 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerification of the Implicit World Model in a Generative Model via Adversarial Sequences
Feb 05, 2026Generative sequence models are typically trained on sample sequences from natural or formal languages. It is a crucial question whether -- or to what extent -- sample-based training is able to capture the true structure of these languages, often referred to as the ``world model''. Theoretical results indicate that we can hope for soundness at best, that is, generating valid sequences, but not necessarily all of them. However, it is still important to have practical tools that are able to verify whether a given sequence model is sound. In this study, we focus on chess, as it is a domain that provides enough complexity while having a simple rule-based world model. We propose adversarial sequence generation for verifying the soundness of the sequence model. Our adversaries generate valid sequences so as to force the sequence model to generate an invalid next move prediction. Apart from the falsification of soundness, this method is also suitable for a more fine-grained analysis of the failure modes and the effects of different choices during training. To demonstrate this, we propose a number of methods for adversarial sequence generation and evaluate the approach on a large set of chess models. We train models on random as well as high-quality chess games, using several training recipes. We find that none of the models are sound, but some training techniques and dataset choices are able to improve soundness remarkably. We also investigate the potential application of board state probes in both our training and attack methods. Our findings indicate that the extracted board states have no causal role in next token prediction in most of the models.
On the Brittleness of LLMs: A Journey around Set Membership
Nov 16, 2025Large language models (LLMs) achieve superhuman performance on complex reasoning tasks, yet often fail on much simpler problems, raising concerns about their reliability and interpretability. We investigate this paradox through a focused study with two key design features: simplicity, to expose basic failure modes, and scale, to enable comprehensive controlled experiments. We focus on set membership queries -- among the most fundamental forms of reasoning -- using tasks like ``Is apple an element of the set \{pear, plum, apple, raspberry\}?''. We conduct a systematic empirical evaluation across prompt phrasing, semantic structure, element ordering, and model choice. Our large-scale analysis reveals that LLM performance on this elementary task is consistently brittle, and unpredictable across all dimensions, suggesting that the models' ``understanding'' of the set concept is fragmented and convoluted at best. Our work demonstrates that the large-scale experiments enabled by the simplicity of the problem allow us to map and analyze the failure modes comprehensively, making this approach a valuable methodology for LLM evaluation in general.
How not to Stitch Representations to Measure Similarity: Task Loss Matching versus Direct Matching
Dec 15, 2024Measuring the similarity of the internal representations of deep neural networks is an important and challenging problem. Model stitching has been proposed as a possible approach, where two half-networks are connected by mapping the output of the first half-network to the input of the second one. The representations are considered functionally similar if the resulting stitched network achieves good task-specific performance. The mapping is normally created by training an affine stitching layer on the task at hand while freezing the two half-networks, a method called task loss matching. Here, we argue that task loss matching may be very misleading as a similarity index. For example, it can indicate very high similarity between very distant layers, whose representations are known to have different functional properties. Moreover, it can indicate very distant layers to be more similar than architecturally corresponding layers. Even more surprisingly, when comparing layers within the same network, task loss matching often indicates that some layers are more similar to a layer than itself. We argue that the main reason behind these problems is that task loss matching tends to create out-of-distribution representations to improve task-specific performance. We demonstrate that direct matching (when the mapping minimizes the distance between the stitched representations) does not suffer from these problems. We compare task loss matching, direct matching, and well-known similarity indices such as CCA and CKA. We conclude that direct matching strikes a good balance between the structural and functional requirements for a good similarity index.
Gossip Learning with Linear Models on Fully Distributed Data
Jun 06, 2012


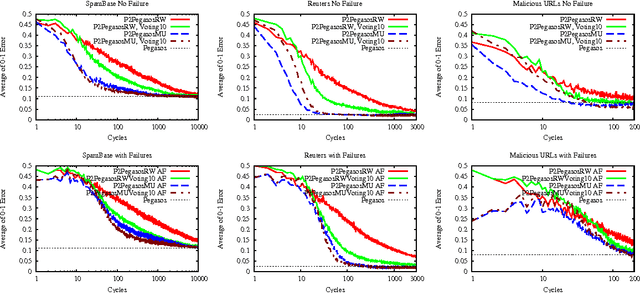
Machine learning over fully distributed data poses an important problem in peer-to-peer (P2P) applications. In this model we have one data record at each network node, but without the possibility to move raw data due to privacy considerations. For example, user profiles, ratings, history, or sensor readings can represent this case. This problem is difficult, because there is no possibility to learn local models, the system model offers almost no guarantees for reliability, yet the communication cost needs to be kept low. Here we propose gossip learning, a generic approach that is based on multiple models taking random walks over the network in parallel, while applying an online learning algorithm to improve themselves, and getting combined via ensemble learning methods. We present an instantiation of this approach for the case of classification with linear models. Our main contribution is an ensemble learning method which---through the continuous combination of the models in the network---implements a virtual weighted voting mechanism over an exponential number of models at practically no extra cost as compared to independent random walks. We prove the convergence of the method theoretically, and perform extensive experiments on benchmark datasets. Our experimental analysis demonstrates the performance and robustness of the proposed approach.