 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDatasets for Depression Modeling in Social Media: An Overview
Mar 27, 2025



Depression is the most common mental health disorder, and its prevalence increased during the COVID-19 pandemic. As one of the most extensively researched psychological conditions, recent research has increasingly focused on leveraging social media data to enhance traditional methods of depression screening. This paper addresses the growing interest in interdisciplinary research on depression, and aims to support early-career researchers by providing a comprehensive and up-to-date list of datasets for analyzing and predicting depression through social media data. We present an overview of datasets published between 2019 and 2024. We also make the comprehensive list of datasets available online as a continuously updated resource, with the hope that it will facilitate further interdisciplinary research into the linguistic expressions of depression on social media.
On the State of NLP Approaches to Modeling Depression in Social Media: A Post-COVID-19 Outlook
Oct 11, 2024



Computational approaches to predicting mental health conditions in social media have been substantially explored in the past years. Multiple surveys have been published on this topic, providing the community with comprehensive accounts of the research in this area. Among all mental health conditions, depression is the most widely studied due to its worldwide prevalence. The COVID-19 global pandemic, starting in early 2020, has had a great impact on mental health worldwide. Harsh measures employed by governments to slow the spread of the virus (e.g., lockdowns) and the subsequent economic downturn experienced in many countries have significantly impacted people's lives and mental health. Studies have shown a substantial increase of above 50% in the rate of depression in the population. In this context, we present a survey on natural language processing (NLP) approaches to modeling depression in social media, providing the reader with a post-COVID-19 outlook. This survey contributes to the understanding of the impacts of the pandemic on modeling depression in social media. We outline how state-of-the-art approaches and new datasets have been used in the context of the COVID-19 pandemic. Finally, we also discuss ethical issues in collecting and processing mental health data, considering fairness, accountability, and ethics.
Transformer and Hybrid Deep Learning Based Models for Machine-Generated Text Detection
May 28, 2024



This paper describes the approach of the UniBuc - NLP team in tackling the SemEval 2024 Task 8: Multigenerator, Multidomain, and Multilingual Black-Box Machine-Generated Text Detection. We explored transformer-based and hybrid deep learning architectures. For subtask B, our transformer-based model achieved a strong \textbf{second-place} out of $77$ teams with an accuracy of \textbf{86.95\%}, demonstrating the architecture's suitability for this task. However, our models showed overfitting in subtask A which could potentially be fixed with less fine-tunning and increasing maximum sequence length. For subtask C (token-level classification), our hybrid model overfit during training, hindering its ability to detect transitions between human and machine-generated text.
Designing NLP Systems That Adapt to Diverse Worldviews
May 18, 2024Natural Language Inference (NLI) is foundational for evaluating language understanding in AI. However, progress has plateaued, with models failing on ambiguous examples and exhibiting poor generalization. We argue that this stems from disregarding the subjective nature of meaning, which is intrinsically tied to an individual's \textit{weltanschauung} (which roughly translates to worldview). Existing NLP datasets often obscure this by aggregating labels or filtering out disagreement. We propose a perspectivist approach: building datasets that capture annotator demographics, values, and justifications for their labels. Such datasets would explicitly model diverse worldviews. Our initial experiments with a subset of the SBIC dataset demonstrate that even limited annotator metadata can improve model performance.
Transformer based neural networks for emotion recognition in conversations
May 18, 2024This paper outlines the approach of the ISDS-NLP team in the SemEval 2024 Task 10: Emotion Discovery and Reasoning its Flip in Conversation (EDiReF). For Subtask 1 we obtained a weighted F1 score of 0.43 and placed 12 in the leaderboard. We investigate two distinct approaches: Masked Language Modeling (MLM) and Causal Language Modeling (CLM). For MLM, we employ pre-trained BERT-like models in a multilingual setting, fine-tuning them with a classifier to predict emotions. Experiments with varying input lengths, classifier architectures, and fine-tuning strategies demonstrate the effectiveness of this approach. Additionally, we utilize Mistral 7B Instruct V0.2, a state-of-the-art model, applying zero-shot and few-shot prompting techniques. Our findings indicate that while Mistral shows promise, MLMs currently outperform them in sentence-level emotion classification.
