 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOLD: Sinhala Offensive Language Dataset
Dec 01, 2022The widespread of offensive content online, such as hate speech and cyber-bullying, is a global phenomenon. This has sparked interest in the artificial intelligence (AI) and natural language processing (NLP) communities, motivating the development of various systems trained to detect potentially harmful content automatically. These systems require annotated datasets to train the machine learning (ML) models. However, with a few notable exceptions, most datasets on this topic have dealt with English and a few other high-resource languages. As a result, the research in offensive language identification has been limited to these languages. This paper addresses this gap by tackling offensive language identification in Sinhala, a low-resource Indo-Aryan language spoken by over 17 million people in Sri Lanka. We introduce the Sinhala Offensive Language Dataset (SOLD) and present multiple experiments on this dataset. SOLD is a manually annotated dataset containing 10,000 posts from Twitter annotated as offensive and not offensive at both sentence-level and token-level, improving the explainability of the ML models. SOLD is the first large publicly available offensive language dataset compiled for Sinhala. We also introduce SemiSOLD, a larger dataset containing more than 145,000 Sinhala tweets, annotated following a semi-supervised approach.
Predicting the Type and Target of Offensive Social Media Posts in Marathi
Nov 22, 2022The presence of offensive language on social media is very common motivating platforms to invest in strategies to make communities safer. This includes developing robust machine learning systems capable of recognizing offensive content online. Apart from a few notable exceptions, most research on automatic offensive language identification has dealt with English and a few other high resource languages such as French, German, and Spanish. In this paper we address this gap by tackling offensive language identification in Marathi, a low-resource Indo-Aryan language spoken in India. We introduce the Marathi Offensive Language Dataset v.2.0 or MOLD 2.0 and present multiple experiments on this dataset. MOLD 2.0 is a much larger version of MOLD with expanded annotation to the levels B (type) and C (target) of the popular OLID taxonomy. MOLD 2.0 is the first hierarchical offensive language dataset compiled for Marathi, thus opening new avenues for research in low-resource Indo-Aryan languages. Finally, we also introduce SeMOLD, a larger dataset annotated following the semi-supervised methods presented in SOLID.
Overview of the HASOC Subtrack at FIRE 2022: Offensive Language Identification in Marathi
Nov 18, 2022



The widespread of offensive content online has become a reason for great concern in recent years, motivating researchers to develop robust systems capable of identifying such content automatically. With the goal of carrying out a fair evaluation of these systems, several international competitions have been organized, providing the community with important benchmark data and evaluation methods for various languages. Organized since 2019, the HASOC (Hate Speech and Offensive Content Identification) shared task is one of these initiatives. In its fourth iteration, HASOC 2022 included three subtracks for English, Hindi, and Marathi. In this paper, we report the results of the HASOC 2022 Marathi subtrack which provided participants with a dataset containing data from Twitter manually annotated using the popular OLID taxonomy. The Marathi track featured three additional subtracks, each corresponding to one level of the taxonomy: Task A - offensive content identification (offensive vs. non-offensive); Task B - categorization of offensive types (targeted vs. untargeted), and Task C - offensive target identification (individual vs. group vs. others). Overall, 59 runs were submitted by 10 teams. The best systems obtained an F1 of 0.9745 for Subtrack 3A, an F1 of 0.9207 for Subtrack 3B, and F1 of 0.9607 for Subtrack 3C. The best performing algorithms were a mixture of traditional and deep learning approaches.
ALEXSIS-PT: A New Resource for Portuguese Lexical Simplification
Sep 19, 2022
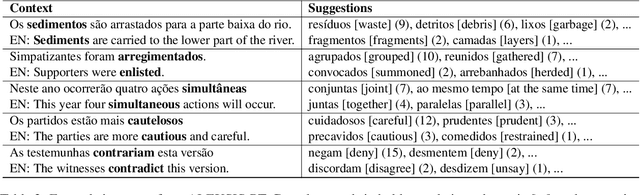

Lexical simplification (LS) is the task of automatically replacing complex words for easier ones making texts more accessible to various target populations (e.g. individuals with low literacy, individuals with learning disabilities, second language learners). To train and test models, LS systems usually require corpora that feature complex words in context along with their candidate substitutions. To continue improving the performance of LS systems we introduce ALEXSIS-PT, a novel multi-candidate dataset for Brazilian Portuguese LS containing 9,605 candidate substitutions for 387 complex words. ALEXSIS-PT has been compiled following the ALEXSIS protocol for Spanish opening exciting new avenues for cross-lingual models. ALEXSIS-PT is the first LS multi-candidate dataset that contains Brazilian newspaper articles. We evaluated four models for substitute generation on this dataset, namely mDistilBERT, mBERT, XLM-R, and BERTimbau. BERTimbau achieved the highest performance across all evaluation metrics.
