 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Classifiers with Label Noise Modeling and Distance Awareness
Oct 06, 2021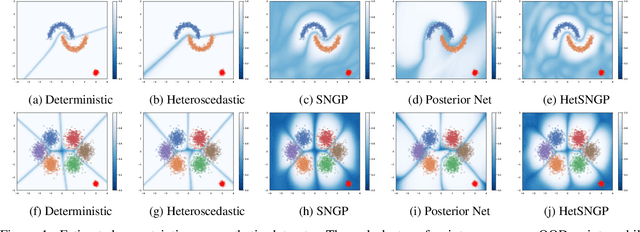



Uncertainty estimation in deep learning has recently emerged as a crucial area of interest to advance reliability and robustness in safety-critical applications. While there have been many proposed methods that either focus on distance-aware model uncertainties for out-of-distribution detection or on input-dependent label uncertainties for in-distribution calibration, both of these types of uncertainty are often necessary. In this work, we propose the HetSNGP method for jointly modeling the model and data uncertainty. We show that our proposed model affords a favorable combination between these two complementary types of uncertainty and thus outperforms the baseline methods on some challenging out-of-distribution datasets, including CIFAR-100C, Imagenet-C, and Imagenet-A. Moreover, we propose HetSNGP Ensemble, an ensembled version of our method which adds an additional type of uncertainty and also outperforms other ensemble baselines.
Uncertainty Baselines: Benchmarks for Uncertainty & Robustness in Deep Learning
Jun 07, 2021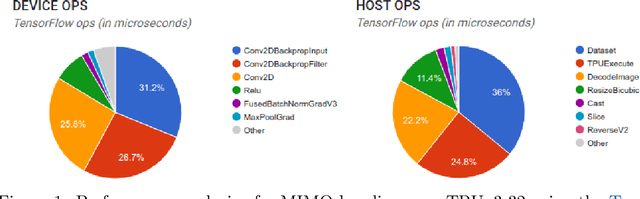
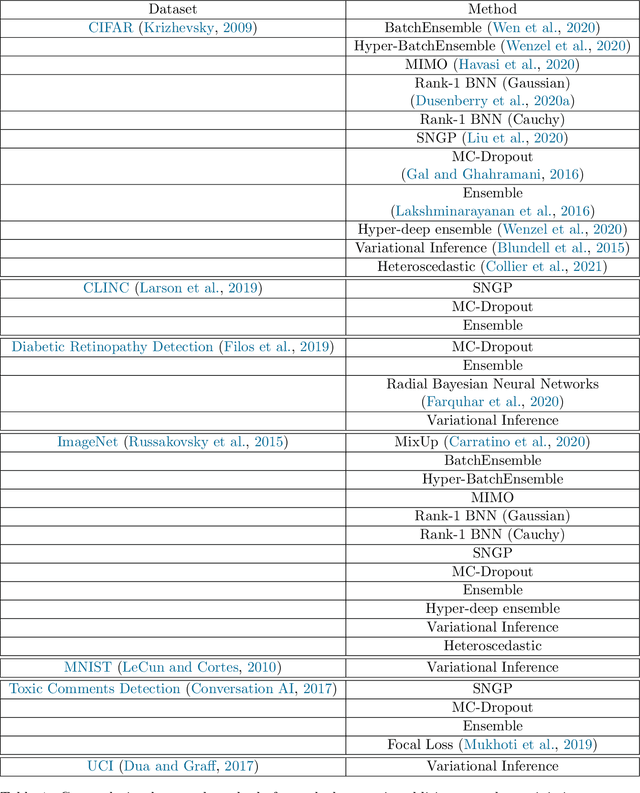
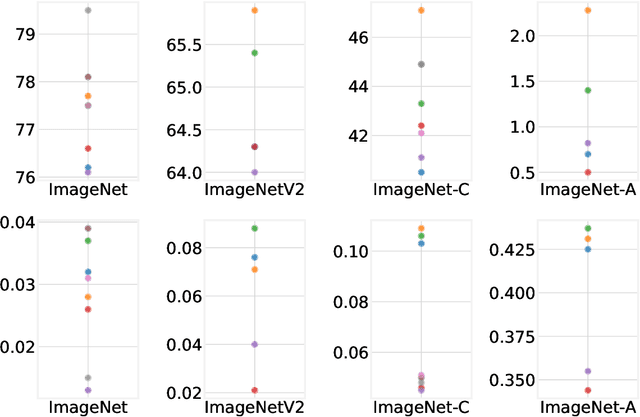
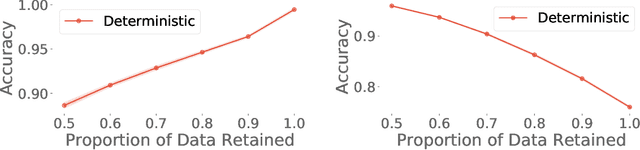
High-quality estimates of uncertainty and robustness are crucial for numerous real-world applications, especially for deep learning which underlies many deployed ML systems. The ability to compare techniques for improving these estimates is therefore very important for research and practice alike. Yet, competitive comparisons of methods are often lacking due to a range of reasons, including: compute availability for extensive tuning, incorporation of sufficiently many baselines, and concrete documentation for reproducibility. In this