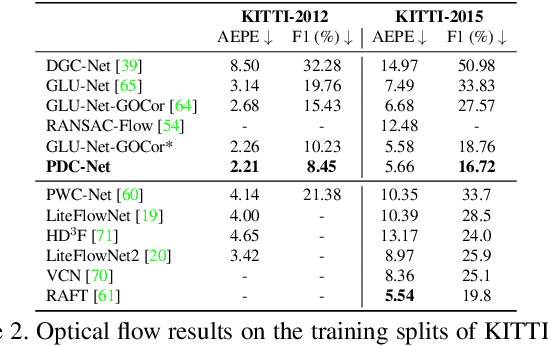
Establishing dense correspondences between a pair of images is an important and general problem. However, dense flow estimation is often inaccurate in the case of large displacements or homogeneous regions. For most applications and down-steam tasks, such as pose estimation, image manipulation, or 3D reconstruction, it is crucial to know when and where to trust the estimated correspondences. In this work, we aim to estimate a dense flow field relating two images, coupled with a robust pixel-wise confidence map indicating the reliability and accuracy of the prediction. We develop a flexible probabilistic approach that jointly learns the flow prediction and its uncertainty. In particular, we parametrize the predictive distribution as a constrained mixture model, ensuring better modelling of both accurate flow predictions and outliers. Moreover, we develop an architecture and training strategy tailored for robust and generalizable uncertainty prediction in the context of self-supervised training. Our approach obtains state-of-the-art results on multiple challenging geometric matching and optical flow datasets. We further validate the usefulness of our probabilistic confidence estimation for the task of pose estimation. Code and models will be released at github.com/PruneTruong/PDCNet.
Scaling Semantic Segmentation Beyond 1K Classes on a Single GPU
Dec 14, 2020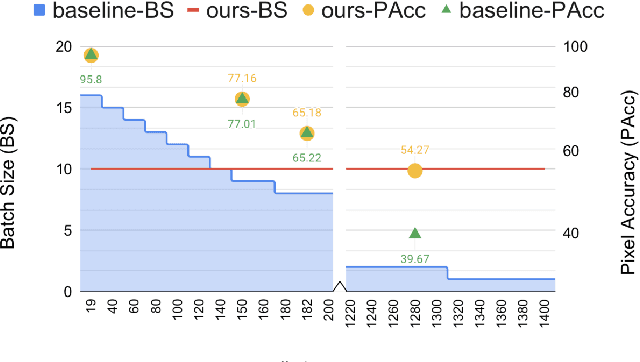
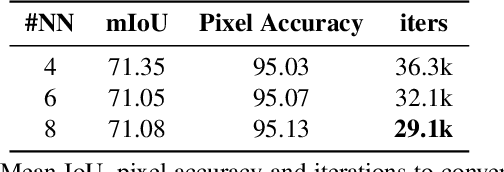
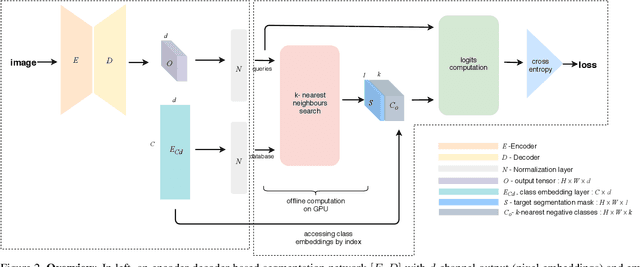

The state-of-the-art object detection and image classification methods can perform impressively on more than 9k and 10k classes, respectively. In contrast, the number of classes in semantic segmentation datasets is relatively limited. This is not surprising when the restrictions caused by the lack of labeled data and high computation demand for segmentation are considered. In this paper, we propose a novel training methodology to train and scale the existing semantic segmentation models for a large number of semantic classes without increasing the memory overhead. In our embedding-based scalable segmentation approach, we reduce the space complexity of the segmentation model's output from O(C) to O(1), propose an approximation method for ground-truth class probability, and use it to compute cross-entropy loss. The proposed approach is general and can be adopted by any state-of-the-art segmentation model to gracefully scale it for any number of semantic classes with only one GPU. Our approach achieves similar, and in some cases, even better mIoU for Cityscapes, Pascal VOC, ADE20k, COCO-Stuff10k datasets when adopted to DeeplabV3+ model with different backbones. We demonstrate a clear benefit of our approach on a dataset with 1284 classes, bootstrapped from LVIS and COCO annotations, with three times better mIoU than the DeeplabV3+ model.