Lexical Simplification Benchmarks for English, Portuguese, and Spanish
Sep 12, 2022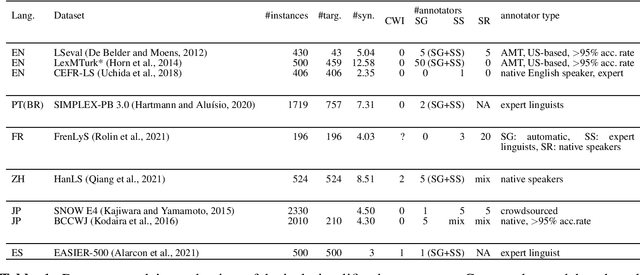
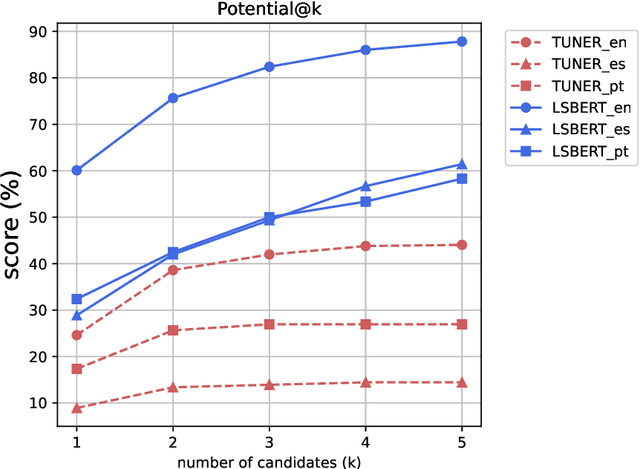
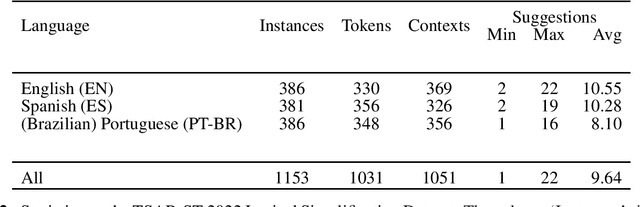
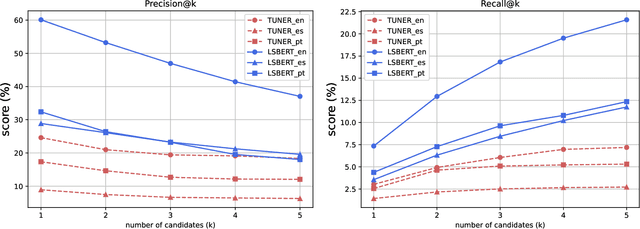
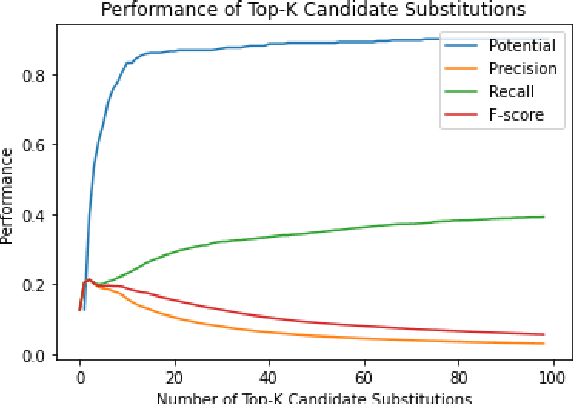
Even in highly-developed countries, as many as 15-30\% of the population can only understand texts written using a basic vocabulary. Their understanding of everyday texts is limited, which prevents them from taking an active role in society and making informed decisions regarding healthcare, legal representation, or democratic choice. Lexical simplification is a natural language processing task that aims to make text understandable to everyone by replacing complex vocabulary and expressions with simpler ones, while preserving the original meaning. It has attracted considerable attention in the last 20 years, and fully automatic lexical simplification systems have been proposed for various languages. The main obstacle for the progress of the field is the absence of high-quality datasets for building and evaluating lexical simplification systems. We present a new benchmark dataset for lexical simplification in English, Spanish, and (Brazilian) Portuguese, and provide details about data selection and annotation procedures. This is the first dataset that offers a direct comparison of lexical simplification systems for three languages. To showcase the usability of the dataset, we adapt two state-of-the-art lexical simplification systems with differing architectures (neural vs.\ non-neural) to all three languages (English, Spanish, and Brazilian Portuguese) and evaluate their performances on our new dataset. For a fairer comparison, we use several evaluation measures which capture varied aspects of the systems' efficacy, and discuss their strengths and weaknesses. We find a state-of-the-art neural lexical simplification system outperforms a state-of-the-art non-neural lexical simplification system in all three languages. More importantly, we find that the state-of-the-art neural lexical simplification systems perform significantly better for English than for Spanish and Portuguese.
