 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Generative Models Using Divergence Frontiers
May 26, 2019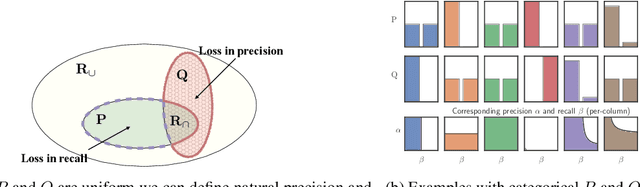
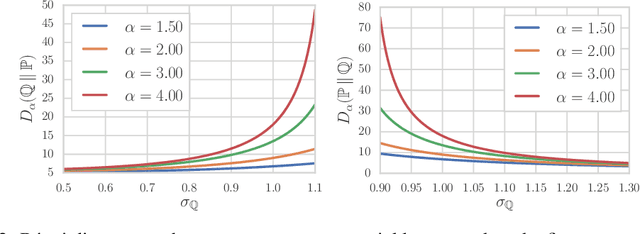
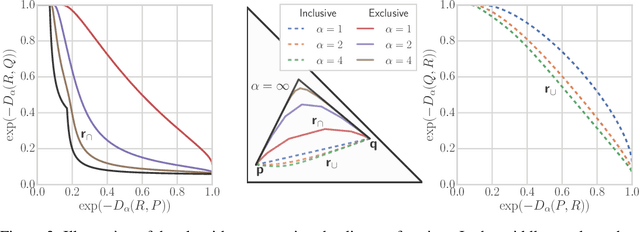
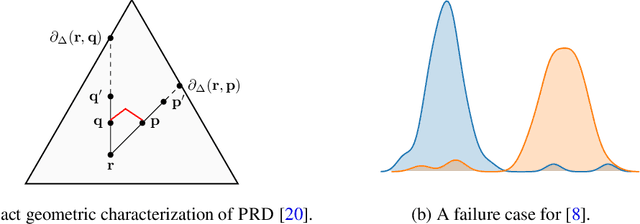
Despite the tremendous progress in the estimation of generative models, the development of tools for diagnosing their failures and assessing their performance has advanced at a much slower pace. Recent developments have investigated metrics that quantify which parts of the true distribution are modeled well, and, on the contrary, what the model fails to capture, akin to precision and recall in information retrieval. In this paper, we present a general evaluation framework for generative models that measures the trade-off between precision and recall using R\'enyi divergences. Our framework provides a novel perspective on existing techniques and extends them to more general domains. As a key advantage, it allows for efficient algorithms that are directly applicable to continuous distributions directly without discretization. We further showcase the proposed techniques on a set of image synthesis models.
High-Fidelity Image Generation With Fewer Labels
Mar 06, 2019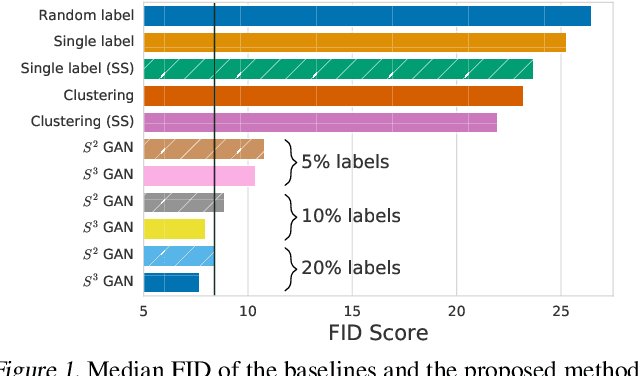
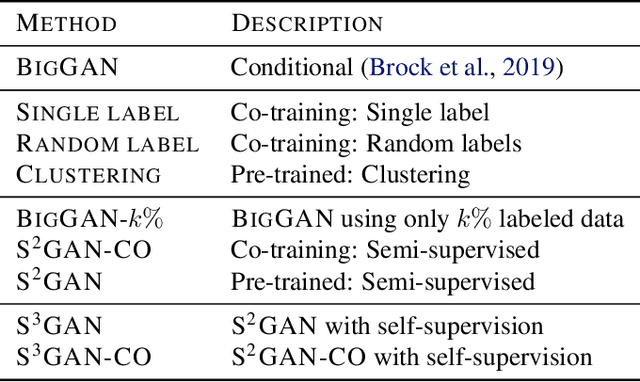

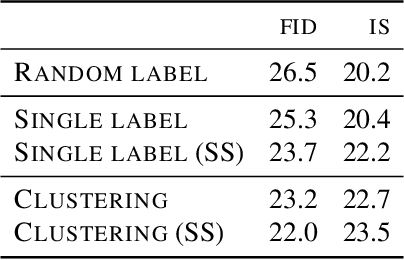
Deep generative models are becoming a cornerstone of modern machine learning. Recent work on conditional generative adversarial networks has shown that learning complex, high-dimensional distributions over natural images is within reach. While the latest models are able to generate high-fidelity, diverse natural images at high resolution, they rely on a vast