paper we introduce Uncertainty Baselines: high-quality implementations of standard and state-of-the-art deep learning methods on a variety of tasks. As of this writing, the collection spans 19 methods across 9 tasks, each with at least 5 metrics. Each baseline is a self-contained experiment pipeline with easily reusable and extendable components. Our goal is to provide immediate starting points for experimentation with new methods or applications. Additionally we provide model checkpoints, experiment outputs as Python notebooks, and leaderboards for comparing results. Code available at https://github.com/google/uncertainty-baselines.
Correlated Input-Dependent Label Noise in Large-Scale Image Classification
May 19, 2021

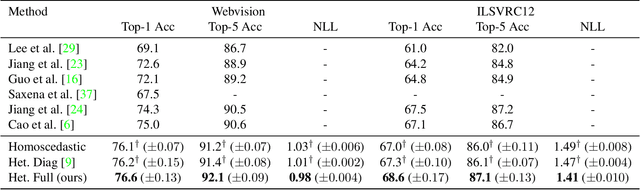
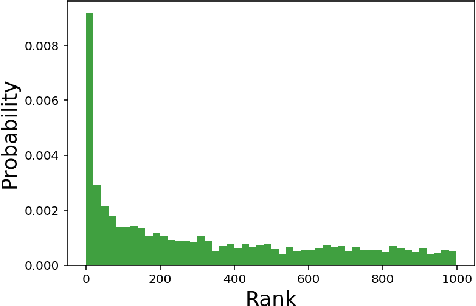
Large scale image classification datasets often contain noisy labels. We take a principled probabilistic approach to modelling input-dependent, also known as heteroscedastic, label noise in these datasets. We place a multivariate Normal distributed latent variable on the final hidden layer of a neural network classifier. The covariance matrix of this latent variable, models the aleatoric uncertainty due to label noise. We demonstrate that the learned covariance structure captures known sources of label noise between semantically similar and co-occurring classes. Compared to standard neural network training and other baselines, we show significantly improved accuracy on Imagenet ILSVRC 2012 79.3% (+2.6%), Imagenet-21k 47.0% (+1.1%) and JFT 64.7% (+1.6%). We set a new state-of-the-art result on WebVision 1.0 with 76.6% top-1 accuracy. These datasets range from over 1M to over 300M training examples and from 1k classes to more than 21k classes. Our method is simple to use, and we provide an implementation that is a drop-in replacement for the final fully-connected layer in a deep classifier.
