 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Moments of Change from Longitudinal User Text
May 11, 2022

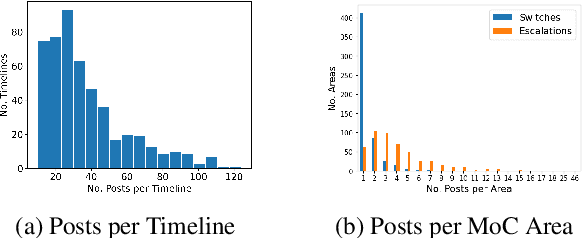
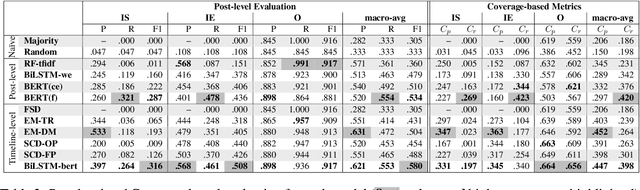
Identifying changes in individuals' behaviour and mood, as observed via content shared on online platforms, is increasingly gaining importance. Most research to-date on this topic focuses on either: (a) identifying individuals at risk or with a certain mental health condition given a batch of posts or (b) providing equivalent labels at the post level. A disadvantage of such work is the lack of a strong temporal component and the inability to make longitudinal assessments following an individual's trajectory and allowing timely interventions. Here we define a new task, that of identifying moments of change in individuals on the basis of their shared content online. The changes we consider are sudden shifts in mood (switches) or gradual mood progression (escalations). We have created detailed guidelines for capturing moments of change and a corpus of 500 manually annotated user timelines (18.7K posts). We have developed a variety of baseline models drawing inspiration from related tasks and show that the best performance is obtained through context aware sequential modelling. We also introduce new metrics for capturing rare events in temporal windows.
Natural Language Inference with Self-Attention for Veracity Assessment of Pandemic Claims
May 05, 2022
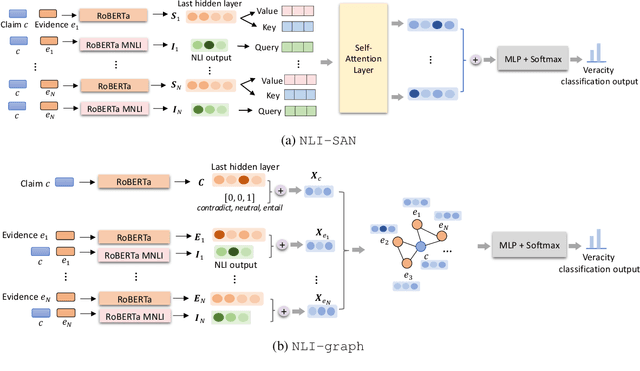

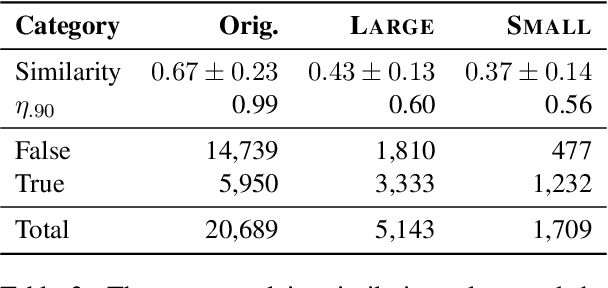
We present a comprehensive work on automated veracity assessment from dataset creation to developing novel methods based on Natural Language Inference (NLI), focusing on misinformation related to the COVID-19 pandemic. We first describe the construction of the novel PANACEA dataset consisting of heterogeneous claims on COVID-19 and their respective information sources. The dataset construction includes work on retrieval techniques and similarity measurements to ensure a unique set of claims. We then propose novel techniques for automated veracity assessment based on Natural Language Inference including graph convolutional networks and attention based approaches. We have carried out experiments on evidence retrieval and veracity assessment on the dataset using the proposed techniques and found them competitive with SOTA methods, and provided a detailed discussion.
