 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaTIM: Measuring Latent Token-to-Token Interactions in Mamba Models
Feb 21, 2025State space models (SSMs), such as Mamba, have emerged as an efficient alternative to transformers for long-context sequence modeling. However, despite their growing adoption, SSMs lack the interpretability tools that have been crucial for understanding and improving attention-based architectures. While recent efforts provide insights into Mamba's internal mechanisms, they do not explicitly decompose token-wise contributions, leaving gaps in understanding how Mamba selectively processes sequences across layers. In this work, we introduce LaTIM, a novel token-level decomposition method for both Mamba-1 and Mamba-2 that enables fine-grained interpretability. We extensively evaluate our method across diverse tasks, including machine translation, copying, and retrieval-based generation, demonstrating its effectiveness in revealing Mamba's token-to-token interaction patterns.
AdaSplash: Adaptive Sparse Flash Attention
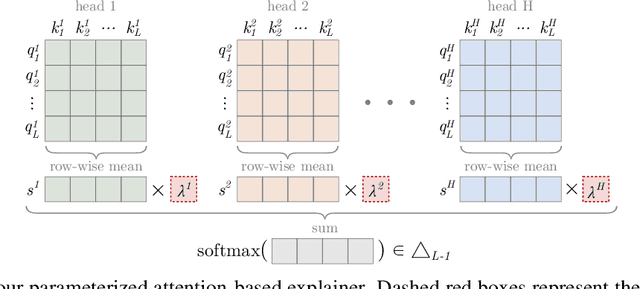
Feb 17, 2025The computational cost of softmax-based attention in transformers limits their applicability to long-context tasks. Adaptive sparsity, of which $\alpha$-entmax attention is an example, offers a flexible data-dependent alternative, but existing implementations are inefficient and do not leverage the sparsity to obtain runtime and memory gains. In this work, we propose AdaSplash, which combines the efficiency of GPU-optimized algorithms with the sparsity benefits of $\alpha$-entmax. We first introduce a hybrid Halley-bisection algorithm, resulting in a 7-fold reduction in the number of iterations needed to compute the $\alpha$-entmax transformation. Then, we implement custom Triton kernels to efficiently handle adaptive sparsity. Experiments with RoBERTa and ModernBERT for text classification and single-vector retrieval, along with GPT-2 for language modeling, show that our method achieves substantial improvements in runtime and memory efficiency compared to existing $\alpha$-entmax implementations. It approaches -- and in some cases surpasses -- the efficiency of highly optimized softmax implementations like FlashAttention-2, enabling long-context training while maintaining strong task performance.
How Effective are State Space Models for Machine Translation?
Jul 07, 2024



Transformers are the current architecture of choice for NLP, but their attention layers do not scale well to long contexts. Recent works propose to replace attention with linear recurrent layers -- this is the case for state space models, which enjoy efficient training and inference. However, it remains unclear whether these models are competitive with transformers in machine translation (MT). In this paper, we provide a rigorous and comprehensive experimental comparison between transformers and linear recurrent models for MT. Concretely, we experiment with RetNet, Mamba, and hybrid versions of Mamba which incorporate attention mechanisms. Our findings demonstrate that Mamba is highly competitive with transformers on sentence and paragraph-level datasets, where in the latter both models benefit from shifting the training distribution towards longer sequences. Further analysis show that integrating attention into Mamba improves translation quality, robustness to sequence length extrapolation, and the ability to recall named entities.
xTower: A Multilingual LLM for Explaining and Correcting Translation Errors
Jun 27, 2024



While machine translation (MT) systems are achieving increasingly strong performance on benchmarks, they often produce translations with errors and anomalies. Understanding these errors can potentially help improve the translation quality and user experience. This paper introduces xTower, an open large language model (LLM) built on top of TowerBase designed to provide free-text explanations for translation errors in order to guide the generation of a corrected translation. The quality of the generated explanations by xTower are assessed via both intrinsic and extrinsic evaluation. We ask expert translators to evaluate the quality of the explanations across two dimensions: relatedness towards the error span being explained and helpfulness in error understanding and improving translation quality. Extrinsically, we test xTower across various experimental setups in generating translation corrections, demonstrating significant improvements in translation quality. Our findings highlight xTower's potential towards not only producing plausible and helpful explanations of automatic translations, but also leveraging them to suggest corrected translations.
