 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Auxiliary Task Learning
Feb 22, 2022
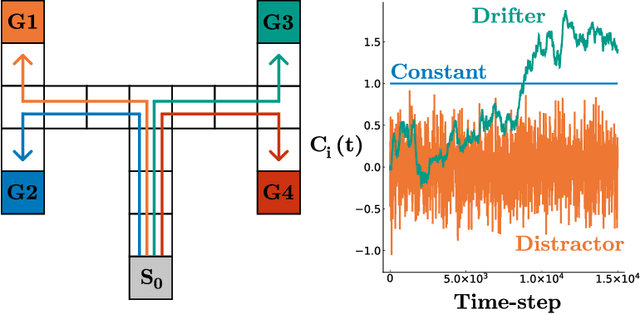
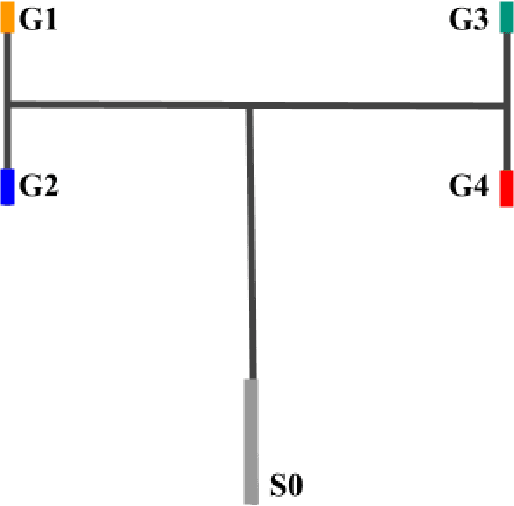
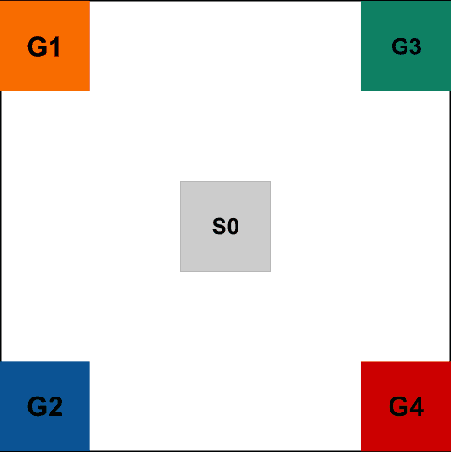
Learning auxiliary tasks, such as multiple predictions about the world, can provide many benefits to reinforcement learning systems. A variety of off-policy learning algorithms have been developed to learn such predictions, but as yet there is little work on how to adapt the behavior to gather useful data for those off-policy predictions. In this work, we investigate a reinforcement learning system designed to learn a collection of auxiliary tasks, with a behavior policy learning to take actions to improve those auxiliary predictions. We highlight the inherent non-stationarity in this continual auxiliary task learning problem, for both prediction learners and the behavior learner. We develop an algorithm based on successor features that facilitates tracking under non-stationary rewards, and prove the separation into learning successor features and rewards provides convergence rate improvements. We conduct an in-depth study into the resulting multi-prediction learning system.
