 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebate is efficient with your time
Feb 09, 2026AI safety via debate uses two competing models to help a human judge verify complex computational tasks. Previous work has established what problems debate can solve in principle, but has not analysed the practical cost of human oversight: how many queries must the judge make to the debate transcript? We introduce Debate Query Complexity}(DQC), the minimum number of bits a verifier must inspect to correctly decide a debate. Surprisingly, we find that PSPACE/poly (the class of problems which debate can efficiently decide) is precisely the class of functions decidable with O(log n) queries. This characterisation shows that debate is remarkably query-efficient: even for highly complex problems, logarithmic oversight suffices. We also establish that functions depending on all their input bits require Omega(log n) queries, and that any function computable by a circuit of size s satisfies DQC(f) <= log(s) + 3. Interestingly, this last result implies that proving DQC lower bounds of log(n) + 6 for languages in P would yield new circuit lower bounds, connecting debate query complexity to central questions in circuit complexity.
Coresets for Decision Trees of Signals
Oct 07, 2021


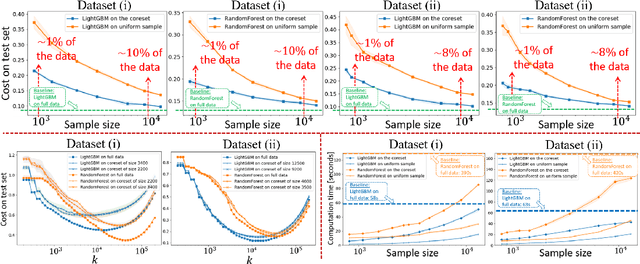
A $k$-decision tree $t$ (or $k$-tree) is a recursive partition of a matrix (2D-signal) into $k\geq 1$ block matrices (axis-parallel rectangles, leaves) where each rectangle is assigned a real label. Its regression or classification loss to a given matrix $D$ of $N$ entries (labels) is the sum of squared differences over every label in $D$ and its assigned label by $t$. Given an error parameter $\varepsilon\in(0,1)$, a $(k,\varepsilon)$-coreset $C$ of $D$ is a small summarization that provably approximates this loss to \emph{every} such tree, up to a multiplicative factor of $1\pm\varepsilon$. In particular, the optimal $k$-tree of $C$ is a $(1+\varepsilon)$-approximation to the optimal $k$-tree of $D$. We provide the first algorithm that outputs such a $(k,\varepsilon)$-coreset for \emph{every} such matrix $D$. The size $|C|$ of the coreset is polynomial in $k\log(N)/\varepsilon$, and its construction takes $O(Nk)$ time. This is by forging a link between decision trees from machine learning -- to partition trees in computational geometry. Experimental results on \texttt{sklearn} and \texttt{lightGBM} show that applying our coresets on real-world data-sets boosts the computation time of random forests and their parameter tuning by up to x$10$, while keeping similar accuracy. Full open source code is provided.