Scaling up COMETKIWI: Unbabel-IST 2023 Submission for the Quality Estimation Shared Task
Sep 21, 2023



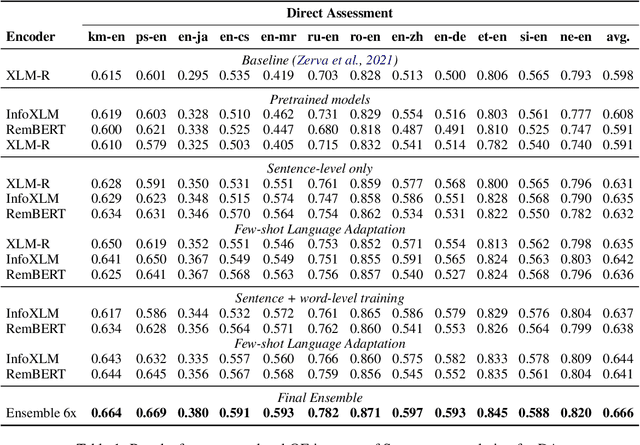
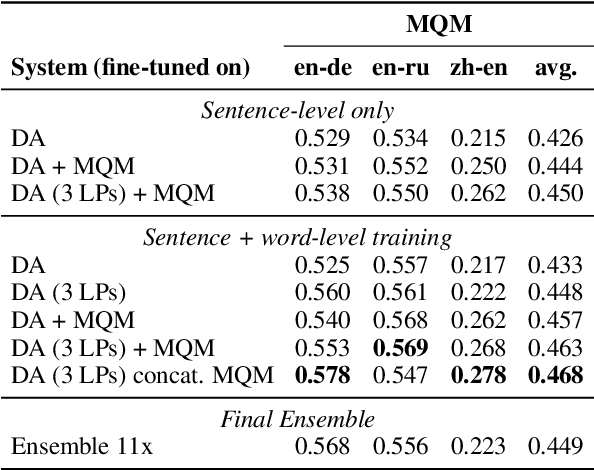
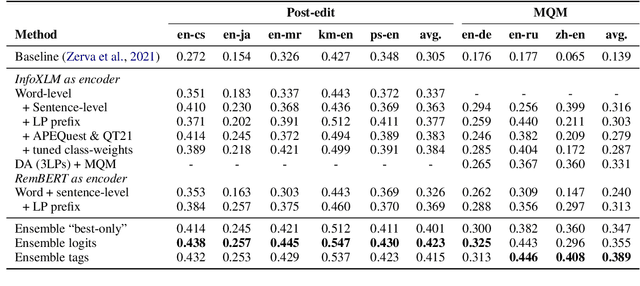
We present the joint contribution of Unbabel and Instituto Superior T\'ecnico to the WMT 2023 Shared Task on Quality Estimation (QE). Our team participated on all tasks: sentence- and word-level quality prediction (task 1) and fine-grained error span detection (task 2). For all tasks, we build on the COMETKIWI-22 model (Rei et al., 2022b). Our multilingual approaches are ranked first for all tasks, reaching state-of-the-art performance for quality estimation at word-, span- and sentence-level granularity. Compared to the previous state-of-the-art COMETKIWI-22, we show large improvements in correlation with human judgements (up to 10 Spearman points). Moreover, we surpass the second-best multilingual submission to the shared-task with up to 3.8 absolute points.