A Temporal-Difference Approach to Policy Gradient Estimation
Feb 04, 2022
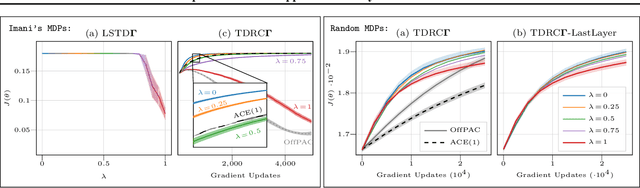
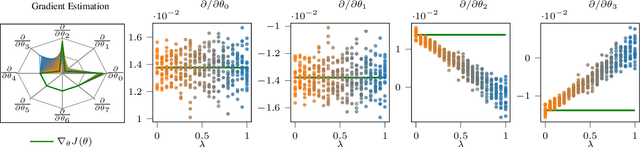
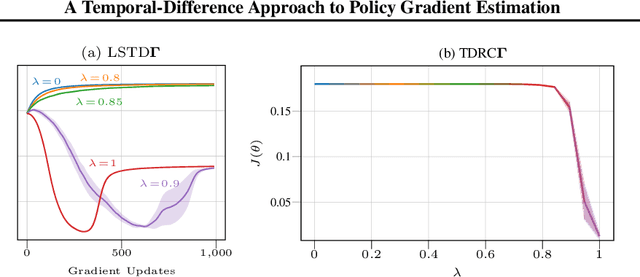
The policy gradient theorem (Sutton et al., 2000) prescribes the usage of a cumulative discounted state distribution under the target policy to approximate the gradient. Most algorithms based on this theorem, in practice, break this assumption, introducing a distribution shift that can cause the convergence to poor solutions. In this paper, we propose a new approach of reconstructing the policy gradient from the start state without requiring a particular sampling strategy. The policy gradient calculation in this form can be simplified in terms of a gradient critic, which can be recursively estimated due to a new Bellman equation of gradients. By using temporal-difference updates of the gradient critic from an off-policy data stream, we develop the first estimator that sidesteps the distribution shift issue in a model-free way. We prove that, under certain realizability conditions, our estimator is unbiased regardless of the sampling strategy. We empirically show that our technique achieves a superior bias-variance trade-off and performance in presence of off-policy samples.
An Alternate Policy Gradient Estimator for Softmax Policies
Dec 22, 2021
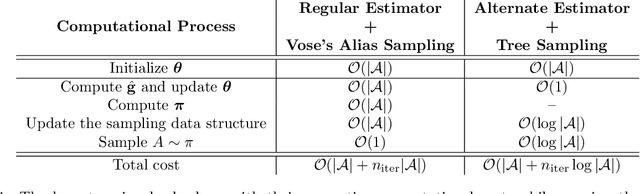
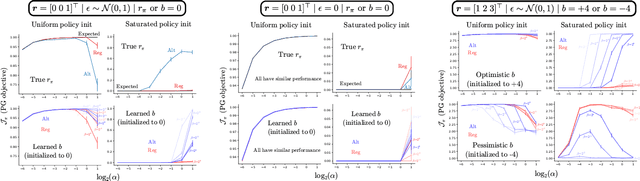
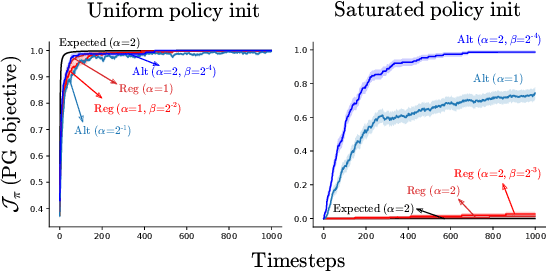
Policy gradient (PG) estimators for softmax policies are ineffective with sub-optimally saturated initialization, which happens when the density concentrates on a sub-optimal action. Sub-optimal policy saturation may arise from bad policy initialization or sudden changes in the environment that occur after the policy has already converged, and softmax PG estimators require a large number of updates to recover an effective policy. This severe issue causes high sample inefficiency and poor adaptability to new situations. To mitigate this problem, we propose a novel policy gradient estimator for softmax policies that utilizes the bias in the critic estimate and the noise present in the reward signal to escape the saturated regions of the policy parameter space. Our analysis and experiments, conducted on bandits and classical MDP benchmarking tasks, show that our estimator is more robust to policy saturation.