Evaluation of Abstractive Summarisation Models with Machine Translation in Deliberative Processes
Oct 12, 2021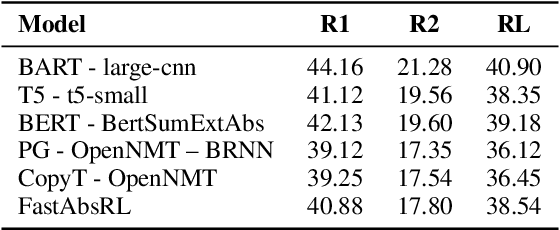
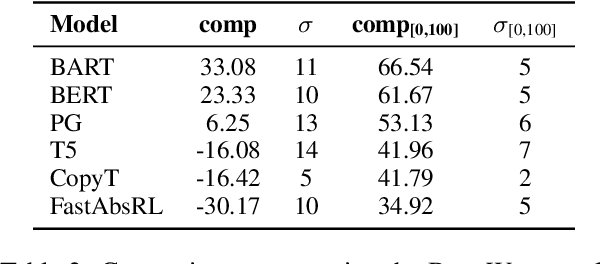
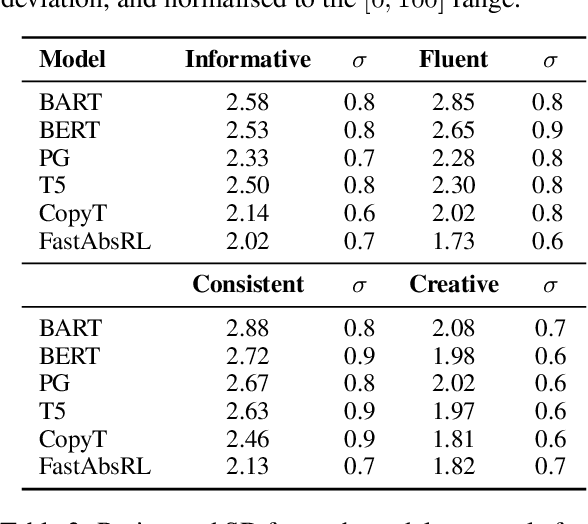
We present work on summarising deliberative processes for non-English languages. Unlike commonly studied datasets, such as news articles, this deliberation dataset reflects difficulties of combining multiple narratives, mostly of poor grammatical quality, in a single text. We report an extensive evaluation of a wide range of abstractive summarisation models in combination with an off-the-shelf machine translation model. Texts are translated into English, summarised, and translated back to the original language. We obtain promising results regarding the fluency, consistency and relevance of the summaries produced. Our approach is easy to implement for many languages for production purposes by simply changing the translation model.
A Longitudinal Multi-modal Dataset for Dementia Monitoring and Diagnosis
Sep 03, 2021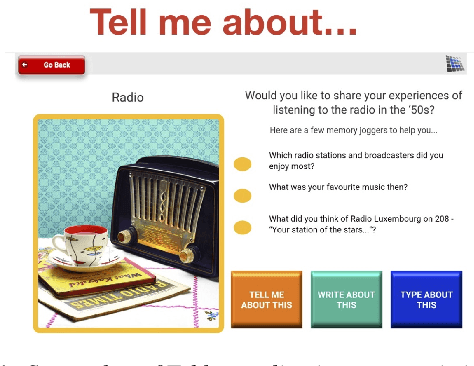
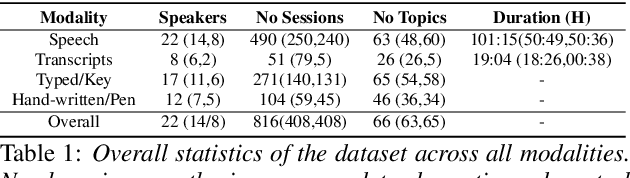
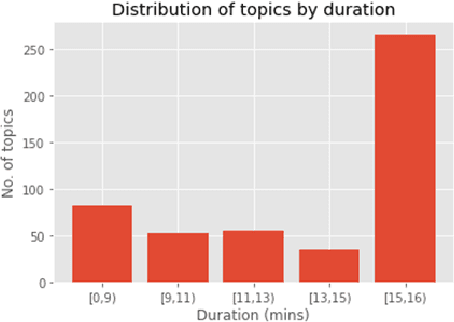
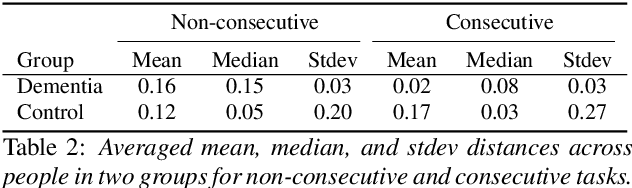
Dementia is a family of neurogenerative conditions affecting memory and cognition in an increasing number of individuals in our globally aging population. Automated analysis of language, speech and paralinguistic indicators have been gaining popularity as potential indicators of cognitive decline. Here we propose a novel longitudinal multi-modal dataset collected from people with mild dementia and age matched controls over a period of several months in a natural setting. The multi-modal data consists of spoken conversations, a subset of which are transcribed, as well as typed and written thoughts and associated extra-linguistic information such as pen strokes and keystrokes. We describe the dataset in detail and proceed to focus on a task using the speech modality. The latter involves distinguishing controls from people with dementia by exploiting the longitudinal nature of the data. Our experiments showed significant differences in how the speech varied from session to session in the control and dementia groups.
