 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Optimization of Weighted Sparse Decision Trees for use in Optimal Treatment Regimes and Optimal Policy Design
Oct 13, 2022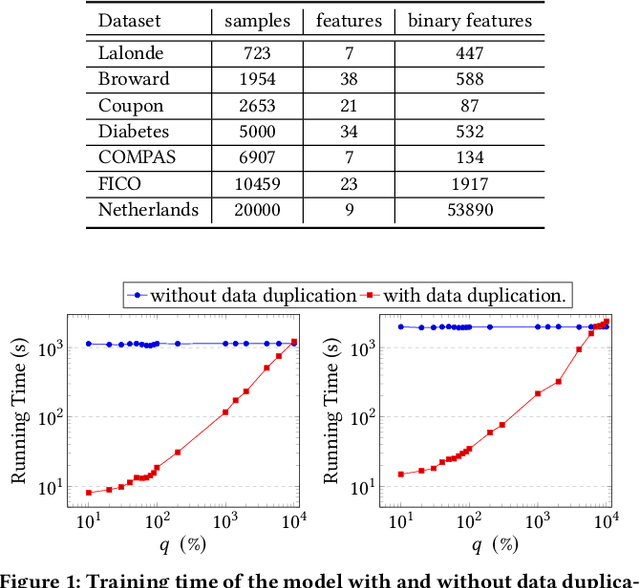
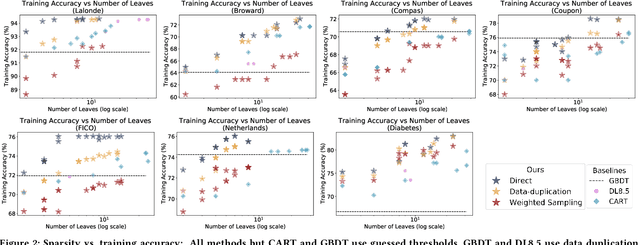

Sparse decision trees are one of the most common forms of interpretable models. While recent advances have produced algorithms that fully optimize sparse decision trees for prediction, that work does not address policy design, because the algorithms cannot handle weighted data samples. Specifically, they rely on the discreteness of the loss function, which means that real-valued weights cannot be directly used. For example, none of the existing techniques produce policies that incorporate inverse propensity weighting on individual data points. We present three algorithms for efficient sparse weighted decision tree optimization. The first approach directly optimizes the weighted loss function; however, it tends to be computationally inefficient for large datasets. Our second approach, which scales more efficiently, transforms weights to integer values and uses data duplication to transform the weighted decision tree optimization problem into an unweighted (but larger) counterpart. Our third algorithm, which scales to much larger datasets, uses a randomized procedure that samples each data point with a probability proportional to its weight. We present theoretical bounds on the error of the two fast methods and show experimentally that these methods can be two orders of magnitude faster than the direct optimization of the weighted loss, without losing significant accuracy.
FasterRisk: Fast and Accurate Interpretable Risk Scores
Oct 12, 2022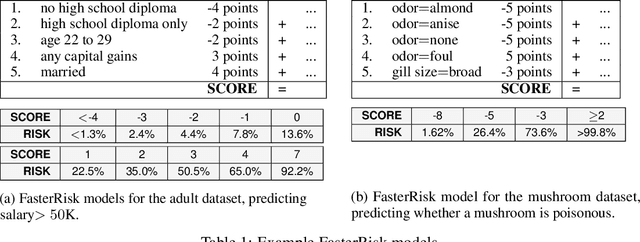
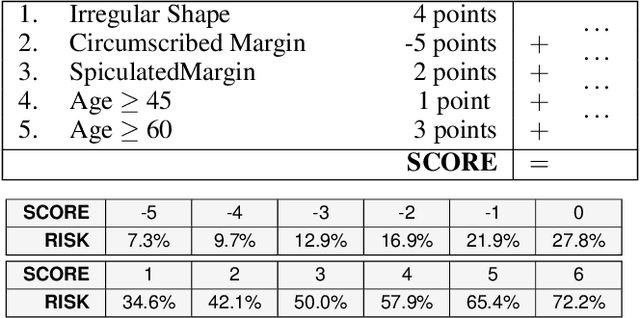