Understanding Feature Transfer Through Representation Alignment
Dec 15, 2021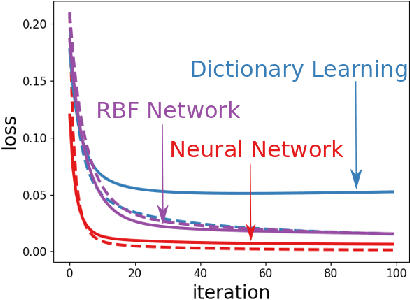
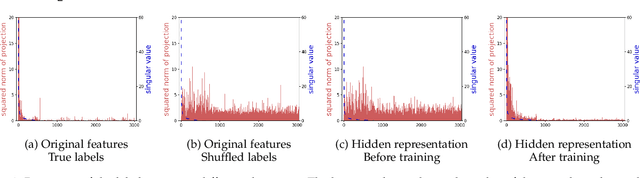

Training with the true labels of a dataset as opposed to randomized labels leads to faster optimization and better generalization. This difference is attributed to a notion of alignment between inputs and labels in natural datasets. We find that training neural networks with different architectures and optimizers on random or true labels enforces the same relationship between the hidden representations and the training labels, elucidating why neural network representations have been so successful for transfer. We first highlight why aligned features promote transfer and show in a classic synthetic transfer problem that alignment is the determining factor for positive and negative transfer to similar and dissimilar tasks. We then investigate a variety of neural network architectures and find that (a) alignment emerges across a variety of different architectures and optimizers, with more alignment arising from depth (b) alignment increases for layers closer to the output and (c) existing high-performance deep CNNs exhibit high levels of alignment.
Off-Policy Actor-Critic with Emphatic Weightings
Nov 16, 2021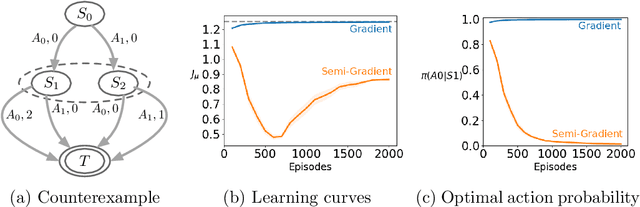
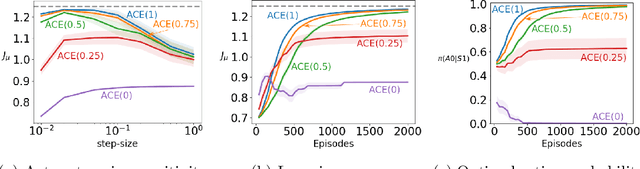
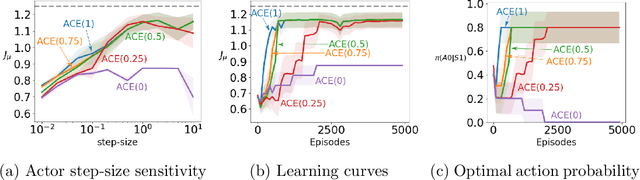
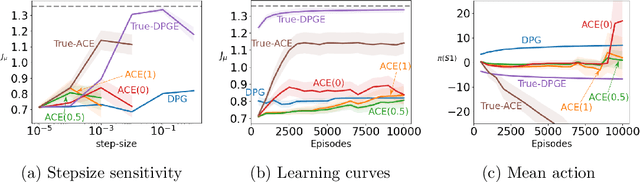
A variety of theoretically-sound policy gradient algorithms exist for the on-policy setting due to the policy gradient theorem, which provides a simplified form for the gradient. The off-policy setting, however, has been less clear due to the existence of multiple objectives and the lack of an explicit off-policy policy gradient theorem. In this work, we unify these objectives into one off-policy objective, and provide a policy gradient theorem for this unified objective. The derivation involves emphatic weightings and interest functions. We show multiple strategies to approximate the gradients, in an algorithm called Actor Critic with Emphatic weightings (ACE). We prove in a counterexample that previous (semi-gradient) off-policy actor-critic methods--particularly OffPAC and DPG--converge to the wrong solution whereas ACE finds the optimal solution. We also highlight why these semi-gradient approaches can still perform well in practice, suggesting strategies for variance reduction in ACE. We empirically study several variants of ACE on two classic control environments and an image-based environment designed to illustrate the tradeoffs made by each gradient approximation. We find that by approximating the emphatic weightings directly, ACE performs as well as or better than OffPAC in all settings tested.
