 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebate is efficient with your time
Feb 09, 2026AI safety via debate uses two competing models to help a human judge verify complex computational tasks. Previous work has established what problems debate can solve in principle, but has not analysed the practical cost of human oversight: how many queries must the judge make to the debate transcript? We introduce Debate Query Complexity}(DQC), the minimum number of bits a verifier must inspect to correctly decide a debate. Surprisingly, we find that PSPACE/poly (the class of problems which debate can efficiently decide) is precisely the class of functions decidable with O(log n) queries. This characterisation shows that debate is remarkably query-efficient: even for highly complex problems, logarithmic oversight suffices. We also establish that functions depending on all their input bits require Omega(log n) queries, and that any function computable by a circuit of size s satisfies DQC(f) <= log(s) + 3. Interestingly, this last result implies that proving DQC lower bounds of log(n) + 6 for languages in P would yield new circuit lower bounds, connecting debate query complexity to central questions in circuit complexity.
On the Brittleness of LLMs: A Journey around Set Membership
Nov 16, 2025Large language models (LLMs) achieve superhuman performance on complex reasoning tasks, yet often fail on much simpler problems, raising concerns about their reliability and interpretability. We investigate this paradox through a focused study with two key design features: simplicity, to expose basic failure modes, and scale, to enable comprehensive controlled experiments. We focus on set membership queries -- among the most fundamental forms of reasoning -- using tasks like ``Is apple an element of the set \{pear, plum, apple, raspberry\}?''. We conduct a systematic empirical evaluation across prompt phrasing, semantic structure, element ordering, and model choice. Our large-scale analysis reveals that LLM performance on this elementary task is consistently brittle, and unpredictable across all dimensions, suggesting that the models' ``understanding'' of the set concept is fragmented and convoluted at best. Our work demonstrates that the large-scale experiments enabled by the simplicity of the problem allow us to map and analyze the failure modes comprehensively, making this approach a valuable methodology for LLM evaluation in general.
Non-linear Quantum Monte Carlo
Feb 07, 2025The mean of a random variable can be understood as a $\textit{linear}$ functional on the space of probability distributions. Quantum computing is known to provide a quadratic speedup over classical Monte Carlo methods for mean estimation. In this paper, we investigate whether a similar quadratic speedup is achievable for estimating $\textit{non-linear}$ functionals of probability distributions. We propose a quantum-inside-quantum Monte Carlo algorithm that achieves such a speedup for a broad class of non-linear estimation problems, including nested conditional expectations and stochastic optimization. Our algorithm improves upon the direct application of the quantum multilevel Monte Carlo algorithm introduced by An et al.. The existing lower bound indicates that our algorithm is optimal up polylogarithmic factors. A key innovation of our approach is a new sequence of multilevel Monte Carlo approximations specifically designed for quantum computing, which is central to the algorithm's improved performance.
On Rearrangement of Items Stored in Stacks
Feb 12, 2020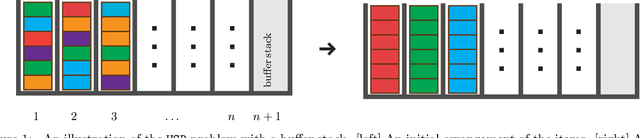

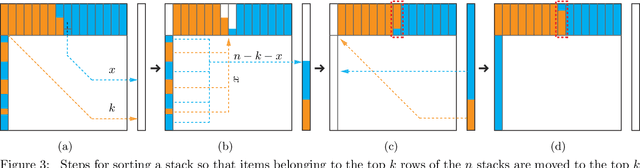
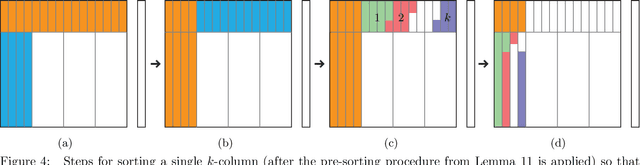
There are $n \ge 2$ stacks, each filled with $d$ items (its full capacity), and one empty stack with capacity $d$. A robot arm, in one stack operation (move), may pop one item from the top of a non-empty stack and subsequently push it into a stack that is not at capacity. In a {\em labeled} problem, all $nd$ items are distinguishable and are initially randomly scattered in the $n$ stacks. The items must be rearranged using pop-and-push moves so that at the end, the $k^{\rm th}$ stack holds items $(k-1)d +1, \ldots, kd$, in that order, from the top to the bottom for all $1 \le k \le n$. In an {\em unlabeled} problem, the $nd$ items are of $n$ types of $d$ each. The goal is to rearrange items so that items of type $k$ are located in the $k^{\rm th}$ stack for all $1 \le k \le n$. In carrying out the rearrangement, a natural question is to find the least number of required pop-and-push moves. In terms of the required number of moves for solving the rearrangement problems, the labeled and unlabeled version have lower bounds $\Omega(nd + nd{\frac{\log d}{\log n}})$ and $\Omega(nd)$, respectively. Our main contribution is the design of an algorithm with a guaranteed upper bound of $O(nd)$ for both versions when $d \le cn$ for arbitrary fixed positive number $c$. In addition, a subroutine for a problem that we call the Rubik table problem is of independent interest, with applications to problems including multi-robot motion planning.