 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpelling Correction with Denoising Transformer
May 12, 2021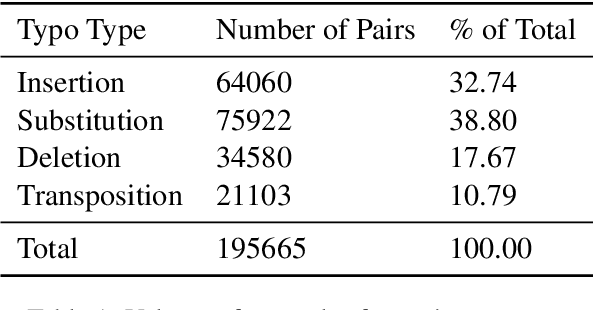
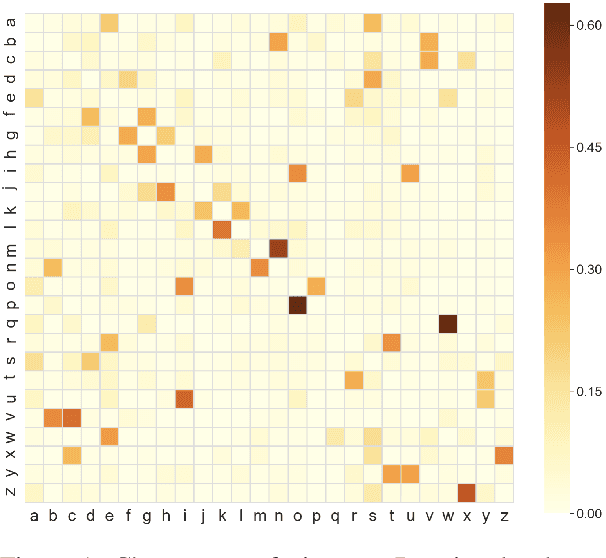
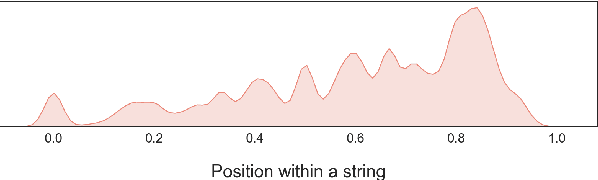
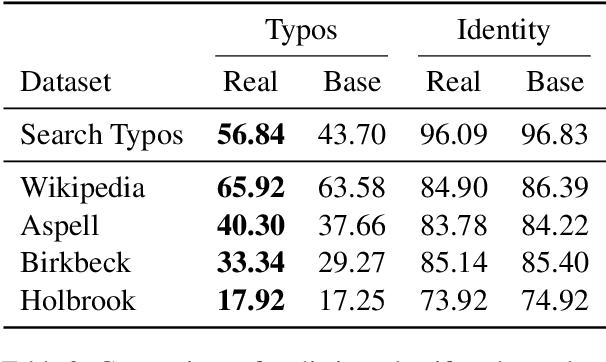
We present a novel method of performing spelling correction on short input strings, such as search queries or individual words. At its core lies a procedure for generating artificial typos which closely follow the error patterns manifested by humans. This procedure is used to train the production spelling correction model based on a transformer architecture. This model is currently served in the HubSpot product search. We show that our approach to typo generation is superior to the widespread practice of adding noise, which ignores human patterns. We also demonstrate how our approach may be extended to resource-scarce settings and train spelling correction models for Arabic, Greek, Russian, and Setswana languages, without using any labeled data.
Scalable Deep Unsupervised Clustering with Concrete GMVAEs
Sep 18, 2019
Discrete random variables are natural components of probabilistic clustering models. A number of VAE variants with discrete latent variables have been developed. Training such methods requires marginalizing over the discrete latent variables, causing training time complexity to be linear in the number clusters. By applying a continuous relaxation to the discrete variables in these methods we can achieve a reduction in the training time complexity to be constant in the number of clusters used. We demonstrate that in practice for one such method, the Gaussian Mixture VAE, the use of a continuous relaxation has no negative effect on the quality of the clustering but provides a substantial reduction in training time, reducing training time on CIFAR-100 with 20 clusters from 47 hours to less than 6 hours.