CREST: A Joint Framework for Rationalization and Counterfactual Text Generation
May 26, 2023Selective rationales and counterfactual examples have emerged as two effective, complementary classes of interpretability methods for analyzing and training NLP models. However, prior work has not explored how these methods can be integrated to combine their complementary advantages. We overcome this limitation by introducing CREST (ContRastive Edits with Sparse raTionalization), a joint framework for selective rationalization and counterfactual text generation, and show that this framework leads to improvements in counterfactual quality, model robustness, and interpretability. First, CREST generates valid counterfactuals that are more natural than those produced by previous methods, and subsequently can be used for data augmentation at scale, reducing the need for human-generated examples. Second, we introduce a new loss function that leverages CREST counterfactuals to regularize selective rationales and show that this regularization improves both model robustness and rationale quality, compared to methods that do not leverage CREST counterfactuals. Our results demonstrate that CREST successfully bridges the gap between selective rationales and counterfactual examples, addressing the limitations of existing methods and providing a more comprehensive view of a model's predictions.
The Inside Story: Towards Better Understanding of Machine Translation Neural Evaluation Metrics
May 19, 2023Neural metrics for machine translation evaluation, such as COMET, exhibit significant improvements in their correlation with human judgments, as compared to traditional metrics based on lexical overlap, such as BLEU. Yet, neural metrics are, to a great extent, "black boxes" returning a single sentence-level score without transparency about the decision-making process. In this work, we develop and compare several neural explainability methods and demonstrate their effectiveness for interpreting state-of-the-art fine-tuned neural metrics. Our study reveals that these metrics leverage token-level information that can be directly attributed to translation errors, as assessed through comparison of token-level neural saliency maps with Multidimensional Quality Metrics (MQM) annotations and with synthetically-generated critical translation errors. To ease future research, we release our code at: https://github.com/Unbabel/COMET/tree/explainable-metrics.
CometKiwi: IST-Unbabel 2022 Submission for the Quality Estimation Shared Task
Sep 13, 2022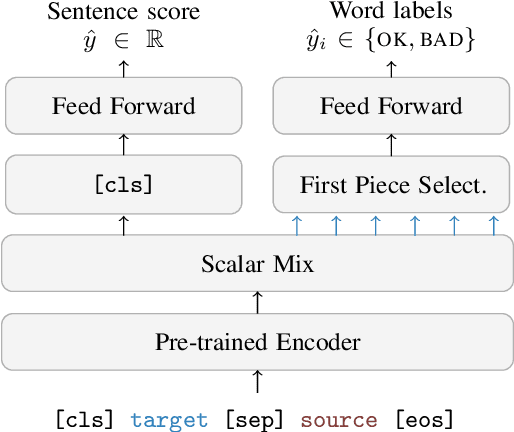
We present the joint contribution of IST and Unbabel to the WMT 2022 Shared Task on Quality Estimation (QE). Our team participated on all three subtasks: (i) Sentence and Word-level Quality Prediction; (ii) Explainable QE; and (iii) Critical Error Detection. For all tasks we build on top of the COMET framework, connecting it with the predictor-estimator architecture of OpenKiwi, and equipping it with a word-level sequence tagger and an explanation extractor. Our results suggest that incorporating references during pretraining improves performance across several language pairs on downstream tasks, and that jointly training with sentence and word-level objectives yields a further boost. Furthermore, combining attention and gradient information proved to be the top strategy for extracting good explanations of sentence-level QE models. Overall, our submissions achieved the best results for all three tasks for almost all language pairs by a considerable margin.