Routing Networks with Co-training for Continual Learning
Sep 09, 2020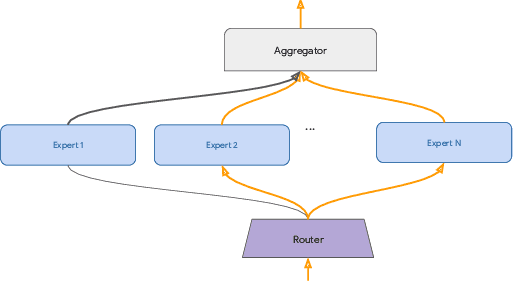

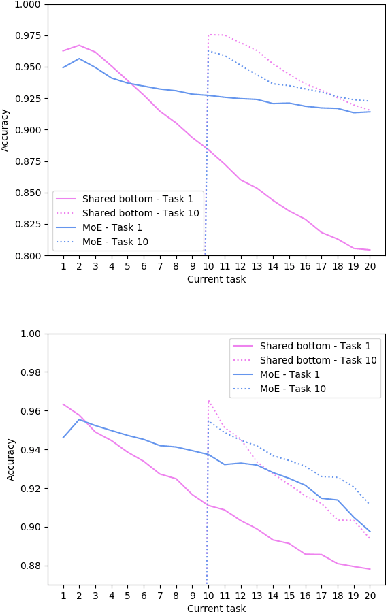
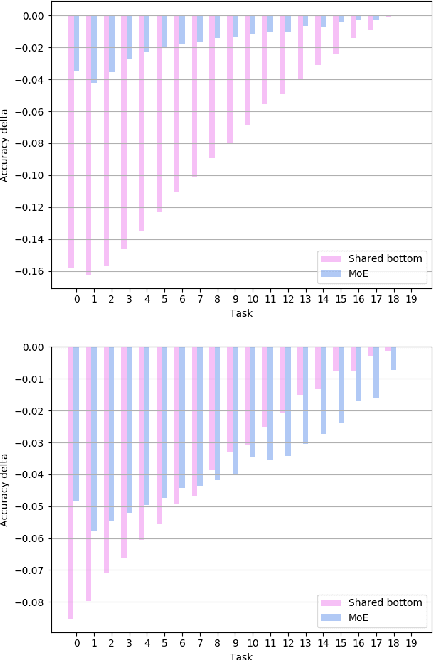
The core challenge with continual learning is catastrophic forgetting, the phenomenon that when neural networks are trained on a sequence of tasks they rapidly forget previously learned tasks. It has been observed that catastrophic forgetting is most severe when tasks are dissimilar to each other. We propose the use of sparse routing networks for continual learning. For each input, these network architectures activate a different path through a network of experts. Routing networks have been shown to learn to route similar tasks to overlapping sets of experts and dissimilar tasks to disjoint sets of experts. In the continual learning context this behaviour is desirable as it minimizes interference between dissimilar tasks while allowing positive transfer between related tasks. In practice, we find it is necessary to develop a new training method for routing networks, which we call co-training which avoids poorly initialized experts when new tasks are presented. When combined with a small episodic memory replay buffer, sparse routing networks with co-training outperform densely connected networks on the MNIST-Permutations and MNIST-Rotations benchmarks.
VAEs in the Presence of Missing Data
Jun 09, 2020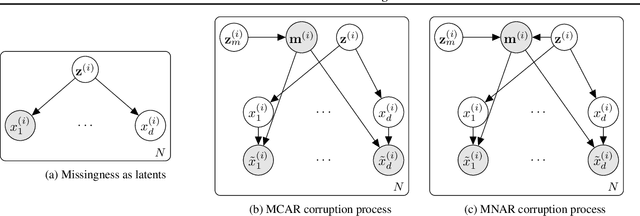


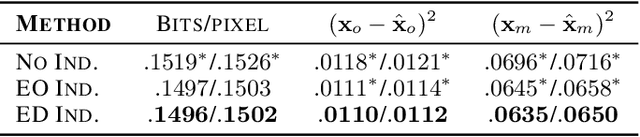
Real world datasets often contain entries with missing elements e.g. in a medical dataset, a patient is unlikely to have taken all possible diagnostic tests. Variational Autoencoders (VAEs) are popular generative models often used for unsupervised learning. Despite their widespread use it is unclear how best to apply VAEs to datasets with missing data. We develop a novel latent variable model of a corruption process which generates missing data, and derive a corresponding tractable evidence lower bound (ELBO). Our model is straightforward to implement, can handle both missing completely at random (MCAR) and missing not at random (MNAR) data, scales to high dimensional inputs and gives both the VAE encoder and decoder principled access to indicator variables for whether a data element is missing or not. On the MNIST and SVHN datasets we demonstrate improved marginal log-likelihood of observed data and better missing data imputation, compared to existing approaches.