Overview of the HASOC Subtrack at FIRE 2021: Hate Speech and Offensive Content Identification in English and Indo-Aryan Languages
Dec 17, 2021
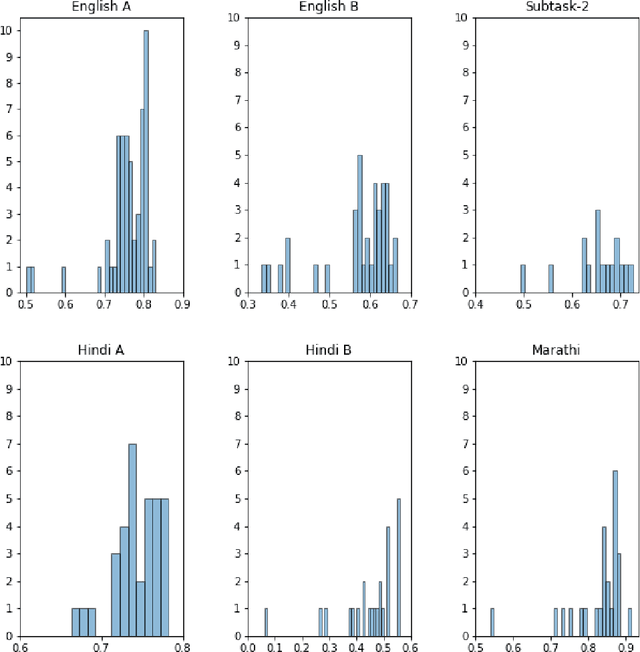

The widespread of offensive content online such as hate speech poses a growing societal problem. AI tools are necessary for supporting the moderation process at online platforms. For the evaluation of these identification tools, continuous experimentation with data sets in different languages are necessary. The HASOC track (Hate Speech and Offensive Content Identification) is dedicated to develop benchmark data for this purpose. This paper presents the HASOC subtrack for English, Hindi, and Marathi. The data set was assembled from Twitter. This subtrack has two sub-tasks. Task A is a binary classification problem (Hate and Not Offensive) offered for all three languages. Task B is a fine-grained classification problem for three classes (HATE) Hate speech, OFFENSIVE and PROFANITY offered for English and Hindi. Overall, 652 runs were submitted by 65 teams. The performance of the best classification algorithms for task A are F1 measures 0.91, 0.78 and 0.83 for Marathi, Hindi and English, respectively. This overview presents the tasks and the data development as well as the detailed results. The systems submitted to the competition applied a variety of technologies. The best performing algorithms were mainly variants of transformer architectures.