It's Just a Matter of Time: Detecting Depression with Time-Enriched Multimodal Transformers
Jan 13, 2023Depression detection from user-generated content on the internet has been a long-lasting topic of interest in the research community, providing valuable screening tools for psychologists. The ubiquitous use of social media platforms lays out the perfect avenue for exploring mental health manifestations in posts and interactions with other users. Current methods for depression detection from social media mainly focus on text processing, and only a few also utilize images posted by users. In this work, we propose a flexible time-enriched multimodal transformer architecture for detecting depression from social media posts, using pretrained models for extracting image and text embeddings. Our model operates directly at the user-level, and we enrich it with the relative time between posts by using time2vec positional embeddings. Moreover, we propose another model variant, which can operate on randomly sampled and unordered sets of posts to be more robust to dataset noise. We show that our method, using EmoBERTa and CLIP embeddings, surpasses other methods on two multimodal datasets, obtaining state-of-the-art results of 0.931 F1 score on a popular multimodal Twitter dataset, and 0.902 F1 score on the only multimodal Reddit dataset.
An End-to-End Set Transformer for User-Level Classification of Depression and Gambling Disorder
Jul 02, 2022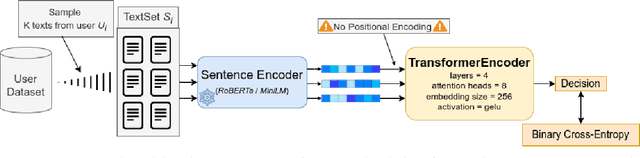
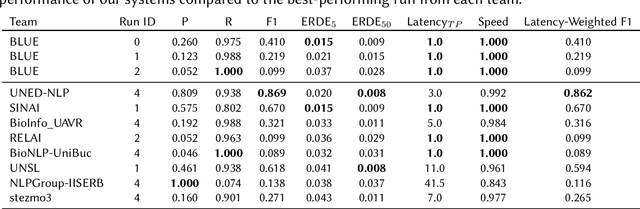
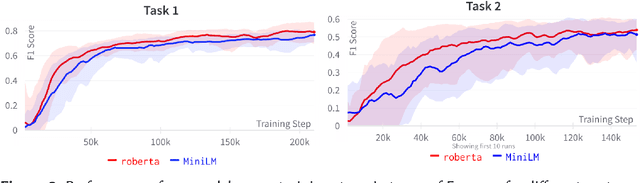
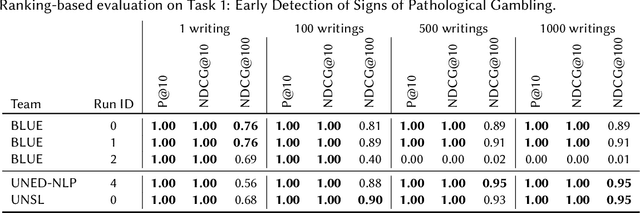
This work proposes a transformer architecture for user-level classification of gambling addiction and depression that is trainable end-to-end. As opposed to other methods that operate at the post level, we process a set of social media posts from a particular individual, to make use of the interactions between posts and eliminate label noise at the post level. We exploit the fact that, by not injecting positional encodings, multi-head attention is permutation invariant and we process randomly sampled sets of texts from a user after being encoded with a modern pretrained sentence encoder (RoBERTa / MiniLM). Moreover, our architecture is interpretable with modern feature attribution methods and allows for automatic dataset creation by identifying discriminating posts in a user's text-set. We perform ablation studies on hyper-parameters and evaluate our method for the eRisk 2022 Lab on early detection of signs of pathological gambling and early risk detection of depression. The method proposed by our team BLUE obtained the best ERDE5 score of 0.015, and the second-best ERDE50 score of 0.009 for pathological gambling detection. For the early detection of depression, we obtained the second-best ERDE50 of 0.027.