quantity of labeled data. In this work we demonstrate how one can benefit from recent work on self- and semi-supervised learning to outperform state-of-the-art (SOTA) on both unsupervised ImageNet synthesis, as well as in the conditional setting. In particular, the proposed approach is able to match the sample quality (as measured by FID) of the current state-of-the art conditional model BigGAN on ImageNet using only 10% of the labels and outperform it using 20% of the labels.
Recent Advances in Autoencoder-Based Representation Learning
Dec 12, 2018
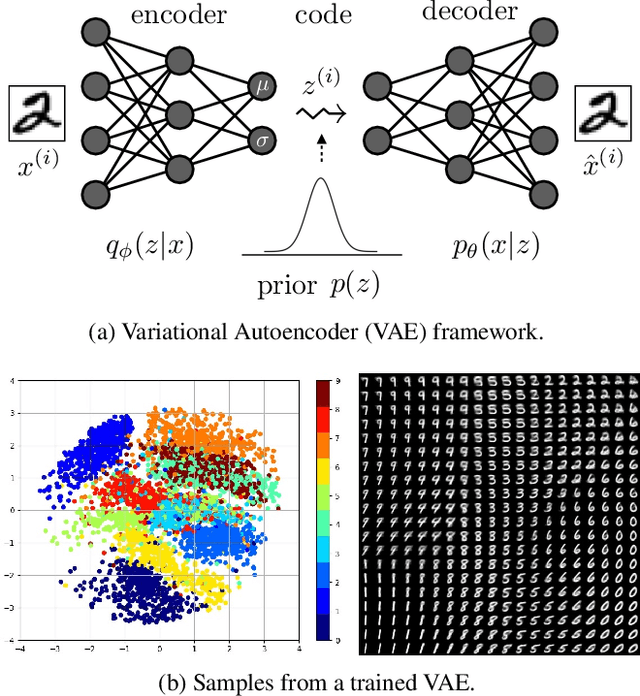
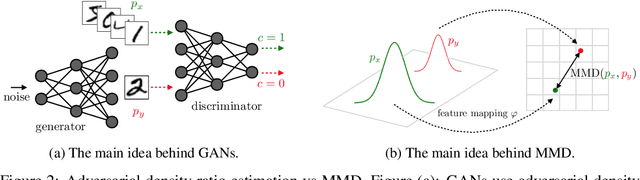

Learning useful representations with little or no supervision is a key challenge in artificial intelligence. We provide an in-depth review of recent advances in representation learning with a focus on autoencoder-based models. To organize these results we make use of meta-priors believed useful for downstream tasks, such as disentanglement and hierarchical organization of features. In particular, we uncover three main mechanisms to enforce such properties, namely (i) regularizing the (approximate or aggregate) posterior distribution, (ii) factorizing the encoding and decoding distribution, or (iii) introducing a structured prior distribution. While there are some promising results, implicit or explicit supervision remains a key enabler and all current methods use strong inductive biases and modeling assumptions. Finally, we provide an analysis of autoencoder-based representation learning through the lens of rate-distortion theory and identify a clear tradeoff between the amount of prior knowledge available about the downstream tasks, and how useful the representation is for this task.
Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations
Dec 02, 2018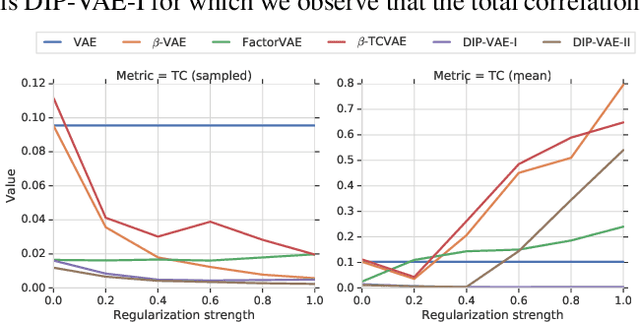

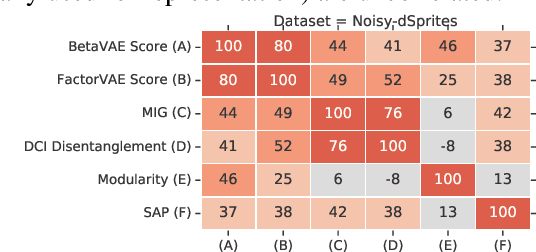

In recent years, the interest in unsupervised learning of disentangled representations has significantly increased. The key assumption is that real-world data is generated by a few explanatory factors of variation and that these factors can be recovered by unsupervised learning algorithms. A large number of unsupervised learning approaches based on auto-encoding and quantitative evaluation metrics of disentanglement have been proposed; yet, the efficacy of the proposed approaches and utility of proposed notions of disentanglement has not been challenged in prior work. In this paper, we provide a sober look on recent progress in the field and challenge some common assumptions. We first theoretically show that the unsupervised learning of disentangled representations is fundamentally impossible without inductive biases on both the models and the data. Then, we train more than 12000 models covering the six most prominent methods, and evaluate them across six disentanglement metrics in a reproducible large-scale experimental study on seven different data sets. On the positive side, we observe that different methods successfully enforce properties "encouraged" by the corresponding losses. On the negative side, we observe in our study that well-disentangled models seemingly cannot be identified without access to ground-truth labels even if we are allowed to transfer hyperparameters across data sets. Furthermore, increased disentanglement does not seem to lead to a decreased sample complexity of learning for downstream tasks. These results suggest that future work on disentanglement learning should be explicit about the role of inductive biases and (implicit) supervision, investigate concrete benefits of enforcing disentanglement of the learned representations, and consider a reproducible experimental setup covering several data sets.
Self-Supervised Generative Adversarial Networks
Nov 27, 2018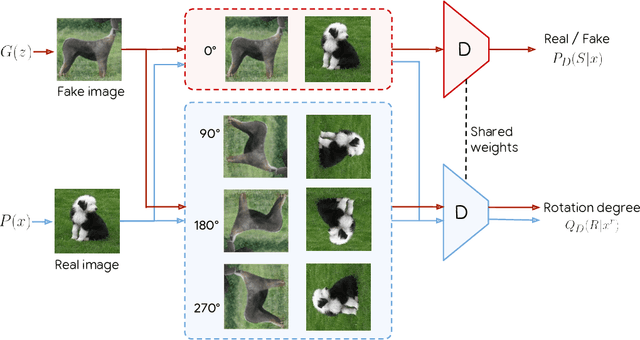
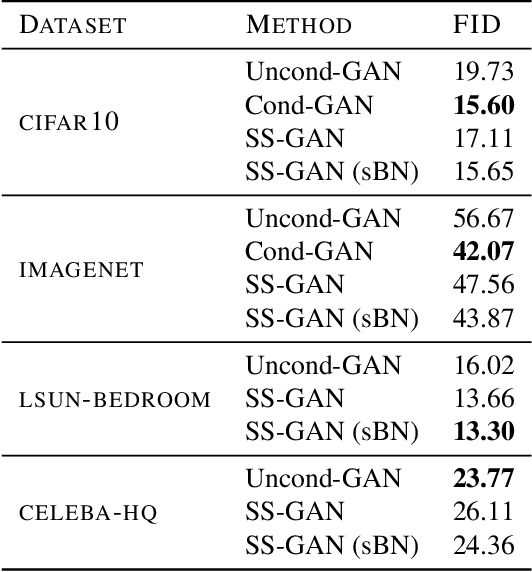
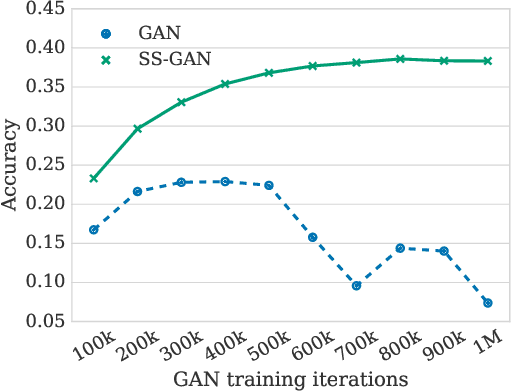
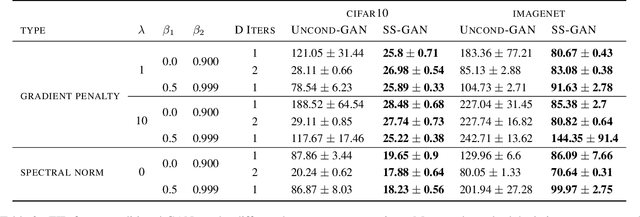