FBERT: A Neural Transformer for Identifying Offensive Content
Sep 10, 2021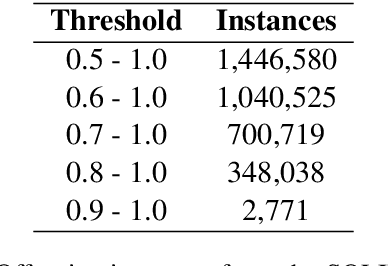
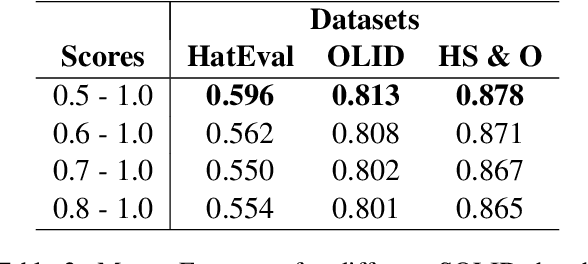
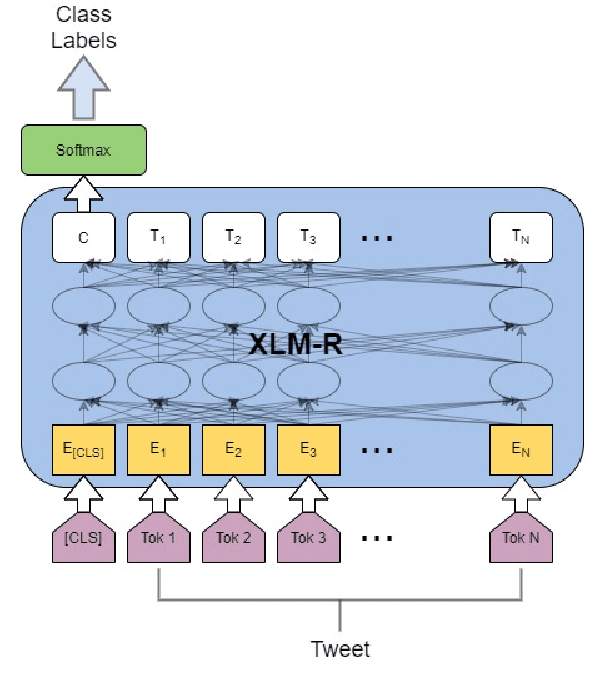
Transformer-based models such as BERT, XLNET, and XLM-R have achieved state-of-the-art performance across various NLP tasks including the identification of offensive language and hate speech, an important problem in social media. In this paper, we present fBERT, a BERT model retrained on SOLID, the largest English offensive language identification corpus available with over $1.4$ million offensive instances. We evaluate fBERT's performance on identifying offensive content on multiple English datasets and we test several thresholds for selecting instances from SOLID. The fBERT model will be made freely available to the community.
Cross-lingual Offensive Language Identification for Low Resource Languages: The Case of Marathi
Sep 08, 2021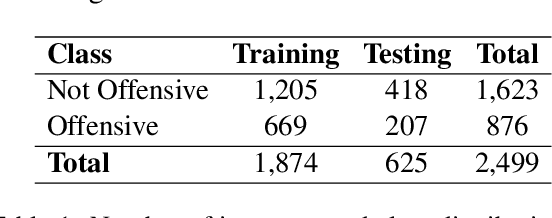

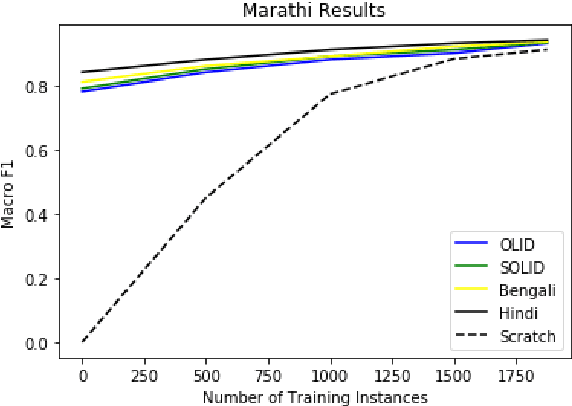
The widespread presence of offensive language on social media motivated the development of systems capable of recognizing such content automatically. Apart from a few notable exceptions, most research on automatic offensive language identification has dealt with English. To address this shortcoming, we introduce MOLD, the Marathi Offensive Language Dataset. MOLD is the first dataset of its kind compiled for Marathi, thus opening a new domain for research in low-resource Indo-Aryan languages. We present results from several machine learning experiments on this dataset, including zero-short and other transfer learning experiments on state-of-the-art cross-lingual transformers from existing data in Bengali, English, and Hindi.