Exploiting Action Impact Regularity and Partially Known Models for Offline Reinforcement Learning
Nov 15, 2021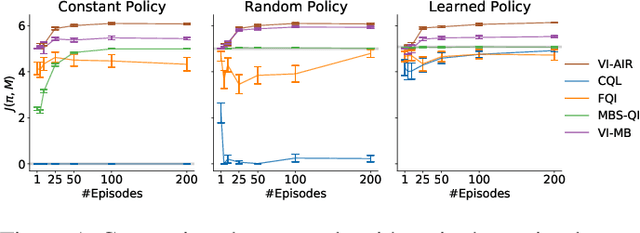
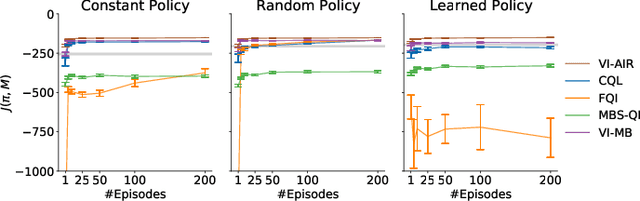
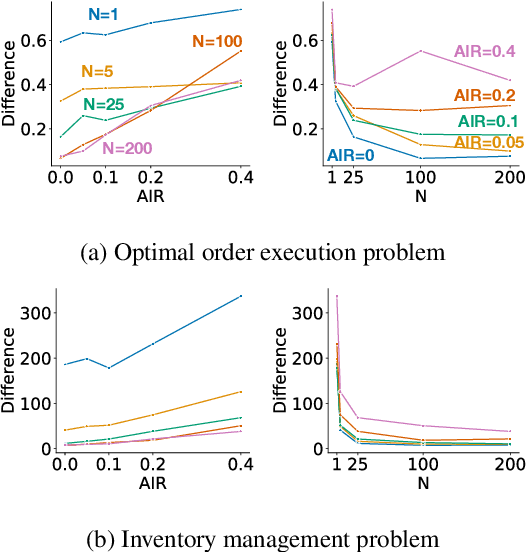
Offline reinforcement learning-learning a policy from a batch of data-is known to be hard: without making strong assumptions, it is easy to construct counterexamples such that existing algorithms fail. In this work, we instead consider a property of certain real world problems where offline reinforcement learning should be effective: those where actions only have limited impact for a part of the state. We formalize and introduce this Action Impact Regularity (AIR) property. We further propose an algorithm that assumes and exploits the AIR property, and bound the suboptimality of the output policy when the MDP satisfies AIR. Finally, we demonstrate that our algorithm outperforms existing offline reinforcement learning algorithms across different data collection policies in two simulated environments where the regularity holds.
Greedification Operators for Policy Optimization: Investigating Forward and Reverse KL Divergences
Jul 17, 2021

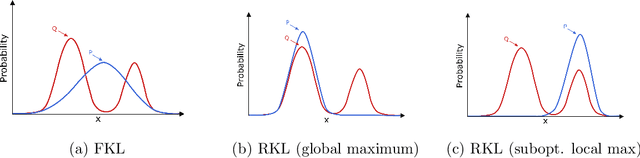

Approximate Policy Iteration (API) algorithms alternate between (approximate) policy evaluation and (approximate) greedification. Many different approaches have been explored for approximate policy evaluation, but less is understood about approximate greedification and what choices guarantee policy improvement. In this work, we investigate approximate greedification when reducing the KL divergence between the parameterized policy and the Boltzmann distribution over action values. In particular, we investigate the difference between the forward and reverse KL divergences, with varying degrees of entropy regularization. We show that the reverse KL has stronger policy improvement guarantees, but that reducing the forward KL can result in a worse policy. We also demonstrate, however, that a large enough reduction of the forward KL can induce improvement under additional assumptions. Empirically, we show on simple continuous-action environments that the forward KL can induce more exploration, but at the cost of a more suboptimal policy. No significant differences were observed in the discrete-action setting or on a suite of benchmark problems. Throughout, we highlight that many policy gradient methods can be seen as an instance of API, with either the forward or reverse KL for the policy update, and discuss next steps for understanding and improving our policy optimization algorithms.