Conditional GANs are at the forefront of natural image synthesis. The main drawback of such models is the necessity for labelled data. In this work we exploit two popular unsupervised learning techniques, adversarial training and self-supervision, to close the gap between conditional and unconditional GANs. In particular, we allow the networks to collaborate on the task of representation learning, while being adversarial with respect to the classic GAN game. The role of self-supervision is to encourage the discriminator to learn meaningful feature representations which are not forgotten during training. We test empirically both the quality of the learned image representations, and the quality of the synthesized images. Under the same conditions, the self-supervised GAN attains a similar performance to state-of-the-art conditional counterparts. Finally, we show that this approach to fully unsupervised learning can be scaled to attain an FID of 33 on unconditional ImageNet generation.
Are GANs Created Equal? A Large-Scale Study
Oct 29, 2018
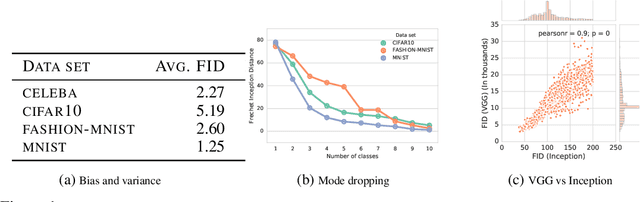
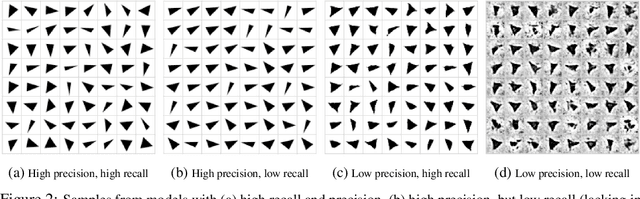
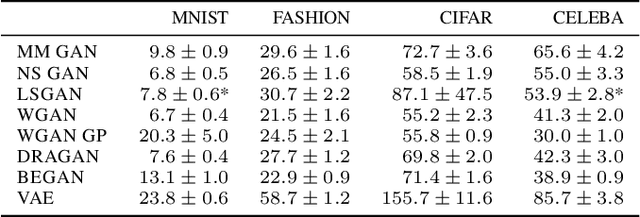
Generative adversarial networks (GAN) are a powerful subclass of generative models. Despite a very rich research activity leading to numerous interesting GAN algorithms, it is still very hard to assess which algorithm(s) perform better than others. We conduct a neutral, multi-faceted large-scale empirical study on state-of-the art models and evaluation measures. We find that most models can reach similar scores with enough hyperparameter optimization and random restarts. This suggests that improvements can arise from a higher computational budget and tuning more than fundamental algorithmic changes. To overcome some limitations of the current metrics, we also propose several data sets on which precision and recall can be computed. Our experimental results suggest that future GAN research should be based on more systematic and objective evaluation procedures. Finally, we did not find evidence that any of the tested algorithms consistently outperforms the non-saturating GAN introduced in \cite{goodfellow2014generative}.