Accurate 3D Object Detection using Energy-Based Models
Dec 08, 2020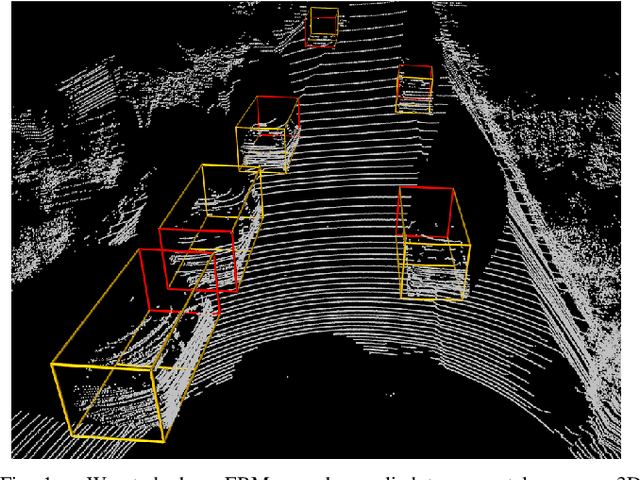
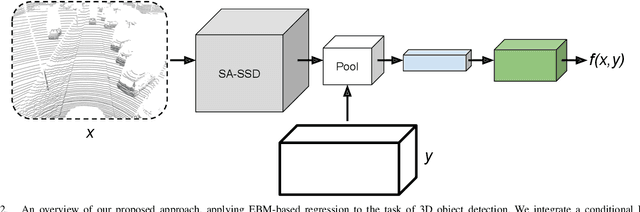
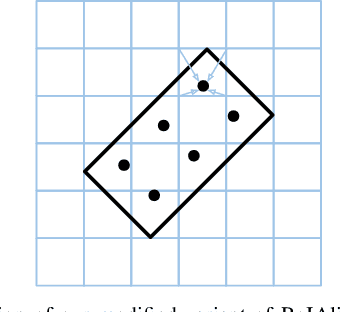
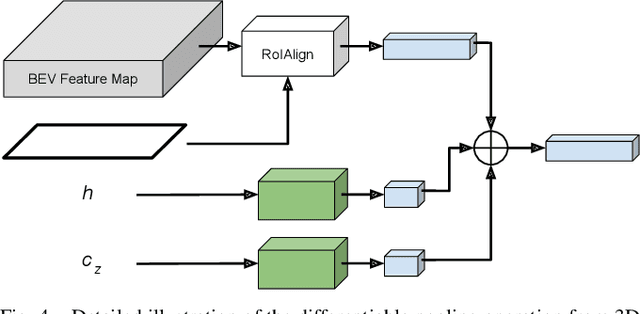
Accurate 3D object detection (3DOD) is crucial for safe navigation of complex environments by autonomous robots. Regressing accurate 3D bounding boxes in cluttered environments based on sparse LiDAR data is however a highly challenging problem. We address this task by exploring recent advances in conditional energy-based models (EBMs) for probabilistic regression. While methods employing EBMs for regression have demonstrated impressive performance on 2D object detection in images, these techniques are not directly applicable to 3D bounding boxes. In this work, we therefore design a differentiable pooling operator for 3D bounding boxes, serving as the core module of our EBM network. We further integrate this general approach into the state-of-the-art 3D object detector SA-SSD. On the KITTI dataset, our proposed approach consistently outperforms the SA-SSD baseline across all 3DOD metrics, demonstrating the potential of EBM-based regression for highly accurate 3DOD. Code is available at https://github.com/fregu856/ebms_3dod.
Learning Video Instance Segmentation with Recurrent Graph Neural Networks
Dec 07, 2020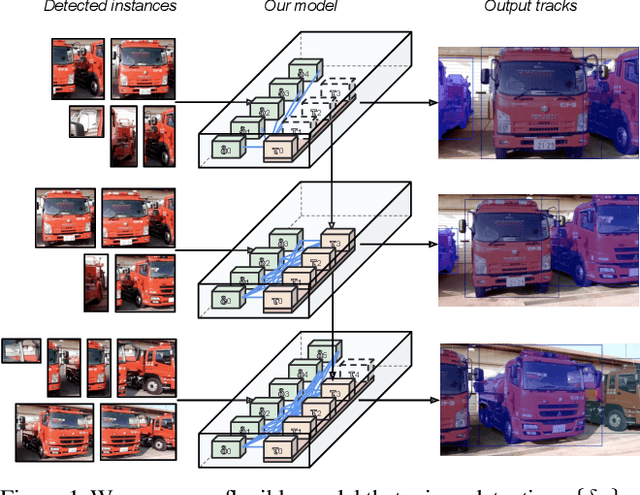
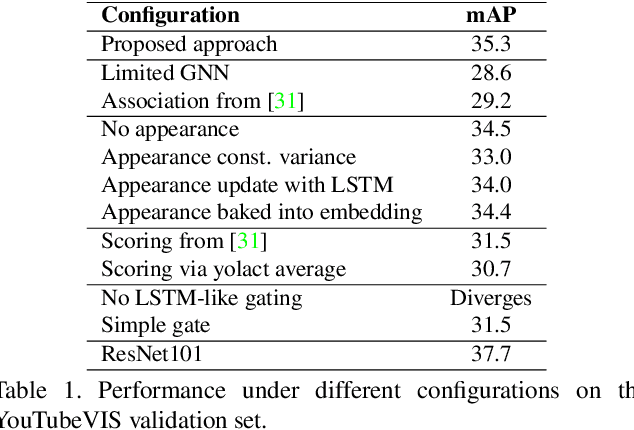
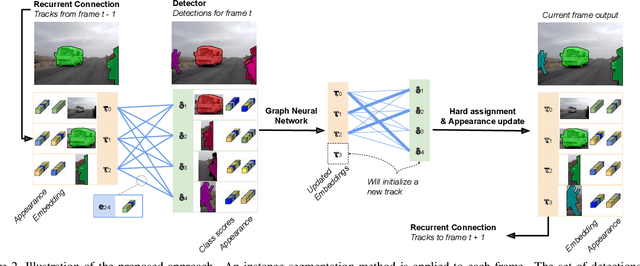
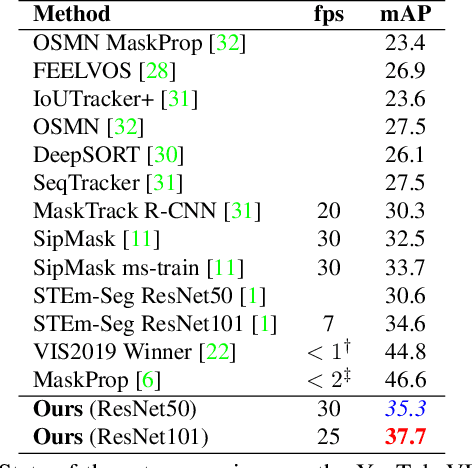
Most existing approaches to video instance segmentation comprise multiple modules that are heuristically combined to produce the final output. Formulating a purely learning-based method instead, which models both the temporal aspect as well as a generic track management required to solve the video instance segmentation task, is a highly challenging problem. In this work, we propose a novel learning formulation, where the entire video instance segmentation problem is modelled jointly. We fit a