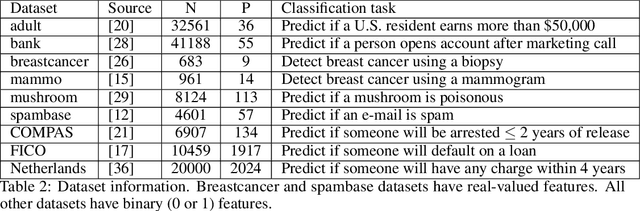
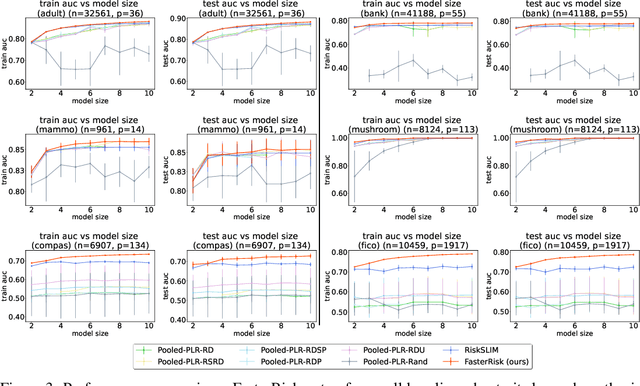
Over the last century, risk scores have been the most popular form of predictive model used in healthcare and criminal justice. Risk scores are sparse linear models with integer coefficients; often these models can be memorized or placed on an index card. Typically, risk scores have been created either without data or by rounding logistic regression coefficients, but these methods do not reliably produce high-quality risk scores. Recent work used mathematical programming, which is computationally slow. We introduce an approach for efficiently producing a collection of high-quality risk scores learned from data. Specifically, our approach produces a pool of almost-optimal sparse continuous solutions, each with a different support set, using a beam-search algorithm. Each of these continuous solutions is transformed into a separate risk score through a "star ray" search, where a range of multipliers are considered before rounding the coefficients sequentially to maintain low logistic loss. Our algorithm returns all of these high-quality risk scores for the user to consider. This method completes within minutes and can be valuable in a broad variety of applications.
TimberTrek: Exploring and Curating Sparse Decision Trees with Interactive Visualization
Sep 19, 2022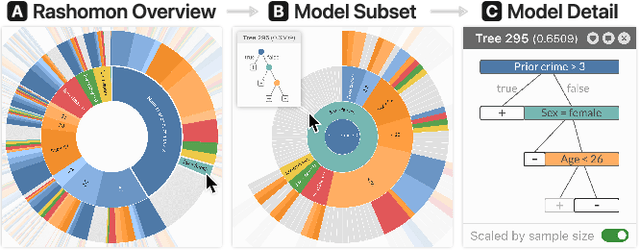
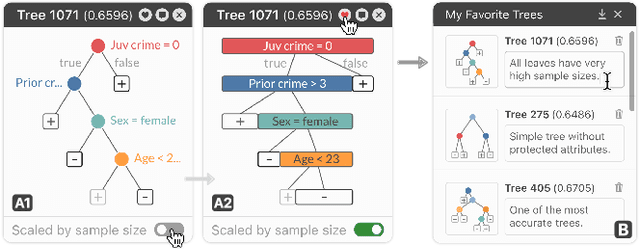
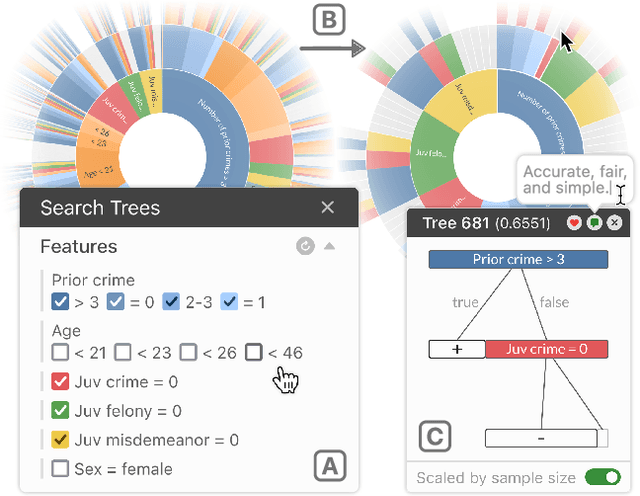
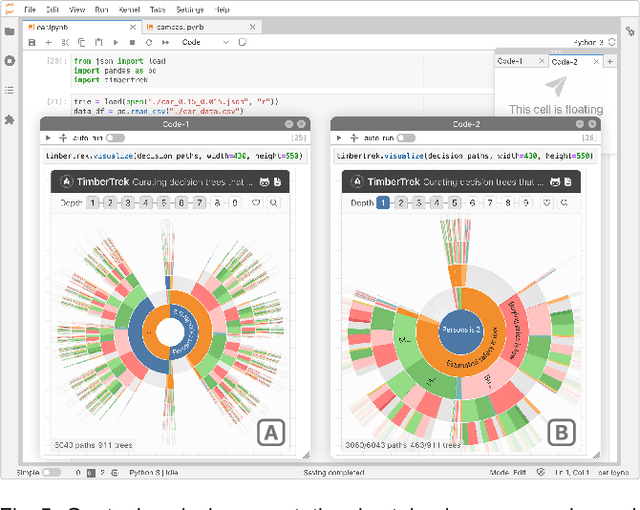