Evaluation of Thematic Coherence in Microblogs
Jun 30, 2021
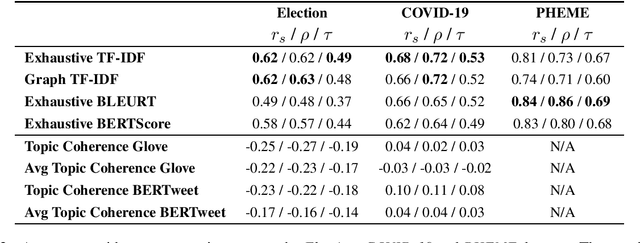


Collecting together microblogs representing opinions about the same topics within the same timeframe is useful to a number of different tasks and practitioners. A major question is how to evaluate the quality of such thematic clusters. Here we create a corpus of microblog clusters from three different domains and time windows and define the task of evaluating thematic coherence. We provide annotation guidelines and human annotations of thematic coherence by journalist experts. We subsequently investigate the efficacy of different automated evaluation metrics for the task. We consider a range of metrics including surface level metrics, ones for topic model coherence and text generation metrics (TGMs). While surface level metrics perform well, outperforming topic coherence metrics, they are not as consistent as TGMs. TGMs are more reliable than all other metrics considered for capturing thematic coherence in microblog clusters due to being less sensitive to the effect of time windows.
Citizen Participation and Machine Learning for a Better Democracy
Feb 28, 2021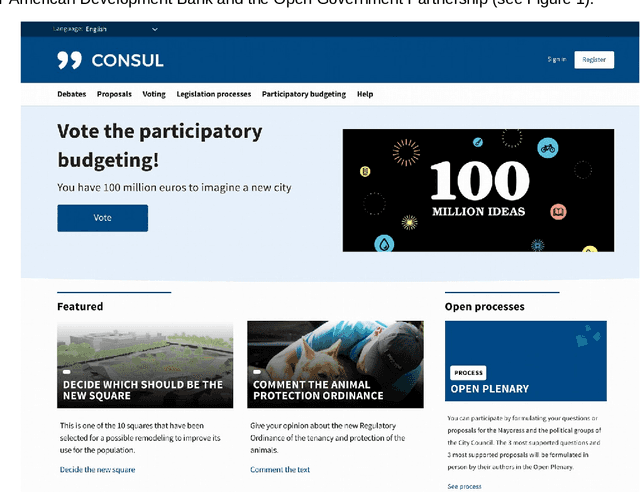

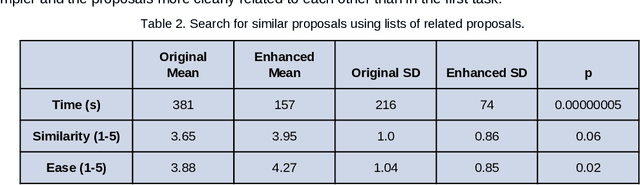
The development of democratic systems is a crucial task as confirmed by its selection as one of the Millennium Sustainable Development Goals by the United Nations. In this article, we report on the progress of a project that aims to address barriers, one of which is information overload, to achieving effective direct citizen participation in democratic decision-making processes. The main objectives are to explore if the application of Natural Language Processing (NLP) and machine learning can improve citizens' experience of digital citizen participation platforms. Taking as a case study the "Decide Madrid" Consul platform, which enables citizens to post proposals for policies they would like to see adopted by the city council, we used NLP and machine learning to provide new ways to (a) suggest to citizens proposals they might wish to support; (b) group citizens by interests so that they can more easily interact with each other; (c) summarise comments posted in response to proposals; (d) assist citizens in aggregating and developing proposals. Evaluation of the results confirms that NLP and machine learning have a role to play in addressing some of the barriers users of platforms such as Consul currently experience.