Learning to Scaffold: Optimizing Model Explanations for Teaching
Apr 22, 2022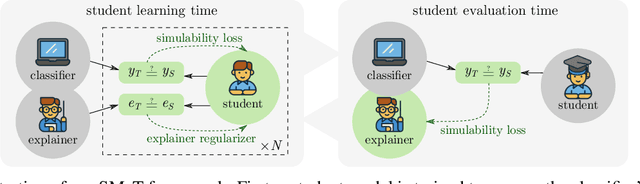
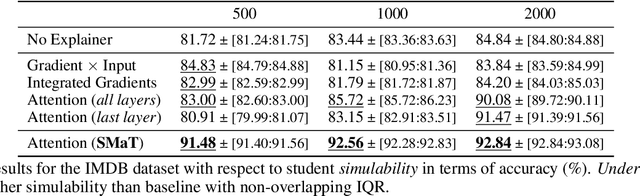

Modern machine learning models are opaque, and as a result there is a burgeoning academic subfield on methods that explain these models' behavior. However, what is the precise goal of providing such explanations, and how can we demonstrate that explanations achieve this goal? Some research argues that explanations should help teach a student (either human or machine) to simulate the model being explained, and that the quality of explanations can be measured by the simulation accuracy of students on unexplained examples. In this work, leveraging meta-learning techniques, we extend this idea to improve the quality of the explanations themselves, specifically by optimizing explanations such that student models more effectively learn to simulate the original model. We train models on three natural language processing and computer vision tasks, and find that students trained with explanations extracted with our framework are able to simulate the teacher significantly more effectively than ones produced with previous methods. Through human annotations and a user study, we further find that these learned explanations more closely align with how humans would explain the required decisions in these tasks. Our code is available at https://github.com/coderpat/learning-scaffold
Predicting Attention Sparsity in Transformers
Sep 24, 2021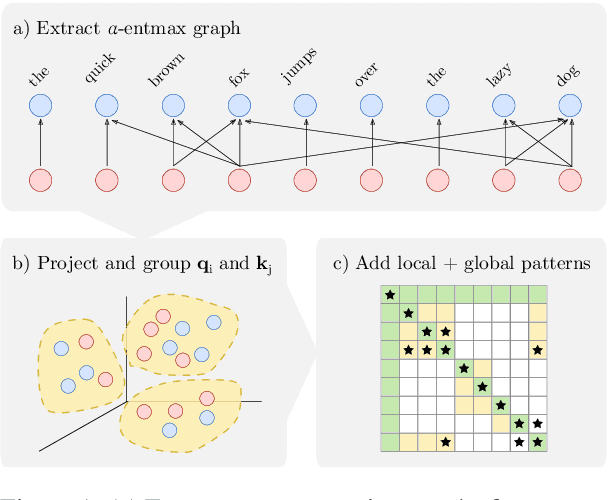
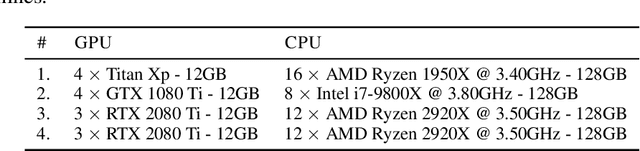
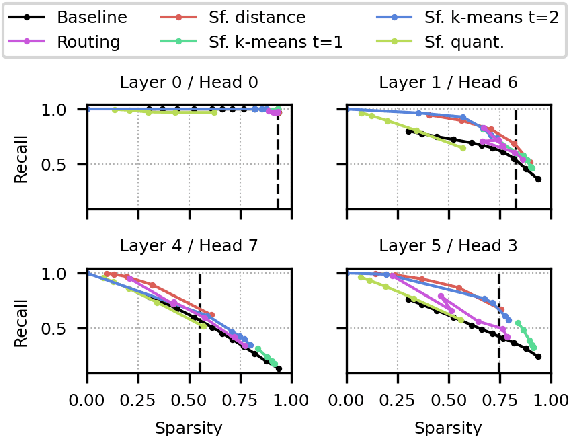

A bottleneck in transformer architectures is their quadratic complexity with respect to the input sequence, which has motivated a body of work on efficient sparse approximations to softmax. An alternative path, used by entmax transformers, consists of having built-in exact sparse attention; however this approach still requires quadratic computation. In this paper, we propose Sparsefinder, a simple model trained to identify the sparsity pattern of entmax attention before computing it. We experiment with three variants of our method, based on distances, quantization, and clustering, on two tasks: machine translation (attention in the decoder) and masked language modeling (encoder-only). Our work provides a new angle to study model efficiency by doing extensive analysis of the tradeoff between the sparsity and recall of the predicted attention graph. This allows for detailed comparison between different models, and may guide future benchmarks for sparse models.