Life is not Always Depressing: Exploring the Happy Moments of People Diagnosed with Depression
Apr 28, 2022
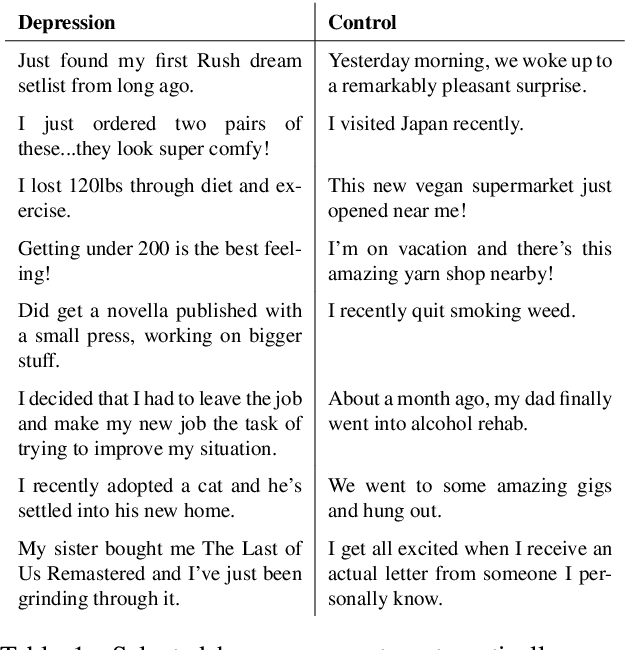
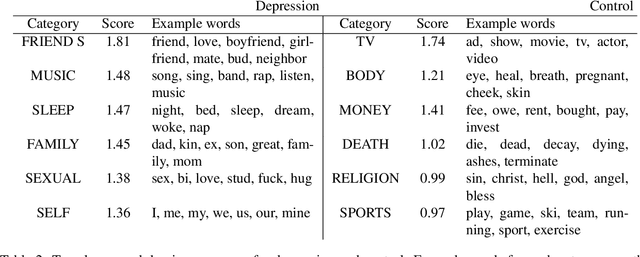
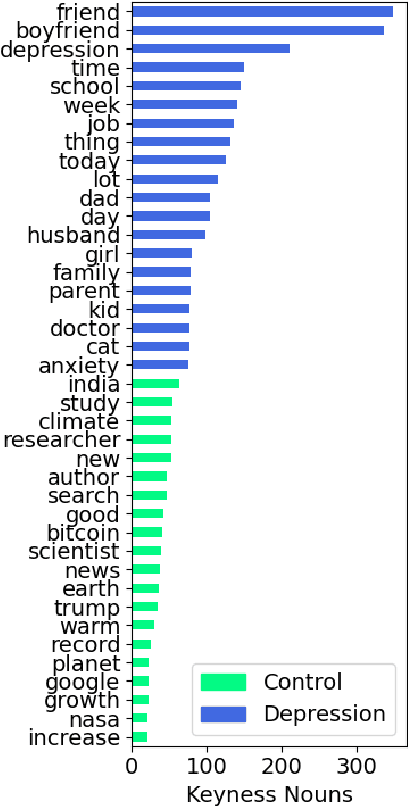
In this work, we explore the relationship between depression and manifestations of happiness in social media. While the majority of works surrounding depression focus on symptoms, psychological research shows that there is a strong link between seeking happiness and being diagnosed with depression. We make use of Positive-Unlabeled learning paradigm to automatically extract happy moments from social media posts of both controls and users diagnosed with depression, and qualitatively analyze them with linguistic tools such as LIWC and keyness information. We show that the life of depressed individuals is not always bleak, with positive events related to friends and family being more noteworthy to their lives compared to the more mundane happy events reported by control users.