Deep Generative Models for Distribution-Preserving Lossy Compression
Oct 28, 2018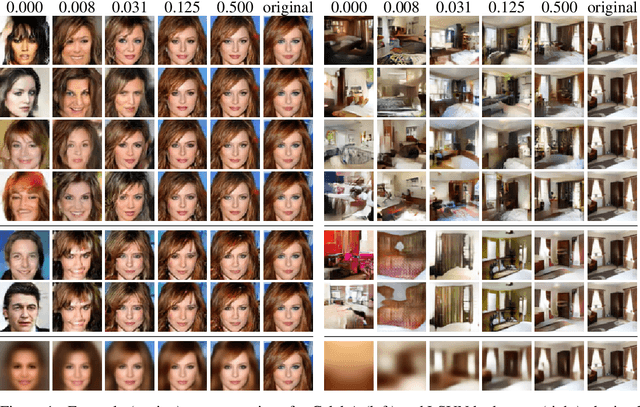
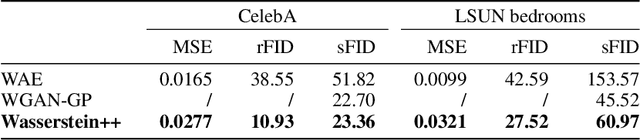
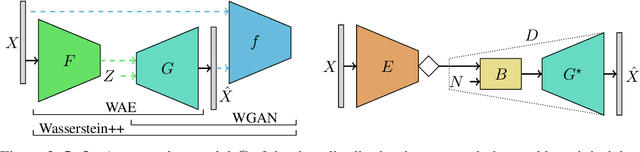
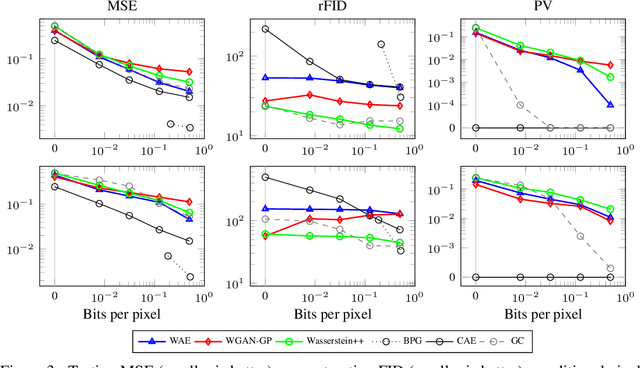
We propose and study the problem of distribution-preserving lossy compression. Motivated by recent advances in extreme image compression which allow to maintain artifact-free reconstructions even at very low bitrates, we propose to optimize the rate-distortion tradeoff under the constraint that the reconstructed samples follow the distribution of the training data. The resulting compression system recovers both ends of the spectrum: On one hand, at zero bitrate it learns a generative model of the data, and at high enough bitrates it achieves perfect reconstruction. Furthermore, for intermediate bitrates it smoothly interpolates between learning a generative model of the training data and perfectly reconstructing the training samples. We study several methods to approximately solve the proposed optimization problem, including a novel combination of Wasserstein GAN and Wasserstein Autoencoder, and present an extensive theoretical and empirical characterization of the proposed compression systems.
