 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKandinsky 5.0: A Family of Foundation Models for Image and Video Generation
Nov 19, 2025



This report introduces Kandinsky 5.0, a family of state-of-the-art foundation models for high-resolution image and 10-second video synthesis. The framework comprises three core line-up of models: Kandinsky 5.0 Image Lite - a line-up of 6B parameter image generation models, Kandinsky 5.0 Video Lite - a fast and lightweight 2B parameter text-to-video and image-to-video models, and Kandinsky 5.0 Video Pro - 19B parameter models that achieves superior video generation quality. We provide a comprehensive review of the data curation lifecycle - including collection, processing, filtering and clustering - for the multi-stage training pipeline that involves extensive pre-training and incorporates quality-enhancement techniques such as self-supervised fine-tuning (SFT) and reinforcement learning (RL)-based post-training. We also present novel architectural, training, and inference optimizations that enable Kandinsky 5.0 to achieve high generation speeds and state-of-the-art performance across various tasks, as demonstrated by human evaluation. As a large-scale, publicly available generative framework, Kandinsky 5.0 leverages the full potential of its pre-training and subsequent stages to be adapted for a wide range of generative applications. We hope that this report, together with the release of our open-source code and training checkpoints, will substantially advance the development and accessibility of high-quality generative models for the research community.
$ abla$NABLA: Neighborhood Adaptive Block-Level Attention
Jul 17, 2025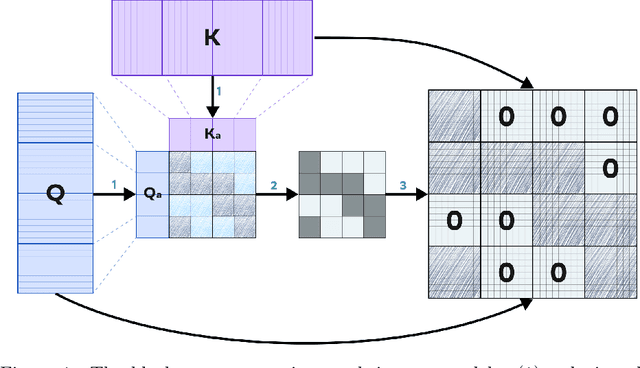
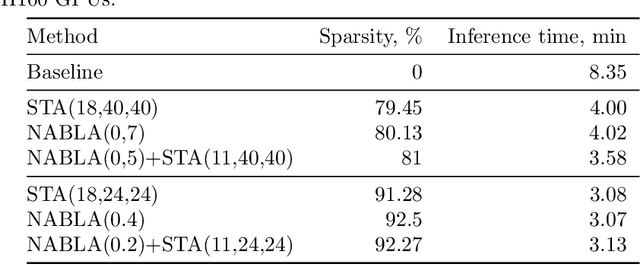
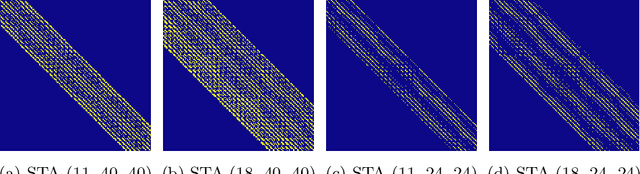
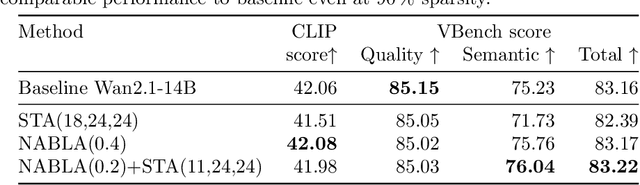
Recent progress in transformer-based architectures has demonstrated remarkable success in video generation tasks. However, the quadratic complexity of full attention mechanisms remains a critical bottleneck, particularly for high-resolution and long-duration video sequences. In this paper, we propose NABLA, a novel Neighborhood Adaptive Block-Level Attention mechanism that dynamically adapts to sparsity patterns in video diffusion transformers (DiTs). By leveraging block-wise attention with adaptive sparsity-driven threshold, NABLA reduces computational overhead while preserving generative quality. Our method does not require custom low-level operator design and can be seamlessly integrated with PyTorch's Flex Attention operator. Experiments demonstrate that NABLA achieves up to 2.7x faster training and inference compared to baseline almost without compromising quantitative metrics (CLIP score, VBench score, human evaluation score) and visual quality drop. The code and model weights are available here: https://github.com/gen-ai-team/Wan2.1-NABLA