Analysis of Softmax Approximation for Deep Classifiers under Input-Dependent Label Noise
Mar 15, 2020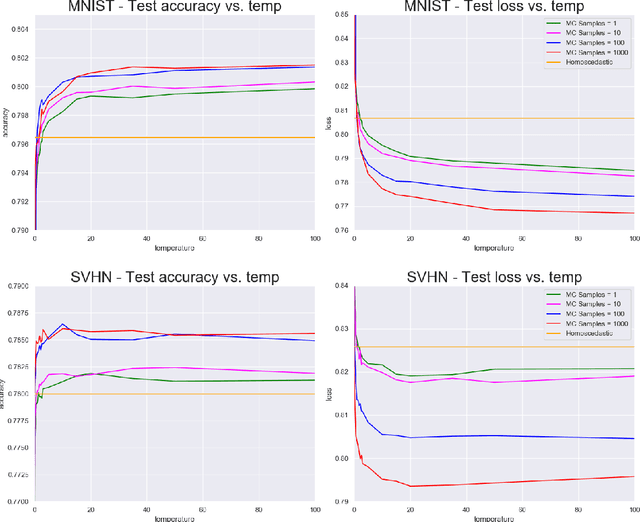

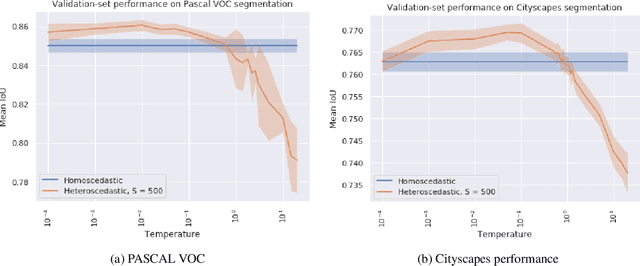
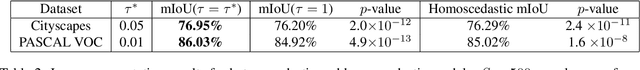
Modelling uncertainty arising from input-dependent label noise is an increasingly important problem. A state-of-the-art approach for classification [Kendall and Gal, 2017] places a normal distribution over the softmax logits, where the mean and variance of this distribution are learned functions of the inputs. This approach achieves impressive empirical performance but lacks theoretical justification. We show that this model is a special case of a well known and theoretically understood model studied in econometrics. Under this view the softmax over the logit distribution is a smooth approximation to an argmax, where the approximation is exact in the zero temperature limit. We further illustrate that the softmax temperature controls a bias-variance trade-off and the optimal point on this trade-off is not always found at 1.0. By tuning the softmax temperature, we achieve improved performance on well known image classification benchmarks with controlled label noise. For image segmentation, where input-dependent label noise naturally arises, we show that tuning the temperature increases the mean IoU on the PASCAL VOC and Cityscapes datasets by more than 1% over the state-of-the-art model and a strong baseline that does not model this noise source.
Memory-Augmented Neural Networks for Machine Translation
Sep 18, 2019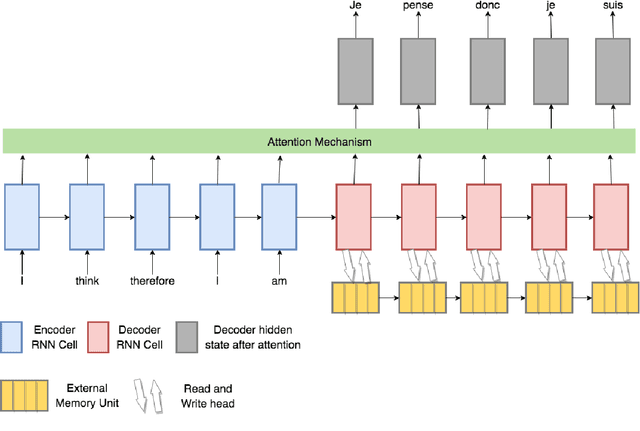
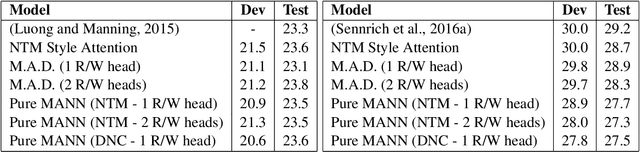
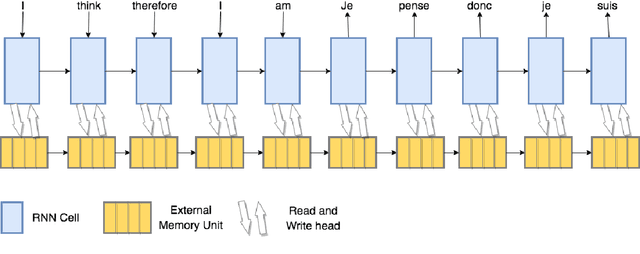
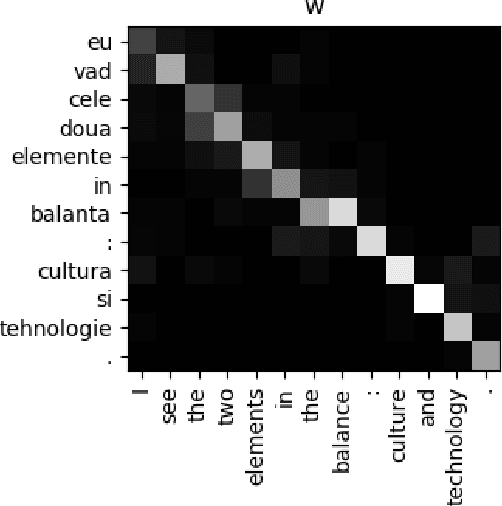
Memory-augmented neural networks (MANNs) have been shown to outperform other recurrent neural network architectures on a series of artificial sequence learning tasks, yet they have had limited application to real-world tasks. We evaluate direct application of Neural Turing Machines (NTM) and Differentiable Neural Computers (DNC) to machine translation. We further propose and evaluate two models which extend the attentional encoder-decoder with capabilities inspired by memory augmented neural networks. We evaluate our proposed models on IWSLT Vietnamese to English and ACL Romanian to English datasets. Our proposed models and the memory augmented neural networks perform similarly to the attentional encoder-decoder on the Vietnamese to English translation task while have a 0.3-1.9 lower BLEU score for the Romanian to English task. Interestingly, our analysis shows that despite being equipped with additional flexibility and being randomly initialized memory augmented neural networks learn an algorithm for machine translation almost identical to the attentional encoder-decoder.