Assessing Generative Models via Precision and Recall
Oct 28, 2018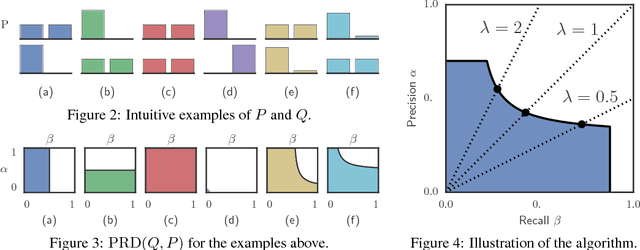
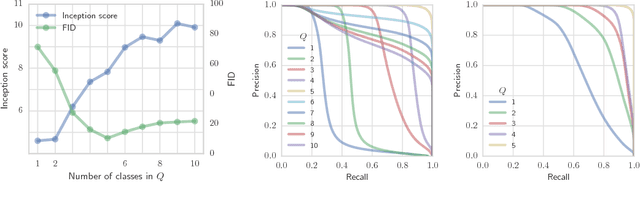
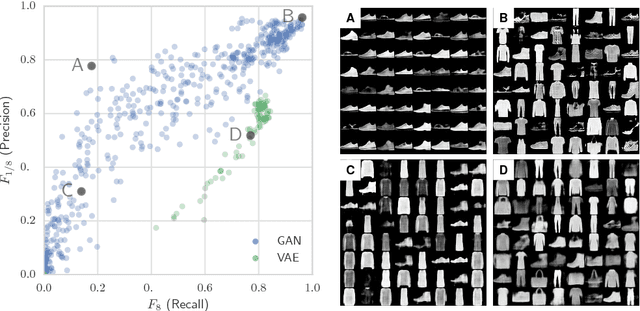
Recent advances in generative modeling have led to an increased interest in the study of statistical divergences as means of model comparison. Commonly used evaluation methods, such as the Frechet Inception Distance (FID), correlate well with the perceived quality of samples and are sensitive to mode dropping. However, these metrics are unable to distinguish between different failure cases since they only yield one-dimensional scores. We propose a novel definition of precision and recall for distributions which disentangles the divergence into two separate dimensions. The proposed notion is intuitive, retains desirable properties, and naturally leads to an efficient algorithm that can be used to evaluate generative models. We relate this notion to total variation as well as to recent evaluation metrics such as Inception Score and FID. To demonstrate the practical utility of the proposed approach we perform an empirical study on several variants of Generative Adversarial Networks and Variational Autoencoders. In an extensive set of experiments we show that the proposed metric is able to disentangle the quality of generated samples from the coverage of the target distribution.
The GAN Landscape: Losses, Architectures, Regularization, and Normalization
Oct 26, 2018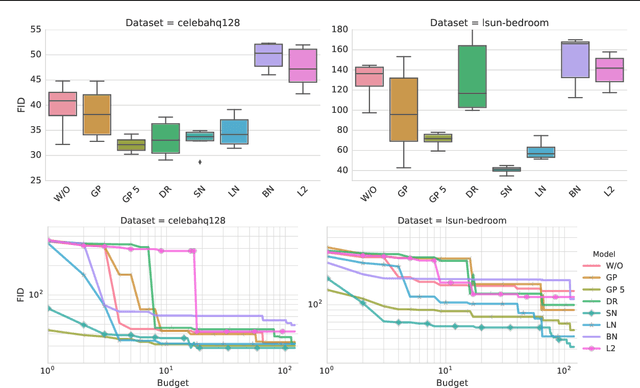
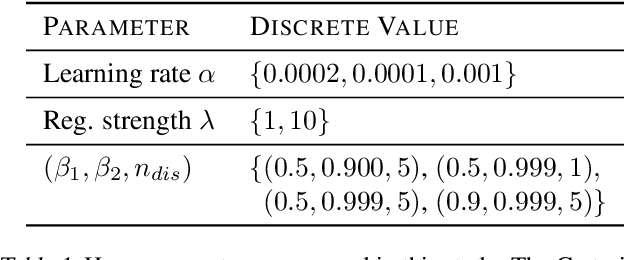

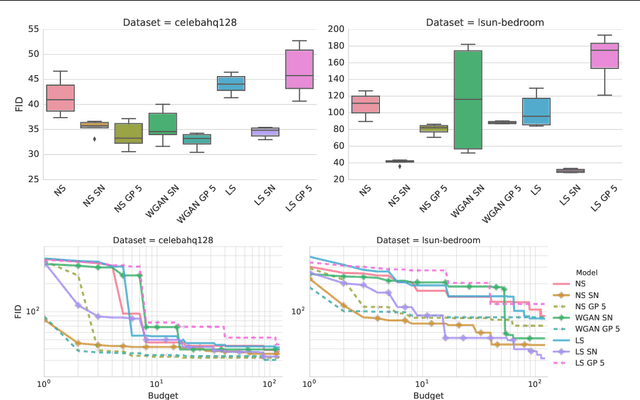
Generative adversarial networks (GANs) are a class of deep generative models which aim to learn a target distribution in an unsupervised fashion. While they were successfully applied to many problems, training a GAN is a notoriously challenging task and requires a significant amount of hyperparameter tuning, neural architecture engineering, and a non-trivial amount of "tricks". The success in many practical applications coupled with the lack of a measure to quantify the failure modes of GANs resulted in a plethora of proposed losses, regularization and normalization schemes, and neural architectures. In this work we take a sober view of the current state of GANs from a practical perspective. We reproduce the current state of the art and go beyond fairly exploring the GAN landscape. We discuss common pitfalls and reproducibility issues, open-source our code on Github, and provide pre-trained models on TensorFlow Hub.