Predictive Representation Learning for Language Modeling
May 29, 2021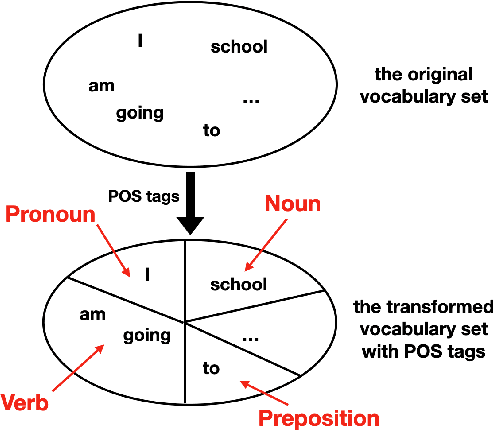
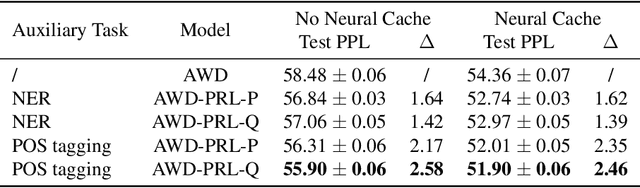
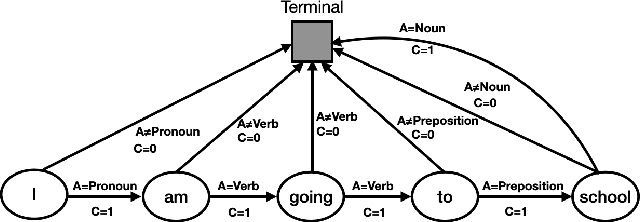
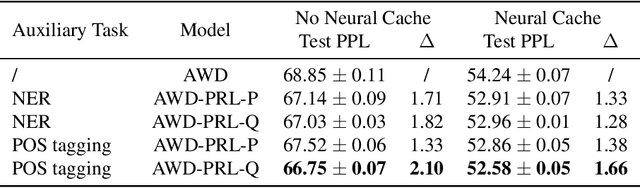
To effectively perform the task of next-word prediction, long short-term memory networks (LSTMs) must keep track of many types of information. Some information is directly related to the next word's identity, but some is more secondary (e.g. discourse-level features or features of downstream words). Correlates of secondary information appear in LSTM representations even though they are not part of an \emph{explicitly} supervised prediction task. In contrast, in reinforcement learning (RL), techniques that explicitly supervise representations to predict secondary information have been shown to be beneficial. Inspired by that success, we propose Predictive Representation Learning (PRL), which explicitly constrains LSTMs to encode specific predictions, like those that might need to be learned implicitly. We show that PRL 1) significantly improves two strong language modeling methods, 2) converges more quickly, and 3) performs better when data is limited. Our work shows that explicitly encoding a simple predictive task facilitates the search for a more effective language model.
A Generalized Projected Bellman Error for Off-policy Value Estimation in Reinforcement Learning
Apr 28, 2021
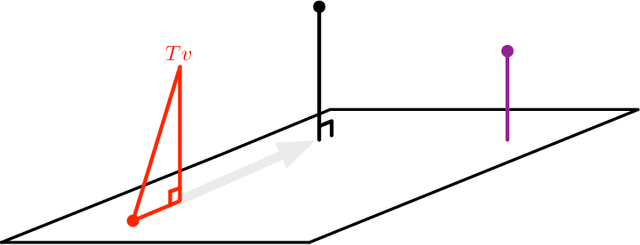

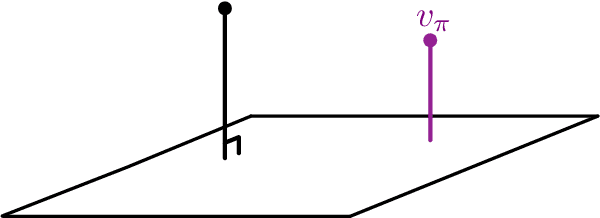
Many reinforcement learning algorithms rely on value estimation. However, the most widely used algorithms -- namely temporal difference algorithms -- can diverge under both off-policy sampling and nonlinear function approximation. Many algorithms have been developed for off-policy value estimation which are sound under linear function approximation, based on the linear mean-squared projected Bellman error (PBE). Extending these methods to the non-linear case has been largely unsuccessful. Recently, several methods have been introduced that approximate a different objective, called the mean-squared Bellman error (BE), which naturally facilities nonlinear approximation. In this work, we build on these insights and introduce a new generalized PBE, that extends the linear PBE to the nonlinear setting. We show how this generalized objective unifies previous work, including previous theory, and obtain new bounds for the value error of the solutions of the generalized objective. We derive an easy-to-use, but sound, algorithm to minimize the generalized objective which is more stable across runs, is less sensitive to hyperparameters, and performs favorably across four control domains with neural network function approximation.