Scalable Deep Unsupervised Clustering with Concrete GMVAEs
Sep 18, 2019
Discrete random variables are natural components of probabilistic clustering models. A number of VAE variants with discrete latent variables have been developed. Training such methods requires marginalizing over the discrete latent variables, causing training time complexity to be linear in the number clusters. By applying a continuous relaxation to the discrete variables in these methods we can achieve a reduction in the training time complexity to be constant in the number of clusters used. We demonstrate that in practice for one such method, the Gaussian Mixture VAE, the use of a continuous relaxation has no negative effect on the quality of the clustering but provides a substantial reduction in training time, reducing training time on CIFAR-100 with 20 clusters from 47 hours to less than 6 hours.
An Empirical Comparison of Syllabuses for Curriculum Learning
Sep 27, 2018
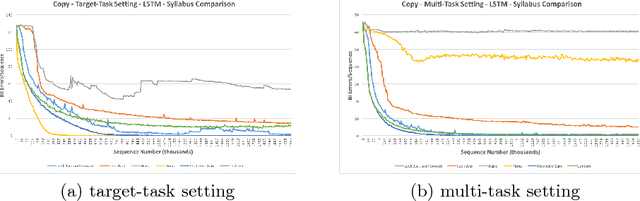
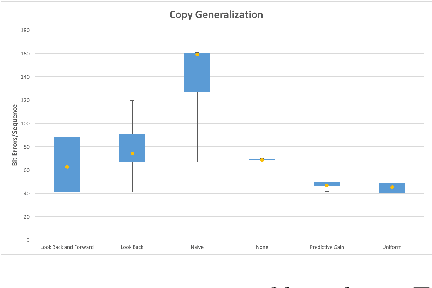
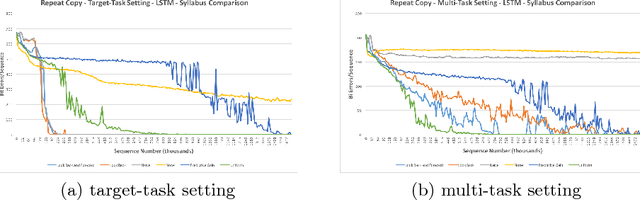
Syllabuses for curriculum learning have been developed on an ad-hoc, per task basis and little is known about the relative performance of different syllabuses. We identify a number of syllabuses used in the literature. We compare the identified syllabuses based on their effect on the speed of learning and generalization ability of a LSTM network on three sequential learning tasks. We find that the choice of syllabus has limited effect on the generalization ability of a trained network. In terms of speed of learning our results demonstrate that the best syllabus is task dependent but that a recently proposed automated curriculum learning approach - Predictive Gain, performs very competitively against all identified hand-crafted syllabuses. The best performing hand-crafted syllabus which we term Look Back and Forward combines a syllabus which steps through tasks in the order of their difficulty with a uniform distribution over all tasks. Our experimental results provide an empirical basis for the choice of syllabus on a new problem that could benefit from curriculum learning. Additionally, insights derived from our results shed light on how to successfully design new syllabuses.