Given thousands of equally accurate machine learning (ML) models, how can users choose among them? A recent ML technique enables domain experts and data scientists to generate a complete Rashomon set for sparse decision trees--a huge set of almost-optimal interpretable ML models. To help ML practitioners identify models with desirable properties from this Rashomon set, we develop TimberTrek, the first interactive visualization system that summarizes thousands of sparse decision trees at scale. Two usage scenarios highlight how TimberTrek can empower users to easily explore, compare, and curate models that align with their domain knowledge and values. Our open-source tool runs directly in users' computational notebooks and web browsers, lowering the barrier to creating more responsible ML models. TimberTrek is available at the following public demo link: https://poloclub.github.io/timbertrek.
Exploring the Whole Rashomon Set of Sparse Decision Trees
Sep 16, 2022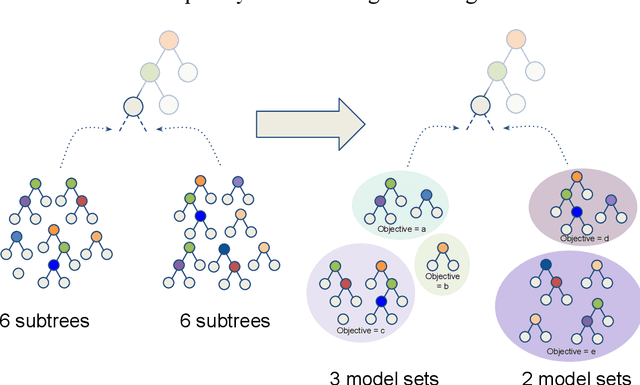
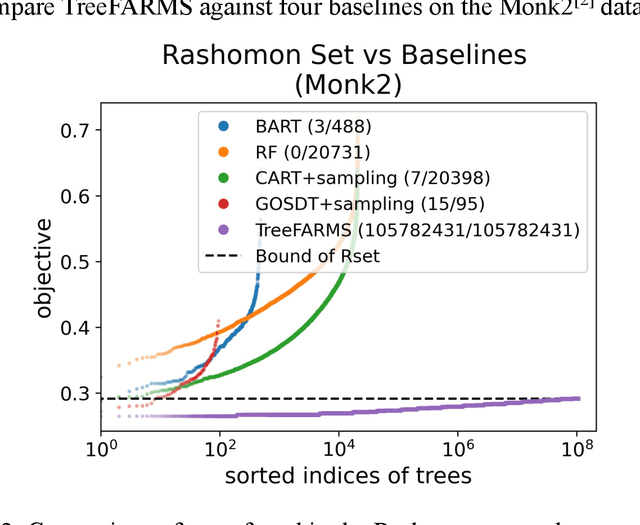
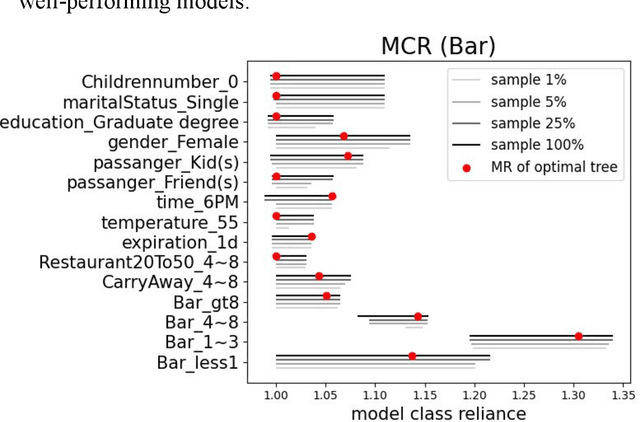
In any given machine learning problem, there may be many models that could explain the data almost equally well. However, most learning algorithms return only one of these models, leaving practitioners with no practical way to explore alternative models that might have desirable properties beyond what could be expressed within a loss function. The Rashomon set is the set of these all almost-optimal models. Rashomon sets can be extremely complicated, particularly for highly nonlinear function classes that allow complex interaction terms, such as decision trees. We provide the first technique for completely enumerating the Rashomon set for sparse decision trees; in fact, our work provides the first complete enumeration of any Rashomon set for a non-trivial problem with a highly nonlinear discrete function class. This allows the user an unprecedented level of control over model choice among all models that are