Modelling Paralinguistic Properties in Conversational Speech to Detect Bipolar Disorder and Borderline Personality Disorder
Feb 18, 2021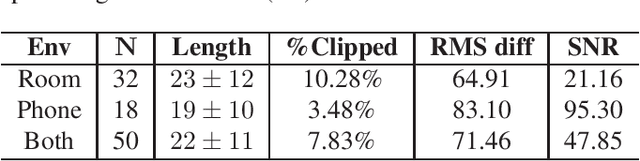

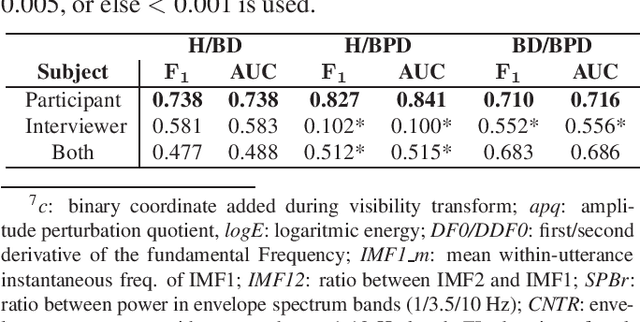
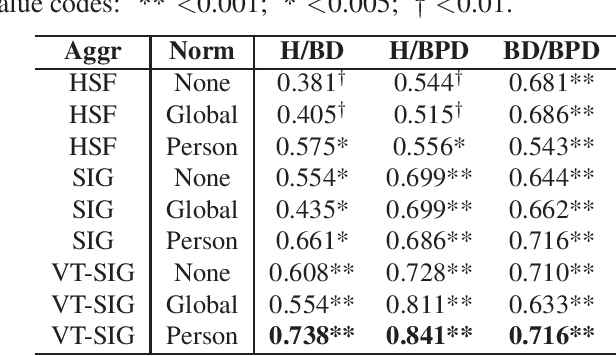
Bipolar disorder (BD) and borderline personality disorder (BPD) are two chronic mental health conditions that clinicians find challenging to distinguish based on clinical interviews, due to their overlapping symptoms. In this work, we investigate the automatic detection of these two conditions by modelling both verbal and non-verbal cues in a set of interviews. We propose a new approach of modelling short-term features with visibility-signature transform, and compare it with widely used high-level statistical functions. We demonstrate the superior performance of our proposed signature-based model. Furthermore, we show the role of different sets of features in characterising BD and BPD.
Boosting Low-Resource Biomedical QA via Entity-Aware Masking Strategies
Feb 16, 2021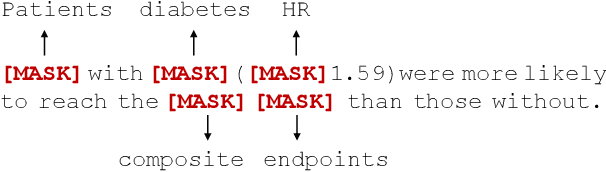
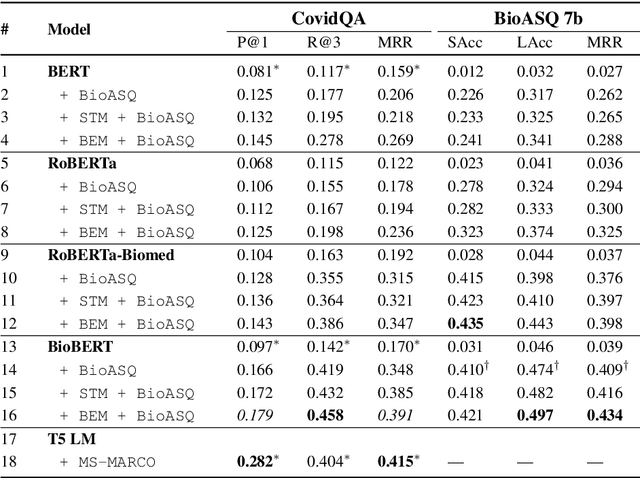
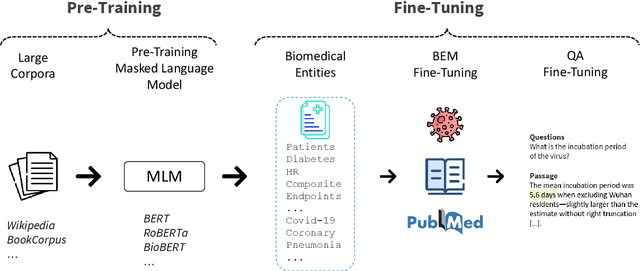

Biomedical question-answering (QA) has gained increased attention for its capability to provide users with high-quality information from a vast scientific literature. Although an increasing number of biomedical QA datasets has been recently made available, those resources are still rather limited and expensive to produce. Transfer learning via pre-trained language models (LMs) has been shown as a promising approach to leverage existing general-purpose knowledge. However, finetuning these large models can be costly and time consuming, often yielding limited benefits when adapting to specific themes of specialised domains, such as the COVID-19 literature. To bootstrap further their domain adaptation, we propose a simple yet unexplored approach, which we call biomedical entity-aware masking (BEM). We encourage masked language models to learn entity-centric knowledge based on the pivotal entities characterizing the domain at hand, and employ those entities to drive the LM fine-tuning. The resulting strategy is a downstream process applicable to a wide variety of masked LMs, not requiring additional memory or components in the neural architectures. Experimental results show performance on par with state-of-the-art models on several biomedical QA datasets.