Sequence-to-Sequence Lexical Normalization with Multilingual Transformers
Oct 12, 2021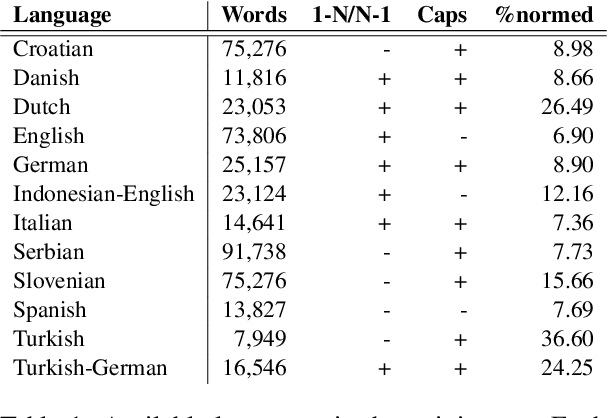
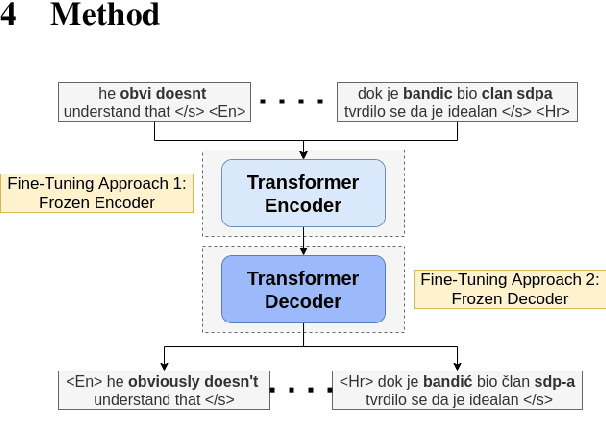

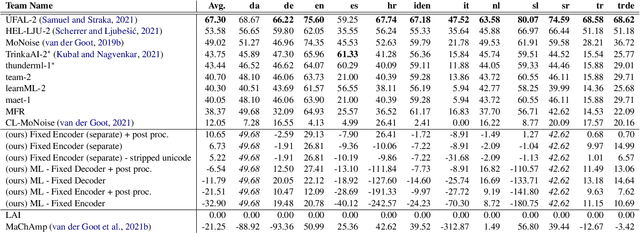
Current benchmark tasks for natural language processing contain text that is qualitatively different from the text used in informal day to day digital communication. This discrepancy has led to severe performance degradation of state-of-the-art NLP models when fine-tuned on real-world data. One way to resolve this issue is through lexical normalization, which is the process of transforming non-standard text, usually from social media, into a more standardized form. In this work, we propose a sentence-level sequence-to-sequence model based on mBART, which frames the problem as a machine translation problem. As the noisy text is a pervasive problem across languages, not just English, we leverage the multi-lingual pre-training of mBART to fine-tune it to our data. While current approaches mainly operate at the word or subword level, we argue that this approach is straightforward from a technical standpoint and builds upon existing pre-trained transformer networks. Our results show that while word-level, intrinsic, performance evaluation is behind other methods, our model improves performance on extrinsic, downstream tasks through normalization compared to models operating on raw, unprocessed, social media text.