approximately equally good. We represent the Rashomon set in a specialized data structure that supports efficient querying and sampling. We show three applications of the Rashomon set: 1) it can be used to study variable importance for the set of almost-optimal trees (as opposed to a single tree), 2) the Rashomon set for accuracy enables enumeration of the Rashomon sets for balanced accuracy and F1-score, and 3) the Rashomon set for a full dataset can be used to produce Rashomon sets constructed with only subsets of the data set. Thus, we are able to examine Rashomon sets across problems with a new lens, enabling users to choose models rather than be at the mercy of an algorithm that produces only a single model.
Fast Sparse Classification for Generalized Linear and Additive Models
Feb 23, 2022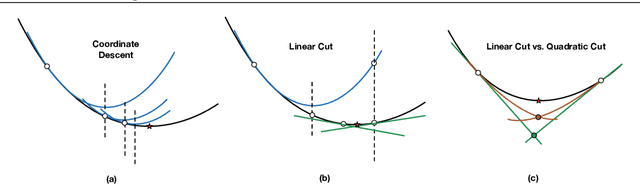


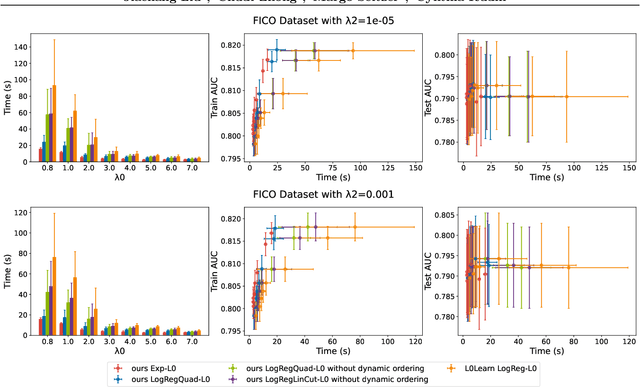
We present fast classification techniques for sparse generalized linear and additive models. These techniques can handle thousands of features and thousands of observations in minutes, even in the presence of many highly correlated features. For fast sparse logistic regression, our computational speed-up over other best-subset search techniques owes to linear and quadratic surrogate cuts for the logistic loss that allow us to efficiently screen features for elimination, as well as use of a priority queue that favors a more uniform exploration of features. As an alternative to the logistic loss, we propose the exponential loss, which permits an analytical solution to the line search at each iteration. Our algorithms are generally 2 to 5 times faster than previous approaches. They produce interpretable models that have accuracy comparable to black box models on challenging datasets.