An Ensemble Approach for Annotating Source Code Identifiers with Part-of-speech Tags
Sep 01, 2021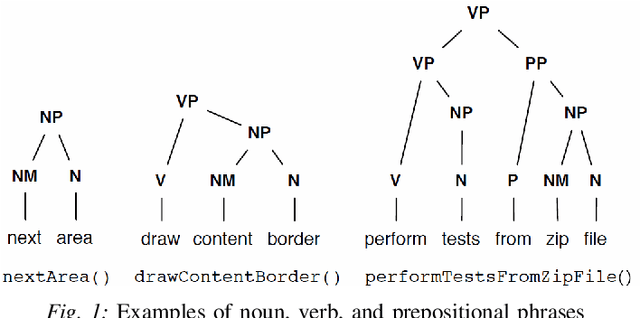

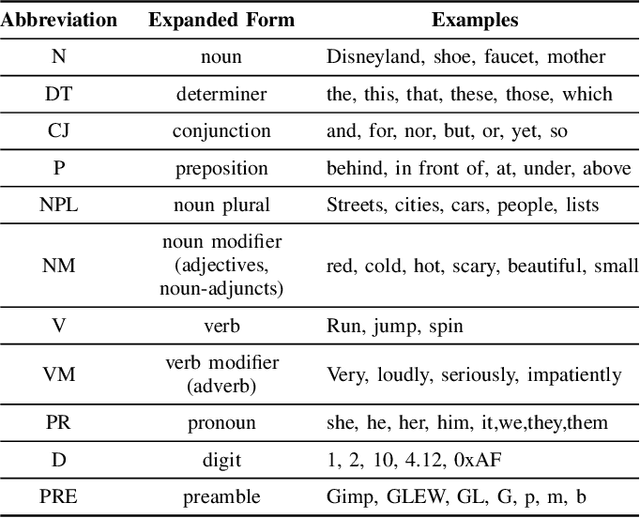
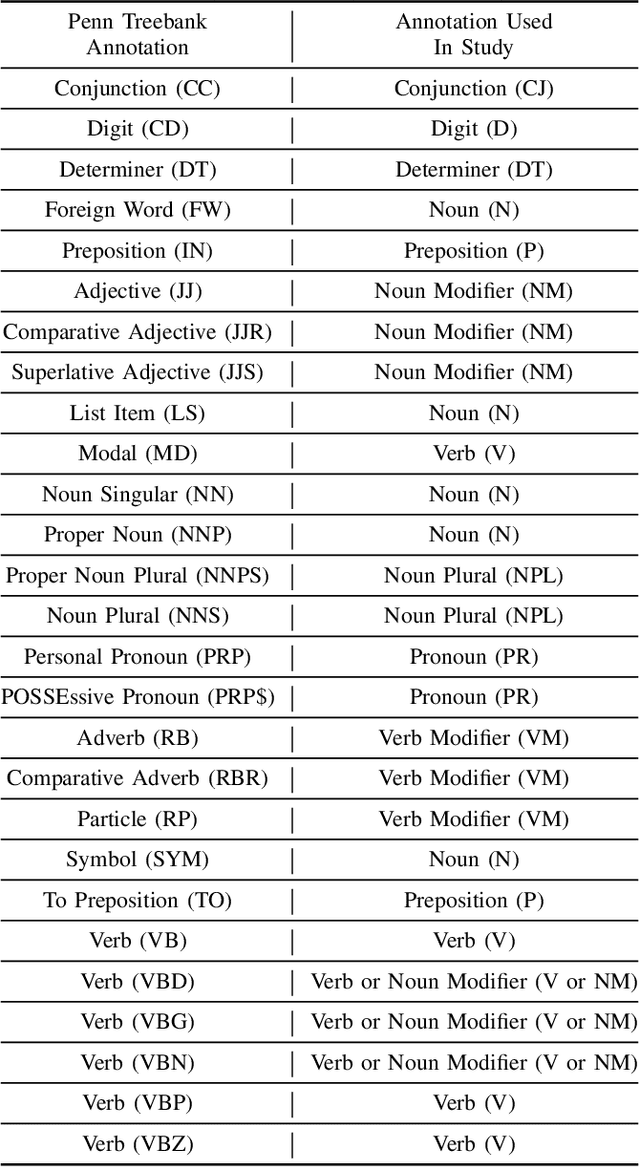
This paper presents an ensemble part-of-speech tagging approach for source code identifiers. Ensemble tagging is a technique that uses machine-learning and the output from multiple part-of-speech taggers to annotate natural language text at a higher quality than the part-of-speech taggers are able to obtain independently. Our ensemble uses three state-of-the-art part-of-speech taggers: SWUM, POSSE, and Stanford. We study the quality of the ensemble's annotations on five different types of identifier names: function, class, attribute, parameter, and declaration statement at the level of both individual words and full identifier names. We also study and discuss the weaknesses of our tagger to promote the future amelioration of these problems through further research. Our results show that the ensemble achieves 75\% accuracy at the identifier level and 84-86\% accuracy at the word level. This is an increase of +17\% points at the identifier level from the closest independent part-of-speech tagger.