A Psychologically Informed Part-of-Speech Analysis of Depression in Social Media
Jul 31, 2021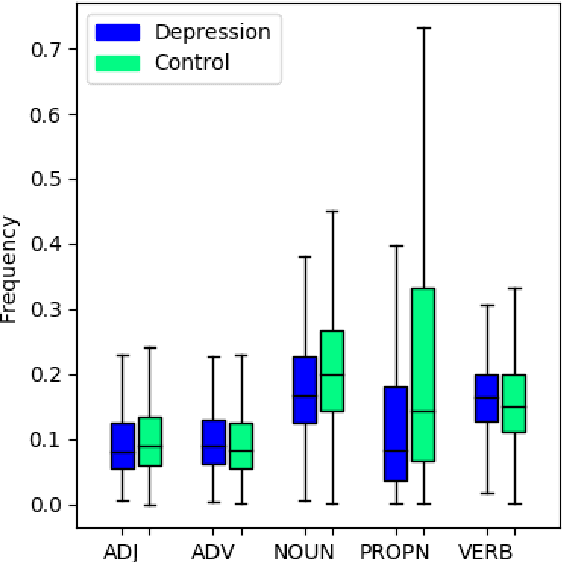
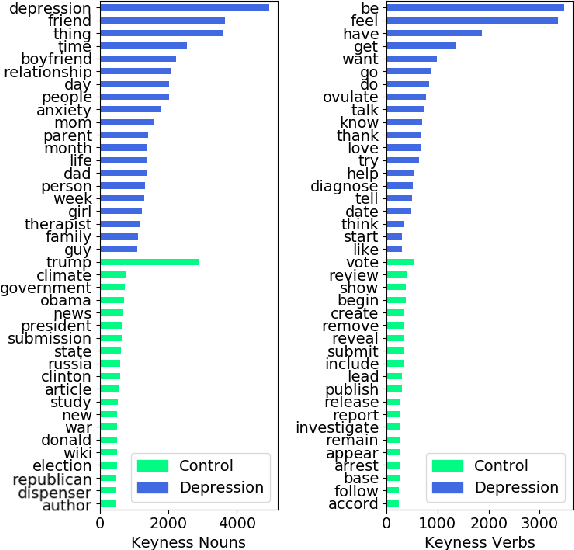
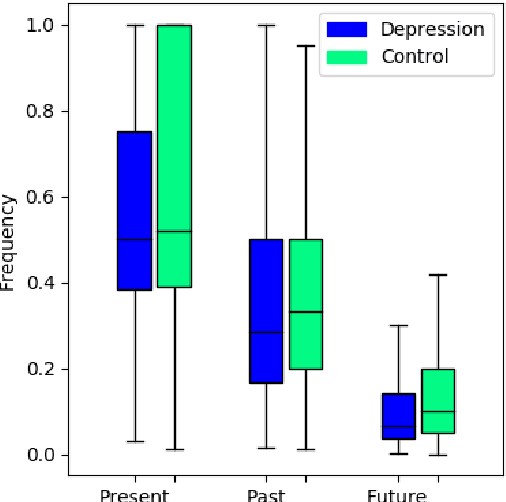
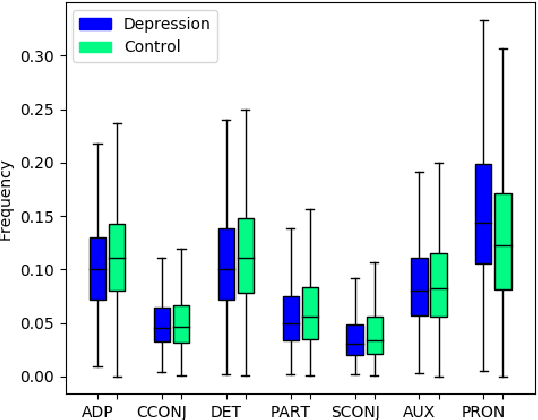
In this work, we provide an extensive part-of-speech analysis of the discourse of social media users with depression. Research in psychology revealed that depressed users tend to be self-focused, more preoccupied with themselves and ruminate more about their lives and emotions. Our work aims to make use of large-scale datasets and computational methods for a quantitative exploration of discourse. We use the publicly available depression dataset from the Early Risk Prediction on the Internet Workshop (eRisk) 2018 and extract part-of-speech features and several indices based on them. Our results reveal statistically significant differences between the depressed and non-depressed individuals confirming findings from the existing psychology literature. Our work provides insights regarding the way in which depressed individuals are expressing themselves on social media platforms, allowing for better-informed computational models to help monitor and prevent mental illnesses.