Fast Sparse Decision Tree Optimization via Reference Ensembles
Dec 21, 2021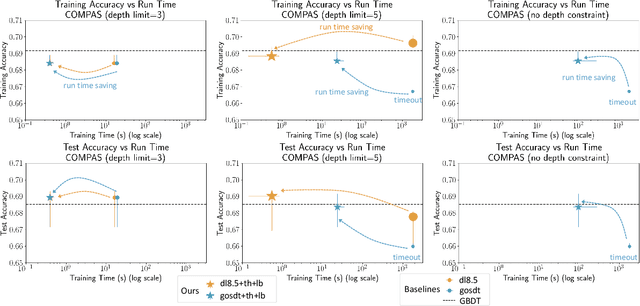
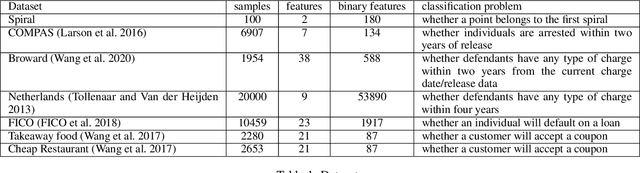
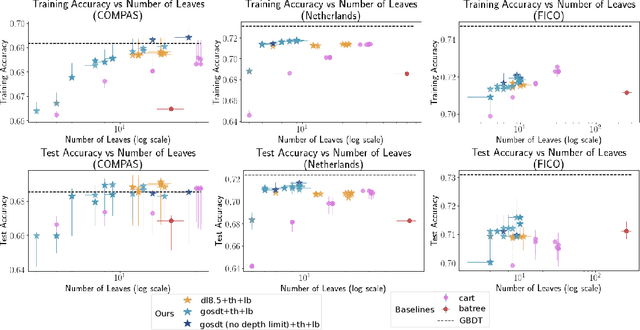
Sparse decision tree optimization has been one of the most fundamental problems in AI since its inception and is a challenge at the core of interpretable machine learning. Sparse decision tree optimization is computationally hard, and despite steady effort since the 1960's, breakthroughs have only been made on the problem within the past few years, primarily on the problem of finding optimal sparse decision trees. However, current state-of-the-art algorithms often require impractical amounts of computation time and memory to find optimal or near-optimal trees for some real-world datasets, particularly those having several continuous-valued features. Given that the search spaces of these decision tree optimization problems are massive, can we practically hope to find a sparse decision tree that competes in accuracy with a black box machine learning model? We address this problem via smart guessing strategies that can be applied to any optimal branch-and-bound-based decision tree algorithm. We show that by using these guesses, we can reduce the run time by multiple orders of magnitude, while providing bounds on how far the resulting trees can deviate from the black box's accuracy and expressive power. Our approach enables guesses about how to bin continuous features, the size of the tree, and lower bounds on the error for the optimal decision tree. Our experiments show that in many cases we can rapidly construct sparse decision trees that match the accuracy of black box models. To summarize: when you are having trouble optimizing, just guess.