* 18 pages. arXiv admin note: text overlap with arXiv:2007.08033
WLV-RIT at GermEval 2021: Multitask Learning with Transformers to Detect Toxic, Engaging, and Fact-Claiming Comments
Jul 30, 2021
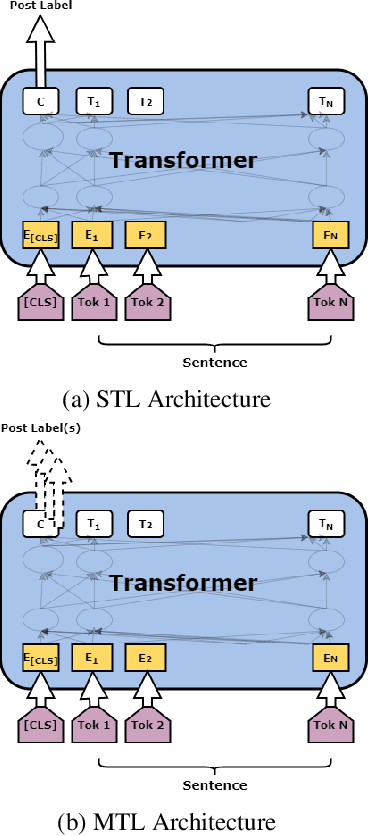
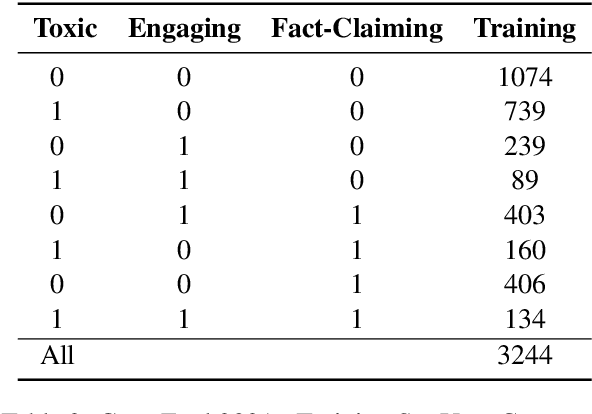
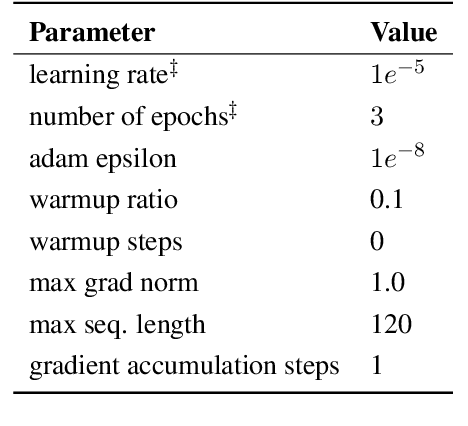
This paper addresses the identification of toxic, engaging, and fact-claiming comments on social media. We used the dataset made available by the organizers of the GermEval-2021 shared task containing over 3,000 manually annotated Facebook comments in German. Considering the relatedness of the three tasks, we approached the problem using large pre-trained transformer models and multitask learning. Our results indicate that multitask learning achieves performance superior to the more common single task learning approach in all three tasks. We submit our best systems to GermEval-2021 under the team name WLV-RIT.