On Self Modulation for Generative Adversarial Networks
Oct 02, 2018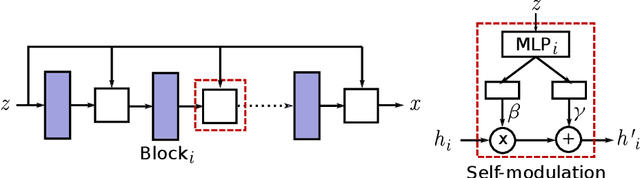

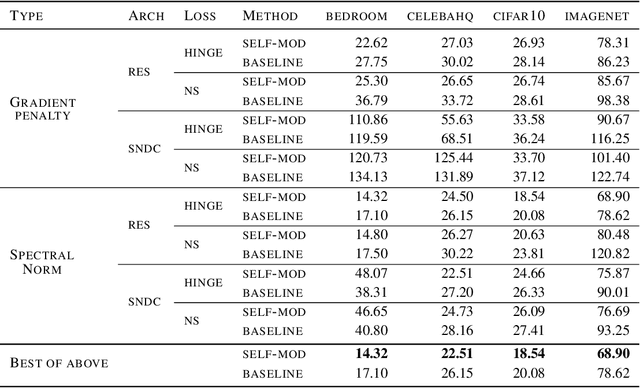
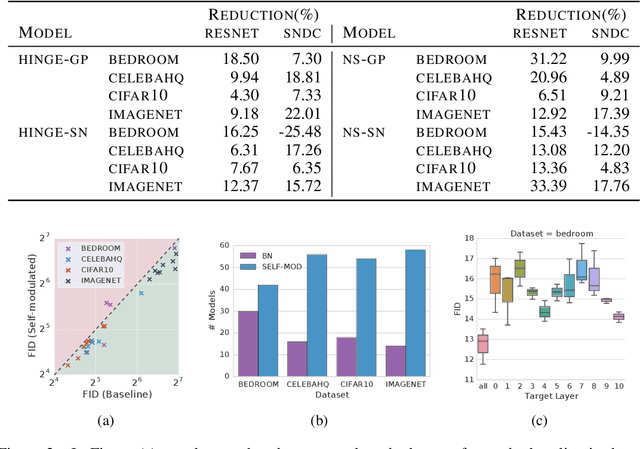
Training Generative Adversarial Networks (GANs) is notoriously challenging. We propose and study an architectural modification, self-modulation, which improves GAN performance across different data sets, architectures, losses, regularizers, and hyperparameter settings. Intuitively, self-modulation allows the intermediate feature maps of a generator to change as a function of the input noise vector. While reminiscent of other conditioning techniques, it requires no labeled data. In a large-scale empirical study we observe a relative decrease of $5\%-35\%$ in FID. Furthermore, all else being equal, adding this modification to the generator leads to improved performance in $124/144$ ($86\%$) of the studied settings. Self-modulation is a simple architectural change that requires no additional parameter tuning, which suggests that it can be applied readily to any GAN.