SIGL: Securing Software Installations Through Deep Graph Learning
Aug 26, 2020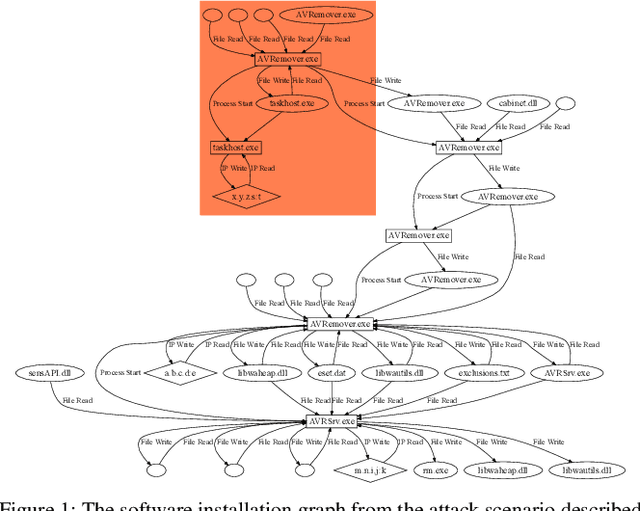

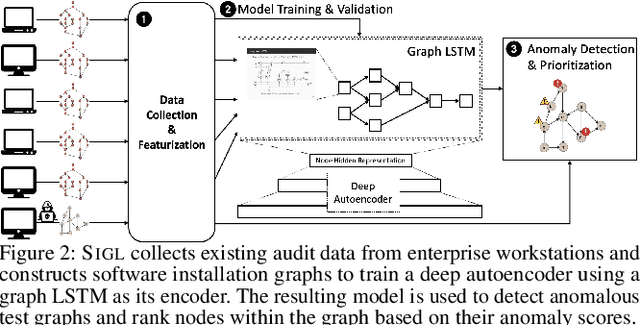

Many users implicitly assume that software can only be exploited after it is installed. However, recent supply-chain attacks demonstrate that application integrity must be ensured during installation itself. We introduce SIGL, a new tool for detecting malicious behavior during software installation. SIGL collects traces of system call activity, building a data provenance graph that it analyzes using a novel autoencoder architecture with a graph long short-term memory network (graph LSTM) for the encoder and a standard multilayer perceptron for the decoder. SIGL flags suspicious installations as well as the specific installation-time processes that are likely to be malicious. Using a test corpus of 625 malicious installers containing real-world malware, we demonstrate that SIGL has a detection accuracy of 96%, outperforming similar systems from industry and academia by up to 87% in precision and recall and 45% in accuracy. We also demonstrate that SIGL can pinpoint the processes most likely to have triggered malicious behavior, works on different audit platforms and operating systems, and is robust to training data contamination and adversarial attack. It can be used with application-specific models, even in the presence of new software versions, as well as application-agnostic meta-models that encompass a wide range of applications and installers.
Generalized and Scalable Optimal Sparse Decision Trees
Jul 17, 2020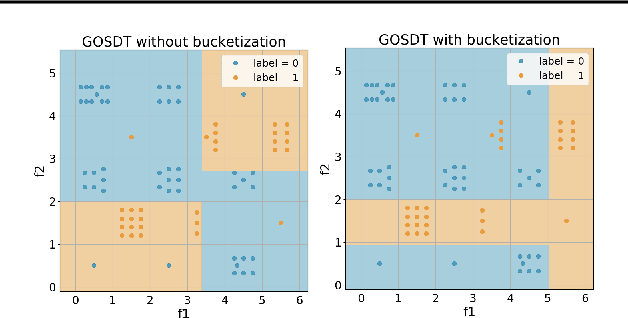
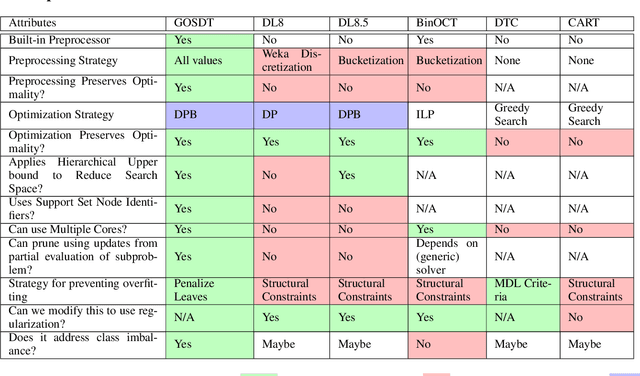
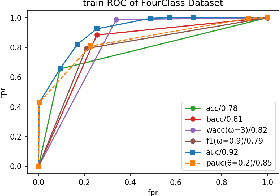
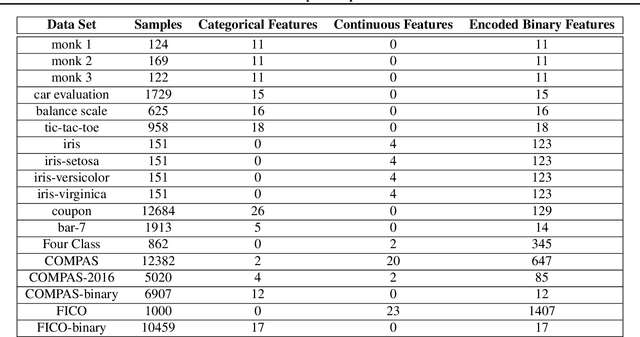
Decision tree optimization is notoriously difficult from a computational perspective but essential for the field of interpretable machine learning. Despite efforts over the past 40 years, only recently have optimization breakthroughs been made that have allowed practical algorithms to find optimal decision trees. These new techniques have the potential to trigger a paradigm shift where it is possible to construct sparse decision trees to efficiently optimize a variety of objective functions without relying on greedy splitting and pruning heuristics that often lead to suboptimal solutions. The contribution in this work is to provide a general framework for decision tree optimization that addresses the two significant open problems in the area: treatment of imbalanced data and fully optimizing over continuous variables. We present techniques that produce optimal decision trees over a variety of objectives including F-score, AUC, and partial area under the ROC convex hull. We also introduce a scalable algorithm that produces provably optimal results in the presence of continuous variables and speeds up decision tree construction by several orders of magnitude relative to the state-of-the art.