Implementing Neural Turing Machines
Jul 26, 2018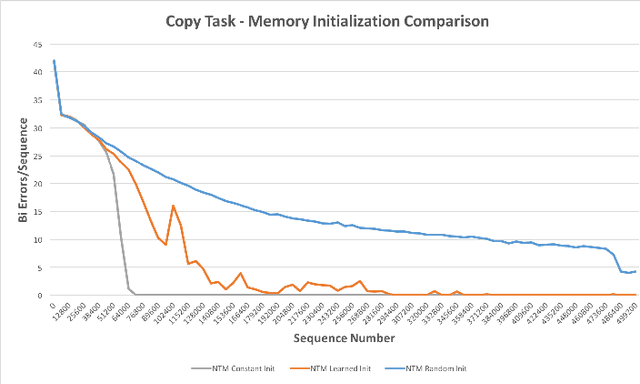
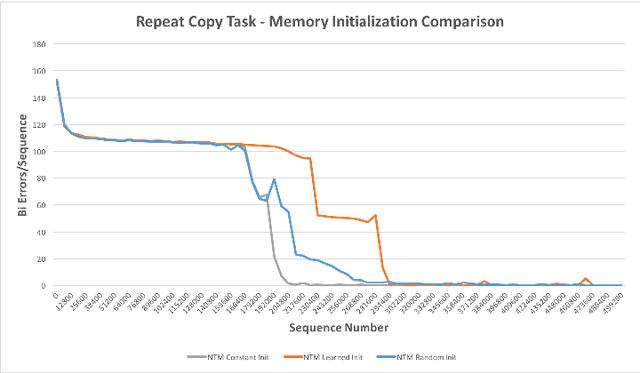
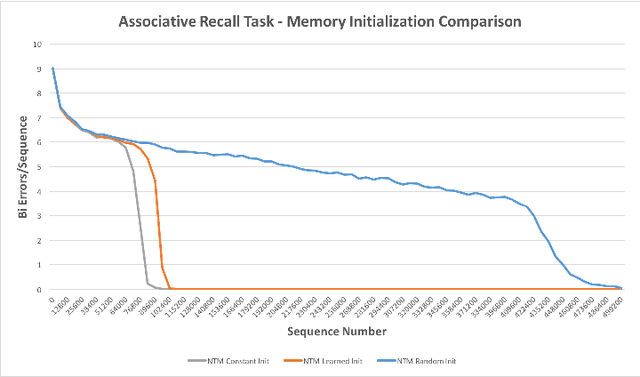
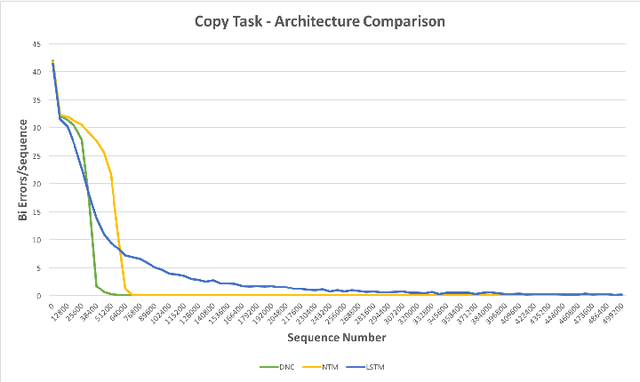
Neural Turing Machines (NTMs) are an instance of Memory Augmented Neural Networks, a new class of recurrent neural networks which decouple computation from memory by introducing an external memory unit. NTMs have demonstrated superior performance over Long Short-Term Memory Cells in several sequence learning tasks. A number of open source implementations of NTMs exist but are unstable during training and/or fail to replicate the reported performance of NTMs. This paper presents the details of our successful implementation of a NTM. Our implementation learns to solve three sequential learning tasks from the original NTM paper. We find that the choice of memory contents initialization scheme is crucial in successfully implementing a NTM. Networks with memory contents initialized to small constant values converge on average 2 times faster than the next best memory contents initialization scheme.