Scalable Online Recurrent Learning Using Columnar Neural Networks
Mar 09, 2021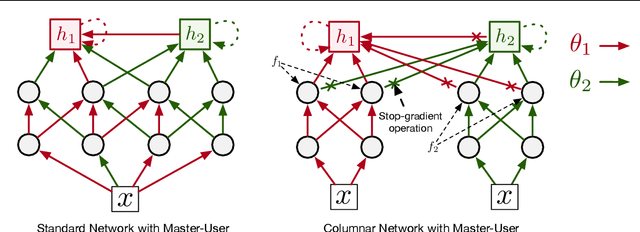
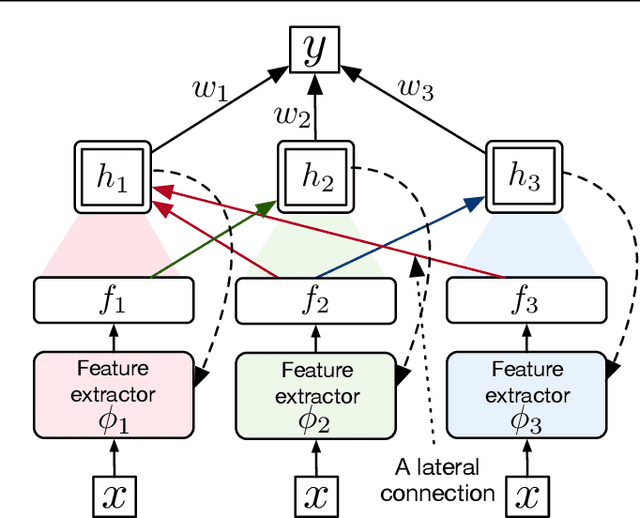
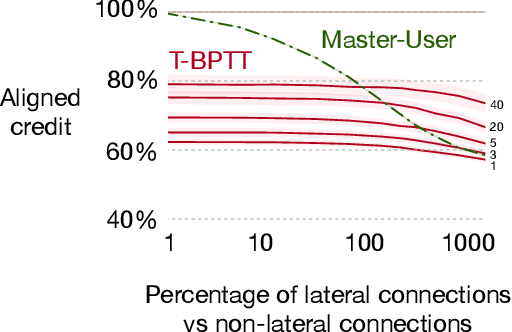
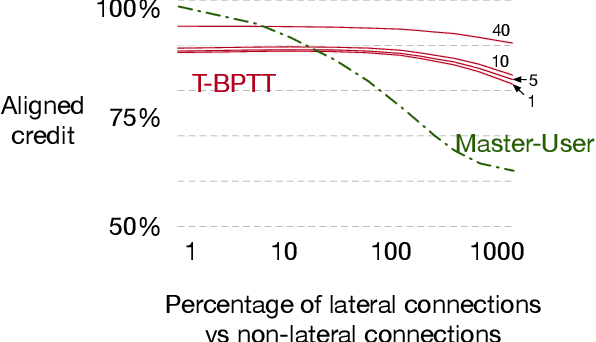
Structural credit assignment for recurrent learning is challenging. An algorithm called RTRL can compute gradients for recurrent networks online but is computationally intractable for large networks. Alternatives, such as BPTT, are not online. In this work, we propose a credit-assignment algorithm -- \algoname{} -- that approximates the gradients for recurrent learning in real-time using $O(n)$ operations and memory per-step. Our method builds on the idea that for modular recurrent networks, composed of columns with scalar states, it is sufficient for a parameter to only track its influence on the state of its column. We empirically show that as long as connections between columns are sparse, our method approximates the true gradient well. In the special case when there are no connections between columns, the $O(n)$ gradient estimate is exact. We demonstrate the utility of the approach for both recurrent state learning and meta-learning by comparing the estimated gradient to the true gradient on a synthetic test-bed.