Optimal Sparse Decision Trees
Apr 29, 2019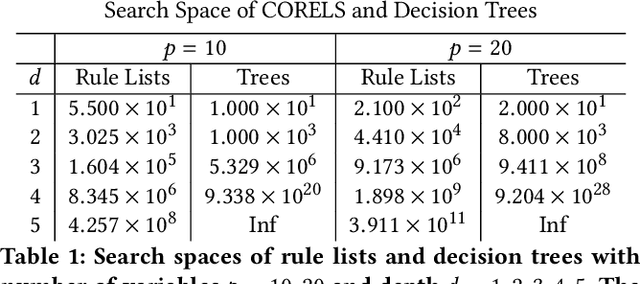
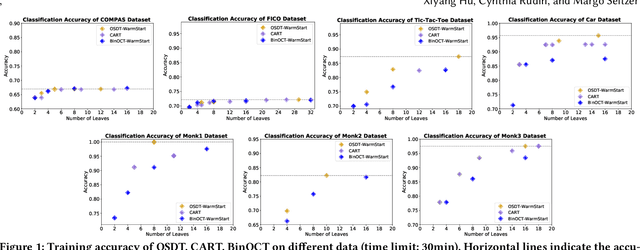
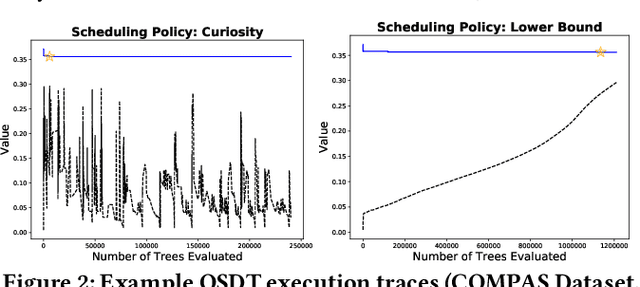
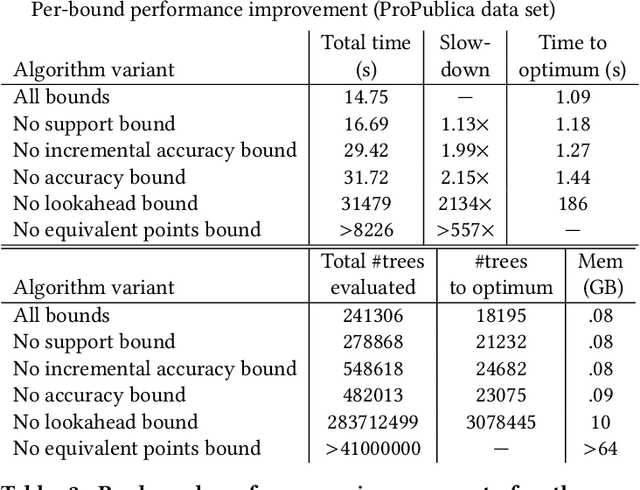
Decision tree algorithms have been among the most popular algorithms for interpretable (transparent) machine learning since the early 1980's. The problem that has plagued decision tree algorithms since their inception is their lack of optimality, or lack of guarantees of closeness to optimality: decision tree algorithms are often greedy or myopic, and sometimes produce unquestionably suboptimal models. Hardness of decision tree optimization is both a theoretical and practical obstacle, and even careful mathematical programming approaches have not been able to solve these problems efficiently. This work introduces the first practical algorithm for optimal decision trees for binary variables. The algorithm is a co-design of analytical bounds that reduce the search space and modern systems techniques, including data structures and a custom bit-vector library. We highlight possible steps to improving the scalability and speed of future generations of this algorithm based on insights from our theory and experiments.