CD2CR: Co-reference Resolution Across Documents and Domains
Jan 29, 2021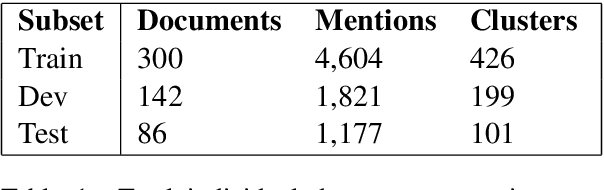
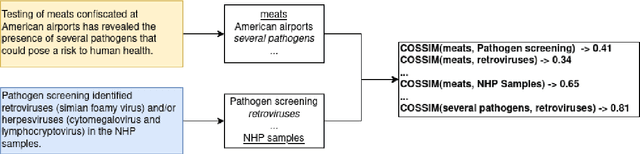
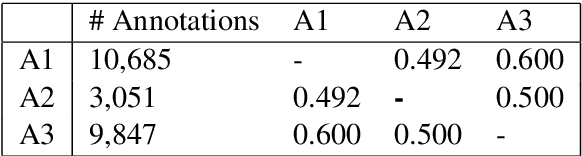
Cross-document co-reference resolution (CDCR) is the task of identifying and linking mentions to entities and concepts across many text documents. Current state-of-the-art models for this task assume that all documents are of the same type (e.g. news articles) or fall under the same theme. However, it is also desirable to perform CDCR across different domains (type or theme). A particular use case we focus on in this paper is the resolution of entities mentioned across scientific work and newspaper articles that discuss them. Identifying the same entities and corresponding concepts in both scientific articles and news can help scientists understand how their work is represented in mainstream media. We propose a new task and English language dataset for cross-document cross-domain co-reference resolution (CD$^2$CR). The task aims to identify links between entities across heterogeneous document types. We show that in this cross-domain, cross-document setting, existing CDCR models do not perform well and we provide a baseline model that outperforms current state-of-the-art CDCR models on CD$^2$CR. Our data set, annotation tool and guidelines as well as our model for cross-document cross-domain co-reference are all supplied as open access open source resources.
QMUL-SDS @ DIACR-Ita: Evaluating Unsupervised Diachronic Lexical Semantics Classification in Italian
Nov 06, 2020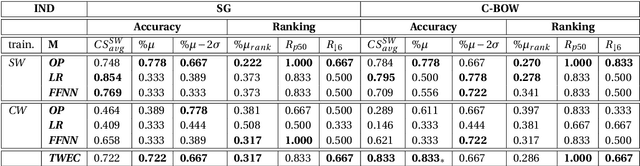
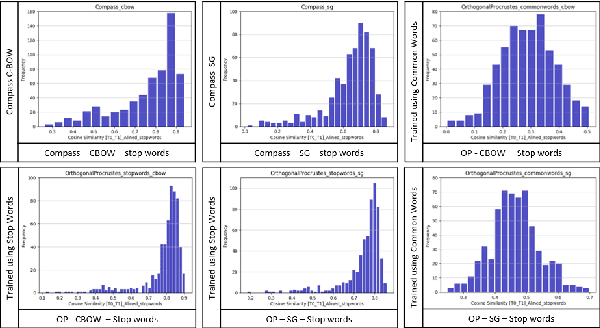
In this paper, we present the results and main findings of our system for the DIACR-ITA 2020 Task. Our system focuses on using variations of training sets and different semantic detection methods. The task involves training, aligning and predicting a word's vector change from two diachronic Italian corpora. We demonstrate that using Temporal Word Embeddings with a Compass C-BOW model is more effective compared to different approaches including Logistic Regression and a Feed Forward Neural Network using accuracy. Our model ranked 3rd with an accuracy of 83.3%.