flexible model to our formulation that, with the help of a graph neural network, processes all available new information in each frame. Past information is considered and processed via a recurrent connection. We demonstrate the effectiveness of the proposed approach in comprehensive experiments. Our approach, operating at over 25 FPS, outperforms previous video real-time methods. We further conduct detailed ablative experiments that validate the different aspects of our approach.
Few-Shot Classification By Few-Iteration Meta-Learning
Oct 01, 2020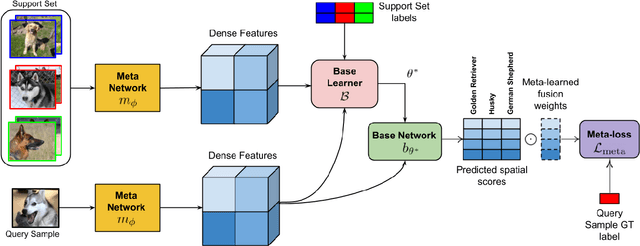
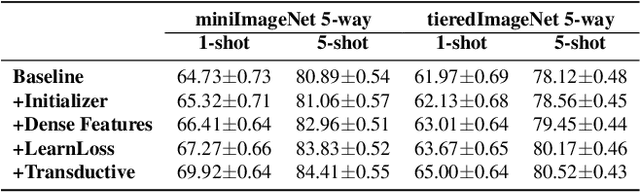

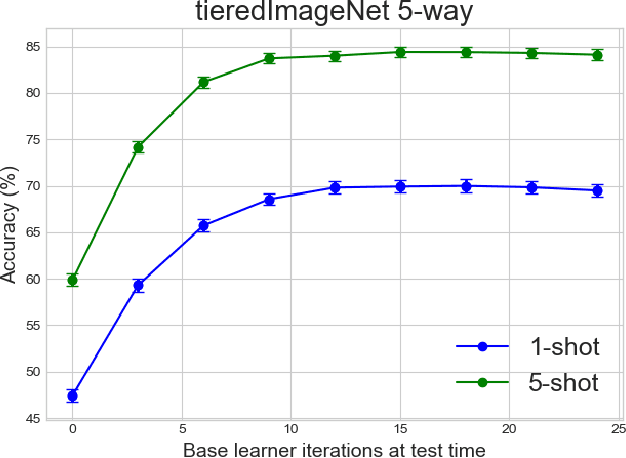
Learning in a low-data regime from only a few labeled examples is an important, but challenging problem. Recent advancements within meta-learning have demonstrated encouraging performance, in particular, for the task of few-shot classification. We propose a novel optimization-based meta-learning approach for few-shot classification. It consists of an embedding network, providing a general representation of the image, and a base learner module. The latter learns a linear classifier during the inference through an unrolled optimization procedure. We design an inner learning objective composed of (i) a robust classification loss on the support set and (ii) an entropy loss, allowing transductive learning from unlabeled query samples. By employing an efficient initialization module and a Steepest Descent based optimization algorithm, our base learner predicts a powerful classifier within only a few iterations. Further, our strategy enables important aspects of the base learner objective to be learned during meta-training. To the best of our knowledge, this work is the first to integrate both induction and transduction into the base learner in an optimization-based meta-learning framework. We perform a comprehensive experimental analysis, demonstrating the effectiveness of our approach on four few-shot classification datasets.