Learning Certifiably Optimal Rule Lists for Categorical Data
Aug 03, 2018
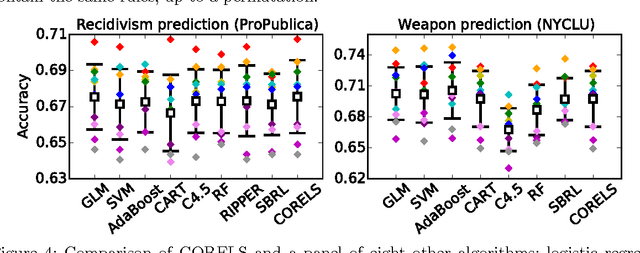
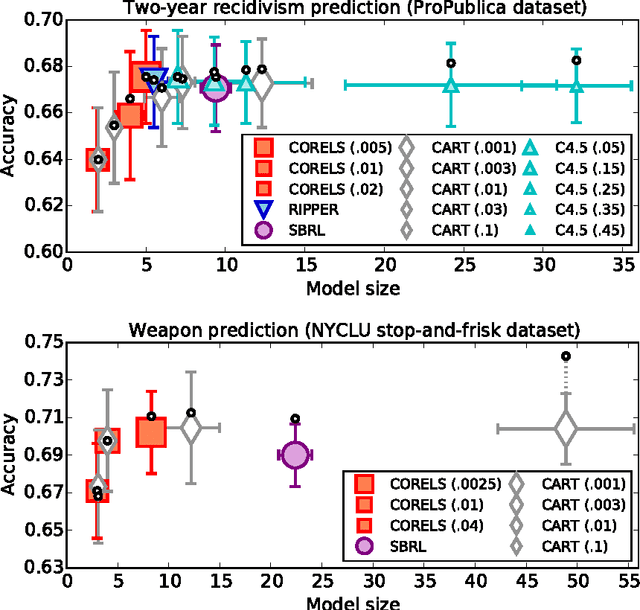
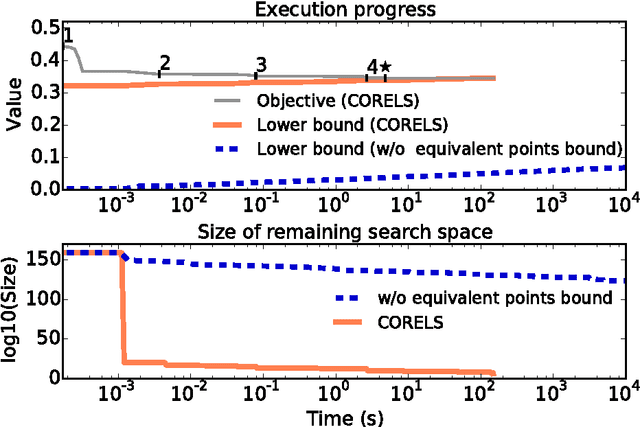
We present the design and implementation of a custom discrete optimization technique for building rule lists over a categorical feature space. Our algorithm produces rule lists with optimal training performance, according to the regularized empirical risk, with a certificate of optimality. By leveraging algorithmic bounds, efficient data structures, and computational reuse, we achieve several orders of magnitude speedup in time and a massive reduction of memory consumption. We demonstrate that our approach produces optimal rule lists on practical problems in seconds. Our results indicate that it is possible to construct optimal sparse rule lists that are approximately as accurate as the COMPAS proprietary risk prediction tool on data from Broward County, Florida, but that are completely interpretable. This framework is a novel alternative to CART and other decision tree methods for interpretable modeling.
* A short version of this work appeared in KDD '17 as "Learning Certifiably Optimal Rule Lists"